21世纪被称为复杂性的世纪。当今的科学挑战以复杂性为特点:相互连接的自然、技术和人类系统,受到时间和空间尺度的力量影响,表现出复杂的相互作用和涌现行为。人工智能(AI)为理解这种复杂性提供了工具。AI 应用于气候科学、农业科学、天体物理学、发育生物学、神经科学等各个领域,跨越多个维度和尺度,帮助科学家从数据中提取关于世界的新知识。
本文受到2022年9月 Dagstuhl 研讨会“科学中的机器学习:架起数据驱动和机制建模的桥梁”启发,提出了一份针对“AI for Science”的路线图,旨在推动开发更强大的 AI 工具赋能科学发现,促进对自然、物理和社会复杂系统的模拟能力。
集智俱乐部联合斯坦福大学计算机科学系博士后研究员吴泰霖(Jure Leskovec 教授指导)、哈佛量子计划研究员扈鸿业、麻省理工学院物理系博士生刘子鸣(Max Tegmark 教授指导),共同发起以“AI+Science”为主题的读书会,探讨该领域的重要问题,共学共研相关文献。读书会从2023年3月26日开始,每周日早上 9:00-11:00 线上举行,持续时间预计10周。欢迎对探索这个激动人心的前沿领域有兴趣的朋友报名参与。
关键词:复杂系统,人工智能,AI for Science
Philipp Berens 等 | 作者
唐诗翔、Lynn Zhao | 编译
梁金 | 编辑
论文题目:AI for Science: An Emerging Agenda
论文链接:https://arxiv.org/abs/2303.04217
摘要
总论
1. 引言:数据驱动和物理模型驱动两种研究范式的桥梁
2. AI 在科学中的应用概览
3. 构建高效的模拟系统
4. 联系数据与因果
5. 编码领域知识
6. AI for science 研究议程
7. 加速 AI for science 进程
这份报告记录了 Dagstuhl 研讨会22382 “科学中的机器学习:架起数据驱动和机制建模的桥梁”的项目和成果。
人工智能的变革潜力来自于其在各个学科的广泛适用性,并且只有通过跨学科整合才能实现,AI for Science 是一个汇聚点。它汇集了人工智能和应用领域的专业知识;结合了建模知识和工程技能;并依赖于跨学科和人机之间的合作。伴随着技术的进步,该领域下一波进展将来自构建一个由机器学习研究人员、领域专家、公民科学家和工程师组成的社群,一起共同努力设计和部署有效的人工智能工具。
本报告总结了研讨会的讨论内容,并提供了一份路线图,以建议不同社群如何合作推动人工智能及其在科学发现中的应用的新一波进展。
当今的科学挑战以复杂性为特点:相互连接的自然、技术和人类系统,受到作用于时间和空间尺度的力量影响,导致出现复杂的相互作用和涌现行为。理解这些现象并利用科学进步为提高社会健康、财富和福祉提供创新解决方案需要新的方法来分析复杂系统。
人工智能(AI)为我们提供了一套工具来帮助理解这种复杂性。在一个来自比以往任何时候都更多的数据源的环境中——从原子尺度到天文尺度——AI最近的进步所提供的分析工具可以在解锁新一波研究和创新方面发挥重要作用。如今,AI这个术语描述了一套工具和方法,它们在计算机系统中复制了智能的某些方面。该领域的许多最近进展源于机器学习方面的进步,这是一种基于数据的人工智能方法,使计算机系统学会如何执行任务。
在科学领域,AI 释放的潜力信号可以在许多领域看到。AI 应用于气候科学,以研究地球系统如何应对气候变化;在农业科学中,用于监测动物健康;在发展研究中,支持社区更有效地管理本地资源;在天体物理学中,了解黑洞、暗物质和系外行星的性质;以及在发育生物学中,绘制从基因到器官的细胞发育途径。这些成功例子说明了AI在科学领域可能实现的更广泛的进步。在实践中,这些应用为人工智能科学(the science of AI)提供了深入见解,揭示了理解智能本质及在计算机系统中实现智能行为的学习策略途径。
我们需要新一代的人工智能模型。AI for Science 需具备新的建模方法:促进自然、物理或社会系统复杂模拟的能力;赋能科研工作者使用数据去分析塑造这种系统的力;解析复杂因果关系;与领域专家协同适应。创建这些模型将消除学科间及数据驱动与机制建模间的隔阂。此路线图展示了如何跨领域合作,实现AI及其在科学发现应用的新进展。
围绕AI在科学中的共同挑战,研究界可加速技术进步并部署解决实际问题的工具。通过创建用户友好工具包、实施软件和数据工程最佳实践,研究人员可以支持广泛采用的有效AI方法。研究机构通过技能培训、召集及支持跨学科合作,鼓励研究人员开发和采用新的AI方法。个人研究者和机构通过贡献研究和实践社区,分享见解并扩大AI与科学交融的研究者群体。科学家们需要共同努力可推动科学范式转变,实现AI进步,释放新一波AI驱动创新。AI变革潜力源于跨学科广泛适用性,需跨研究领域整合。
AI for Science 是一个汇聚点。它汇集了人工智能和应用领域的专业知识;结合了建模知识和工程技能;并依赖于跨学科和人机之间的合作。伴随着技术的进步,该领域下一波进展将来自构建一个由机器学习研究人员、领域专家、公民科学家和工程师组成的社群,一起共同努力设计和部署有效的人工智能工具。
21世纪被称为复杂性的世纪。不断变化的社会、经济、环境和技术力量已经创造了越来越紧密相连的社群,并受到健康、气候和经济等领域的“顽固”问题影响。这种复杂性反映在今天的科学议程中:无论是自然科学、物理科学、医学、环境科学还是社会科学,研究人员通常关注复杂系统的动力学和从中涌现的现象。
科学一直通过收集数据来发展,做实验和观察数据,建立模型或关于世界运行方式的理论,然后对这些预测进行测试,从而对模型和基础理论进行进一步完善。实验室和其他地方的日常活动数字化意味着研究人员今天可以从更广泛的来源获取更多数据。同时,从更加成熟精密的工具收集到的数据也打开了科学探索的新尺度,从基因表达的模式到来自星系的光信号。AI的进步为理解这些数据来源提供了新的分析工具,将数据、数学模型和计算能力相结合以对世界进行预测的算法决策系统。
1. 地球科学:研究地球生物圈互动与气候变化影响。
2. 气候科学:重建历史气候模式,预测未来气候变化。
4. 天体物理学:深化对暗物质本质及其在宇宙中作用的理解。
5. 发育生物学:揭示影响细胞发育和分化的遗传过程。
6. 环境科学:更准确地分析自然环境特征,助力土地和资源管理。
7. 神经科学:帮助模拟不同的神经回路如何在动物身上产生不同的行为。
这些成功案例的多样性表明,AI 在自然、物理、社会、医学、计算机科学、艺术、人文和工程等领域具有潜力来改变研究方式。AI 能够让研究人员从更多来源、更大规模的数据中提取见解,跨越多个维度和尺度,从而揭示世界的新认识。通过精细的模拟,AI 可以帮助研究人员生成自然或物理系统,创建现实世界系统的“数字孪生”用于实验和分析,也可以辅助实验室流程提高实验效率,并协助研究人员制定和测试新假设[47]。这些进步依赖于跨学科合作,将领域专长与机器学习模型开发相结合,并将这些模型产生的见解反馈到研究领域。
未来需要探讨“AI for science”的最佳实践方法和技术,以及它是否将作为独立领域出现,还是通过各领域的子领域来实现最佳效果[46]。本文提出了一份针对“AI for Science”的路线图,旨在帮助开发更强大的 AI 工具赋能科学发现,并确定可为其部署提供支持的领域。先开始于探索核心的研究课题——仿真,因果,领域知识编码——然后从这些想法中提炼研究议题和行动计划来支持后续的发展。这里提出的观点受到了2022年9月 Dagstuhl 研讨会“科学中的机器学习:架起数据驱动和机制建模的桥梁”的讨论启发。
AI 正在不断地应用于各个领域,以推动科学的发展。下面的简述介绍了一些当前科学中 AI 的研究领域,并探讨了这些研究项目所带来的问题。在这些概述中,一些共同主题显现出来:
• 研究人员如何能更有效地结合观察、数据驱动模型和物理模型来深入理解复杂系统?为解答这个问题,需要研发能够整合不同类型、不同粒度级别模型的方法,同时控制在将机器学习模型整合到更广泛系统中时产生的不确定性影响。新的模拟和仿真方法可以推动应对这些挑战的进展,同时为评估机器学习模型的稳定性或性能提供新策略。
• AI系统的输出如何与研究人员已经了解的世界知识相吻合,以及这些系统如何揭示数据中的因果关系?需要在因果机器学习方面取得突破,将许多研究领域已经确立的法则和原则与数据驱动方法相结合。
• 如何安全、可靠地将AI整合到科学过程中?有效地整合依赖于在AI系统中嵌入领域知识、设计人机互动友好的界面,以及开发分享在实践中如何使用AI知识和技能的机制。
地球是由陆地、海洋和大气生物圈组成的复杂系统,它们相互作用并交换能量。研究地球系统主要依赖于观测和物理模型,以分析气候变化对地球的影响并构建地球子系统模型。地球系统科学的挑战是在不产生过多不确定性的前提下,建立更为复杂的模型,以便了解环境变化的局部影响。例如,不同因素会影响生物圈吸收二氧化碳的贡献,包括植被覆盖、水分和温度等。虽然可以获得各地生态系统吸收二氧化碳的数据,但这些数据不足以表示全球碳交换。为解决这一挑战,一种方法是利用数据驱动的模型将不同生物圈的碳、水和能量循环机制联系起来。
通过从观测数据开始并结合物理建模,研究人员可以利用机器学习创建仿真,从而生成关于复杂系统如何运作的新理解。FLUXNET项目利用观测数据和物理建模结合机器学习创建仿真,生成全球碳动力学的数据驱动画面。该项目通过组合数据建立全球碳动力学的统计模型,生成地球呼吸的模拟。整合不同地球子系统的模型还可以为构建地球的“数字孪生”做出贡献,了解气候变化对生物圈和群落的影响。
随着气候变化,地球环境将发生变化,极端天气事件也将增多。了解这些变化对于采取适当的应对措施非常重要。景观对环境变化的反应取决于当地气候、地形和人类活动。模型假设或抽象可能失效,而仅依赖机制性描述或统计模型可能导致不准确。机器学习可以通过创建融合物理定律和数据学习的混合模型来解决这一挑战。
冰量损失成为海平面上升的主要原因,全球所有冰川和冰层融化后海平面将上升超过60米,使沿海城市被淹没。通过力学模型和观测数据,研究人员可以估算冰融化对海平面上升的贡献。机器学习可以为模型提供工具,连接冰层模型和海洋大气模型,提高其准确性,并在混合机制-数据模型中整合不同类型的数据。
然而,建立满足特定领域需求的模型具有相当的复杂性。一些项目已考虑对冰层系统或其组成部分进行仿真,以检验模型是否能更快地运行,但尚不清楚这些努力是否满足了明确的研究需求。另一种方法是利用机器学习简化模拟,例如,确定不同模型的最佳粒度级别。需要记住的一点是,机器学习是研究工具,但并不是万能工具。将机器学习有效地应用于研究需要适当的AI工具箱,并了解哪些工具最适合解决哪些挑战。
在坦桑尼亚,家禽养殖是重要收入和食物来源,但由于疾病的流行,生产力相对较低。现有的诊断方法需要对粪便进行实验室分析,这需要3-4天的时间,一旦确诊,农民通常会失去整个农场的鸡群。为了解决这个问题,研究人员通过收集农场的粪便图像,创建了一个用于训练能识别这些疾病症状的机器学习系统的数据集,并设计了一个应用程序来自动化诊断过程。这一研究的结果展示了尤其是在发展中国家利用本地数据进行疾病检测的潜力。[1]
跨领域专家合作对于开发此系统至关重要。需要农民参与收集数据并在实际操作中测试系统;兽医病理学家有助于对数据进行标注并确保系统的准确性;技术专家负责开发一个能在手机上有效部署为应用程序的AI系统。这些合作还为新形式的公民科学创造了机会,农民和当地社区可以参与到开发和维护一个开放式的疾病诊断工具箱中,让社区能够更好地利用机器学习这一工具来满足自己的需求。
树木和森林对维护生态系统至关重要,但全球每年因重新造林而失去约1000万公顷的森林,非洲的森林每年以大约390万公顷的速度消失,这对生物多样性和人类产生了影响。为了了解树木数量和分布对制定林业管理计划和理解土地利用变化对碳储存的影响至关重要。研究人员使用来自400个采样点的9万个树木的卫星图像,创建了一个标记数据集用于机器学习。使用图像分割工具识别树木位置,自动化系统能够计算树木数量,然后使用这些属性来输入描述生态系统物理功能的模型,预测树木生物量并估计其存储的碳量。需要注意管理由于使用不同建模方法而带来的的不同类型和性质的不确定性。源自于计算一棵树的生物量时的一个小错误,当规模化到国家面积级别时,会有非常大的累积影响,在使用机器学习模型时,需要考虑此类不确定性的类型和性质。
疾病媒介昆虫导致全球17%以上的人类疾病,每年超过700,000人死亡[12]。利用卫星图像的工具可以表征建筑特征,研究人员利用这些工具分析多尺度数据,调查建筑环境对人类感染蚊媒疾病的风险的影响。在某些地区,蚊子的流行率与建筑物屋顶材料的类型有关[14, 15]。这些见解可以被决策者用于开发适当的政策响应。
暗物质是粒子物理学未解之谜,虽然无法直接观测,但通过观测宇宙现象如星体运动、引力透镜现象等,可以了解它对宇宙形成的重要影响。机器学习在天体粒子物理研究中的挑战在于从宇宙中可以观察到的宏观模式中提取关于暗物质粒子组成的信息。例如,引力透镜现象可以提供有关暗物质亚结构的信息。通过让机器学习模型描述复杂的背景光源,可以预测光在有和没有暗物质亚结构的情况下因为引力透镜效应出现的形式。该领域需要进一步研究来评估机器学习方法的可靠性,以生成物理可信的结果并对暗物质和其他新物理性质的性质施加严格限制[19]。
许多领域都关注粒子在环境中的运动方式。例如,在化学中,研究人员通常关注分子如何扩散以及它们如何在时间上基于物理力移动并分布到哪里。粒子运动的类比也可以应用于更大尺度的物理过程,例如基于主体的人群模拟。在这些系统中,初始状态表示为初始概率分布,科学目标也可以表示为目标分布。这种扩散背后的动力学在Schrödinger桥问题中被数学形式化。这个长期存在的问题关注的是,基于实验观察到的起始和终止位置,找到粒子从其起始分布移动到定义时间点的分布的最可能路径。通常,找到Schrödinger桥问题的解析解是不可行的,但机器学习工具正在提供新的方法,用于找到可以在不同领域中使用的近似数值解 [22]。
细胞发育和分化成组织和器官是一个复杂的过程,受到激素和基因影响细胞生长的调节[23]。基因组学的进步使得研究人员能够表征不同生物的遗传物质;最近在单细胞基因组学方面的进展将这种能力扩展到了单细胞水平,揭示了遗传活动如何决定细胞功能的详细分析。
单细胞RNA研究探讨了核糖核酸(RNA)如何塑造细胞特性和发育途径。通过基因测序技术创建的RNA剖析文件可以帮助研究人员确定一个细胞中哪些基因是活跃的。该领域今天面临的问题是如何从这些单细胞分析中得到一个显示细胞发育如何特化并形成组织或器官的细胞发育图谱。
通过结合统计和机器学习技术,研究人员可以重构影响细胞发育的基因动力学 – 哪些基因在哪个时刻被激活。例如,小肠中的细胞经历了一种分化模式,将它们从基础状态转变为高度专业化的单位,能够不同程度地分泌粘液、吸收营养或响应激素。通过研究一个细胞早期阶段表达的基因,研究人员可以预测细胞将如何特化,并确定哪些基因变化与该特化相关,从而开发治疗肠道疾病的机会[25]。
建立这些模型需要有效的数据管理。实验室的过程可能会将人为因素注入数据集中,例如由于研究细胞是如何生长或收获而产生的批次效应,需要在分析数据之前从数据中删除这些效应。有效的数据校正可以维护生物学相关信息,同时去除数据中的噪音。校正数据的各种工具包括回归模型、降维方法、图方法和深度学习。为了让领域研究者能够识别对他们有用的工具,对确定最有效的数据集成方法的基准测试非常重要。然而,当存在复杂的分析流程时,如何评估系统的性能方面仍然存在问题。了解分析流程的端到端的本质是困难的,因此可能需要新的评估性能的方法。
为了理解大脑如何工作,神经科学家们开发了数学模型,描述了单个神经元的活动,以及它们如何在脑网络中相互连接。机制层面的模型采用微分方程的形式。这些模型基于实验数据,这些实验研究神经元如何响应不同的信号或扰动。为了从这些数据中建立计算模型,首先需要确定哪些因素影响神经元的行为,从而创建一组参数,决定模型如何工作。寻找参数的过程通常需要耗费大量时间和精力,依赖于试错,这限制了研究人员在复杂神经网络中扩展模型的能力。机器学习可以帮助简化模型定义过程,通过预测哪些模型更有可能与数据相容。通过自动识别模型参数,研究人员可以快速开发模拟复杂结构的模型,例如不同动物的大脑或神经系统 [27]。
科学是通过假设、观察和分析不断发展的。数百年来,研究人员通过收集数据、将这些观察结果压缩成一个模型,然后计算该模型以创建关于自然和物理现象以及这些现象所涉及系统的理论的表示,推动了知识的前沿。这些数学模型依赖于数值方法:帮助解决数学问题的算法,在没有解析解的情况下进行计算。如今,数据收集及其分析中涉及的基本计算任务——线性代数、优化、模拟等仍然是科学过程中的重要部分。然而,机器学习的进展已经改变了模型构建的方式。
AI for science提供了一种以数据为中心的建模和模拟方法。与许多学科中心的传统数学模型并行运行,机器学习提供了数据中心的分析方法,可以集成到科学流程中,例如实现对现实世界系统的复杂模拟。这些模拟可以用于信息模型开发、测试假设、确定研究重点,或者从复杂数据中揭示新的洞见。
模拟是科学发现的一种成熟工具。其基本任务是尽可能减少模拟与真实世界之间的差异,以允许对不同干扰的影响进行实验或测试,同时允许对系统进行一定程度的简化,并从模型中进行数据采样。有效的模拟器可以让研究人员从理论上理解数据应该是什么样子的。例如,粒子物理学、蛋白质折叠、气候科学等领域已经开发出使用已知理论和感兴趣的参数来预测研究系统的复杂模拟。AI for science可以加速其中一些工作,通过替代模型(surrogate models)实现。
AI for science早期围绕的是相反的过程,即:研究人员是否能够从许多研究领域可用的大量数据开始,并从数据中建立对潜在理论的理解?在给定一组观测值的情况下,是否可能找到模型的参数,使其模拟反映测量的数据?这种基于模拟的推理(simulation-based inference,SBI)提供了跨学科生成新见解的机会。
为了实现这种分析,需要能够以节省时间和计算的方式从高维、多模态数据中提取见解的机器学习方法。概率数值方法(probabilistic numerics)提供了一种方法,可以通过统计方法灵活地将来自机制模型和数据的信息组合起来,解决数值问题。为了创建有效的数据驱动模拟,需要平衡不同的模型特性。模型的参数必须足够细致地描述现实世界的系统,同时在分析和计算方面具有适应性的抽象层次。由于这种原因,几乎所有模型都是“错误”的或可证伪的,但是必须在一定程度上进行抽象,以便于分析。模拟还必须设计为具有鲁棒性,并能够生成与现实世界观察一致的推论。
AI for science 的激情源于期望通过利用数据来推进知识的前沿,揭示世界的新理解。虽然AI也有其自身的局限性,但科学界已经制定了一系列检验新知识的措施和平衡方法来维持科学探究的严谨性。近年来,机器学习社区出现了各种挑战或基准测试,这些测试成为了该领域算法在定义的任务上预期性能的标准。然而,这些标准不一定符合领域研究人员的期望[31]。随着数据中心模拟被纳入科学过程,机器学习研究人员必须考虑他们在维护被部署到其中的领域完整性方面的责任,这也提出了一个问题:需要什么保障措施才能确保研究人员可以对机器学习启用的模拟结果感到自信呢?
多样的诊断测试可以帮助解决这个问题。其中许多诊断测试的核心是分析模型是否具有计算准确性。简而言之:模拟所产生的推论应该反映出实验观测的推论[31]。检查这种一致性的一种方法是考虑从推论和观测数据集中推断的分布的一致性。如果模型匹配度高,那么它所生成的数据应该与通过实验观测到的数据大致相同。
这些诊断测试背后的一个根本问题是如何管理不确定性,尤其是在不同的失败模式有不同影响的情况下。简而言之:当模型失败时,对于其结果过于自信或过于保守,哪种情况更糟糕?在科学背景下,结果过于自信似乎更容易导致负面结果,无论是通过提供误导性的解释或结果,还是通过推动无果的研究方向。机器学习方法可以被设计为保守,减少假阳性的风险。
机器学习方法在推论和模型构建方面与领域科学家的做法可能存在差异。从领域的角度来看,模型构建是一个迭代过程,由专家的直觉和知识所引导,需要对研究对象系统有深入理解。机器学习研究已经开发出使用领域知识来塑造概率模型结构的实践方法,但领域直觉的细微差别通常在模型失败时才会显现。在构建有效的模拟中,定性输入是至关重要的,这需要来自领域社区的时间和精力的投入,通过互信、激励和长期关系建立实现协作。
机器学习模拟的有效部署严重依赖于计算工具。这些工具的设计和功能必须符合使用者社区的需求。设计匹配用户需求并在实践中有效的计算系统需要有效的软件工程和与领域专家的紧密协作,他们可以表达在该领域工作人员的需求和期望。为了确保长期有效性,这些系统必须使用有效的软件工程实践,包括嵌入版本控制和构建与其他模型和系统协作的接口。这些实践和相应的软件系统必须根据用户需求进行定制,并借鉴现有的软件工程最佳实践,同时也要适应反映部署领域的具体要求。
通常,机器学习需要明确表示似然函数,但这通常很难计算。为了让研究人员能够从数据中确定模型参数,需要进一步推进基于贝叶斯推断的技术。
• 无似然推断等技术可以增强现有的贝叶斯方法用于推断后验估计[32]。
• 建立代理模型,使用基于贝叶斯的仿真规划来优化信息增益,或部署仿真[35]也可以提高仿真效率。
• 概率数值法提供了一种发展统计优化算法的途径,可适用于综合不确定性量化,利用基于高斯过程的常微分方程求解器将仿真作为推断问题进行研究[36]。
推广这些方法还需要新的工具包来支持概率数值方法的实现。
通过以下方式,可以实现计算精度的一致性,即推断的参数与科学知识的对齐:
• 在贝叶斯联合分布的自一致性诊断中,可以测量贝叶斯 SBI 方法计算的区域的科学质量[31,38]。检查自一致性可以判断模型是否“足够好”(即推断引擎是否能够给出后验的良好感知)。
• 通过二分类器规范实施保守神经比率估计,产生更保守的后验近似值[39]。
• 混合建模将从数据中学习的机器学习组件与现有领域知识指定的机制组件相结合[40]。
• 进一步研究模型错误规范的影响,也有助于生成新的鲁棒性诊断检查[41]。
数字孪生作为利用成熟的模拟技术的一种工具也受到了广泛的关注。它的挑战来自于整合系统中不同的模型或模块。为了交付有效的结果,什么样的颗粒度是有帮助的或者有必要的以及在不同的模型之间有哪些可能的界面。
大多数科学研究都涉及因果关系:研究人员希望了解系统如何运作,为什么它以这种方式运作,以及在受干扰时会发生什么。研究人员如何确定因果关系的方式因学科而异。对于一些学科,假设设计 – 数据收集 – 模型开发的过程构成了研究系统运作方式的核心结构。而在其他学科,由于实验更加困难,研究人员可能依赖自然实验和观察来比较系统在不同条件下的响应。例如,研究地球系统的学者几乎无法复制行星条件,因此他们依赖观测数据和建模来确定不同干预措施的影响。不过,这些不同的方法在建模方法上都有所共同之处,即研究人员提供变量以创建结构性因果模型。
相比之下,机器学习通过从数据中学习表示或规则,基于统计信息而不是关于系统如何运作的结构化规则(例如物理定律),来进行模型构建。因果推断——识别数据中的因果关系的能力——一直是人工智能研究的核心目标,旨在为复制机器智能和创建能够在实际部署中稳健工作的AI系统提供支持。然而,在很多方面,将因果推断融入AI系统的努力尚未取得成果[43]。
因果模型作为路线驱动 science of AI 和 AI for science
许多机器学习方法在诊断因果关系时出现错误,这些错误源于许多机器学习方法的核心假设:数据遵循独立同分布(IID)。实际上,几乎所有来自现实世界或复杂系统的数据都会违反这种假设,因为不同变量之间存在相互联系。因果机器学习的任务是创建能够处理这种违反的模型,区分简单共同出现的数据模式和具有因果关系的数据模式。由此产生的AI系统能够基于对系统的基本因果机制的理解,在许多不同的环境中解决任务[47]。这样的系统在部署中更具鲁棒性,随着它们所处的环境的变化,预测错误的可能性较小,并且可以更高效地进行训练和部署。这些系统还代表了向复制类似于人类或动物的智能的一步,因为它们能够在许多不同的环境中解决任务。
因果机器学习提供了一条平衡统计建模的广泛效用和物理模型优点的途径。因果性允许模型在强机制方法(例如基于微分方程的方法)之外的抽象层面上操作,从机制建模向数据驱动建模的连续移动。它们提供了在数据集转移条件下进行准确预测的能力(实现分布外的泛化),可以提供有关驱动系统行为的物理过程的洞察,解锁了朝向“思考”的AI系统的进展,即在想象空间中进行操作。同时,它们利用可以从数据中学习但无法通过其他方式检测到的见解。这些系统还提供了探索复杂系统中反事实情况的机会,询问不同干预的影响可能是什么,从而打开了发展基于模拟的决策工具的大门。
为实现这一潜力,需要在多个方向上进行技术发展,但也能够产生更有效的AI系统。这样的系统将具备以下特点:
• 能够在分布之外的数据上进行操作,在具有不同条件的环境中执行其训练任务。
• 能够基于相对较少数量的任务示例及其不同条件中的表现,或通过传递、一次性或终身学习方法,快速适应学习并将其应用到新环境中。
• 支持用户分析不同干预措施对系统的影响,并提供解释或归因于不同行动的方式。
对不同的信息传递方式做出反应,使其能够与用户或其他形式的文化学习有效地交流。
达到因果建模所需的技术精度水平需要仔细的模型设计,基于机器学习和领域科学家之间的紧密合作。因果机器学习可以成为促进更深层次的跨学科合作的积极因素。然而,所需的细节水平也可能与促进AI方法在研究领域的广泛应用的努力产生张力。该领域面临的挑战之一是通过开源工具包或有效的软件工程实践使这些方法更广泛地可用。
规范和学习之间的这种张力也凸显了培育从数据驱动到机制建模全谱方法的多样性的重要性。领域(即可用的先验知识量和应该包含哪些知识)、研究问题的兴趣以及其他实际因素(包括计算预算)将决定研究人员希望将建模工作沿着哪些范围展开。
在追求实际应用的同时,因果推断的进展可以帮助回答关于智能本质和因果表达在人类对世界运作的理解中所扮演角色的更广泛问题。人类对世界的理解大部分来源于观察因果关系;也就是看到一种干预后会产生什么反应。将这种能力融入机器学习中将有助于创建可应用于各种任务的系统。构建因果机器学习的过程迫使研究人员审视因果表达的本质。这一过程可能进而支持AI科学的更广泛进展。
因果性在机器学习中是一个长期而复杂的挑战。在科学发现的背景下,学习策略、模型设计和编码领域知识都在帮助识别因果关系方面发挥作用。不同的学习策略可以提高机器学习的泛化能力,从而增强其在以前未见过的任务上的性能,通过以贡献更广泛的因果理解的方式学习任务或环境的潜在结构。这些学习策略包括:
• 迁移学习,将一个任务或领域的学习应用到另一个任务或领域。
• 多任务学习,使系统能够在多个环境中解决多个任务。
• 对抗性学习,以减少模型在分布外数据上性能降低的脆弱性。
• 因果表示学习,定义由因果模型相关的变量[46]。
• 基于不变性的策略识别的强化学习,通过奖励主体根据不同条件下的不变性来识别策略。
在这些新的学习方法中,尝试建立因果机制也促进了机器学习理论的进展,通过核心原则的统计制定来推动进步[49]。组合不同的方法也可以增强AI系统的功能。例如:
• 已经证明,Neural ODEs 能够识别时间序列数据中的因果结构[50]。
• 在受约束的优化问题中将因果效应描述为目标函数,可以提供一种随机因果编程形式[51]。
• 技术干预[52]可以限制或优化模型以实现因果结果。与模拟设计一样,通过将模型输出与现实标准进行比较来检查模型输出,也可以帮助识别因果关系。此外,还有各种方法来在机器学习模型中表示现有的科学知识,特别是通过对世界做出的假设进行对称、不变性和物理定律的表示(见下图)。

图1. 模型沿着从经典的 i.i.d 模型到强机制的微分方程模型展开,通过引入因果和对称性来创建一个在机制世界和数据驱动世界的连续体。统计模型或者数据驱动的模型是弱机制模型。
人们长期以来一直想象AI可以成为一位忠实的仆人,减轻人类的负担或增强人类的能力[54]。然而,实际部署AI时,往往会出现各种潜在的失败模式,这些问题通常源于对环境了解不足、用户需求设定错误或对环境动力学的误解[55]。今天的科学可以利用人类数千年来理解世界的基础来设计服务于科学目标的AI,以实现人类和机器的合作。为实现人类和机器之间的协作,需要将领域知识有效地整合到AI系统中,可以采用算法设计、实验室中的AI整合以及有效的沟通和协作三种策略[54]。
传统建模方法利用明确定义的规则或方程来解释所研究系统的动力学。例如,物理定律描述能量如何基于守恒原理在系统中传递。这些定律由数学对称性所补充,对称性源自我们对物理对象的抽象表达,并描述了一个对象的哪些特征在系统的变化或转换中保持一致。此外,系统中可能存在已知的不变量:在任何扰动下都不变或以一定方式改变的因素。在这些现有知识的基础上,结合机器学习生成对世界因果理解的努力,越来越多地关注的是设计尊重这些规则或对称性的机器学习模型的领域。
支持这种设计策略的原则是,可以从统计(数据驱动)模型向强机制模型的方向移动,创建混合系统,其输出应受到物理可行性的约束,同时也可以利用来自数据的洞见(见图2)。
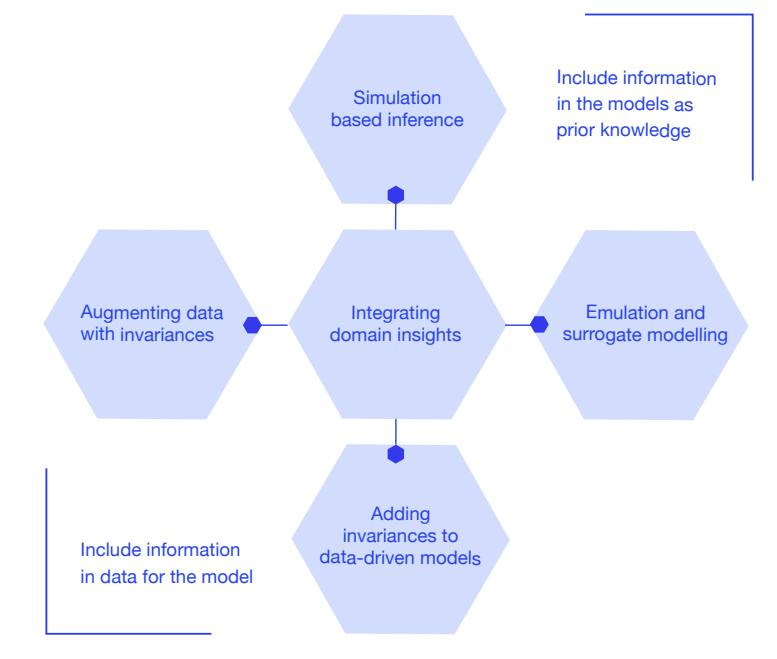
图2. 整合领域洞察的策略:将信息包含到数据中,以及包含信息作为先验知识。
在该连续体的一端,机制模型将以强烈的确定性方式遵守已知的法律或原则;在另一端,统计模型编码更少的假设,更多地依赖于数据[58]。除了其他形式的领域知识之外,不变量和对称性的添加可以使这两个模型类之间建立联系。例如,描述在气候变化条件下海洋吸收多少热量的模型应遵守热力学和能量守恒定律。通过编码这些基本定律的领域知识,如动量或能量的守恒,研究人员可以确保机器学习模型的输出具有物理上可允许的表达式。这种编码可以通过将方程式、对称性或不变量整合到模型设计中来实现。这些编码将机器学习系统的操作限制为与物理系统的已知动力学相一致。预计由此产生的模型将产生更准确的结果,具有更小的泛化误差,并具有更好的分布外泛化能力。
补充建模策略来编码科学知识是在实验室中使用AI的部署策略。实验室长期以来一直是协作和知识生成的物理中心,实验设备和过程的数字化为将AI整合到实验设计和建立虚拟实验室提供了机会[58]。通过结合来自测量设备、实验室过程模拟和计算模型的数据,虚拟实验室提供了用于优化的研究活动的数字平台。例如,在药物发现中,虚拟实验室可以加速测试和分析过程,从潜在药物靶点中识别候选药物[59]。
机器学习方法的进步,包括有效的模拟、因果建模和现有领域洞见的编码,以及将这些方法打包成可用的工具包,都是数字平台的必要基础。将虚拟实验室转向“AI助手”需要进一步的AI系统设计进步,以创建可以征询其领域专家的指导或输入的AI主体。这些AI助手将结合模拟研究问题的能力和模拟其专家用户的目标和偏好的能力。这首先需要用户的交互来提取用户知识,同时需要从认知科学、团队决策制定的研究和基于有限样例的新学习策略中获得洞见,解锁AI和人类之间的新形式的协作 [60]。
机器学习模型需要与应用领域形成反馈循环,这需要跨学科的合作和沟通交换知识和见解。为了让机器学习在科学领域应用,模型的输出需要反馈到领域研究人员中。为了理解这些输出的意义,需要一定程度的可解释性。AI研究人员已经开发了不同的方法来询问AI系统如何工作,或者为什么产生特定的输出。为了理解这些方法中哪些是想要的,研究者与领域专家的密切合作是关键。例如在制药实验中,在更加严格地研究特定药物之前,可以通过“感性检查”不同药物剂量对模型的影响。在天文研究中,需要考虑数据集下的结构,并使用已经反映相关物理规律的确定性模型。在这些方法中,软件包在交流和方法传播方面发挥着重要作用,以供更广泛的使用[61-63]。
新的建模方法和数学创新为将领域知识、对称性和不变性整合到AI系统中提供了机会。这种整合可以通过数据增强、对称性嵌入深度学习系统设计、潜在力模型、架构特征、损失函数和量化性能提升等方式实现。开发实验室中的AI助手的研究引发了有关学习策略和人机协作的问题,需要谨慎设计人类和AI系统之间的交互点。对于人机交互的意外后果、用户需要哪些解释或可解释性、心理理论以及如何从相关专家那里提取领域知识并将其整合到机器学习模型中都是需要考虑的问题。[64-66,70-72]
AI for science是处于多个学科、方法和社群的交汇处。AI和科学(广义定义)都对从数据中学习感兴趣。这种兴趣导致了不同的研究方向:对于AI,问题在于智能的本质以及如何理解人类和机器学习过程;对于科学,这个学习过程的输出是重点,旨在增加有关自然、物理和社会系统的新知识。AI for science 新议程的一个独特特征是能够在这些世界之间移动,利用AI推动科学进步,并从科学中汲取灵感来促进人工智能的进步。结果是在一个从强机制模型到统计模型的模型方法的连续体上移动,允许研究人员在不同的抽象级别上引入或操作。
因此,AI for science社区将人工智能研究的雄心与特定领域的目标相结合,以设计在不同尺度(从纳米到星际)上运行的系统,推动研究和创新的前沿。从这些接口中涌现出研究议程,如果成功,将加速跨学科进展。
1)构建科学AI系统:在科学探索的背景下部署AI的尝试揭示了当前机器学习和AI能力的一系列差距。需要进一步开展工作,开发技术能力,使AI在研究和创新中更有效地使用;开发这些能力还提供了机会,为实现复杂的AI系统做出贡献。进展领域包括:
• 推进高质量模拟和仿真的方法、软件和工具包,这些方法集成了有效的不确定性量化,并利用机器学习健壮性的进展,以确保其安全有效地运行。
• 通过因果机器学习的进展,检测数据中的科学意义结构。
• 通过将科学定律、原理、对称性或不变性集成到机器学习模型中,并通过虚拟自主系统使研究更加有效,来将领域知识编码到人工智能系统中。
2)将AI和机器智能结合起来:在科学领域中有效地部署AI需要在部署路径的所有阶段上实现人类、领域和机器智能之间的有效交互。通过整合关于研究系统的预先存在的知识,可以使AI系统更加有效,但需要机制来提取和编码这些知识。相反方向也需要有效的接口。将AI分析的结果转化为增强人类能力,需要理解哪些见解是相关的,如何最好地进行交流,以及塑造科学行为的文化环境。进展领域包括:
•设计人与机器或AI主体之间的接口,可以提取、形式化和吸收领域研究人员已经获得的知识,包括暗示性知识,并将新知识作为可操作见解传达给用户。
•构建解释性机制,允许研究人员查询为什么以及AI系统是如何提供了特定的结果,所提供的解释应根据用户需求进行调整。
•通过挖掘现有的研究知识库或自动化研究过程中的重复或耗时元素的系统,加快知识创造和使用的速度。
3)影响实践和采用:通过学习最近在科学中部署AI的经验,该领域有机会促进科学领域和AI研究的更广泛采用和进步。这需要捕捉社区已经生成的关于如何设计AI系统的知识,以及伴随着如何克服实际挑战的实践技能,同时采取行动,扩大对潜在的AI在科学中应用的研究人员社区的兴趣。进展的领域包括:
• 通过挑战导向的研究计划支持新应用,促进跨学科合作,支持共同设计AI系统,帮助解决科学难题。
• 开发工具包和用户指南,使研究人员了解哪些AI工具适用于哪些目的,并了解如何在实践中部署这些工具。
• 通过社区外展共享技能和实践经验,传播使用AI的知识和技能。
这些领域的行动强调塑造 AI for Science 发展的接口(研究人员之间和建模方法之间)的重要性(见图3)。
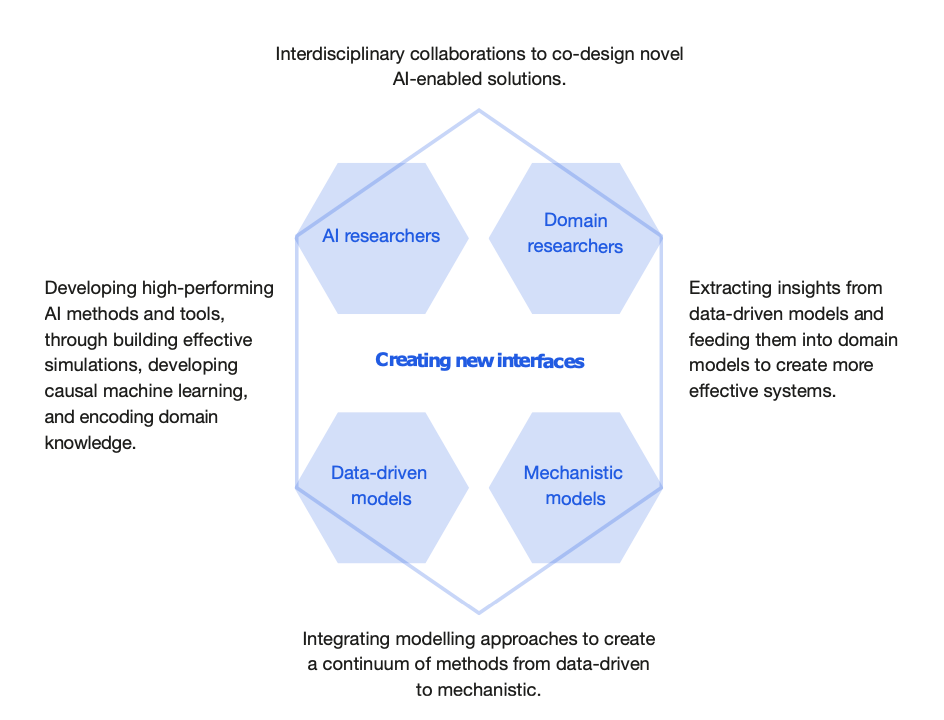
图3. 机器学习和专家研究者之间的接口,数据驱动和机制模型之间的接口。
机器学习已经在许多领域取得惊人进展,广泛采用AI进行研究具有催化新一波创新的潜力,从而推动健康、财富和福祉。今天面临的问题是研究人员、资助者和政策制定者如何利用这一潜力。挑战在于在研究领域建立能力,将专业领域与需求领域连接起来,并加速在领域之间成功的想法的转移。
本文中描述的部署AI for Science的经验以及由这些经验产生的研究议程提供了一个行动路线图。这个路线图为创建一个支持AI in Science的环境制定了一条路径,通过推进为支持科学发现提供AI的研究、建立使AI易于使用的工具和资源、倡导跨学科研究以及从事这些研究的人,并在这些不同领域的交叉地带培养社区。在这些领域的进展可以释放科学和方法上的AI进步,同时也有助于回答一个新兴问题,即是否存在一种“AI for Science”的核心学科。从AI和科学领域交叉的研究项目中出现的共享主题和兴趣表明,“AI for Science”有潜力成为计算机科学中一个独特的专业领域。同时,领域特定的努力推动采用AI作为创新的推动因素,以实现AI在科学发现中的优势。
在研究的背景下部署人工智能的努力,凸显出跨领域的挑战,需要在AI方法和理论方面进一步取得进展,以创建可以在科学环境中更可靠、更有效使用的工具。需要有效的模拟来研究复杂系统的动力学;因果方法来理解这些动力学为何出现;以及整合领域知识,将这些理解与更广泛的世界联系起来。虽然这些研究挑战的某些元素与其他领域共享——例如稳健性、可解释性和人机交互等主题也在AI伦理等领域中引起了关注——但也与AI for Science交叉,这是在努力连接机制和数据驱动建模方面的背景下出现的。
定义共同的挑战可以帮助建立AI for science联盟社区,推动AI在科学方法和应用方面的进展。已经存在了这样通过挑战建立跨领域的研究联盟,从中领域可以获得灵感的例子。其中包括GREAT08项目,该项目开发了图像分析技术,用于研究引力透镜现象[73];Single Cell Biology中的开放问题挑战,召集了机器学习社区以在多模态单细胞数据整合方面取得进展[36];以及SENSORIUM挑战,重点是推进人们对大脑如何处理视觉输入的理解[37]。在追求这个议程的过程中,研究人员可以利用公开材料和共享文档的成熟协议,以确保研究进展能够快速而有效地在学科之间传播。结果应该是更有效的方法,以及一个敏捷的研究环境,让研究人员可以在不同的学科之间灵活运用方法。
为了建立和共享知识,设计良好的软件工具可以帮助人们学习AI科学项目成功所需的技艺和知识。建模是所有AI for science的核心组成部分。在某些方面,该领域的任务可以被认为是在统计学家和数学家之间寻找一条路径。统计学家的有效性来自于接近领域,但其方法难以扩展;数学家的工具被跨领域采用,但是随着方法生成者和采用者之间的距离增加,方法的意义会有所损失。
已经投资于构建有效的机器学习模型的努力可以通过投资于支持有效方法普及的工具包放大,为跨领域的进步提供支持。广谱建模工具可以提供常见AI for science的现成解决方案。这样的工具包面临的挑战是在工具和用户之间创建有效的界面。与人机交互领域相联系可以产生设计见解或协议,以帮助创建更有效的人工智能界面。
这些基础工具和资源的投资可以帮助人们了解哪些AI方法可以用于什么目的,降低跨学科采用AI方法的障碍。
对于研究和工具工程的进展而言,拥有对通过AI推动科学发展充满热情的优秀研究人员至关重要。在AI的开发和部署过程中,人的作用都是至关重要的。成功的项目依赖于那些积极参与不同领域交流的研究人员;能够在跨学科边界上解释和交流核心概念的合作者;能够将不同用户需求转化为AI工具包的工程师;以及能够激发更广泛的AI科学参与的召集人。
以上所述的行动领域相互关联且相互促进。研究和应用的进展可以激励一代研究人员去追求跨学科项目;有效的工具包可以使这种进展更有可能;技能培养计划可以让研究人员有能力使用这些工具包等等,从而创造一个研究人员和研究进展在学科之间平稳过渡的环境,从而带动所有学科的人工智能浪潮不断上升。研究和实践社区是创造这种积极反馈循环的背景。
AI技术的进步打破了传统科学建模方式的思维模式。以往,研究人员可能将模型概念化为机制式的——反映世界上已知的力量,或数据驱动的,而今天出现的AI for Science方法则摒弃了这种分离的想法。它们是两者兼顾,融合了机制和数据驱动的方法,创造出了新的东西。从这些发展中可以得出一系列建模方法,研究人员可以灵活运用,以回答感兴趣的研究问题。
今天,AI在科学领域的应用表现出交叉的特征。它在AI和科学领域之间,科学和工程之间,知识和技能之间,人类和机器之间相互交融。它跨越学科边界,涵盖从原子尺度到宇宙尺度,不仅追求理解智能的使命,还努力利用人类智慧来认识世界。从这些使命中催生出一系列模型和方法,使得研究人员能够跨越领域进行工作,提取人类已经掌握的知识,以及进行深入探究,增强这些知识并将其返回为可操作的形式。
作为一种领域和其他学科的推动者,AI在科学中的力量在于其能够以一种加速各个研究领域进展的方式召集不同的观点。AI为科学提供了一个交汇点。它的下一个发展浪潮将来自于从其多样性中获得力量,并将更多的人纳入其社区。
[1] Horst W. J. Rittel and Melvin M. Webber. Dilemmas in a general theory of planning. Policy sciences, 4(2):155–169, 1973. Reprinted in N. Cross, ed. Developments in design methodology, pp. 135–44. Chichester: J. Wiley & Sons, 1984.
[2] Tim Summers, Erik Mackie, Risa Ueno, Charles Simpson, J. Scott Hosking, Tudor Suciu, Andrew Coburn, and Emily Shuckburgh. Localized impacts and economic implications from high temperature disruption days under climate change. Climate Resilience and Sustainability, 1(2):e35, 2022.
[3] Christian Beer, Markus Reichstein, Enrico Tomelleri, Philippe Ciais, Martin Jung, Nuno Carvalhais, Christian R¨odenbeck, M. Altaf Arain, Dennis Baldocchi, Gordon B. Bonan, A. Bondeau, A. Cescatti, G. Lasslop, A. Lindroth, M. Lomas, S. Luyssaert, H. Margolis, K. W. Oleson, O. Roupsard, E. Veenendaal, N. Viovy, C. Williams, F. I. Woodward, and D. Papale. Terrestrial gross carbon dioxide uptake: global distribution and covariation with climate. Science, 329(5993):834–838, 2010.
[4] Ren´ee M. Marchin, Diana Backes, Alessandro Ossola, Michelle R. Leishman, Mark G. Tjoelker, and David S. Ellsworth. Extreme heat increases stomatal conductance and drought-induced mortality risk in vulnerable plant species. Global Change Biology, 28(3):1133–1146, 2022.
[5] Christian Requena-Mesa, Markus Reichstein, Miguel Mahecha, Basil Kraft, and Joachim Denzler. Predicting landscapes from environmental conditions using generative networks. In Pattern Recognition: 41st DAGM German Conference, DAGM GCPR 2019, Dortmund, Germany, September 10–13, 2019, Proceedings 41, pages 203–217. Springer, 2019.
[6] IPCC. IPCC special report on the ocean and cryosphere in a changing climate. IPCC Intergovernmental Panel on Climate Change: Geneva, Switzerland, 2019.
[7] NASA. Understanding sea level,. available from: https://sealevel.nasa.gov/ understanding-sea-level/global-sea-level/ice-melt.
[8] Dina Machuve, Ezinne Nwankwo, Neema Mduma, and Jimmy Mbelwa. Poultry diseases diagnostics models using deep learning. Frontiers in Artificial Intelligence, page 168, 2022.
[9] H. Ritchie and M. Roser. Forests and deforestation. Published online at OurWorldInData.org, https://ourworldindata.org/forests-and-deforestation, 2021.
[10] Martin Brandt, Compton J. Tucker, Ankit Kariryaa, Kjeld Rasmussen, Christin Abel, Jennifer Small, Jerome Chave, Laura Vang Rasmussen, Pierre Hiernaux, Abdoul Aziz Diouf, Laurent Kergoat, Ole Mertz, Christian Igel, Fabian Gieseke, Johannes Sch¨oning, Sizhuo Li, Katherine Melocik, Jesse Meyer, Scott Sinno, Eric Romero, Erin Glennie, Amandine Montagu, Morgane Dendoncker, and Rasmus Fensholt. An unexpectedly large count of trees in the west african sahara and sahel. Nature, 587(7832):78–82, 2020.
[11] Pierre Hiernaux, Hassane Bil-Assanou Issoufou, Christian Igel, Ankit Kariryaa, Moussa Kourouma, J´erˆome Chave, Eric Mougin, and Patrice Savadogo. Allometric equations to estimate the dry mass of sahel woody plants mapped with very-high resolution satellite imagery. Forest Ecology and Management, 529:120653, 2023. 36
[12] Luis Hernandez-Triana and Ssuzanna Bell. Taking the sting out of vector borne diseases. APHA Science Blog, available at: https://aphascience.blog.gov.uk/2022/07/06/ vector-borne-diseases/, 2022.
[13] John Quinn. Mapping africa’s buildings with satellite imagery. Google Research Blog, available at: https://ai.googleblog.com/2021/07/mapping-africas-buildings-with. html, 2021.
[14] Steve W Lindsay, Musa Jawara, Julia Mwesigwa, Jane Achan, Nabie Bayoh, John Bradley, Balla Kandeh, Matthew J. Kirby, Jakob Knudsen, Mike Macdonald, et al. Reduced mosquito survival in metal-roof houses may contribute to a decline in malaria transmission in sub-saharan africa. Scientific reports, 9(1):7770, 2019.
[15] Royal Danish Academy. New research to combat malaria mosquitoes in african metropolises. Available at: https://royaldanishacademy.com/news/ ny-forskning-skal-bekaempe-malariamyg-i-afrikanske-storbyer, 2022. [16] NASA. Dark energy, dark matter. Available at: https://science.nasa.gov/ astrophysics/focus-areas/what-is-dark-energy. Last accessed March 4th 2023.
[17] The ATLAS Collaboration et al. The ATLAS experiment at the CERN large hadron collider. Jinst, 3:S08003, 2008.
[18] Siddharth Mishra-Sharma and Ge Yang. Strong lensing source reconstruction using continuous neural fields. Technical report, 2022.
[19] Cora Dvorkin, Siddharth Mishra-Sharma, Brian Nord, V. Ashley Villar, Camille Avestruz, Keith Bechtol, Aleksandra Ciprijanovi´c, Andrew J. Connolly, Lehman H. Garrison, ´ Gautham Narayan, and Francisco Villaescusa-Navarro. Machine learning and cosmology. Technical report, 2022.
[20] Fumiyasu Makinoshima and Yusuke Oishi. Crowd flow forecasting via agent-based simulations with sequential latent parameter estimation from aggregate observation. Scientific Reports, 12(1):1–13, 2022.
[21] Nicolas Malleson, Kevin Minors, Le-Minh Kieu, Jonathan A. Ward, Andrew West, and Alison Heppenstall. Simulating crowds in real time with agent-based modelling and a particle filter. Journal of Artificial Societies and Social Simulation, 23(3):3, 2020.
[22] Francisco Vargas, Pierre Thodoroff, Austen Lamacraft, and Neil D. Lawrence. Solving schr¨odinger bridges via maximum likelihood. Entropy, 23(9):1134, 2021.
[23] K. V. Krishnamurthy, Bir Bahadur, S. John Adams, and Padma Venkatasubramanian. Development and organization of cell types and tissues. Plant Biology and Biotechnology: Volume I: Plant Diversity, Organization, Function and Improvement, pages 73–111, 2015.
[24] Laleh Haghverdi, Maren B¨uttner, F. Alexander Wolf, Florian Buettner, and Fabian J. Theis. Diffusion pseudotime robustly reconstructs lineage branching. Nature methods, 13(10):845–848, 2016.
[25] Anika B¨ottcher, Maren B¨uttner, Sophie Tritschler, Michael Sterr, Alexandra Aliluev, Lena Oppenl¨ander, Ingo Burtscher, Steffen Sass, Martin Irmler, Johannes Beckers, Christoph Ziegenhain, Wolfgang Enard, Andrea C. Schamberger, Fien M. Verhamme, Oliver Eickelberg, Fabian J. Theis, and Heiko Lickert. Non-canonical Wnt/PCP signalling regulates intestinal stem cell lineage priming towards enteroendocrine and paneth cell fates. Nature cell biology, 23(1):23–31, 2021. 37
[26] Malte D. Luecken, Maren B¨uttner, Kridsadakorn Chaichoompu, Anna Danese, Marta Interlandi, Michaela F. M¨uller, Daniel C Strobl, Luke Zappia, Martin Dugas, Maria Colom´e-Tatch´e, and Fabian J. Theis. Benchmarking atlas-level data integration in single-cell genomics. Nature methods, 19(1):41–50, 2022.
[27] Pedro J Gon¸calves, Jan-Matthis Lueckmann, Michael Deistler, Marcel Nonnenmacher, Kaan Ocal, Giacomo Bassetto, Chaitanya Chintaluri, William F Podlaski, Sara A. Haddad, ¨ Tim P. Vogels, David S. Greenberg, and Jakob H. Macke. Training deep neural density estimators to identify mechanistic models of neural dynamics. eLife, 9:e56261, 2020.
[28] David M. Blei. Build, compute, critique, repeat: Data analysis with latent variable models. Annual Review of Statistics and Its Application, 1:203–232, 2014.
[29] Kyle Cranmer, Johann Brehmer, and Gilles Louppe. The frontier of simulation-based inference. Proceedings of the National Academy of Sciences, 117(48):30055–30062, 2020.
[30] Philipp Hennig, Michael A. Osborne, and Hans P. Kersting. Probabilistic Numerics: Computation as Machine Learning. Cambridge University Press, 2022.
[31] Joeri Hermans, Arnaud Delaunoy, Fran¸cois Rozet, Antoine Wehenkel, and Gilles Louppe. A trust crisis in simulation-based inference? your posterior approximations can be unfaithful. Technical report, 2021.
[32] Justin Alsing, Tom Charnock, Stephen Feeney, and Benjamin Wandelt. Fast likelihoodfree cosmology with neural density estimators and active learning. Monthly Notices of the Royal Astronomical Society, 488(3):4440–4458, 07 2019.
[33] Alexander Lavin, Hector Zenil, Brooks Paige, David Krakauer, Justin Gottschlich, Tim Mattson, Anima Anandkumar, Sanjay Choudry, Kamil Rocki, Atılım G¨une¸s Baydin, et al. Simulation intelligence: Towards a new generation of scientific methods. Technical report, 2021.
[34] Kyle Cranmer, Lukas Heinrich, Tim head, and Gilles Louppe. Active sciencing. Available from https://github.com/cranmer/active_sciencing, 2017.
[35] Jan Boelts, Jan-Matthis Lueckmann, Richard Gao, and Jakob H. Macke. Flexible and efficient simulation-based inference for models of decision-making. eLife, 11:e77220, 2022.
[36] Hans Kersting. Uncertainty-Aware Numerical Solutions of ODEs by Bayesian Filtering. PhD thesis, Eberhard Karls Universit¨at T¨ubingen, 2021.
[37] Jonathan Schmidt, Nicholas Kr¨amer, and Philipp Hennig. A probabilistic state space model for joint inference from differential equations and data. Advances in Neural Information Processing Systems, 34:12374–12385, 2021.
[38] Siddharth Mishra-Sharma. Inferring dark matter substructure with astrometric lensing beyond the power spectrum. Machine Learning: Science and Technology, 3(1):01LT03, 2022.
[39] Arnaud Delaunoy, Joeri Hermans, Fran¸cois Rozet, Antoine Wehenkel, and Gilles Louppe. Towards reliable simulation-based inference with balanced neural ratio estimation. Technical report, 2022.
[40] Antoine Wehenkel, Jens Behrmann, Hsiang Hsu, Guillermo Sapiro, Gilles Louppe, and J¨orn-Henrik Jacobsen. Robust hybrid learning with expert augmentation. Technical report, 2022.
[41] Patrick Cannon, Daniel Ward, and Sebastian M. Schmon. Investigating the impact of model misspecification in neural simulation-based inference. Technical report, 2022. 38
[42] European Commission. Destination Earth – new digital twin of the Earth will help tackle climate change and protect nature. Available at https://ec.europa.eu/commission/ presscorner/detail/en/IP_22_1977, 2022.
[43] Bernhard Sch¨olkopf, Francesco Locatello, Stefan Bauer, Nan Rosemary Ke, Nal Kalchbrenner, Anirudh Goyal, and Yoshua Bengio. Toward causal representation learning. Proceedings of the IEEE, 109(5):612–634, 2021.
[44] Johannes Rueckel, Lena Trappmann, Balthasar Schachtner, Philipp Wesp, Boj Friedrich Hoppe, Nicola Fink, Jens Ricke, Julien Dinkel, Michael Ingrisch, and Bastian Oliver Sabel. Impact of confounding thoracic tubes and pleural dehiscence extent on artificial intelligence pneumothorax detection in chest radiographs. Investigative Radiology, 55(12):792–798, 2020.
[45] Jesse Emspak. How a machine learns prejudice. Scientific American Blogs, available at: https://www.scientificamerican.com/article/ how-a-machine-learns-prejudice/, 2016.
[46] Bernhard Sch¨olkopf. Causality for machine learning. In Probabilistic and Causal Inference: The Works of Judea Pearl, pages 765–804. 2022.
[47] Jonas Peters, Dominik Janzing, and Bernhard Sch¨olkopf. Elements of Causal Inference: Foundations and Learning Algorithms. The MIT Press, Cambridge, MA, USA, 2017.
[48] Atalanti Mastakouri and Bernhard Sch¨olkopf. Causal analysis of covid-19 spread in germany. Advances in Neural Information Processing Systems, 33:3153–3163, 2020.
[49] Siyuan Guo, Viktor T´oth, Bernhard Sch¨olkopf, and Ferenc Husz´ar. Causal de Finetti: On the identification of invariant causal structure in exchangeable data. Technical report, 2022.
[50] Hananeh Aliee, Fabian J. Theis, and Niki Kilbertus. Beyond predictions in neural odes: Identification and interventions. Technical report, 2021.
[51] Kirtan Padh, Jakob Zeitler, David Watson, Matt Kusner, Ricardo Silva, and Niki Kilbertus. Stochastic causal programming for bounding treatment effects. Technical report, 2022.
[52] Martin Emil Jakobsen and Jonas Peters. Distributional robustness of k-class estimators and the pulse. The Econometrics Journal, 25(2):404–432, 2022.
[53] Michael Stadler and Peter Kruse. Uber Wirklichkeitskriterien ¨ . Suhrkamp, Frankfurt am Main, Germany, 1990.
[54] The Royal Society. Ai narratives: portrayals and perceptions of artificial intelligence and why they matter. Available at: https://royalsociety.org/topics-policy/projects/ ai-narratives/, 2018.
[55] Andrei Paleyes, Raoul-Gabriel Urma, and Neil D. Lawrence. Challenges in deploying machine learning: a survey of case studies. ACM Computing Surveys, 55(6):1–29, 2022.
[56] Soledad Villar, David W. Hogg, Kate Storey-Fisher, Weichi Yao, and Ben Blum-Smith. Scalars are universal: Equivariant machine learning, structured like classical physics. Advances in Neural Information Processing Systems, 34:28848–28863, 2021.
[57] Julia Ling, Reese Jones, and Jeremy Templeton. Machine learning strategies for systems with invariance properties. Journal of Computational Physics, 318:22–35, 2016.
[58] Neil D. Lawrence. Introduction to learning and inference in computational systems biology. In Neil D. Lawrence, Mark Girolami, Magnus Rattray, and Guido Sanguinetti, editors, Learning and Inference in Computational Systems Biology, chapter 1. MIT Press, Cambridge, MA, 2010. 39
[59] Arto Klami, Theodoros Damoulas, Ola Engkvist, Patrick Rinke, and Samuel Kaski. Virtual laboratories: Transforming research with ai. Technical report, 2022.
[60] Mustafa Mert C¸ elikok, Frans A. Oliehoek, and Samuel Kaski. Best-response bayesian reinforcement learning with bayes-adaptive pomdps for centaurs. In International Conference on Autonomous Agents and Multi-Agent Systems (AAMAS) 2022, 2022.
[61] NASA. What is a gravitational wave? Available at: https://spaceplace.nasa.gov/ gravitational-waves/en/.
[62] Maximilian Dax, Stephen R. Green, Jonathan Gair, Jakob H. Macke, Alessandra Buonanno, and Bernhard Sch¨olkopf. Real-time gravitational wave science with neural posterior estimation. Phys. Rev. Lett., 127:241103, Dec 2021.
[63] Erik Bodin, Zhenwen Dai, Neill Campbell, and Carl Henrik Ek. Black-box density function estimation using recursive partitioning. In International Conference on Machine Learning, volume 139, pages 1015–1025. PMLR, 2021.
[64] Soledad Villar, Weichi Yao, David W Hogg, Ben Blum-Smith, and Bianca Dumitrascu. Dimensionless machine learning: Imposing exact units equivariance. Technical report, 2022.
[65] Mauricio A. Alvarez, David Luengo, and Neil D. Lawrence. Linear latent force models ´ using Gaussian processes. TPAMI, 35(11):2693–2705, 5 2013.
[66] Wil Ward, Tom Ryder, Dennis Prangle, and Mauricio Alvarez. Black-box inference for non-linear latent force models. In International Conference on Artificial Intelligence and Statistics, volume 108, pages 3088–3098. PMLR, 2020.
[67] Risi Kondor and Shubhendu Trivedi. On the generalization of equivariance and convolution in neural networks to the action of compact groups. In International Conference on Machine Learning, volume 80, pages 2747–2755. PMLR, 2018.
[68] Haggai Maron, Heli Ben-Hamu, Nadav Shamir, and Yaron Lipman. Invariant and equivariant graph networks. Technical report, 2018.
[69] Nadav Dym and Haggai Maron. On the universality of rotation equivariant point cloud networks. Technical report, 2020.
[70] Iiris Sundin, Tomi Peltola, Luana Micallef, Homayun Afrabandpey, Marta Soare, Muntasir Mamun Majumder, Pedram Daee, Chen He, Baris Serim, Aki Havulinna, Caroline Heckman, Giulio Jacucci, Pekka Marttinen, and Samuel Kaski. Improving genomicsbased predictions for precision medicine through active elicitation of expert knowledge. Bioinformatics, 34(13):i395–i403, 06 2018.
[71] Antti Kangasr¨a¨asi¨o, Jussi PP Jokinen, Antti Oulasvirta, Andrew Howes, and Samuel Kaski. Parameter inference for computational cognitive models with approximate bayesian computation. Cognitive science, 43(6):e12738, 2019.
[72] Sebastiaan De Peuter, Antti Oulasvirta, and Samuel Kaski. Toward ai assistants that let designers design. Technical report, 2021.
[73] Sarah Bridle, Sreekumar T Balan, Matthias Bethge, Marc Gentile, Stefan Harmeling, Catherine Heymans, Michael Hirsch, Reshad Hosseini, Mike Jarvis, Donnacha Kirk, et al. Results of the great08 challenge: an image analysis competition for cosmological lensing. Monthly Notices of the Royal Astronomical Society, 405(3):2044–2061, 2010.
[74] Schmidt Futures. Schmidt futures launches $148m global initiative to accelerate ai use in postdoctoral research. Available at availableat:https://www.schmidtfutures.com/ schmidt-futures-launches-148m-global-initiative-to-accelerate-ai-use-in-postdoctoral-resear2022.
AI+Science 是近年兴起的将人工智能和科学相结合的一种趋势。一方面是 AI for Science,机器学习和其他 AI 技术可以用来解决科学研究中的问题,从预测天气和蛋白质结构,到模拟星系碰撞、设计优化核聚变反应堆,甚至像科学家一样进行科学发现,被称为科学发现的“第五范式”。另一方面是 Science for AI,科学尤其是物理学中的规律和思想启发机器学习理论,为人工智能的发展提供全新的视角和方法。
集智俱乐部联合斯坦福大学计算机科学系博士后研究员吴泰霖(Jure Leskovec 教授指导)、哈佛量子计划研究员扈鸿业、麻省理工学院物理系博士生刘子鸣(Max Tegmark 教授指导),共同发起以“AI+Science”为主题的读书会,探讨该领域的重要问题,共学共研相关文献。读书会从2023年3月26日开始,每周日早上 9:00-11:00 线上举行,持续时间预计10周。欢迎对探索这个激动人心的前沿领域有兴趣的朋友报名参与。
链接:https://pattern.swarma.org/study_group/24?from=wechat














