用无模型多主体强化学习掌握 Stratego 游戏 | 复杂性科学顶刊精选8篇
集智斑图顶刊论文速递栏目上线以来,持续收录来自Nature、Science等顶刊的最新论文,追踪复杂系统、网络科学、计算社会科学等领域的前沿进展。现在正式推出订阅功能,每周通过微信服务号「我的集智」推送论文信息。
扫描下方二维码,关注“我的集智”服务号,即可订阅Complexity Express: 
Complexity Express 一周论文精选
目录:
2. 将计算控制与自然文本相结合,揭示意义构成的各个方面
3. 量子处理器上的可穿越虫洞动力学
4. 定向渗流和向湍流的转变
5. 电网恢复过程中的停电组团碎片化
6. 条件偏移下偏微分方程的深度迁移算子学习
7. 狨猴大脑功能和结构连接的综合资源
8. 利用 AlphaFold 估计蛋白质模型精度的最新进展
1.DeepNash模型:用无模型
多主体强化学习掌握Straego游戏
论文题目:Mastering the game of Stratego with model-free multiagent reinforcement learning 论文来源:Science 论文链接:https://www.science.org/doi/10.1126/science.add4679
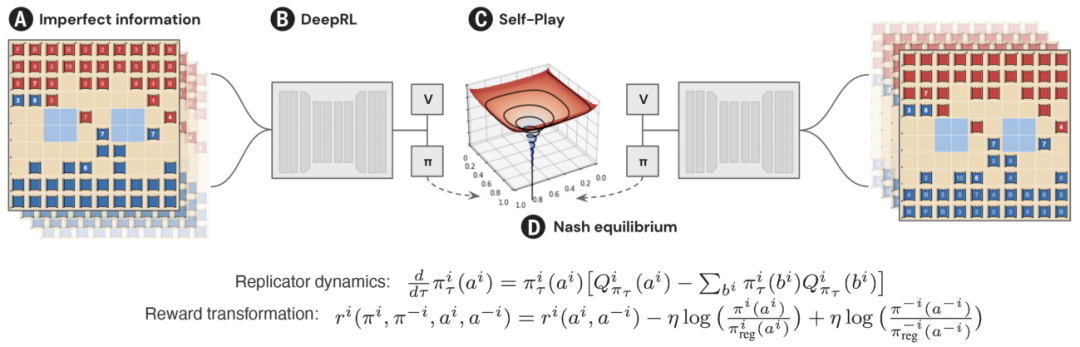
图:R-NaD 的概述。(A)DeepNash 基础上的 R-NaD 方法的概述,它允许学习玩不完全信息游戏Stratego。(B-D)R-NaD通过从头开始的自我博弈(C)学习由深度神经网络(B)代表的政策,并旨在收敛到纳什均衡(D)。该方法依靠两个核心思想来达到收敛:复制者动态和奖励转换。它们的方程以最简单的形式显示。
2.将计算控制与自然文本相结合,
揭示意义构成的各个方面

论文题目:Combining computational controls with natural text reveals aspects of meaning composition 论文来源:Nature Computational Science 论文链接:https://www.nature.com/articles/s43588-022-00354-6
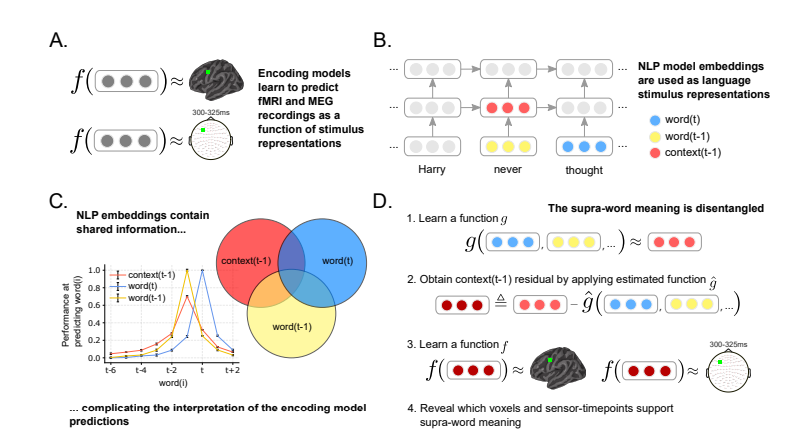
图:方法示意图(A)编码模型 f 试图通过学习,得到一个以参与者在实验中阅读文本的表征为自变量的函数,以预测对大脑的记录。(B)刺激表征是从一个 NLP 模型中获得的,该模型已经从数百万个文档中获取了语言统计数据。该模型使用上下文无关嵌入(以黄色和蓝色显示)和上下文相关的单词嵌入(红色显示)。上下文嵌入是通过不断集成每个新的词的上下文无关嵌入与最新的上下文嵌入形成的。(C)上下文和词嵌入共享信息。在周围位置的单词被绘制在不同的位置时,语境和词语嵌入在预测中的表现。上下文相关嵌入包含最多 6 个过去单词的信息,单词嵌入包含关于周围词语的嵌入。为了孤立超词语(supra-word)意义的表示,需要考虑共享的信息。(D)超词语的意义是通过获取属性的相关信息后嵌入上下文中的词语嵌入中的剩余信息。我们把这种残余称为上位词语嵌入或残余上下文。超词语嵌入被用作编码模型 f 的输入,揭示了其中功能磁共振成像体素和脑电传感器时间点的调制超文字的意义。
3.量子处理器上的可穿越虫洞动力学

论文题目:Traversable wormhole dynamics on a quantum processor 论文来源:Nature 论文链接:https://www.nature.com/articles/s41586-022-05424-3
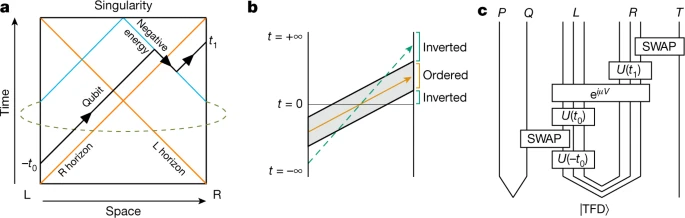
图:时空和全息对偶中的可穿越虫洞。(a)AdS 空间中的可穿越虫洞示意图。一个在 t = -t0 注入的量子比特通过虫洞的左侧进入;在 t = 0 时,在虫洞的两边之间施加一个耦合(虚线),引起一个负能量冲击波(蓝色);量子比特在接触到冲击波时经历一个时间提前,导致它在 t = t1 时从右侧出现。(b)说明传送信号的时间排序(虫洞)和时间反转(扰动)。可穿越虫洞的平滑半古典几何学产生了一个服从因果关系的传送制度;非引力传送导致信号以相反的顺序到达。(c)可穿越虫洞表示为一个量子电路,相当于在无限量子比特的半古典极限中的引力图景。 寄存器P持有一个与寄存器Q上的量子比特纠缠在一起的参考量子比特,被插入到虫洞中。单元 U(t) 表示在左、右SYK 模型(寄存器L和R)下的时间演化。TFD状态,在t=0时初始化虫洞。时间演化和马约拉纳费米子交换门在适当的时候实现量子比特注入(寄存器Q)和到达读出(寄存器T)。当μ<0时,耦合eiμV产生一个负能量冲击波,允许穿越;当μ>0时,耦合产生一个正能量冲击波,量子比特落入奇点。
4.定向渗流和向湍流的转变

论文题目:Directed percolation and the transition to turbulence 论文来源:Nature Reviews Physics 论文链接:https://www.nature.com/articles/s42254-022-00539-y

5.电网恢复过程中的停电组团碎片化

论文题目:Fragmentation of outage clusters during the recovery of power distribution grids 论文来源:Nature Communications 论文链接:https://www.nature.com/articles/s41467-022-35104-9

图:停电恢复期的概率密度函数。研究绘制了四组不同受影响人数下的停电恢复分布情况。四条曲线的相似性可由一个通用的反 Weibull(inverse Weibull) 分布函数拟合,这说明了停电恢复时间和受影响人数之间的独立性。
6.条件偏移下
偏微分方程的深度迁移算子学习
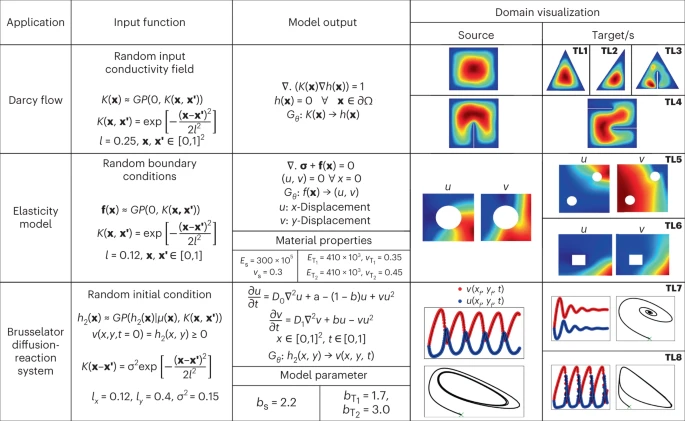
论文题目:Deep transfer operator learning for partial differential equations under conditional shift 论文来源:Nature Machine Intelligence 论文链接:https://www.nature.com/articles/s42256-022-00569-2
7.狨猴大脑功能
和结构连接的综合资源

论文题目:An integrated resource for functional and structural connectivity of the marmoset brain
论文来源:Nature Communications 论文链接:https://www.nature.com/articles/s41467-022-35197-2

图:狨猴脑图谱资源概要。该资源提供了清醒的测试-恢复静止状态 fMRI 数据,来自相同狨猴队列的体内弥散 MRI 数据,以及映射到同一 MRI 空间的体素/皮质水平的神经元追踪数据。除了数据集,它还支持全脑功能网络和计算模型的研究,以及基于功能连接的皮层解析(狨猴脑图谱第四版),使用深度神经网络进行精确的个体映射。作为狨猴大脑研究的综合多模态资源,我们还提供了一个在线平台来探索结构和功能连接之间的关系。这一功能体现在在线互动式查看器中。
8.利用AlphaFold
估计蛋白质模型精度的最新进展

论文题目:State-of-the-Art Estimation of Protein Model Accuracy Using AlphaFold 论文来源:Physical Review Letters 论文链接:https://journals.aps.org/prl/abstract/10.1103/PhysRevLett.129.238101

关于Complexity Express
Complex World, Simple Rules. 复杂世界,简单规则。
为了让大家能及时把握复杂系统领域重要的研究进展,我们隆重推出「Complexity Express」服务,汇总复杂系统相关的最新顶刊论文。
Complexity Express 是什么?

Complexity Express 为谁服务?
-
如果你是复杂系统领域的研究者,可获得重要论文上线通知,每周获取最新顶刊论文汇总。
-
如果你是复杂系统领域的学习者,可了解学界关注的前沿问题,把握专业发展脉络。
-
如果你是传统的生命科学、社会科学等学科中的研究者/学习者,可以从复杂科学和跨学科研究中获得灵感启发。
-
如果你是关注前沿研究发现的知识猎手,可获得复杂系统研究对自然和人类世界的最新洞见。
Complexity Express 论文从哪里来?
-
Nature
-
Science
-
PNAS
-
Nature Communications
-
Science Advances
-
Physics Reports
-
Physical Review Letters
-
Physical Review X
-
Nature Physics
-
Nature Human Behaviour
-
Nature Machine Intelligence
-
Review of Modern Physics -
Nature Review Physics -
Nature Computational Science -
National Science Review -
更多期刊持续增补中,欢迎推荐你认为重要的期刊!
Complexity Express 追踪哪些领域?
-
复杂系统基本理论 -
复杂网络方法及应用 -
图网络与深度学习 -
计算机建模与仿真 -
统计物理与复杂系统 -
量子计算与量子信息 -
生态系统、进化、生物物理等 -
系统生物学与合成生物学 -
计算神经科学与认知神经科学 -
计算社会科学与社会经济复杂系统 -
城市科学与人类行为 -
科学学 -
计算流行病学 -
以及一些领域小众,但有趣的工作
更多论文
点击“阅读原文”,追踪复杂科学顶刊论文
微信扫一扫,分享到朋友圈











