如何利用 GPT-4 加速合成生物学的知识挖掘和机器学习?

导语

.PNG")
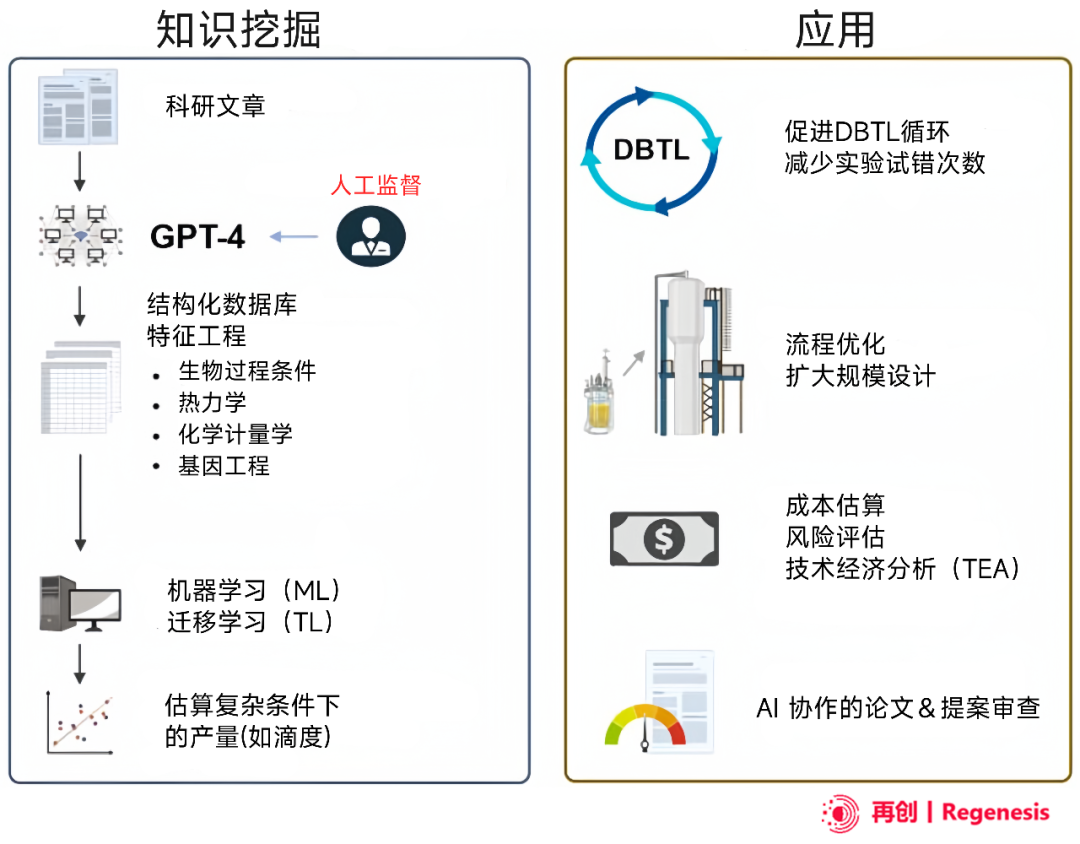
图 1:用于机器学习的 GPT-4 知识挖掘(左图)和潜在的 AI 应用(协助生物制造设计、商业决策或项目质量/风险评估)
一、结果与讨论
一、结果与讨论
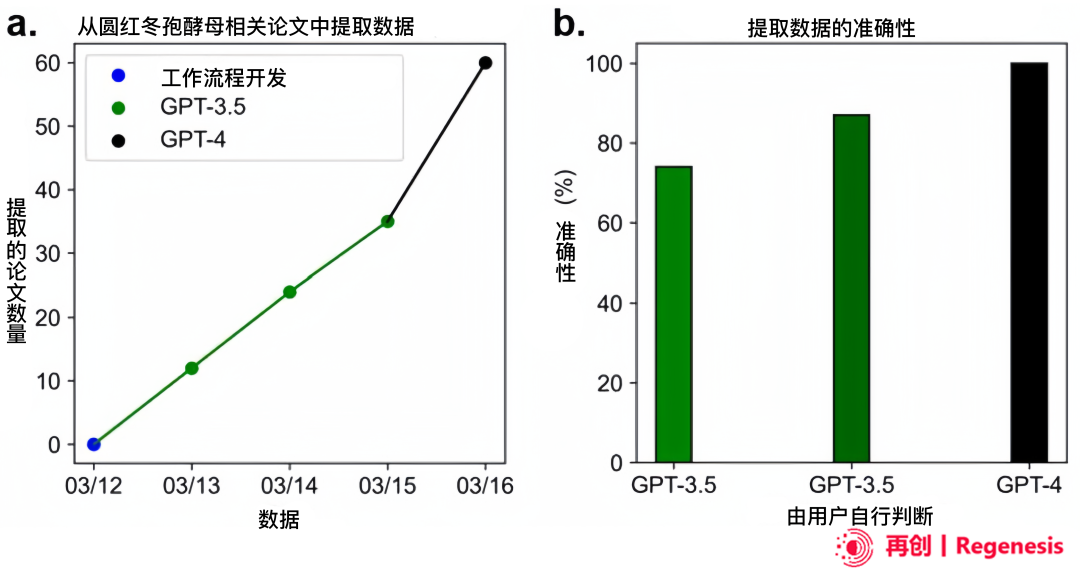
图 2:GPT-3.5 与 GPT-4 的速度和准确率差异。a. 单个用户在五天内处理的圆红冬孢酵母相关论文数量。b. 从包含 115 个发酵实例的 10 篇解脂耶氏酵母测试集文章中提取的数据的准确性。注意:在用于机器学习之前,所有数据都经过了人工检查,排除了错误。

图 3:手动提取的解脂耶氏酵母数据集与 GPT-4 提取的解脂耶氏酵母数据集的比较。a. 使用随机森林回归确定的特征重要性,从高到低排列。b. 规范化的特征差异。(紫色:手动提取的数据集,黄色:GPT-4 提取的数据集。)

图 4:使用 K-均值无监督学习的主成分分析 (PCA)。(a)手动提取的数据集的 PCA。(b) GPT-4 提取的数据集的 PCA。注意图 a 和图 b 之间的轴比例差异。
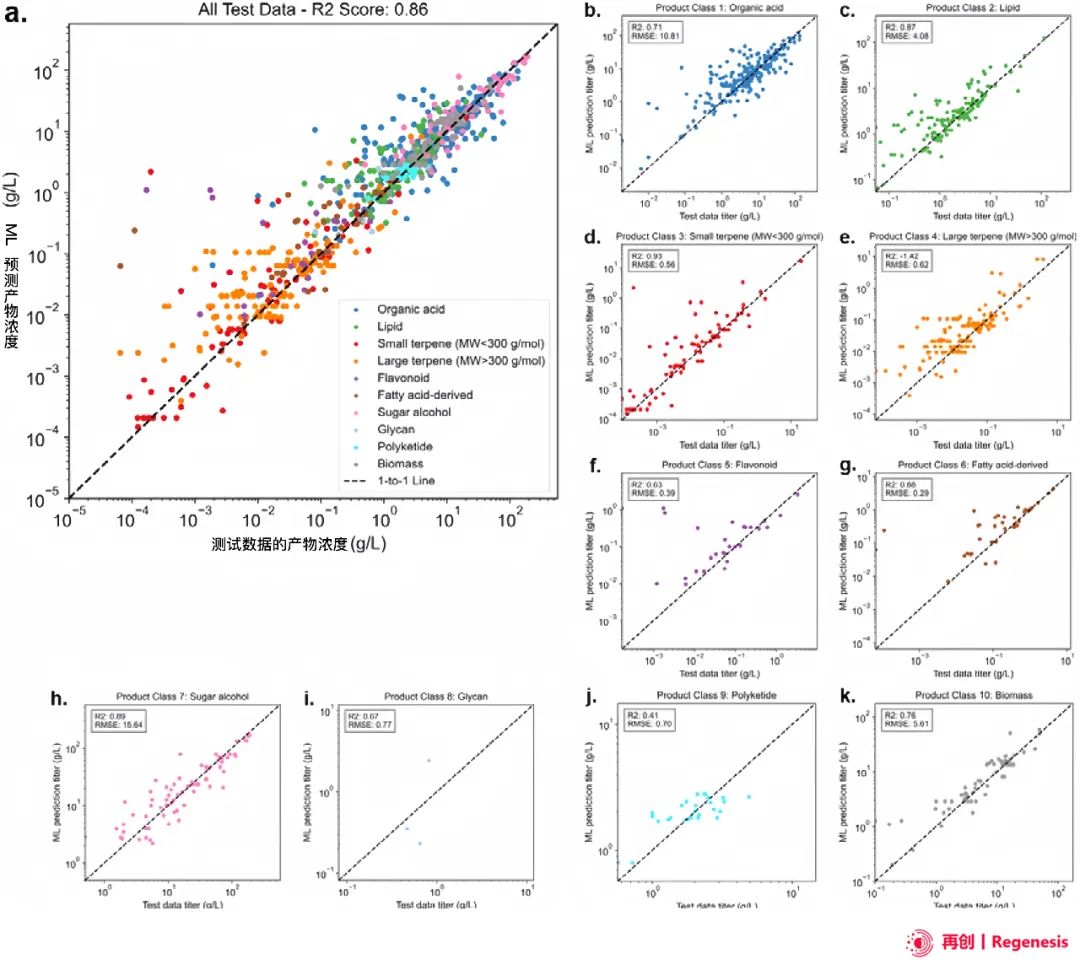
图 5:使用随机森林集成学习器进行解脂耶氏酵母发酵产物浓度的测试集预测。
二、GPT-4 的
局限性、提示和未来的 ML/NLP 方向
二、GPT-4 的
局限性、提示和未来的 ML/NLP 方向
三、结论
三、结论
大模型与生命医学:
AI + Science第二季读书会启动
详情请见:
推荐阅读
微信扫一扫,分享到朋友圈











