关键词:计算社会科学,计算语言学,语言环境假说,语法复杂性
论文标题:Societies of strangers do not speak less complex languages
原文链接:https://www.science.org/doi/10.1126/sciadv.adf7704
最近,许多人提出了语言适应环境的观点。语言环境假说认为,母语使用者众多且非母语使用者占很大比例的语言(陌生人社会)往往会失去语法上的区别,与此相反,孤立的社团中的语言应该保持或扩大其语法标记。
本文使用全球语法结构数据集 Grambank 来检验这些说法。作者建模母语使用者的数量、非母语使用者的比例、语言邻居的数量以及语言地位对语法复杂性的影响,同时控制了空间和系统发育自相关性。作者将“语法复杂性”分解为两个独立的维度:一种语言有多少形态(“融合”)和语法中必须编码的信息(“信息量”)。
研究结果不支持“语言环境假说”的主张,即语法复杂性应随着非母语者人数的增加而降低。与预期的复杂性得分与社会人口变量之间的反向相关性相反,唯一稳健的关系是第一语言使用者对融合性和信息性的微弱正向影响。
同时,模拟的复杂性的两个维度(融合性和信息性)能更好地通过系谱学和地理扩散来预测,测量这两个特征的系统发生学信号表明,它们的得分分布在很大程度上受到全球树上语言之间共同进化历史的影响。语法复杂性的这两个维度在系统发育上似乎都非常稳定,这表明融合性和信息性在系统发育上是受限的。
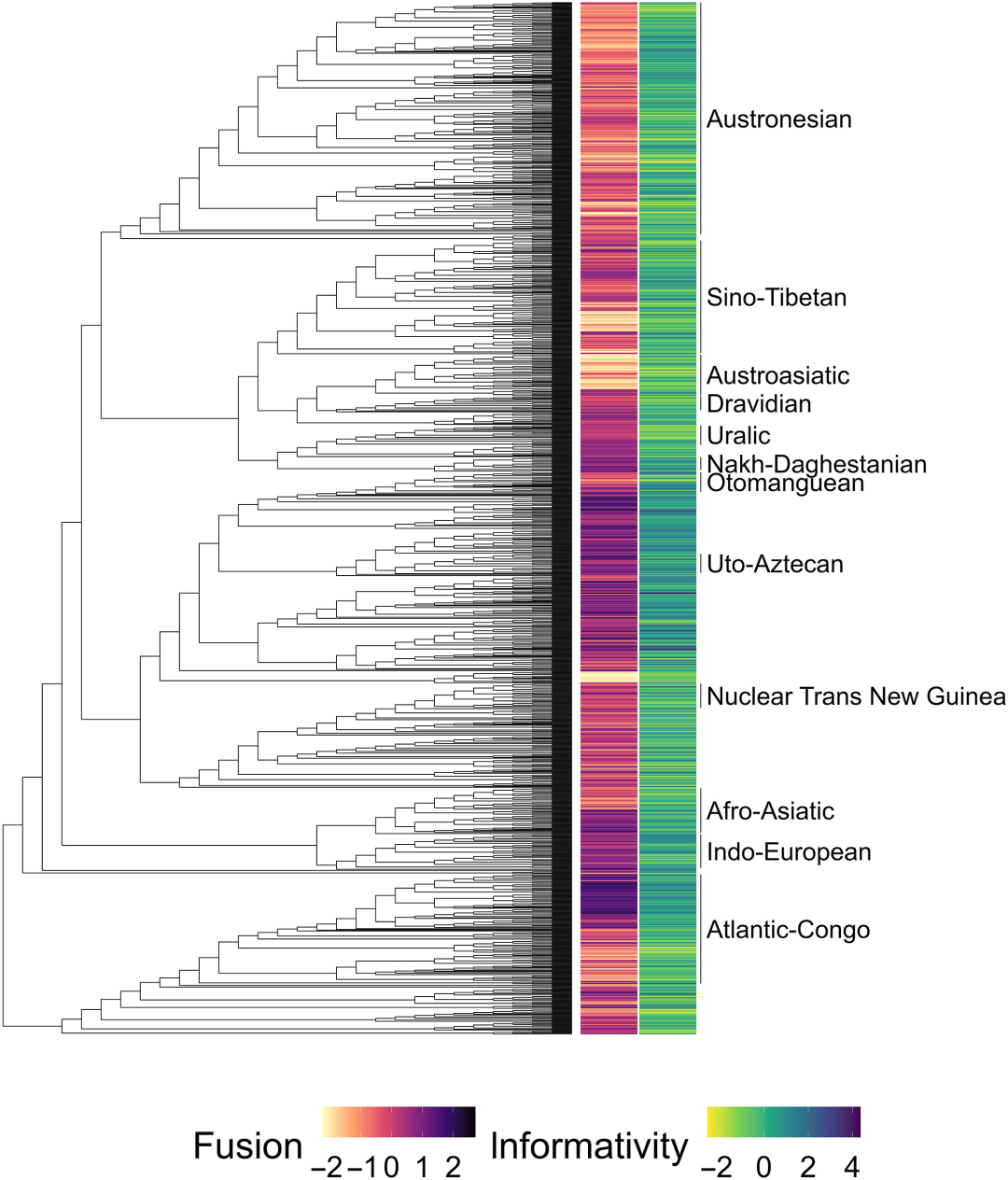
图1 全局树上的融合度和信息度得分。许多近亲语言的得分模式相似,表明语法复杂性从祖先语言忠实地传递给了后代,而不是语法复杂性大规模地适应社会人口因素的变化。与地理分布相似,与信息量得分相比,融合得分遵循了更明确的系统发育聚类模式。
此外,族谱关系以及在某种程度上邻近语言之间的潜在接触为理解融合得分的变化提供了更好的基础。
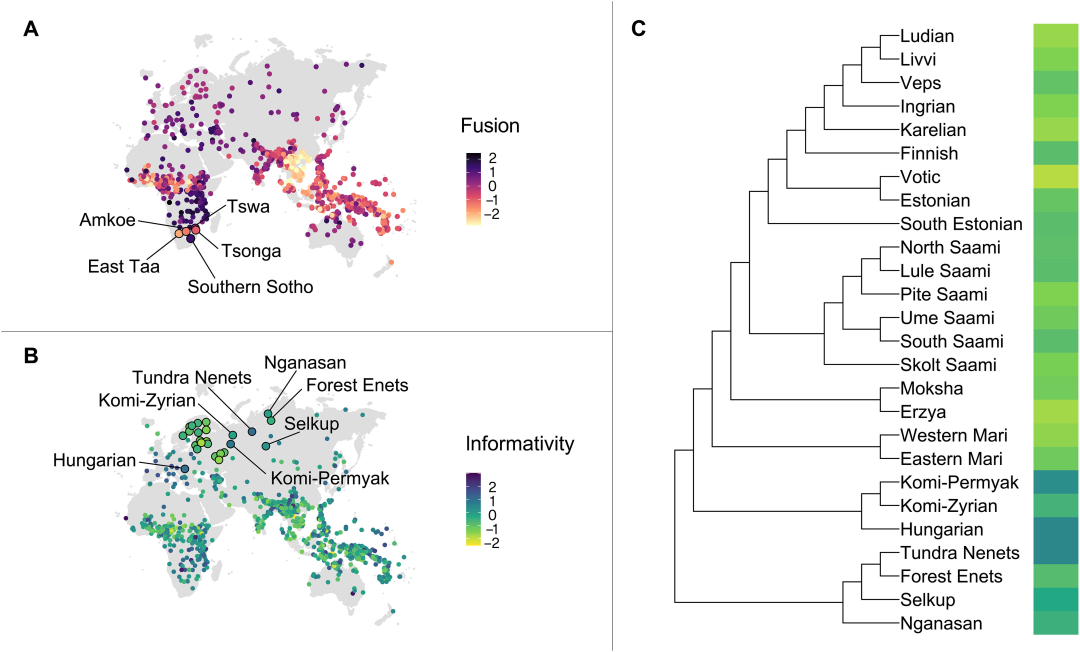
图2 融合度和信息度得分的总体分布以及融合度得分在总体树子集上的分布。
研究结果使语法复杂性由社会语言环境决定这一普遍说法产生了怀疑。未来的研究在模拟语言对环境的适应时,应仔细考虑谱系学和地理学之间的相互作用,并解释为什么某些特征可能比其他特征对社会语言压力更敏感。
详情请见:
数据与计算前沿方法整合:计算社会科学读书会第二季启动
推荐阅读