大型语言模型中涌现类比推理|Nat. Hum. Behav. 速递

关键词:人工智能,大语言模型,类比推理,认知神经科学,涌现


论文题目: Emergent analogical reasoning in large language models 论文地址:
https://www.nature.com/articles/s41562-023-01659-w
人类的推理能力表现出一种独特的灵活性,能够在没有广泛实践或训练的情况下解决新问题。这种能力在很大程度上依赖于类比推理——通过将陌生问题与熟悉问题进行比较来理解它。对于认知科学来说,一个重要问题是人脑是如何进行这个过程的。这个问题与人工智能系统是否以及如何获得类似的类比推理能力密切相关。特别是,关于深度学习系统(逐渐从经验中学习的多层神经元网络)是否在接受足够的训练数据后能够发展出这种灵活推理能力的问题存在着大量争议。
最近发表于 Nature Human Behaviour 的一项研究中,作者对大规模 AI 系统 GPT-3 模型(Generative Pre-trained Tranformer 3)进行了类比能力研究,并在广泛的类比问题数据集中进行测试。类比问题集包含了一种全新的基于文本的 Raven 渐进矩阵(图1a,b)版本,这是一套视觉类比问题,通常被视为衡量人类解决问题能力的最佳标准之一。在原始的视觉问题中,展示了一组包括空白项的几何图形(图1a)。任务是使用这个图形模式从一组备选答案中选择正确的缺失部分来“填补空白”。研究者通过将几何图形转换为数字来创建这些问题的文本版本(图1b)。
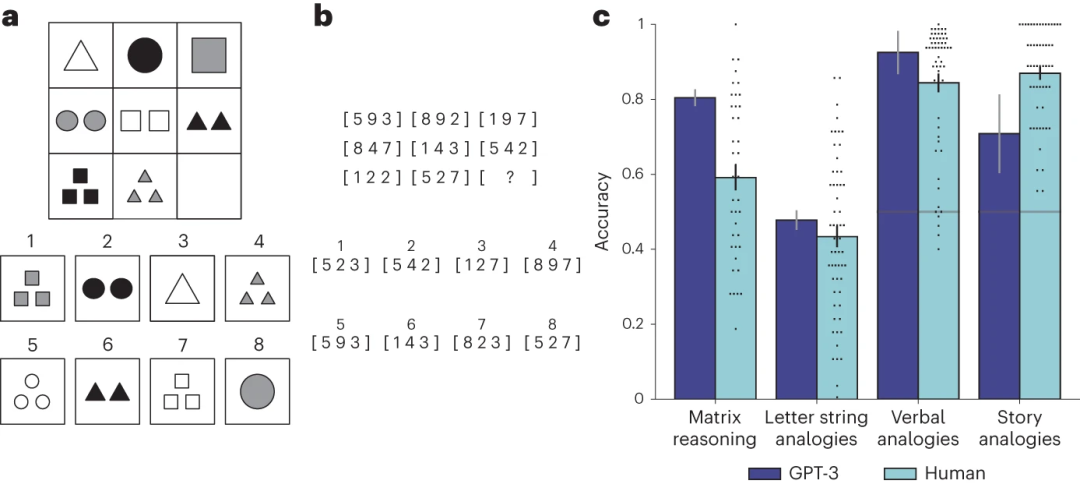
此外,研究者还对GPT-3进行了其他类比问题的测试,包括涉及现实世界概念的问题(例如,“爱:恨::富有:?”)或完整的故事(任务是确定哪个目标故事与源故事最相似)。值得重视的是,研究者在未对GPT-3进行针对这些问题的直接训练的情况下进行了测试,以反映人类在无需大量练习的情况下解决类比问题的能力。
研究发现,GPT-3在大部分任务环境中的表现与大学生相当,甚至有时超过他们(图1c)。更为重要的是,GPT-3展示了与人类参与者相似的错误率模式,即在人类往往认为困难的问题上表现出更大的困难(例如,由多个规则控制或需要更高程度的抽象的问题)。这些结果暗示,通过学习生成类似人类语言的文本,GPT-3习得了高度通用的解决类比问题的能力。
许多认知科学家和人工智能学者的普遍观点是,深度学习系统需要大量特定任务的训练,并且其在训练过程中所经历的条件外泛化能力有限。然而,这项新研究的结果对此前的普遍观点提出了质疑,暗示深度学习系统在通用任务上(即学习生成类似人类语言文本)接受足够广泛的训练后,有可能习得推理新问题的能力。
值得指出,该研究结果存在一些局限性。GPT-3完全基于文本,因此无法直接从视觉输入(如图1a所示的问题)解决类比问题。GPT-3还缺乏长期记忆能力,表现出解决物理问题时的推理能力不足,例如其无法解决涉及使用工具的简单建构问题。该研究还发现,与人类参与者相比,GPT-3在识别故事之间更抽象的类比方面存在困难,尽管GPT-4的表现优于GPT-3。
这项研究提出的一个主要问题是,GPT-3解决类比问题的机制是否与人脑使用的机制相似。虽然像GPT-3这样的深度学习系统受到人脑的启发(由类似神经元的处理单元组成,按多层次结构排列),但目前尚不清楚这些系统如何执行被认为构成人类类比推理基础的计算操作。然而,不同于人脑,像GPT-3这种系统的内部机制至少在理论上可以直接探测。这一特点表明,这些人工智能系统可能作为一种理解高阶认知过程神经基础的“模型生物”。为实现这一目标,开发这些系统的开源版本以供认知科学家研究,并提供评估它们所需的资源将是关键。这一进展还将有助于科学家深化对这些系统优势和局限性的理解,并确保它们安全地应用于社会。
本文翻译自评论文章: https://www.nature.com/articles/s41562-023-01671-0
“后ChatGPT”读书会

推荐阅读
微信扫一扫,分享到朋友圈











