因果表征学习旨在发现高层次的潜在因果变量以及它们之间的因果关系。我们可以根据三个维度对它们进行分类:第一个维度是,我们收集的是由单一分布生成的独立同分布数据还是时序数据或多分布数据;第二个维度是是否有参数化假设;第三个维度是观测数据背后是否有潜在共因。在2023年泛太平洋因果推断大会上,美国卡内基梅隆大学以及阿联酋 MBZUAI 教授张坤给了主题为“Advances in Causal Representation Learning: Discovery of the Hidden World ”的报告,介绍了团队在这三种维度决定的不同设定下的因果表征学习最新工作,及其在各种领域的应用,例如考古学、心理学、计算机视觉等。张坤老师的报告为偏视野性质的介绍,以 PPT+对应核心想法的形式整理成文,分享给大家。
泛太平洋因果推断大会是自2019年起由北京大学讲席教授、北京大学公共卫生学院生物统计系系主任、北京大学北京国际数学研究中心生物统计和信息研究室主任周晓华等发起的因果科学领域一年一度的盛会,面向所有对因果科学感兴趣的相关研究人员,探索新的科研方向。
首先,让我们试着将我们正在经历的与发生在 16 和 17 世纪的科学革命进行类比。我们有什么?我们有丰富的数据,有相对完备的概率论和统计推断,还拥有强大的计算能力。这些东西相比历史上的任何时期都是独一无二的。然后问题来了,我们想从数据中学习什么?这是稍后可以看到的关键点。从本质上讲,我认为要想真正促进下一次科技革命,现在还缺少这一点。
如果你回到16世纪,可以看到很多人发现了新的东西,包括哥白尼、伽利略、牛顿、培根、哈维等等。从本质上讲,他们当时开始利用望远镜等仪器收集数据。他们对概率论有一些基本的了解,有一些非常基本的推断规则,就像牛顿在《自然哲学的数学原理》中介绍的那样。你可以看到,他们试图用定量的观点而不是定性的观点来看待自然(古希腊通常只是用定性的观点来看待自然)。他们对问题给出非常明确的答案。与此同时,研究范式也从研究“为什么”转向了“怎么做”。他们试图发现规律,他们认为研究“为什么”太贪婪也太难,因为没有真正掌握足够的信息。
现在的我们与他们相比,我们拥有足够的数据和计算资源,但问题是,我们试图从这些数据中取得的成果似乎受到了目标的限制。我们能否真正将研究范式从 研究“如何”转回到定量研究“为什么”?这完全是可能的,因为只要你能真正制定出因果原则,并使因果原则在技术上具有可操作性,就能在几乎所有情况下可靠地发现因果关系。即使存在很多潜在变量,我们基本上也能实现这一目标。
现代因果发现研究的历史其实不长。最早可以追溯到 Reichenbach 的共因原则,虽然其中的想法还比较初步,但足以让人们意识到,从统计信息中抽取因果信息是有可能的。随后一些经典的进展包括:Peter Spirtes,Clark Glymour和 Richard Scheines 的著作 Causation, Prediction and Search,其中囊括了大量的因果发现经典算法,以及 Judea Pearl 的 Causality: Models, Reasoning and Inference,非常清晰地介绍了大量概念。但当时,通常因果发现算法都需要非常强的条件,得到的结果很多时候也不够信息丰富。这也告诉我们,因果发现仍然还有很多工作需要去推进。
为什么我们能从数据中发现因果关系?从本质上说,我们必须看到因果关系在数据中留下的足迹,并尝试通过这些足迹回溯。我们需要建立某种可识别性来证明,如果我有足够多的数据,那么就可以利用这些足迹恢复出真相。基本上,所有的因果发现方法都依赖于某种因果模块化的不同实例(经济学中通常称之为外生性,哲学和计算机科学中通常称为模块化,包括 Bernhard 团队提出的独立因果机制原则,内核上它们指的是几乎相同的东西)。
即使一个系统复杂到所有变量间都相互依赖,如果用因果的视角来看待系统,就会发现构成系统的子系统之间没有耦合关系。每个子系统做的都只是通过父节点产生一个变量。然而,我们可以在不改变任何其他子系统的情况下改变一个子系统的因果机制。多个子系统发生改变时彼此独立改变。作为这个条件的实例化,可以很容易地看到变量之间的条件独立关系,在线性非高斯模型中能看到独立噪声条件。如果你允许分布变化,还可以看到最小变化原则和独立变化原则。有了这些原则和信息就能从数据中恢复因果关系。本质上讲,我们有可识别性保证,也就是说,如果你有足够的数据且对数据做的假设成立,那么恢复的因果关系肯定是正确的。
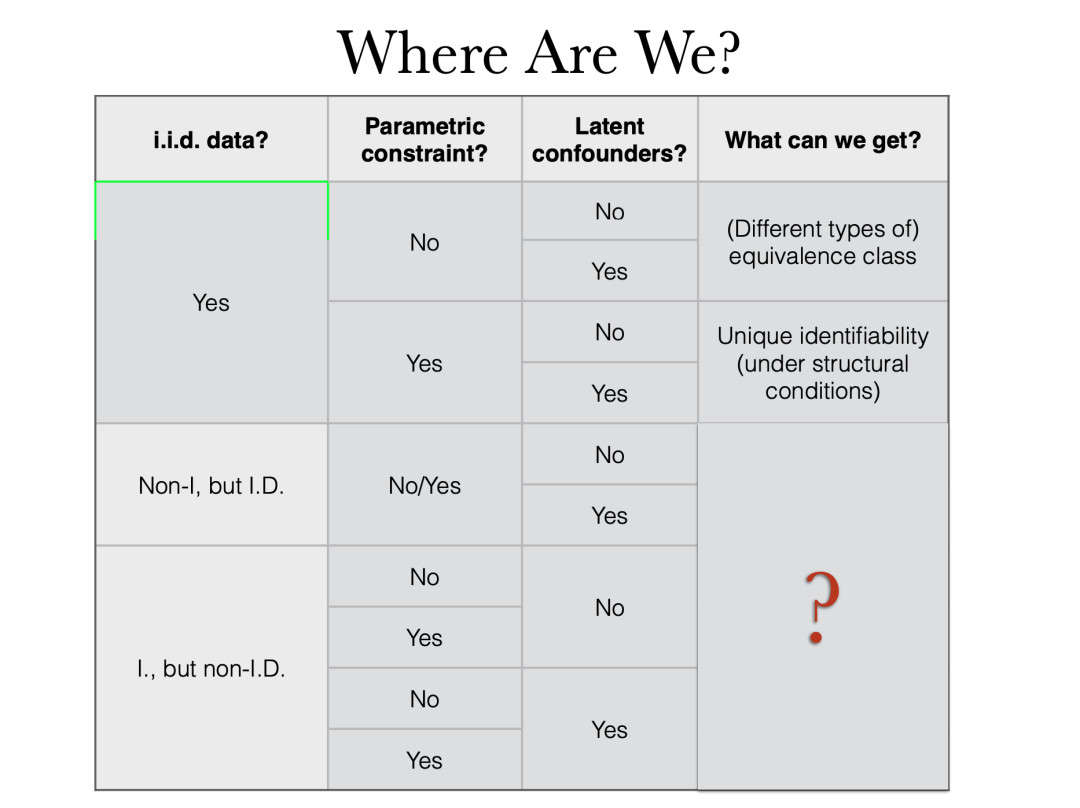
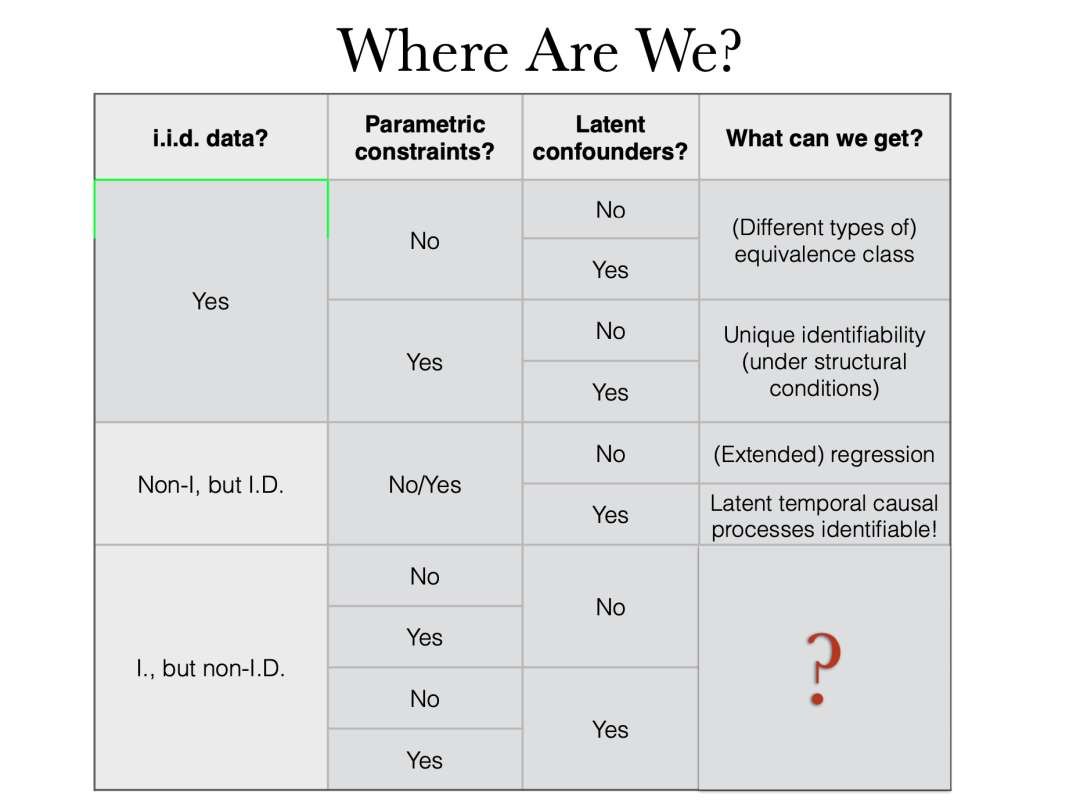
一般性地,我们考虑因果发现或因果表征学习,其目的是发现高层次的潜在因果变量。我们可以根据三个维度对它们进行分类:
有意思的是,因果变量通常是隐藏的,这是我的观点。传统的因果关系在某种程度上是循环论证的。你认为某些变量之间存在因果关系。你收集这些变量的数据,试着去验证关系以及定量分析。但在实践中,尤其是 AI for science 中,我只能为那些我能理解的变量收集数据。然后根据这些数据,试图推断出发生了什么。不管真正有意义的潜在变量是被观察还是被隐藏起来,我们应该同样对待,还原全貌,解释所看到的一切,然后进一步使用发现的因果变量和关系。
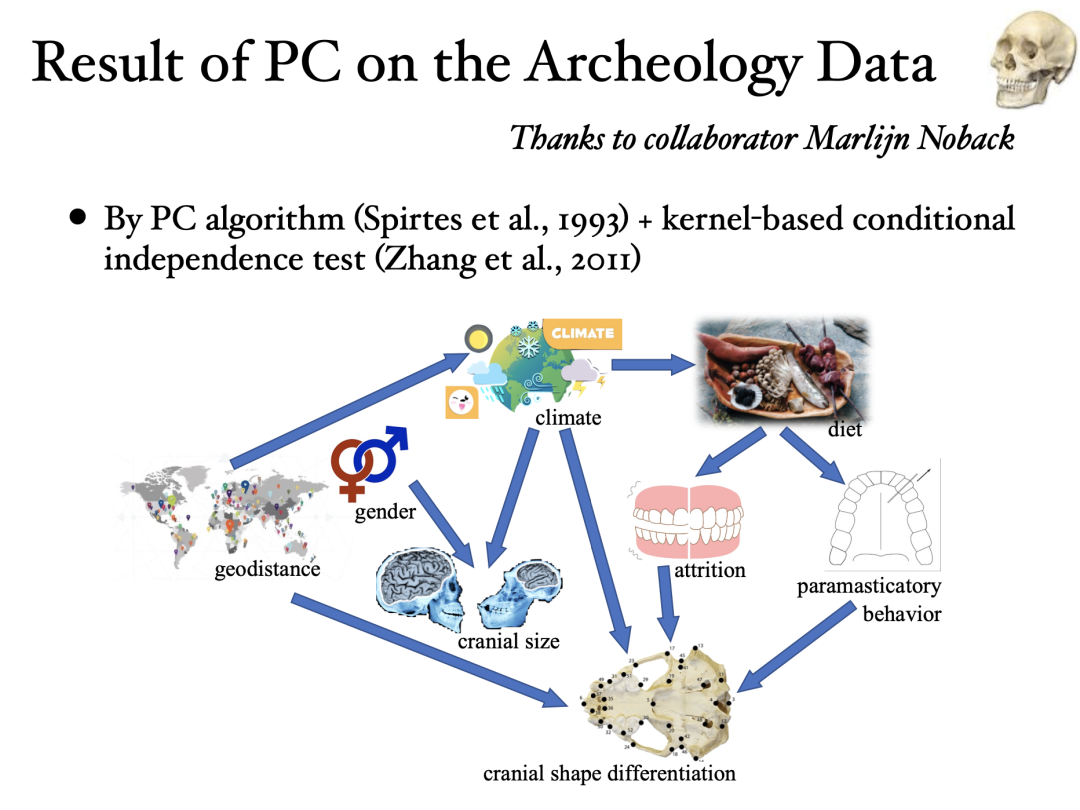
通过基于约束的因果发现算法 PC 算法结合基于核的条件独立性测试工具 KCIT,得到的因果结构图。
如果我们更进一步地对因果机制的形式做一些参数化约束时,我们能在很多场景下得到可识别性的保证,例如线性非高斯加性噪声模型 LiNGAM,后非线性因果模型 PNL,加性噪声模型 ANM 等等。即使只有两个变量(这意味着没有可以利用的条件独立性)时,我们仍然能够区分哪个变量是因变量,哪个变量是果变量。当然这同样也是有代价的,真实场景中我们可能缺少背景知识告诉我们因果机制是否符合这些假设。参数化假设如果不满足时这些方法有可能给出较坏的估计结果。
[1] Shimizu, Hoyer, Hyvärinen, Kerminen, “A Linear Non-Gaussian Acyclic Model for Causal Discovery,” JMLR, 2006.
[2] Zhang, Chan, “Extensions of ICA for Causality Discovery in the Hong Kong Stock Market,” ICONIP 2006.
[3] Hoyer, Janzing, Mooij, Peters, Schölkopf, “Nonlinear causal discovery with additive noise models,” NeurIPS 2008.
3. 隐变量因果结构学习
(独立同分布但不满足因果忠实性假设)
心理学数据集:我们能否找到心理学测试背后反映的精神状态。
通过一些方法可以非常清晰地解释数据背后的隐变量结构,例如,在线性高斯噪声情况下,或仅仅是在线性情况下,可以通过看一组变量是否可以利用某个瓶颈与另一组变量中d-分离。如果瓶颈的维度很低,那么这一观察结果就会产生一些图形意义。通过这样一种方法,可以找到隐变量以及它们之间的关系。
Huang, Low, Xie, Glymour, Zhang, ”Latent Hierarchical Causal Structure Discovery with Rank Constraints,” NeurIPS 2022.
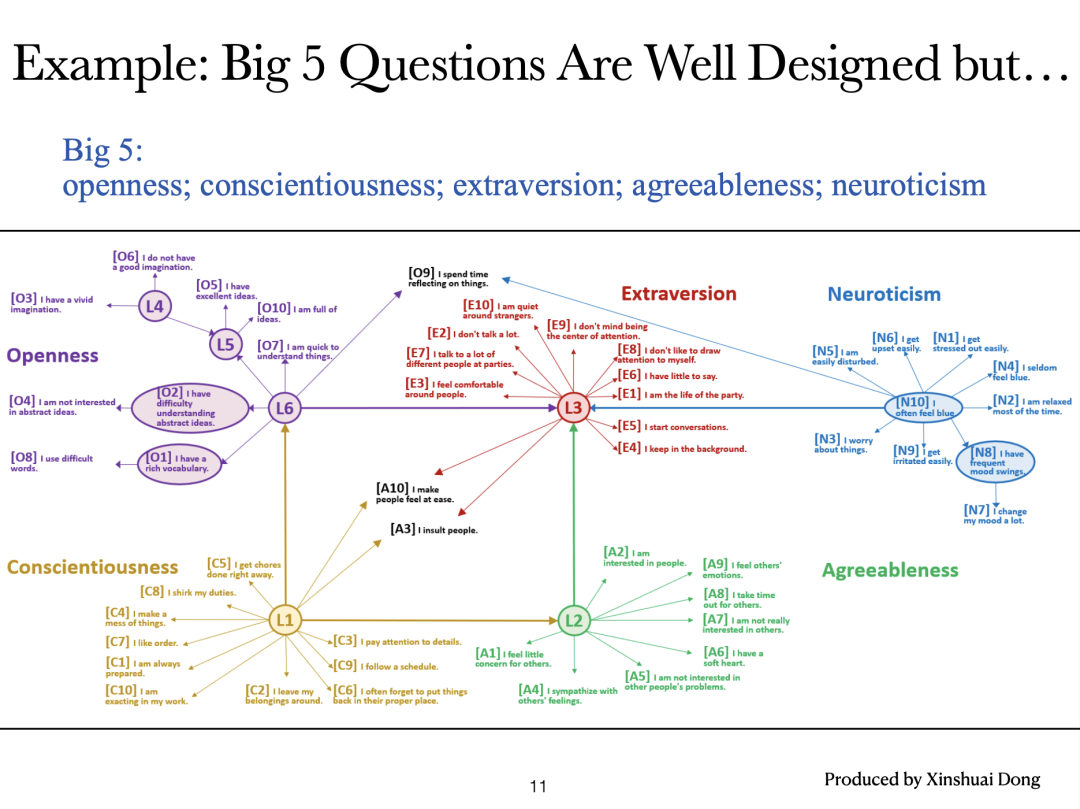
在心理学数据集上测试得到的结果,其中写有Li的节点均表示隐变量。
泛化独立噪声条件,或者GIN:如果将因变量对果变量做回归,那么得到的回归残差将与用来回归的因变量独立。而泛化独立噪声条件在其基础上考虑了变量的组合。如果泛化独立噪声条件满足,那么能够立刻得到一些图结构上的信息。
[1] Xie, Cai, Huang, Glymour, Hao, Zhang, “Generalized Independent Noise Condition for Estimating Linear Non-Gaussian Latent Variable Causal Graphs,” NeurIPS 2020.
[2] Cai, Xie, Glymour, Hao, Zhang, ”Triad Constraints for Learning Causal Structure of LatentVariables,” NeurIPS 2019.
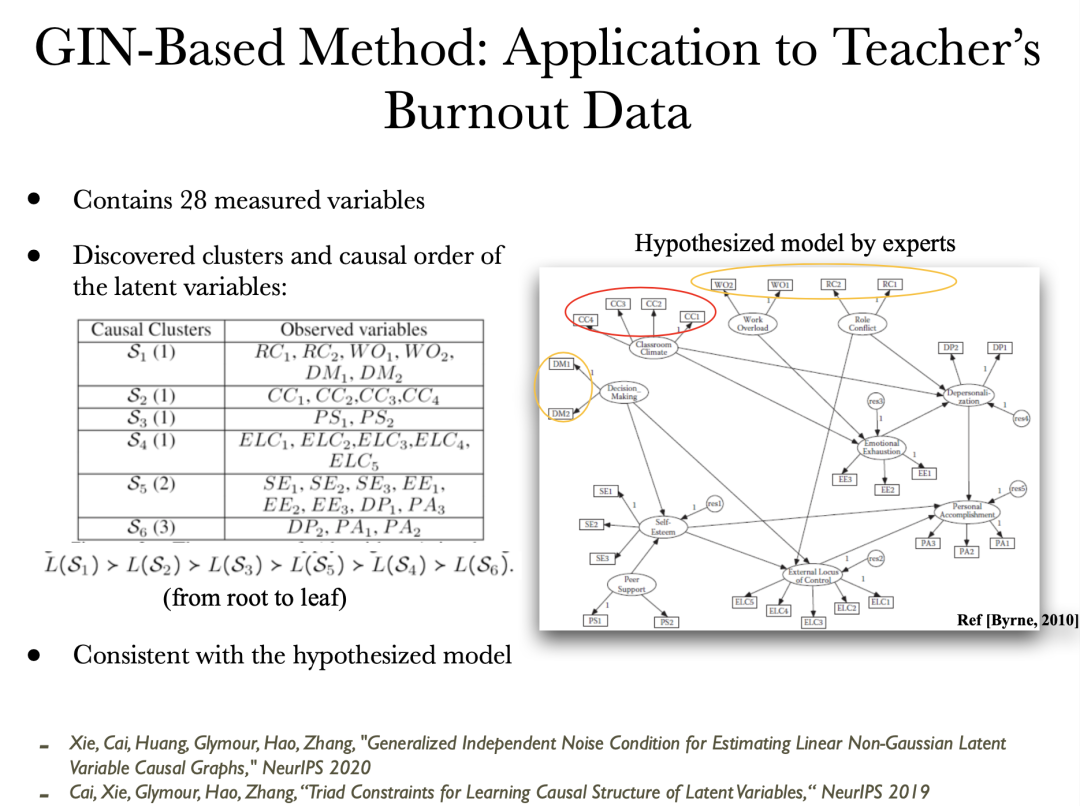
通过GIN条件,首先可以找到因果聚类,了解隐变量的位置。然后,就可以发现隐变量之间的关系或因果顺序。
应用该算法在教师懈怠数据集上得到的结果。左边的表为当前算法在数据中估计的结果,右边为专家给出的参考图。算法学习的结果基本上与专家给出的模型是一致的。
4. 时序数据下的因果表示学习
(不独立但同分布)
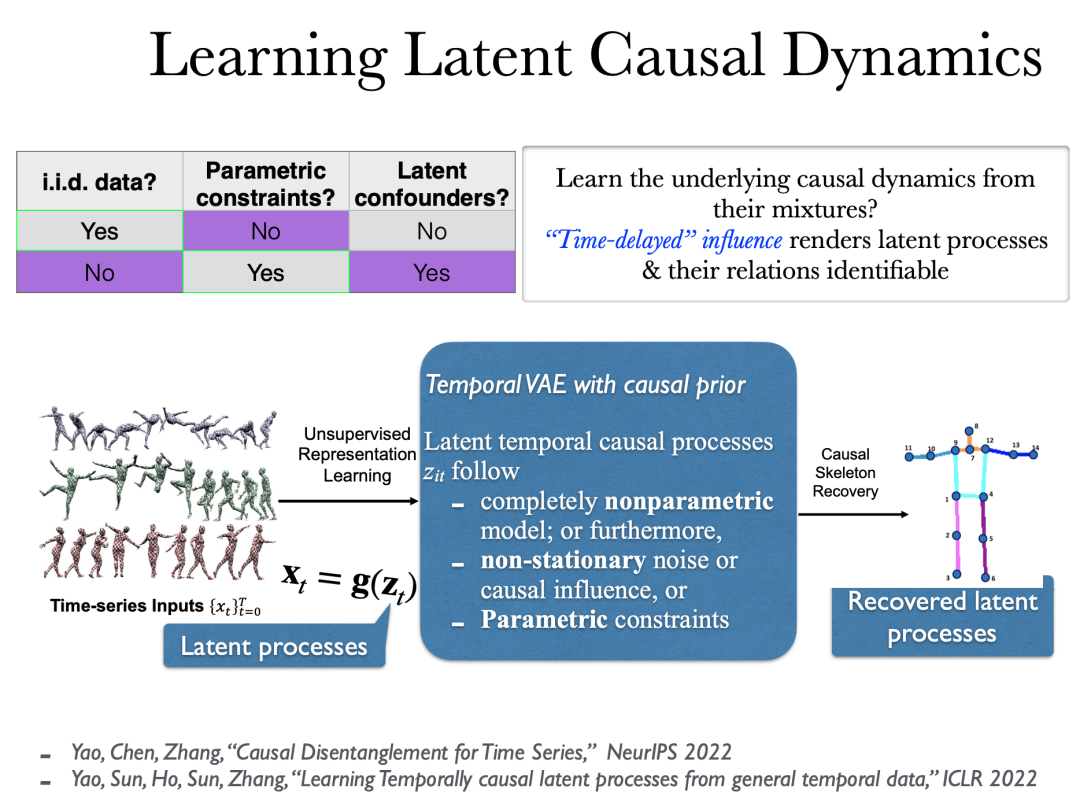
我们前面都是在独立同分布的数据下讨论因果发现的,现在让我们关注到在非独立同分布学习因果关系的情况。非常有趣,又很自然的是,通常在非独立同分布学习因果关系更加容易。原因在于因果天然就是与变化息息相关的。独立同分布的数据本身缺少变化,因而减小了因果性的用武之地。
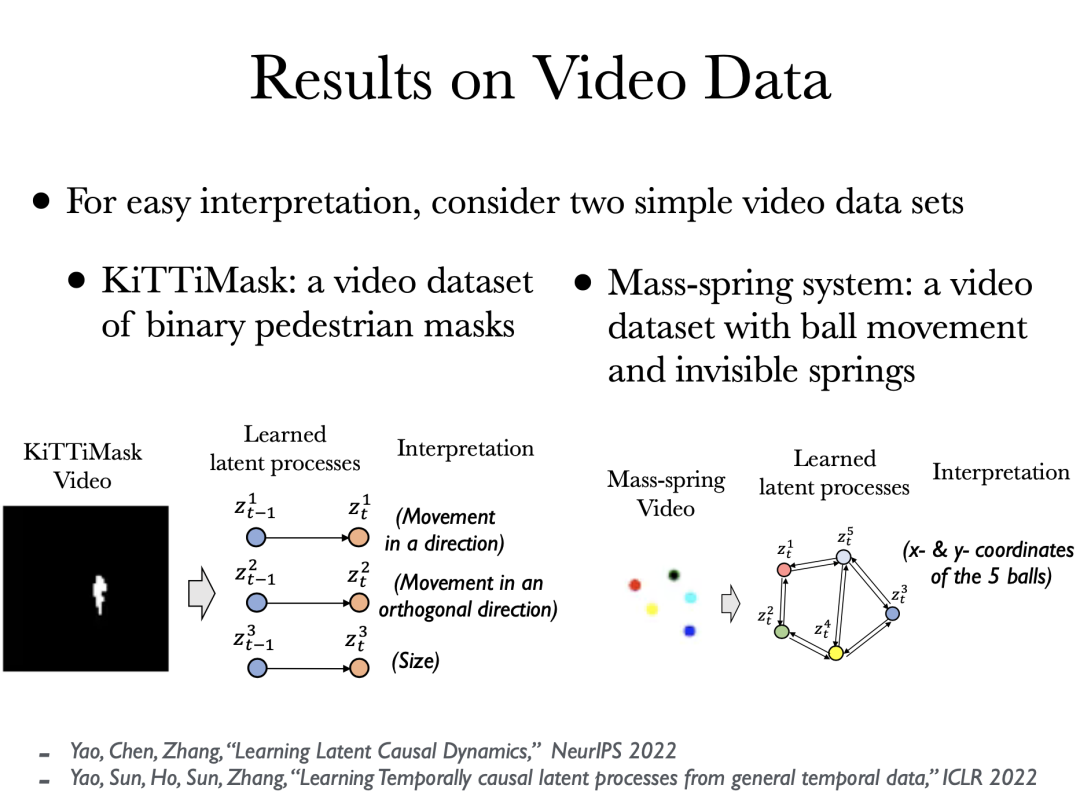
视频数据可以看作是一些潜在概念的高维可逆函数。我们试图从每一帧的像素值中恢复这些概念。有趣的是,在非常一般性的情况下,我们可以几乎唯一地恢复视频数据背后的潜在因果过程。即使这个函数的混合函数可能是完全非参的,概念间的因果关系也是非参的,我们仍然可以通过成分变换恢复出来每一个概念。
[1] Yao, Chen, Zhang, ”Causal Disentanglement for Time Series,” NeurIPS 2022.
[2] Yao, Sun, Ho, Sun, Zhang, ”Learning Temporally Causal Latent Processes from General Temporal Data,” ICLR 2022.
在视频数据集上的应用,例如在右图的例子中,可以恢复出 5 个小球之间的潜在过程。
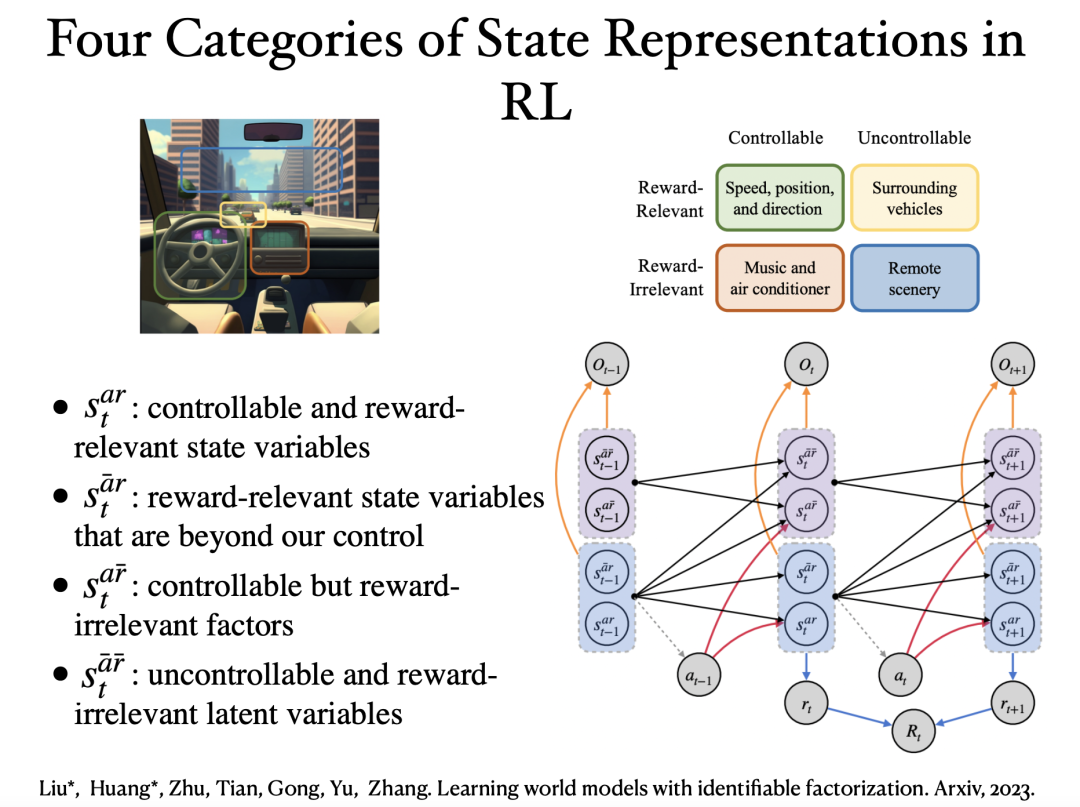
在强化学习中,我们希望提供可视化或对底层状态表示的解释,这是我们所依赖的决策依据。
在这个工作中,我们将状态表示分为四类,根据它们是否可控以及在当前任务中是否奖励相关。有趣的是,从像素标签视频数据中,我们证明了这四类潜在变量的分块可识别性。因此,这能帮助我们去除冗余,但保留策略优化所需的最少但充分的信息。
参考文献:Liu*, Huang*, Zhu, Tian, Gong, Yu, Zhang, ”Learning world models with identifiable factorization,” Arxiv, 2023.
5. 分布迁移下的因果表示学习
(独立但不同分布)
我们刚刚讨论是时序数据的情况,接着让我们来分析分布迁移的场景。
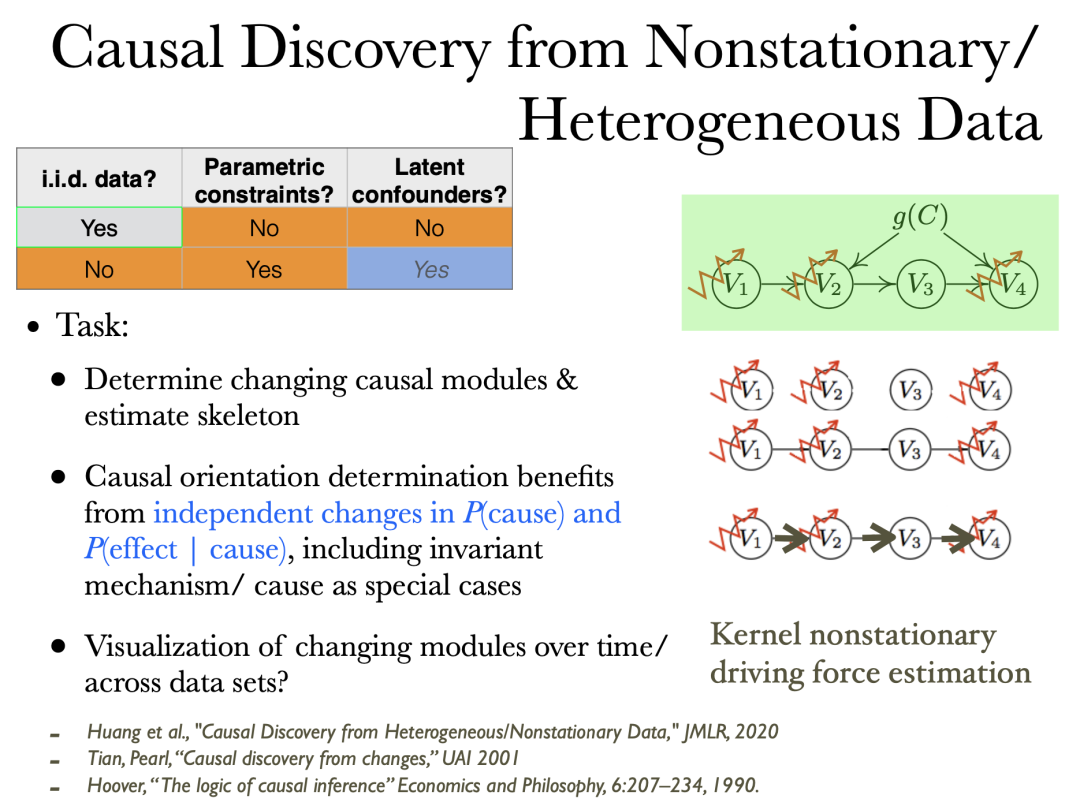
模块化原则告诉我们,因果机制在发生变化时是独立改变的。这意味着当我们观测到分布变化的时候,可以去推测怎么样的因果结构可以导致这种改变。这里的机制改变指因果影响变强,变弱,或者消失。
[1] Huang, Zhang, Zhang, Ramsey, Sanchez-Romero, Glymour, Schölkopf, “Causal Discovery from Heterogeneous/ Nonstationary Data,” JMLR, 2020.
[2] Zhang, Huang, et al., ”Discovery and visualization of nonstationary causal models,” arxiv 2015.[3] Ghassami, et al., ”Multi-Domain Causal Structure Learning in Linear Systems”, NIPS 2018.
通过分布的非暂态性/异质性相比于独立同分布可以得到额外的信息帮助因果发现,例如原先只能最多识别到 Markov 等价类的场景现在能确定更多的因果方向。
[1] Huang, Zhang, Zhang, Ramsey, Sanchez-Romero, Glymour, Schölkopf, “Causal Discovery from Heterogeneous/ Nonstationary Data,” JMLR, 2020.
[2] Tian, Pearl, ”Causal discovery from changes,” UAI 2001.
[3] Hoover, ”The logic of causal inference” Economics and Philosophy, 6:207–234, 1990.
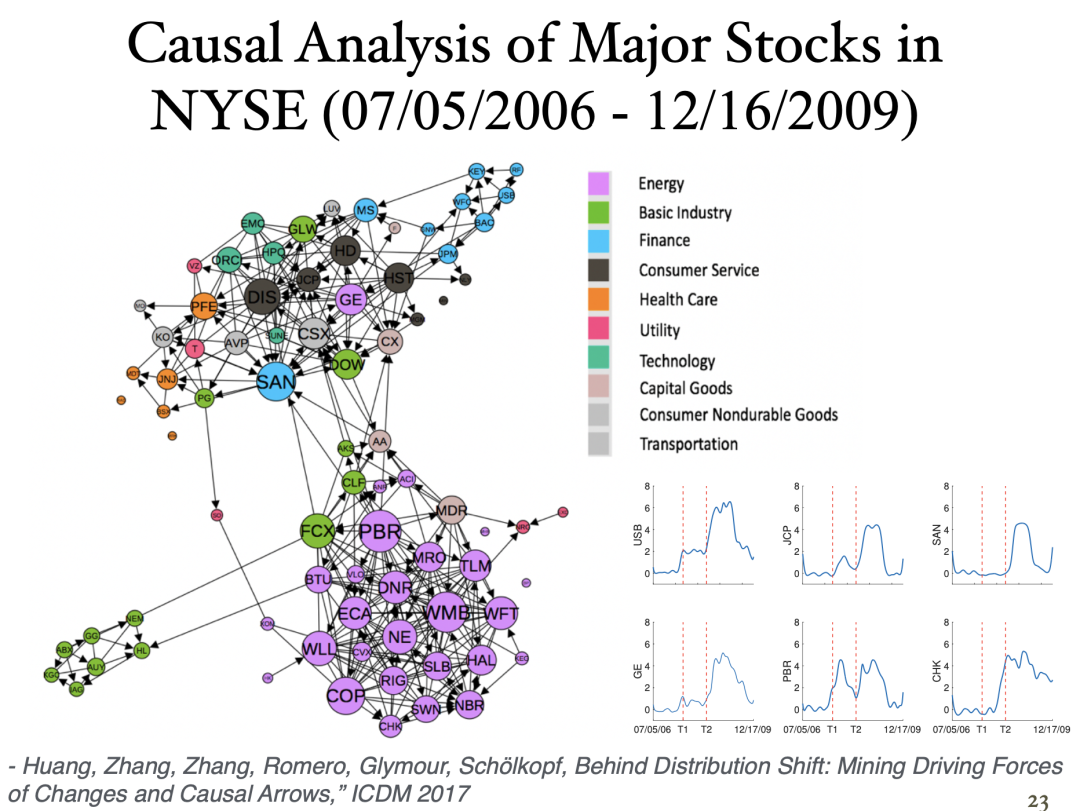
参考文献:Huang, Zhang, Zhang, Romero, Glymour, Schölkopf, ”Behind Distribution Shift: Mining Driving Forces of Changes and Causal Arrows,” ICDM 2017.
前面的例子我们在讨论观测变量背后的因果关系,现在我们更进一步,我们的非暂态性是由一些隐藏成分的分布变化导致的。例如,我们有一堆隐藏成分生成观测变量 X 。现在,我们试图解释 X 的分布为何不同。我们假定存在一组最小的隐藏成分它们的分布变化可以解释联合数据分布的变化。与此同时,其他变量的分布在各种情况下都是一样的。可以证明,这种变化的成分是可识别的,这意味着我们可以真正理解为什么分布在发生变化。领域自适应是最直接的应用。通过类似的手段我们可以找到解释分布变化的最简方式。于是我们就能自动找出在新的场景中哪些地方发生了变化,以及如何对齐不同域的联合分布。然后,很显然,我们就可以利用源域数据进行预测。
参考文献:Kong, Xie, Yao, Zheng, Chen, Stojanov, Akinwande, Zhang, ”Partial disentanglement for domain adaptation,” ICML 2022.
现在生成式人工智能很流行,我们可以使用stable diffusion、ChatGPT来生成大量文本或图片。但在某些情况下,如果问题是完全崭新的,那么生成的结果可能会有点荒谬。为什么会出现这种情况?一般性地,我们认为,这些模型本身并没有真正的概念,也就是人类所拥有的概念的想法。人思考使用概念,而模型使用数据分布。很多时候,它们在做的仍是巧妙的插值而不是外推。因为如果你想超越训练数据本身,就必须真正了解事物是什么,你可以应用什么样的操作。
现在,让我们来考虑一个具体问题,图像到图像的迁移。我们这里有两组图像。其中一组拍摄的是夏天,另一组拍摄的是冬天,它们不是两两配对的。现在,问题是,假设任意给出一张夏天拍摄的照片,如何自动生成这张照片在冬天拍摄的对应版本?这是一个合理且非常重要的问题,因为它关系到如何才能真正理解一个特定的概念,以及以一种合理的方式改变它。
从数学上讲,这可以看成是从边际分布生成联合分布。没有额外的信息这个问题是不可解的,所以我们必须做出进一步的假设。首先我们认为一幅图像由内容和风格两部分生成。图像的迁移意味着内容保持不变但风格发生变化。问题是我们如何才能真正利用一些原理,实现边际分布到联合分布的变换。在这里,我们依靠最小改变原则。我们假设风格变化最小,这意味着对应于风格的组件数量是一个尽可能最小的。此时,整个生成过程是可识别的。例如我们可以知道季节的影响对应于图片中的什么部分等等。
在这里,我们有两个未配对的数据集,分别对应女性和男性。然后我们要做的是生成两张对应不同性别但内容相同的图片。我们要避免任何不必要的改动,尽量保留信息。换句话说,我们需要真的让机器理解性别是什么意思,以及如何真正反映性别信息。我们必须找到机器可以遵循的正确操作。
参考文献:Xie, Kong, Gong, Zhang, ”Multi-domain image generation and translation with identifiability guarantees,” ICLR 2023.
首先,当我们谈论因果表征学习时,我们只是试图恢复潜在变量、潜在混杂因子以及混杂因子之间的关系等等。但实际上,在某些情况下,并不应该用潜在共因来解释。例如,我们体内很多基因之间都是依赖性的。它们相互依赖并不是因为其中一个基因是另一个基因的原因,而是在某种程度上,它们必须以特定的方式共同作用,我们才能生存。即选择偏差导致了基因之间的依赖性。此外,当我们谈论语言和文本时,token之间之所以是依赖性的,不仅仅是因为潜在共因的影响,还有选择偏差的影响。如果我能用这一连串的token让自己明白,我就会用它。否则,我就不会使用它。因此,弄清楚选择过程是非常重要的,这样基于选择过程的因果表征学习也会变得非常清晰。
在独立同分布的情况下,我们通常要假设参数形式。如果系统真的很复杂呢?我们能做什么?所以这里有一些技术或挑战,但我相信几年内就能解决。如果你想解决像视频理解这样的实际问题,那么就必须从因果的原理化表述出发,还要解决很多实际问题。
总结一下,很多学习任务都依赖于某种表征,而因果表示似乎是一种基本的表征类型。例如如果我们想做决策,很明显,我们必须看到我们能改变什么,以及必须预见不同可能行动的后果。
那么,如何才能真正从数据中恢复因果表征或因果结构呢?首先,我们必须制定因果原则,并且这些原则需要是技术上可操作的。可识别性是一个非常重要的问题。一般来说,在非独立同分布的情况下即使存在非暂态性,也可以很容易地得到一些强大的可识别性保证。而在独立同分布情况下,通常必须受益于一些参数化约束。
张坤(Kun Zhang)博士现为美国卡内基梅隆大学以及阿联酋MBZUAI的副教授,研究领域为机器学习和人工智能,尤其是因果发现、基于因果关系的学习以及通用人工智能。他提出了一系列模型与算法用于从各种数据中自动发现因果关系,并与合作者一起开创了从因果思维的角度理解和解决包括迁移学习、概念学习和深度学习等复杂学习问题的研究方向,并研究了因果关系和各种机器学习任务的哲学基础。张坤博士及其团队最近的研究重点为因果表示学习。他长期担任一系列机器学习和人工智能会议的领域主席、资深领域主席或程序委员会主席,包括UAI、NeurIPS、ICML、CLeaR、IJCAI和AISTATS等会议,同时是ACM Computing Surveys和Pattern Recognition等杂志的副主编。
个人主页:https://www.andrew.cmu.edu/user/kunz1/index.html
由智源社区、集智俱乐部联合举办的因果科学与Causal AI读书会第三季,主要面向两类人群:如果你从事计算机相关方向研究,希望为不同领域引入新的计算方法,通过大数据、新算法得到新成果,可以通过读书会各个领域的核心因果问题介绍和论文推荐快速入手;如果你从事其他理工科或人文社科领域研究,也可以通过所属领域的因果研究综述介绍和研讨已有工作的示例代码,在自己的研究中快速开始尝试部署结合因果的算法。读书会直播已结束,欢迎加入因果科学社区,回看第三季直播,加入讨论。

详情请见:
因果+X:解决多学科领域的因果问题 | 因果科学读书会第三季启动
AI+Science 是近年兴起的将人工智能和科学相结合的一种趋势。一方面是 AI for Science,机器学习和其他 AI 技术可以用来解决科学研究中的问题,从预测天气和蛋白质结构,到模拟星系碰撞、设计优化核聚变反应堆,甚至像科学家一样进行科学发现,被称为科学发现的“第五范式”。另一方面是 Science for AI,科学尤其是物理学中的规律和思想启发机器学习理论,为人工智能的发展提供全新的视角和方法。
集智俱乐部联合斯坦福大学计算机科学系博士后研究员吴泰霖(Jure Leskovec 教授指导)、哈佛量子计划研究员扈鸿业、麻省理工学院物理系博士生刘子鸣(Max Tegmark 教授指导),共同发起以“AI+Science”为主题的读书会,探讨该领域的重要问题,共学共研相关文献。欢迎对探索这个激动人心的前沿领域有兴趣的朋友报名参与。