关键词:大语言模型,自然语言处理,医学语料库,人工智能
论文标题:Large language models encode clinical knowledge
斑图链接:https://pattern.swarma.org/paper/e9c7e1b8-2107-11ee-a0b6-0242ac17000d
原文链接:https://www.nature.com/articles/s41586-023-06291-2
在医学事业中,语言为临床医生、研究人员和患者之间的关键互动提供了可能。然而,当今应用于医学和医疗保健的人工智能(artificial intelligence, AI)模型在很大程度上未能充分利用语言。因此,当今模型的功能与现实临床工作中的预期之间存在差距。
大语言系统是一种大型预训练的AI系统,将语言作为调解人类与AI交互的工具,这些富有表达性和交互性的模型可以从医学语料库编码的知识中大规模学习有效的表达。这种模型在医学中存在令人兴奋的潜在应用,包括知识检索、临床决策支持、总结关键发现、患者分类、解决初级保健问题等。但该类模型需要相应评估框架的开发,来对其安全性进行衡量并减轻潜在危害,而现有的医学问答基准测试通常仅限于评估分类的准确性或自动自然语言生成指标(automated natural language generation metrics),且无法实现临床应用所需的详细分析。
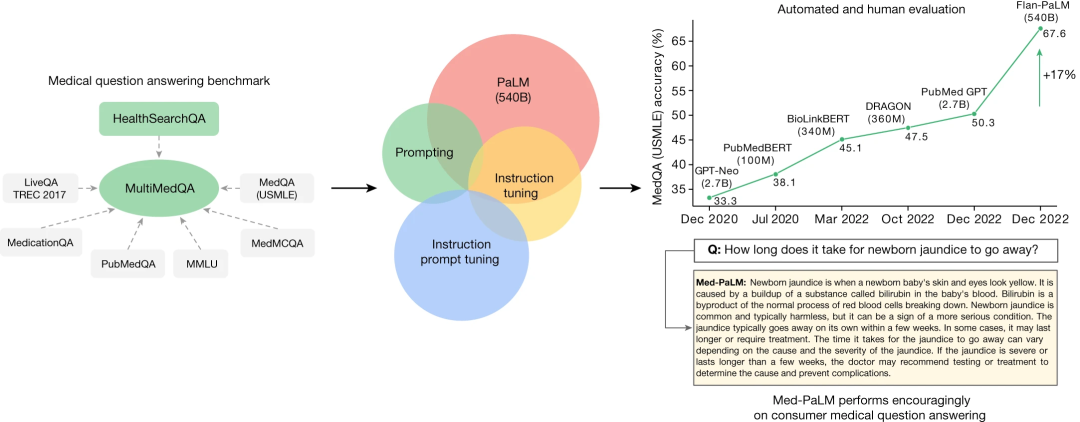
为解决上述问题,该研究提出全新的基准测试 MultiMedQA,这是一个由七个医学问答数据集组成的基准,其中包括六个现有数据集,涵盖专业医学、研究和消费者问题,同时还引入第七个数据集 HealthSearchQA,它由常见搜索的消费者医疗问题组成。研究人员尝试使用人类评估框架来评估大语言模型表现的多个维度,超越原来仅关注多项数据集选择的准确性,进而开始评价评估结果与科学和临床共识的一致性、伤害的可能性和可能的程度、阅读理解能力、相关临床知识的回忆、通过有效推理对知识的操纵、反应的完整性、潜在的偏见、相关性和帮助性等。
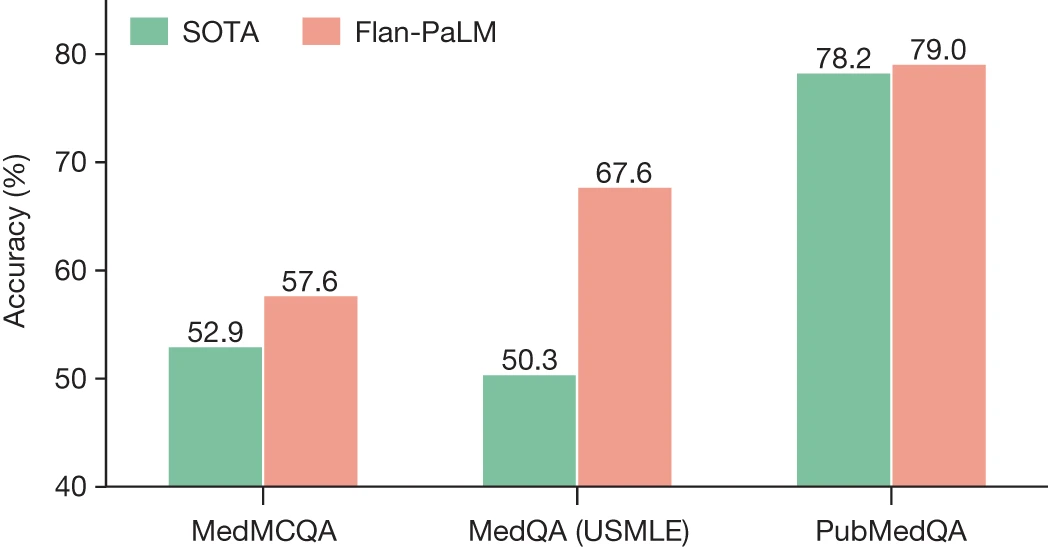
随后,研究人员利用 MultiMedQA 评估 PaLM 及其微调变体 Flan-PaLM 两个大语言模型, Flan-PaLM,在 MedQA、MedMCQA、PubMedQA 和 MMLU 等几个临床主题上达到最先进的性能。
图2 Flan-PaLM与现有技术(previous state-of-the-art performance, SOTA)的比较。
进而,研究人员引入指令提示微调,这是一种简单的、数据高效和参数高效的技术,用于将大语言模型与安全关键的医疗领域(safety-critical medical domain)结合起来,构建了Med-PaLM,这是专门针对医疗领域的 Flan-PaLM 的指令提示调整版本,结果可以看到,Med-PaLM 在其中几个轴上大大缩小了与临床医生的差距。
最后,研究人员详细讨论了AI评估所揭示的大语言模型的主要局限性。尽管大语言模型在医学方面具有巨大潜力,但为了使这些模型适用于现实世界的临床应用,仍需要进行一些关键的改进。Med-PaLM 模型的出色表现提供了发展思路,虽然其相比临床医生尚存在差距,但可以证明评估框架与方法优化在创造安全有效的临床医学大语言模型时具有很高重要性。

推荐阅读