PRL速递:深度神经网络的有限时间Lyapunov指数
关键词:混沌,非线性,Lyapunov指数,深度神经网络


论文题目:Finite-Time Lyapunov Exponents of Deep Neural Networks 论文期刊:Physical Review Letters 论文地址:https://journals.aps.org/prl/abstract/10.1103/PhysRevLett.132.057301
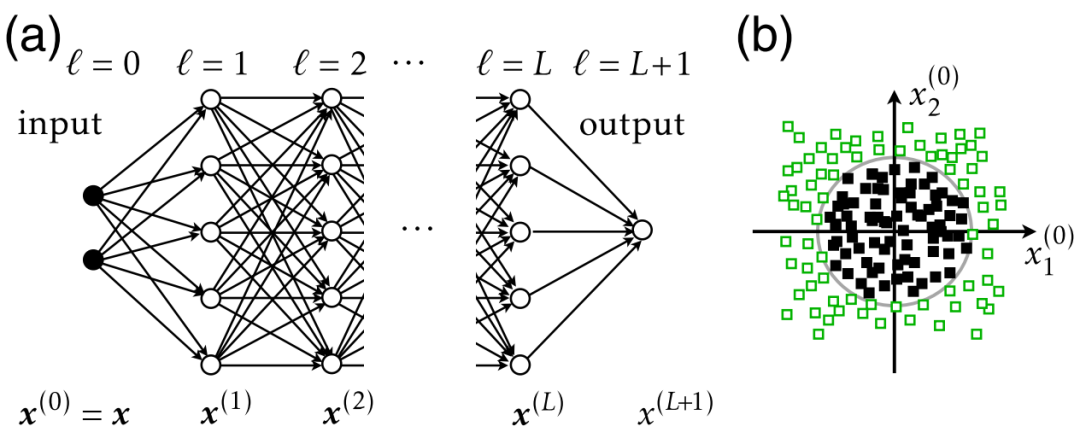
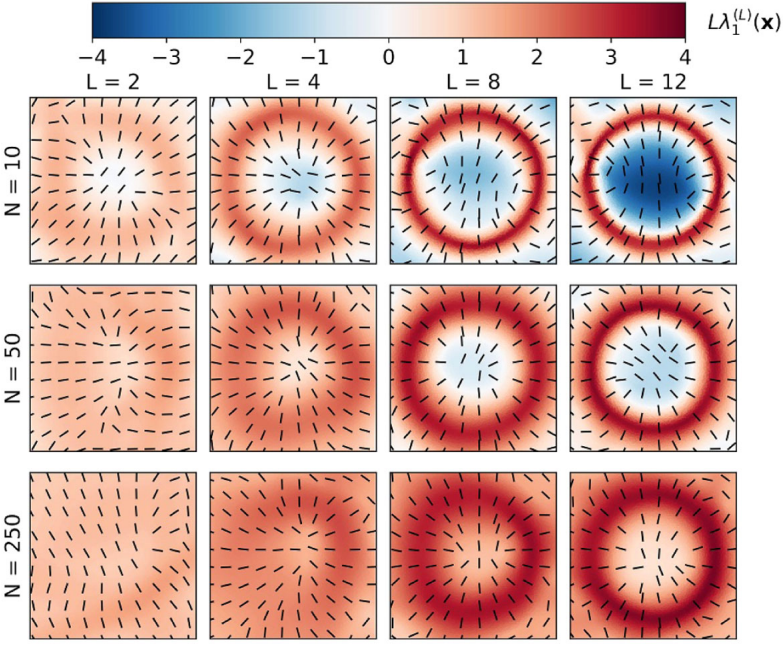
图2 在不同宽度N和深度L的全连接前馈神经网络中,输入空间中的几何 FTLE 结构,这些网络是在图1(b)的数据集上进行训练的。显示了 的大小以及最大的拉伸方向(黑线)。
的大小以及最大的拉伸方向(黑线)。
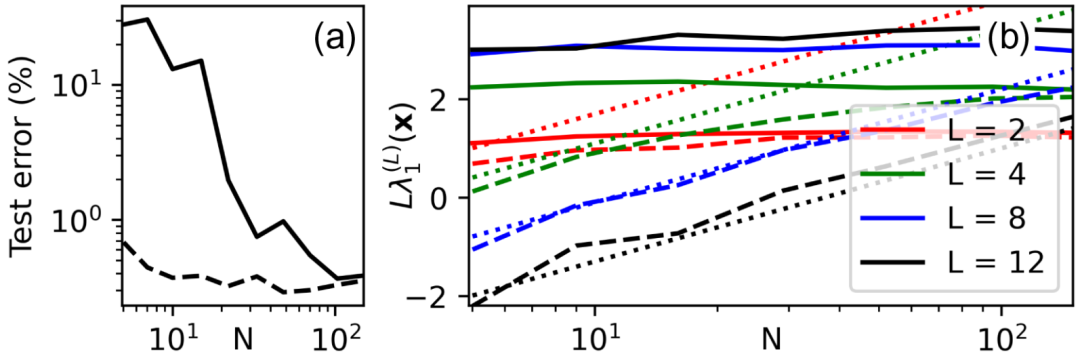
图3 (a) 具有未训练的、随机隐藏权重和经过训练的输出权重的两个隐藏层 L=2 的全连接前馈神经网络在 N 的函数下的分类误差(实线)。同时显示了经过完全训练的网络的分类误差(虚线)。这两条曲线都是对图1中示意的数据集获得的。(b) 对于完全训练的网络,量化在图2中看到的交叉点。显示的是平均值 (实线)和
(实线)和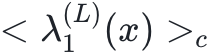 (虚线),详见正文。该数据是通过对独立初始重量实现进行平均获得的。同时,还显示了
(虚线),详见正文。该数据是通过对独立初始重量实现进行平均获得的。同时,还显示了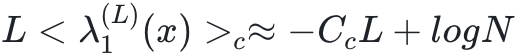 的拟合曲线(点线)。
的拟合曲线(点线)。
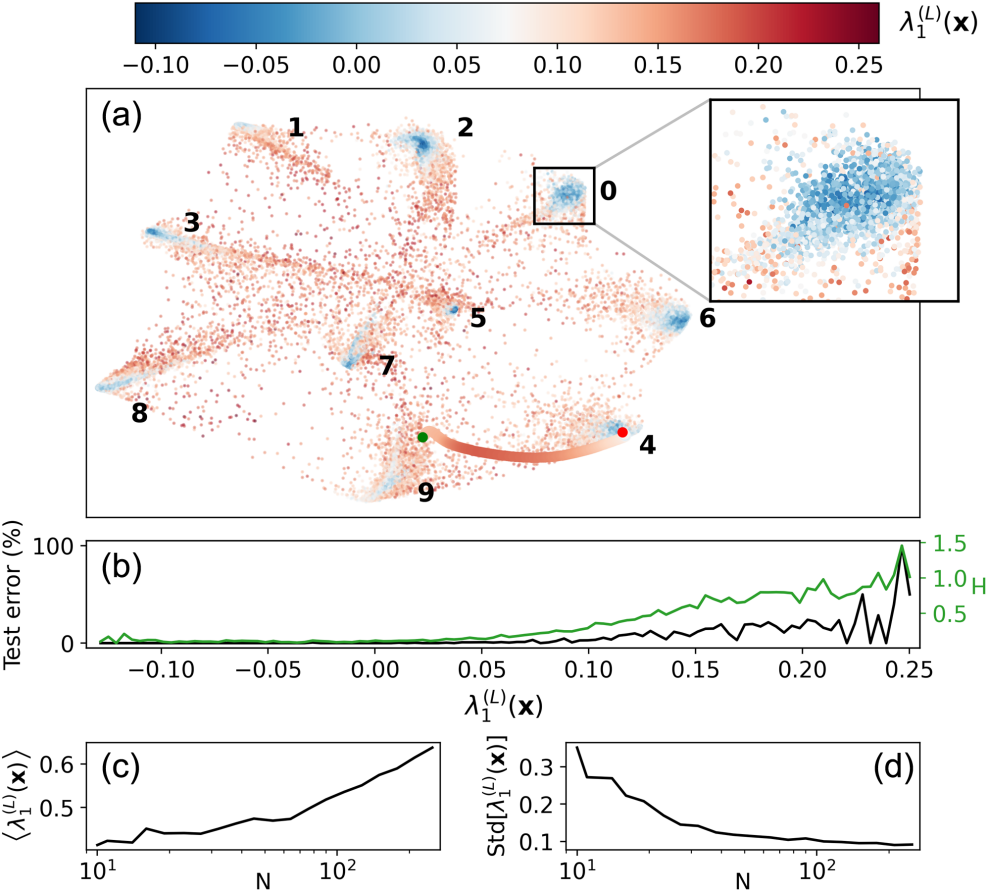
图4 MNIST的最大FTLE场。一个具有每个隐藏层N=20个神经元,L=16个隐藏层和具有十个输出的softmax层的全连接前馈网络被训练到98.88%的分类准确率。对于每个282维输入,计算了最大FTLE并投影到两个维度。(a) 非线性投影中的训练数据。对于每个输入,显示了最大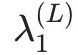 的颜色编码。方框内包含93%的被识别为数字0的样本。还展示了该方框的3倍放大图。彩色线表示从数字9到数字4的对抗攻击,其中以
的颜色编码。方框内包含93%的被识别为数字0的样本。还展示了该方框的3倍放大图。彩色线表示从数字9到数字4的对抗攻击,其中以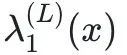 颜色编码。(b) 测试集上的分类错误和预测的不确定性H作为的函数。(c),(d) 最大FTLE分布的均值和标准差与N的变化关系。
颜色编码。(b) 测试集上的分类错误和预测的不确定性H作为的函数。(c),(d) 最大FTLE分布的均值和标准差与N的变化关系。
AI+Science 读书会

点击“阅读原文”,报名读书会
微信扫一扫,分享到朋友圈











