人类文明的成功,植根于我们通过沟通和制定共同计划进行合作的能力。人工智能主体面临着与人类类似的问题。最近,人工智能公司 DeepMind 展示了AI如何利用沟通在桌游“强权外交”中更好地合作。研究发现,沟通主体容易受到背叛协议者的负面影响。但如果对违反合同的主体进行制裁,则可以大大降低背叛者的优势,并鼓励人工智能主体保持诚实。
Yoram Bachrach, János Kramár | 作者
郭瑞东 | 译者
梁金 | 审校
邓一雪 | 编辑
论文题目:
Negotiation and honesty in artificial intelligence methods for the board game of Diplomacy
https://www.nature.com/articles/s41467-022-34473-5
纵观历史,成功的沟通与合作对于推动社会发展至关重要。棋类游戏的封闭环境可以作为沙盒来建模和调研交互和沟通,我们可以从中学到很多东西。在最近发表在 Nature Communications 杂志上的论文中,我们展示了人工智能(AI)如何利用沟通在桌游“强权外交”(Diplomacy)中更好地进行合作。“强权外交”是人工智能研究中一个充满活力的领域,以其对建立联盟的关注而闻名。
“强权外交”是具有挑战性的桌游,它规则简单,但由于玩家之间强烈的相互依赖性和巨大的行动空间而涌现出高度的复杂性。为解决这一挑战,我们设计了协商算法,允许主体(agent)交流并就联合计划达成一致,使他们能够战胜缺乏这种能力的主体。
当我们不能指望同伴履行承诺时,合作尤其具有挑战性。我们将“强权外交”作为沙盒,来探索当主体背叛他们过去的协议时会发生什么。我们的研究说明了当复杂的主体能够歪曲他们的意图,或者在未来计划上误导他人时,会出现怎样的风险,这就引出了另一个大问题:什么样的条件能够促进可信赖的沟通和团队合作?
我们的研究表明,制裁那些违反合同的同伴这一策略大大削减了他们背弃承诺所能获得的好处,从而促进了更诚实的沟通。
象棋、扑克、围棋和许多视频游戏一直是人工智能研究的沃土。“强权外交”是一个7人的谈判和结盟游戏,在将欧洲划分成省份的古老地图上进行,每个玩家控制多个单位(外交规则)。在游戏的标准版本,称为“新闻外交”(Press Diplomacy),每回合包括一个谈判阶段,在此之后,所有玩家同时透露他们选择的行动。
“强权外交”的核心是谈判阶段,在这个阶段,玩家们试图就他们的下一步行动达成一致。例如,一个玩家可以支持另一个玩家,允许它克服其他玩家的阻力,如下所示:
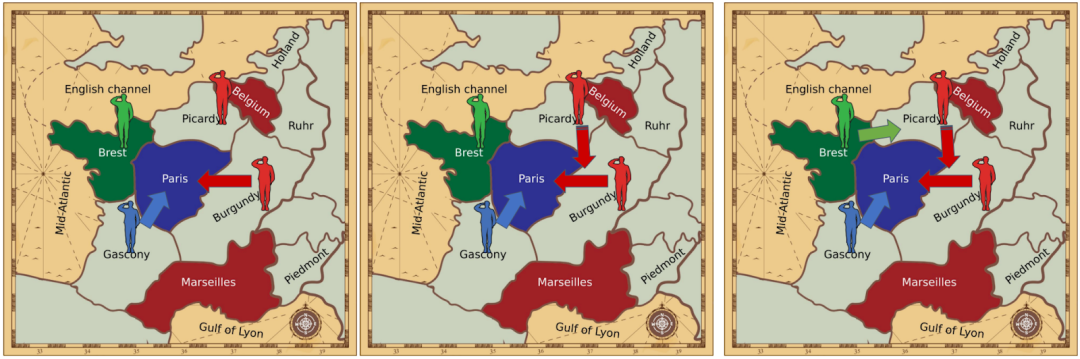
图1. 两种移动方案。左图: 两支部队(Burgundy 的一支红色部队和 Gascony 的一支蓝色部队)试图进入巴黎。由于两个单元势均力敌,两个单位都不能成功。右图:Picardy 的红色部队支援 Burgundy 的红色部队,压制蓝色部队,让红色部队进入 Burgundy。
自20世纪80年代以来,人们一直在研究“强权外交”的AI算法,其中许多方法都是在一个更简单的游戏版本“无媒体外交”(No-Press Diplomacy)中进行探索的,在这个版本中,玩家之间不允许进行战略沟通。研究人员还提出了计算机友好的谈判协议,有时被称为“限制版外交”。
我们使用“强权外交”作为现实世界谈判的模拟,人工智能主体通过算法协调他们的行动。我们通过向没有沟通能力的主体提供一份用以谈判联合行动计划的协议,用以增强他们在沟通方面的能力。我们称这些增强主体为基线谈判主体(Baseline Negotiator),它们受协议的约束。
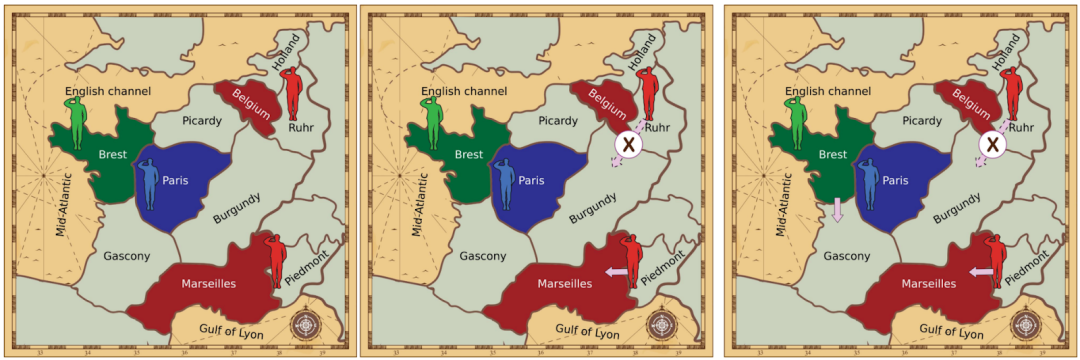
图2. 外交合同。左图: 一个限制,只允许红方玩家采取某些行动 [他们不允许从鲁尔河移动到勃艮第(Burgundy),必须从皮德蒙特(Piedmont)移动到马赛(Marseilles)]。右:红绿双方之间的合同,对双方都有限制。本文考虑两个协议:相互提议协议和提议-选择协议。
我们的主体应用算法,通过模拟游戏如何在不同的合同下展开来识别互惠交易。我们使用博弈论中的纳什讨价还价解(Nash Bargaining Solution)作为识别高质量协议的基础原则。游戏可能以很多方式展开,这取决于玩家的行为,因此我们的主体使用蒙特卡洛模拟来看下一回合可能发生什么。
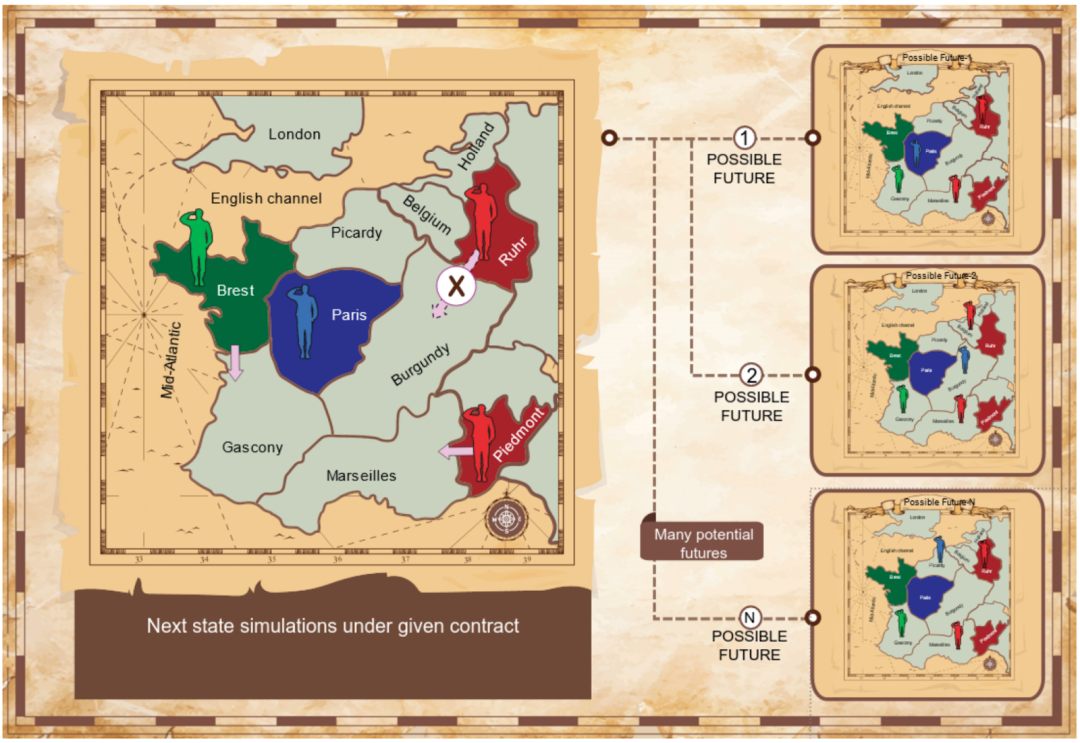
图3. 给定一个约定的契约,模拟下一步状态。左:部分棋盘上当前的状态,包括红色和绿色玩家之间商定的一个合同。右:多种可能的下一步状态。
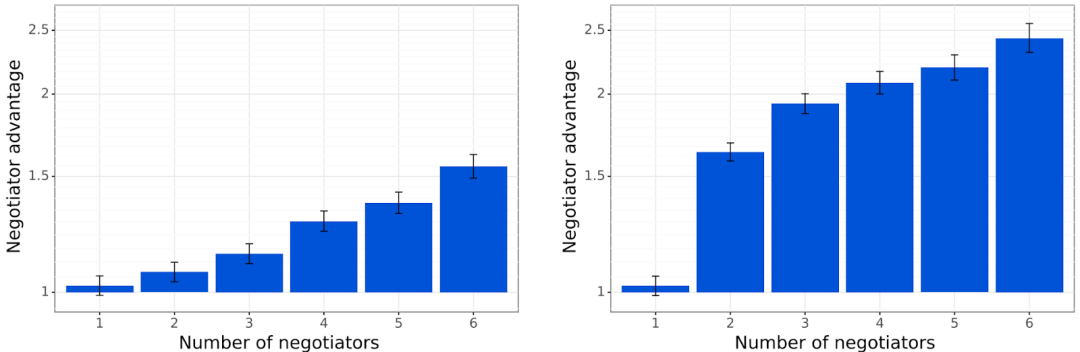
实验表明,我们的协商机制允许基线谈判主体明显优于非交流的基线主体。
图4. 基线谈判主体的表现明显优于非交流的主体。左: 共同提议协议。右: 提议-选择协议。“谈判者优势”(纵轴)是指交流主体与非交流主体之间的胜率比。
在“强权外交”中,谈判期间达成的协议是没有约束力的(口说无凭)。但是,如果主体这一次同意合同,下一次又违反合同,会发生什么呢?在许多现实生活场景中,人们同意以某种方式行事,但事后却不能履行承诺。为了实现人工智能主体之间或者主体与人类之间的合作,我们必须研究主体战略性地违反协议带来的潜在隐患,以及解决这个问题的方法。我们利用强权外交研究了背弃承诺的能力如何损害信任与合作,并确定了促进诚实合作的条件。
所以我们考虑背叛主体(Deviator Agent),它通过偏离商定的合同,试图战胜诚实的基线谈判者。简单背叛者(Simple Deviator)只是“忘记”他们曾同意合同,并随心所欲地移动。条件背叛者(Conditional Deviator)更加复杂,他们假设其他接受合同的玩家会按照合同行事,据此优化自己的行为。
图5. 所有类型的可交流主体。在绿色分组标准下,每个蓝色块代表一种特定的主体算法。
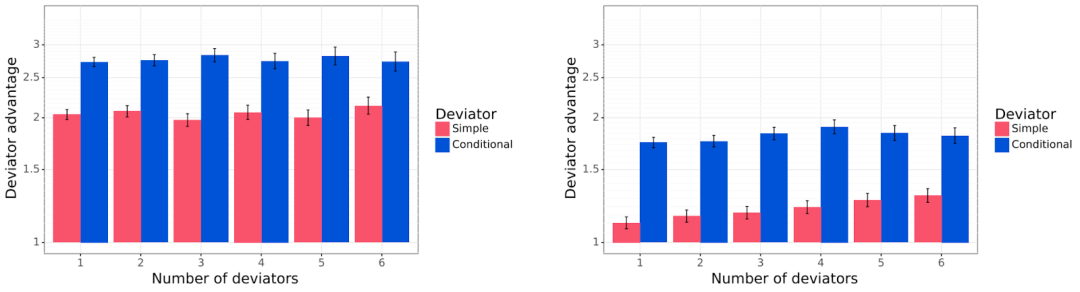
我们发现简单背叛者和条件背叛者的表现明显优于基线谈判者,而条件背叛者的表现是压倒性的(图3)。
图6. 背叛主体与 vs 基线谈判主体。左: 共同提议协议。右: 提议-选择协议。“背叛主体优势”(纵轴)是背叛主体与基线谈判主体之间的胜率比。
接下来我们使用防御主体(Defensive Agent)来解决背叛问题,防御主体对背叛者有负面的反应。我们调查二元谈判者(Binary Negotiator),它们只是简单地切断与违反协议的主体的联系。但回避只是一种温和的反应,所以我们也开发了制裁主体(Sanctioning Agent),他们不会忽视背叛,而是修改他们的目标,积极地试图降低背叛者的得分——一个怀恨在心的对手!我们表明,这两种类型的防御主体减少了背叛带来的优势,特别是制裁主体。
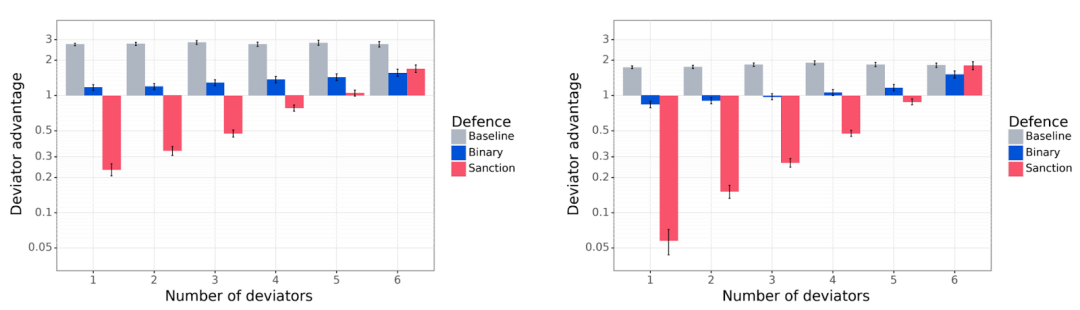 图7. 非背叛主体(基线谈判主体、二元谈判主体和制裁主体)对付条件背叛主体。左图: 共同提案协议。右图,提议-选择协议。“背叛优势”(纵轴)值小于1表示防御主体优于背叛主体。与基线谈判者(灰色)相比,二元谈判者(蓝色)的数量减少了背叛者的优势。
图7. 非背叛主体(基线谈判主体、二元谈判主体和制裁主体)对付条件背叛主体。左图: 共同提案协议。右图,提议-选择协议。“背叛优势”(纵轴)值小于1表示防御主体优于背叛主体。与基线谈判者(灰色)相比,二元谈判者(蓝色)的数量减少了背叛者的优势。
最后,我们引入可学习的背叛者(Learned Deviator),他们在多场游戏中调整和优化策略,以对抗制裁主体的行为,试图降低上述防御策略的有效性。一个可学习背叛者只有在背叛带来的直接收益足够高,而其他主体的报复能力足够低的情况下才会违约。在实践中,可学习的背叛者偶尔会在游戏后期违反合同,这样做相比制裁主体可以获得略微优势。尽管如此,这些制裁还是促使可学习的背叛者履行了99.7%以上的合同。
我们还研究了制裁和背叛主体的可能学习动力学:当制裁主体也可能背叛合同时会发生什么,以及当这种行为代价高昂时停止制裁的潜在动机。这些问题会逐渐削弱合作,因此可能需要其他机制,例如跨多个游戏的重复互动,或需要使用信任和声誉系统。
我们的论文为未来的研究留下了许多问题:是否有可能设计更复杂的协议来鼓励更诚实的行为?如何在不完全信息博弈时使用各种交流技术?最后,还有什么其他机制可以阻止协议被破坏?构建公平、透明和可信赖的人工智能系统是一个极其重要的课题,也是 DeepMind 使命的关键部分。在“强权外交”这样的沙盒中研究这些问题,有助于我们更好地理解现实世界中可能存在的合作与竞争之间的紧张关系。最终,我们相信应对这些挑战能让我们更好地理解,如何根据社会的价值观和优先事项开发人工智能系统。
原文链接:https://www.deepmind.com/blog/ai-for-the-board-game-diplomacy
集智斑图顶刊论文速递栏目上线以来,持续收录来自Nature、Science等顶刊的最新论文,追踪复杂系统、网络科学、计算社会科学等领域的前沿进展。现在正式推出订阅功能,每周通过微信服务号「我的集智」推送论文信息。扫描下方二维码即可一键订阅: