现代生活产生了大量的时序数据和时空数据,分析这些数据对于深入理解现实世界系统的复杂性和演化规律至关重要。近期,受到大语言模型(LLM)在通用智能领域的启发,”大模型+时序/时空数据”这个新方向迸发出了许多相关进展。当前的LLM有潜力彻底改变时空数据挖掘方式,从而促进城市、交通、遥感等典型复杂系统的决策高效制定,并朝着更普遍的时空分析智能形式迈进。
集智俱乐部联合美国佐治亚理工学院博士&松鼠AI首席科学家文青松、香港科技大学(广州)助理教授梁宇轩、中国科学院计算技术研究所副研究员姚迪、澳大利亚新南威尔士大学讲师薛昊、莫纳什大学博士生金明等五位发起人,共同发起以“时序时空大模型”为主题的系列读书会,鼓励研究人员和实践者认识到LLM在推进时序及时空数据挖掘方面的潜力,共学共研相关文献。读书会第一期分享从5月8日(周三)19:00 公开直播,后续分享时间为每周三19:00-21:00(北京时间)进行,预计持续10-12周。读书会详情及参与方式见文末。
研究领域:时空数据挖掘,时间序列,大模型,基座模型,机器学习
时间序列和时空数据蕴含着丰富的动态信息,广泛应用于现实世界中如地球科学、交通运输、医疗保健等领域。它们捕获动态系统的测量值,并由物理和虚拟传感器大量产生。分析这些数据类型对于深入理解现实世界系统的复杂性和演化规律至关重要。
大型语言模型(LLM)主要处理自然语言,但最近的研究将其扩展到时间序列和时空任务(近期,时间序列预测领域的首个大模型TimeGPT引起业界热议,“大模型+时序/时空数据”这个新方向迸发出了许多相关进展),LLM具有强大的学习能力和表示能力,能够有效地捕捉时间序列数据中的复杂模式和长期依赖关系。现有文献主要分为两大类:用于时间序列分析的大型模型(LM4TS)和用于时空数据挖掘的大型模型(LM4STD)。然而,LLM作为“黑匣子”,其预测和决策背后的数据影响难以理解。需要进行更深入的理论分析,以了解语言和时序数据之间的潜在模式相似性,以及如何有效地将其用于特定的时间序列和时空任务。

图1. 大型模型(即语言和其他相关的基础模型)既可以训练,也可以巧妙地重新调整用途,以处理一系列通用任务和专用领域应用中的时间序列和时空数据。

图2. 代表性大型语言模型(左)和其他基础模型(右)的路线图|图片来源:[2310.10196] Large Models for Time Series and Spatio-Temporal Data: A Survey and Outlook (arxiv.org)
尽管LLM取得了重大进展,但具有时空时序数据能力的人工通用智能(AGI)的发展仍处于早期阶段。大多数现有的机器学习或深度学习模型严重依赖于领域知识和广泛的模型调整,主要关注预测任务。事实上,我们认为当前的LLM有潜力彻底改变时空时序数据挖掘,从而促进高效的决策制定,并朝着更普遍的时空分析智能形式迈进。为此,以“时序时空大模型”为主题的系列读书会,旨在鼓励研究人员和实践者认识到大模型在推进时序时空数据挖掘方面的潜力,通过共学共研相关文献与面向典型复杂系统(如城市、交通、遥感等)的应用案例,形成对时序时空大模型技术演进方向的一致认知。相信随着技术的不断发展和创新,大模型的应用潜力将进一步释放,可为时间序列分析和时空数据挖掘带来更多的可能性和价值。
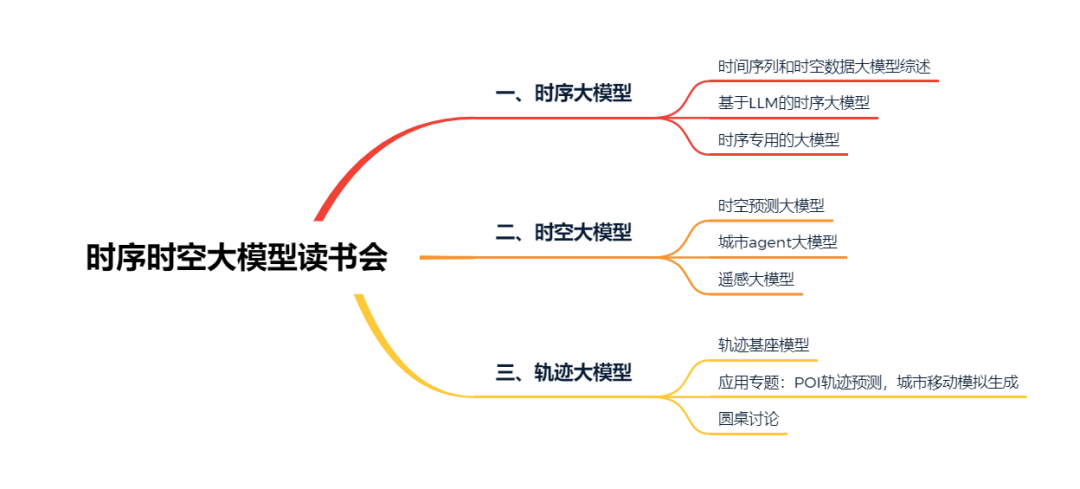
时序数据、时空数据是刻画各类复杂系统动态行为的重要维度。以往的时序时空数据研究,主要依赖于统计学方法、时间序列分析技术、地理信息技术、机器学习方法等,但传统模型在可解释性、多源数据融合、非线性、实时预测等方面尚且面临局限与挑战。随着深度学习架构蓬勃发展,尤其是近几年大语言模型技术的异军突起,一系列时序时空数据处理方法涌现出来。其中,时序大模型主要用于分析时间序列数据,以识别复杂系统随时间变化的模式,建立预测模型;时空大模型主要用于分析和预测复杂系统中空间和时间维度的相互作用,揭示揭示空间分布如何随时间变化,以及不同地理位置之间的相互作用。轨迹大模型则结合了时序和时空分析的特点,分析对象在时间空间中的移动路径。随着大模型等技术的进一步发展,时序时空大模型的方法创新正层出不穷,我们对复杂系统动态行为的认识、对干预策略的设计都将获得提升。

梁宇轩,香港科技大学(广州)智能交通学域、数据科学与分析学域助理教授、博士生导师。长期从事人工智能与时空数据挖掘技术在城市计算、智能交通等领域的跨学科交叉研究。在TPAMI、TKDE、AI Journal、KDD、WWW、NeurIPS、ICLR等多个权威国际期刊和会议发表高水平论文60余篇,其中CCF A类论文达40余篇。谷歌学术引用量3400余次,h-index为28,多篇论文入选最具影响力KDD/IJCAI论文。长期担任TKDE、TMC、TNNLS等国际知名期刊审稿人,KDD、WWW、NeurIPS、ICML、ICLR等国际顶级会议程序委员会成员,曾获评SIGSPATIAL杰出程序委员会成员。多次担任数据挖掘和人工智能顶会 (KDD、IJCAI等) Workshop on Urban Computing, Workshop on AI for Time Series的联合主席。曾获得新加坡数据科学联合会论文研究奖,第二十三届中国专利优秀奖等海内外奖项。

姚迪,中国科学院计算技术研究所副研究员,硕士生导师,中国计算机学会大数据专委会委员,ACM SIGSPATIAL中国分会执行委员,主要研究方向为时空数据挖掘,异常检测,因果机器学习等。在KDD、WWW、ICDE、TKDE等领域内顶级学术会议和期刊发表论文30余篇,长期担任担任多个期刊会议的审稿人和程序委员会委员,获得中科院院长优秀奖,MDM最佳论文候选奖,入选微软亚洲研究院“铸星计划”,研究成果在阿里、网易、滴滴等多个互联网公司中应用。

薛昊,目前在澳大利亚新南威尔士大学(UNSW Sydney)计算机科学与工程学院担任讲师职位。他于2020年从西澳大利亚大学获得博士学位。在完成博士学位后,曾在RMIT大学计算技术学院和UNSW Sydney工作过。目前是澳大利亚国家科研委员会(ARC)卓越决策与社会自动化中心(ADM+S)UNSW分支的副研究员。研究兴趣包括时空数据建模、时间序列预测、基于语言生成的预测以及时间序列表示学习。

金明,澳大利亚蒙纳士大学(Monash University)博士。长期从事图神经网络与时序数据挖掘相关研究,在ICLR、NeurIPS、IJCAI、TNNLS、TKDE等多个权威国际期刊/会议发表高水平论文20余篇,谷歌学术引用量近1000余次,其科研工作曾入选IJCAI最具影响力论文。长期担任NeurIPS、ICLR、ICML、TPAMI、TNNLS、TKDE等国际知名会议/期刊程序委员会成员。研究兴趣包括时序/时空数据挖掘和动态图神经网络。
个人主页:https://mingjin.dev/

文青松,美国佐治亚理工学院(Georgia Tech)电子与计算机工程博士,人工智能、决策智能和信号处理方向专家,在松鼠AI、阿里、Marvell等公司超10年的技术和管理经验,近100篇文章发表在人工智能相关的顶会与顶刊,多篇文章被AI顶会(NeurIPS, ICLR等)评选为Oral/Spotlight论文,两次入选IJCAI最具影响力论文并排名第一,两次获得AAAI人工智能系统部署应用奖,获得ICASSP Grand Challenge冠军。近期研究兴趣为智能时序与AI教育, 也是AI顶会 (AAAI, IJCAI, KDD, ICDM等) Workshop on AI for Time Series, Workshop on AI for Education的主要组织者之一。
个人主页: https://sites.google.com/site/qingsongwen8
张屹莉,中山大学数学硕士,现从事大模型数据分析/产品相关工作。
-
基于时间序列分析和时空数据挖掘相关领域研究,对时序数据大模型,特别是时序时空大模型研究中的模型、方法有浓厚兴趣的一线科研工作者;
-
能基于读书会所列主题和文献进行深入探讨,可提供适合的文献和主题的朋友;
-
能熟练阅读英文文献,并对复杂科学充满激情,对世界的本质充满好奇的探索者;
-
想锻炼自己科研能力或者有出国留学计划的高年级本科生及研究生。
本读书会谢绝参与的对象
为确保专业性和讨论的聚焦,本读书会谢绝脱离读书会文本和复杂科学问题本身的空泛的哲学和思辨式讨论;不提倡过度引申在社会、人文、管理、政治、经济等应用层面的讨论。我们将对参与人员进行筛选,如果出现讨论内容不符合要求、经提醒无效者,会被移除群聊并对未参与部分退费。一切解释权归集智俱乐部所有。
运行模式
本季读书会涉及【时序大模型】、【时空大模型】、【轨迹大模型】3个模块,按暂定框架贯次展开;
每周进行线上会议,由 1-2 名读书会成员以PPT讲解的形式领读相关论文,与会者可以广泛参与讨论,会后可以获得视频回放持续学习。
举办时间
从 2024 年 05 月 08 日开始,每周三晚 19:00-21:00(北京时间),持续时间预计 10-12 周。
我们也会对每次分享的内容进行录制,剪辑后发布在集智斑图网站上,供读书会成员回看,因此报名的成员可以根据自己的时间自由安排学习时间。
参与方式
本季读书会为线上读书会,参与方式有两种:
加入读书会社区。报名加入读书会,即可解锁完整权限,包括线上问答、录播回看、资料共享、社群交流、信息同步、共创协作等。扫码完成报名并添加负责人微信(报名成功后显示微信二维码名片),负责人会邀请您加入交流群。每期读书会将在群内发布腾讯会议房间号(请提前下载安装)。
观看线上直播。读书会的主题分享部分,会在集智俱乐部平台在线直播。请关注后续直播预告。
报名方式
扫码报名
第三步:添加负责人微信,拉入对应主题的读书会社区(微信群)。
针对学生的退费机制
读书会通过共学共研的机制,围绕前沿主题进行内容梳理和沉淀,所以针对于学生,可以通过参与共创任务,获取积分,积分达到退费标准之后,可以直接退费。
加入社区后可以获得的资源
-
在线会议室沉浸式讨论:与主讲人即时讨论交流
-
交互式播放器高效回看:快速定位主讲人提到的术语、论文、大纲、讨论等重要时间点
-
高质量的主题微信社群:硕博比例超过80%的成员微信社区,闭门夜谈和交流
-
超多学习资源随手可得:从不同尺度记录主题下的路径、词条、前沿解读、算法、学者等
-
参与社区内容共创任务:读书会笔记、百科词条、公众号文章、论文解读分享等不同难度共创任务,在学习中贡献,在付出中收获
-
共享追踪主题前沿进展:在群内和公众号分享最新进展,领域论文速递
-
获得相关岗位内推机会:新兴前沿技术公司的直通面试资格
参与共创任务,共建学术社区
-
读书会笔记:在交互式播放器上记录术语和参考文献
-
集智百科词条:围绕读书会主题中重要且前沿的知识概念梳理成词条。例如:
-
论文解读分享:认领待读列表中的论文,以主题报告的形式在社区分享
-
论文摘要翻译:翻译社区推荐论文中的摘要和图注
-
公众号文章:以翻译整理或者原创生产形式生产公众号文章,以介绍前沿进展。例如:
– 多者异也:破缺的对称性与科学层级结构的本质
– 诺奖委员会万字评述:为什么复杂系统研究受诺贝尔物理学奖青睐?
– 从生命起源到流行病:复杂系统中的多尺度涌现现象
– 涌现:21世纪科学的统一主题
– 从麦克斯韦妖到量子生物学,生命物质中是否潜藏着新物理学?
– 大脑热力学:利用“湍流”远离平衡态
– 张江:从图网络到因果推断,复杂系统自动建模五部曲
– 粗看长尾,细辨幂律:跨世纪的无标度网络研究纷争史
– Erik Hoel:因果涌现理论怎样连通复杂系统的宏观与微观
PS:具体参与方式可以加入读书会后查看对应的共创任务列表,领取任务,与运营负责人沟通详情,上述规则的最终解释权归集智俱乐部所有。
阅读材料较长,为了更好的阅读体验,建议您前往集智斑图沉浸式阅读,并可收藏感兴趣的论文。
https://pattern.swarma.org/article/293
(一) 时序大模型
-
综述类
[1] Ming Jin, Qingsong Wen, Yuxuan Liang, et al. Large Models for Time Series and Spatio-Temporal Data: A Survey and Outlook. arXiv.org, 2023, abs/2310.10196
该综述主要将现有文献分类为两大类:时间序列分析的大型模型(LM4TS)和时空数据挖掘(LM4STD)。基于此,论文进一步根据模型范围(即通用与特定领域)和应用领域/任务对研究进行分类。论文还提供了一个全面的相关资源集合,其中包括数据集、模型资产和有用的工具,按主流应用进行分类。该综述汇集了关于时间序列和时空数据的大型模型为中心的研究的最新进展,强调了坚实的基础、当前的进展、实际应用、丰富的资源和未来的研究机会。
[2] Jing Su, Chufeng Jiang, Xin Jin, et al. Large Language Models for Forecasting and Anomaly Detection: A Systematic Literature Review. arXiv.org, 2024, abs/2402.10350
该综述探讨了大型语言模型在预测和异常检测中的应用,并突出介绍了LLMs在解析大数据、识别模式和预测事件方面的潜力。文中指出了若干个挑战,包括依赖庞大历史数据集、不同情境中的泛化问题、模型幻觉现象、模型知识边界的限制以及所需的大量计算资源。通过详细分析,综述讨论了克服这些障碍的潜在解决方案和策略,如整合多模态数据、改进学习方法、提高模型解释性和计算效率。综述最后强调,尽管LLMs在预测和异常检测方面展现出颠覆性的影响力,但要充分发挥其潜能,还需要不断创新、考虑伦理问题,并寻求切实可行的解决方案。
[3] Xiyuan Zhang, Ranak Roy Chowdhury, Rajesh K. Gupta, et al. Large Language Models for Time Series: A Survey. arXiv.org, 2024, abs/2402.01801
该综述详细探讨了大型语言模型(LLMs)在时间序列数据分析中的应用潜力,突破了传统的文本和图像领域的界限。它集中在如何克服“LLMs原始训练数据为文本,而时间序列数据通常为数值这一模态差异”的挑战上。论文详细分类并讨论了各种方法,包括直接提示(Prompting)、时间序列量化(Quantization)、对齐技术(Alignment)、利用视觉模态作为桥梁(Vision as Bridge),以及将LLMs与工具结合使用(Tool)。它还涵盖了现有的多模态时间序列和文本数据集,并探讨了这一新兴领域的挑战和未来发展方向。综述提供了一个关于“如何利用LLMs进行时间序列分析”的全面框架,并提供了对实践应用和未来研究的深入见解。
[4] John A. Miller, Mohammed Aldosari, Farah Saeed, et al. A Survey of Deep Learning and Foundation Models for Time Series Forecasting. arXiv:2401.13912, 2024
该综述提供了深度学习和基础模型在时间序列预测领域的全面回顾。
[5] Yuxuan Liang, Haomin Wen, Yuqi Nie, et al. Foundation Models for Time Series Analysis: A Tutorial and Survey. arxiv.org, 2024, abs/2403.14735
该综述旨在提供关于时间序列分析的基座模型(FM)的全面概述。现有相关综述主要关注FM在时间序列分析中的应用或流程方面,但它们通常缺乏对FM为何以及如何帮助时间序列分析的基本机制的深入理解。为了解决这个问题,该综述采用以方法论为中心的分类,勾勒出时间序列FM的各种关键要素,包括模型架构、预训练技术、适应方法和数据模态。此外,该综述还探讨了时间序列FM未来可能的研究方向。
-
基于LLM的时序大模型
[6] Xu Liu, Junfeng Hu, Yuan Li, et al. UniTime: A Language-Empowered Unified Model for Cross-Domain Time Series Forecasting. arXiv.org, 2023, abs/2310.09751
该论文提出了一种统一的模型范式(UniTime),它能够跨越不同领域进行时间序列预测,而不是为每个特定的时间序列应用领域创建专用模型。
[7] Zijie Pan, Yushan Jiang, Sahil Garg, et al. S2IP-LLM: Semantic Space Informed Prompt Learning with LLM for Time Series Forecasting. arXiv:2403.05798, 2024
该论文提出了一种将时间序列在隐空间和NLP大模型对齐,并利用隐空间prompt提升时间序列预测效果的方法。
[8] Defu Cao, Furong Jia, Sercan O Arik, et al. TEMPO: Prompt-based Generative Pre-trained Transformer for Time Series Forecasting. arXiv:2310.04948, 2023
文献解读推文:https://zhuanlan.zhihu.com/p/670183566
该论文利用生成式预训练Transformer和基于prompt的学习来提高预测任务的准确性和适应性。模型有效地将时间序列分解为趋势、季节性和残差三个部分,并使用基于选择的prompt更好地处理非平稳时间序列。
[9] Hao Xue, Flora D. Salim. PromptCast: A New Prompt-based Learning Paradigm for Time Series Forecasting. arXiv:2210.08964, 2023
PromptCast成功开创了时间序列预测的全新视角,巧妙地将时间序列预测任务转换为基于提示的自然语言处理问题。该研究工作巧妙地将时序数据转化为文本数据,将传统的时序预测任务创新性地转化为对话预测任务。这一突破性方法,借助语言模型的强大能力,成功应用于时序数据的预测。论文中提出的PISA数据集为这一领域的研究提供了宝贵资源,其详尽的实验分析和评估结果展示了PromptCast在多种预测情景下的优越性能和强大的泛化能力,确立了其在TS4LLM的创新地位。
[10] Ching Chang, Wei-Yao Wang, Wen-Chih Peng, et al. LLM4TS: Aligning Pre-Trained LLMs as Data-Efficient Time-Series Forecasters. arXiv:2308.08469, 2024
该论文通过结合时间序列分块和时间编码技术,利用预训练的大型语言模型(LLMs)增强时间序列预测的能力。
[11] Chenxi Sun, Hongyan Li, Yaliang Li, et al. TEST: Text Prototype Aligned Embedding to Activate LLM’s Ability for Time Series. arXiv:2308.08241, 2024
该论文重点关注了TS-for-LLM方法,旨在通过设计一种适合LLM的TS嵌入方法来激活LLM对TS数据的处理能力。所提出的方法被命名为TEST。
[12] Tian Zhou, PeiSong Niu, Xue Wang, et al. One Fits All:Power General Time Series Analysis by Pretrained LM. arXiv:2302.11939, 2023
该论文介绍了一种利用预训练的语言模型或计算机视觉模型进行通用时间序列分析的方法。作者提出了一种名为Frozen Pretrained Transformer(FPT)的模型,通过在涉及时间序列的各种任务上进行微调,展示了预训练模型在时间序列分析中取得可比或最先进的性能。
[13] Ming Jin, Shiyu Wang, Lintao Ma, et al. Time-LLM: Time Series Forecasting by Reprogramming Large Language Models. arXiv:2310.01728, 2024
文献解读推文:https://segmentfault.com/a/1190000044701270
TIME-LLM提出了一个重编程(Reprograming)框架,利用LLMs进行通用时间序列预测。它通过文本原型重新编程输入时间序列,并利用Prompt-as-Prefix(PaP)来增强LLM处理时间序列数据的能力。经过全面评估,TIME-LLM在预测性能上优于专门化预测模型,并在少样本和零样本学习场景中表现出色。TIME-LLM探索了使用大语言模型做时序分析任务的可能性,提出了对大语言模型做重编程的概念,同时发现和验证了时序任务本身可以抽象成一种能够被大语言模型解决的特殊语言任务。
[14] Zheng Zhang, Hossein Amiri, Zhenke Liu, et al. Large Language Models for Spatial Trajectory Patterns Mining. arXiv:2310.04942, 2023
该论文探讨了使用LLMs来检测人类空间轨迹数据中的异常行为的能力。本文发现LLMs在没有特定线索的情况下也能够达到合理的异常检测性能,在提供上下文线索后可以进一步提高预测效果。
[15] Nate Gruver, Marc Finzi, Shikai Qiu, et al. Large Language Models Are Zero-Shot Time Series Forecasters. arXiv:2310.07820, 2023
该论文表明,通过将时间序列编码为文本形式,LLMs可以在zero-shot条件下对时间序列进行有效外推,其性能甚至可以超过专门训练的时间序列模型。
-
时序专用的大模型
[16] Shanghua Gao, Teddy Koker, Owen Queen, et al. UniTS: Building a Unified Time Series Model. arXiv:2403.00131, 2024
该论文提出了一个统一的时间序列模型,支持通用任务规范,包括分类、预测、填补和异常检测等任务。
[17] Kashif Rasul, Arjun Ashok, Andrew Robert Williams, et al. Lag-Llama: Towards Foundation Models for Probabilistic Time Series Forecasting. arXiv:2310.08278, 2024
该论文提出了一个通用的单变量概率时间序列预测模型,该模型在未见过的的时间序列数据集上表现出良好的zero-shot预测能力。
[18] Gerald Woo, Chenghao Liu, Akshat Kumar, et al. Unified Training of Universal Time Series Forecasting Transformers. arXiv:2402.02592, 2024
该论文提出了一种基于Masked Encoder的统一时间序列预测模型,该模型旨在解决时间序列数据面临的跨频率学习、多变量时间序列的任意变量数目以及大规模数据中不同分布特性的挑战。
[19] Azul Garza, Max Mergenthaler-Canseco. TimeGPT-1. arXiv:2310.03589, 2023
文献解读推文:https://zhuanlan.zhihu.com/p/665409859
业界首个时序基础模型TimeGPT,并开放了相关模型的API(https://docs.nixtla.io/)供用户体验。
[20] Abhimanyu Das, Weihao Kong, Rajat Sen, et al. A decoder-only foundation model for time-series forecasting. arXiv:2310.10688, 2024
文献解读推文:https://zhuanlan.zhihu.com/p/683799427
该论文提出了一种基于Decoder的时间序列预测基础模型,名为TimesFM。该工作的关键在于构建了一个时间序列预测数据集,该数据集由Google trends, Wiki Pageviews和合成数据组成。
[21] Abdul Fatir Ansari, Lorenzo Stella, Caner Turkmen, et al. Chronos: Learning the Language of Time Series. arXiv:2403.07815, 2024
亚马逊最新时序预训练模型,使用缩放和量化将时间序列值标记为Token,并通过交叉熵损失在这些token的时间序列上训练现有的Transformer语言模型架构。
(二)时空大模型
[22] Xingchen Zou, Yibo Yan, Xixuan Hao, et al. Deep Learning for Cross-Domain Data Fusion in Urban Computing: Taxonomy, Advances, and Outlook. arXiv:2402.19348, 2024
随着城市的不断发展,城市计算通过利用不同来源(例如地理、交通、社交媒体和环境数据)和模态(例如时空数据,视觉和文本模态)的跨域数据融合的力量,成为可持续发展的关键学科。最近,看到利用各种深度学习方法促进智慧城市跨域数据融合的上升趋势。为此,提出了第一篇综述——系统地回顾了为城市计算量身定制的基于深度学习的数据融合方法的最新进展。与之前的综述相比,本文更关注深度学习方法与城市计算应用的协同作用。此外,还阐明了大型语言模型(LLM)和城市计算之间的相互作用,提出了可能彻底改变该领域的未来研究方向。
[23] Yibo Yan, Haomin Wen, Siru Zhong, et al. When Urban Region Profiling Meets Large Language Models. arXiv:2310.18340, 2023
该论文提出了UrbanCLIP,首次使用大语言模型来描述遥感图像生成文本,再使用CLIP框架进行文本和图像对齐,从而学习到高质量的城市区域embedding,增益多种下游应用。
[24] Vicente Vivanco Cepeda, Gaurav Kumar Nayak, Mubarak Shah. GeoCLIP: Clip-Inspired Alignment between Locations and Images for Effective Worldwide Geo-localization. arXiv:2309.16020, 2023
该论文启发自CLIP的地点和图像之间的对齐,用于有效的全球地理定位。
[25] Zhonghang Li, Lianghao Xia, Jiabin Tang, et al. UrbanGPT: Spatio-Temporal Large Language Models. arXiv:2403.00813, 2024
该论文提出了UrbanGPT,它将时空依赖编码器与指令微调范式无缝集成到一起。这种集成使得语言模型能够理解时间和空间之间的复杂相互依赖关系,在数据稀缺的情况下进行更全面、更准确的预测。
[26] Yuan Yuan, Jingtao Ding, Jie Feng, et al. UniST: A Prompt-Empowered Universal Model for Urban Spatio-Temporal Prediction. arXiv:2402.11838, 2024
该论文提出了UniST,一个基于提示的通用模型,通过灵活处理多样化时空数据、有效的生成预训练和时空知识引导的提示,实现了在多个城市和领域中的卓越泛化能力和城市时空预测性能。
[27] Yilong Ren, Yue Chen, Shuai Liu, et al. TPLLM: A Traffic Prediction Framework Based on Pretrained Large Language Models. arXiv:2403.02221, 2024
该论文提出了一个名为TPLLM(基于预训练大型语言模型的交通预测框架)的新型交通预测框架,旨在利用预训练的大型语言模型(LLMs)的强大能力和少量样本学习(few-shot learning)的特性,来提高交通预测的准确性和泛化能力。
[28] Chenxi Liu, Sun Yang, Qianxiong Xu, et al. Spatial-Temporal Large Language Model for Traffic Prediction. arXiv:2401.10134, 2024
该论文提出了一种新的时空大型语言模型(ST-LLM),该模型通过将每个位置的时间步重新定义为标记,并结合时空嵌入模块来学习标记的空间位置和全局时间表示。此外,还提出了一种新的部分冻结注意力策略,旨在捕捉交通预测中的时空依赖性。通过在真实交通数据集上的综合实验,论文证明了ST-LLM优于现有最先进的模型,并且在少样本和零样本预测场景中也表现出强大的性能。
[29] Siqi Lai, Zhao Xu, Weijia Zhang, et al. LLMLight: Large Language Models as Traffic Signal Control Agents. arXiv:2312.16044, 2024
该框架向智能体提供详细的实时交通状况,并结合先验知识构成提示,利用大模型卓越的泛化能力,采用符合人类直觉的推理和决策过程来实现有效的交通控制。在九个交通流数据集上的实验证明了LLMLight框架的有效性、泛化能力和可解释性。
[30] Zhilun Zhou, Yuming Lin, Yong Li. Large language model empowered participatory urban planning. arXiv:2402.01698, 2024
这项研究引入了一种创新的城市规划方法,将大语言模型(LLM)整合到居民参与过程中。该框架基于精心设计的 LLM 主体,由角色扮演、协作生成和反馈迭代组成,解决了满足 1000 个不同兴趣的社区级土地利用任务。
(三)轨迹大模型
[31] Wei Chen, Yuxuan Liang, Yuanshao Zhu, et al. Deep Learning for Trajectory Data Management and Mining: A Survey and Beyond. arXiv:2403.14151, 2024
该论文全面回顾了深度学习在轨迹数据管理和挖掘的发展和最新进展。首先定义轨迹数据并简要概述了广泛使用的深度学习模型。系统地探索了深度学习在轨迹管理(预处理、存储、分析和可视化)和挖掘(轨迹相关预测、轨迹相关推荐、轨迹分类、行程时间估计、异常检测和移动性生成)中的应用。值得注意的是,本文还概括了大型语言模型(LLM)的最新进展,这些进展具有增强轨迹计算的潜力。此外,本文总结了应用场景、公共数据集和工具包。并最后概述了 DL4Traj 研究当前面临的挑战并提出了未来的方向。
[32] Yanchuan Chang, Jianzhong Qi, Yuxuan Liang, et al. Contrastive Trajectory Similarity Learning with Dual-Feature Attention. arXiv:2210.05155, 2023
该论文提出了一个名为TrajCL的自监督轨迹相似性学习方法,该方法结合了对比学习和双特征自注意力轨迹编码器(DualSTB)。TrajCL通过四个轨迹增强方法和对比学习框架来生成轨迹的不同变体,并通过DualSTB编码器将轨迹嵌入到能够捕捉轨迹间空间距离相关性的向量中。
[33] Jiawei Jiang, Dayan Pan, Houxing Ren, et al. Self-supervised Trajectory Representation Learning with Temporal Regularities and Travel Semantics. arXiv:2211.09510, 2024
该论文提出了一个名为START的自监督轨迹表示学习框架,该框架通过两个阶段整合了时间规律性和旅行语义,以生成适用于多种下游任务的通用低维轨迹表示向量。改工作设计了两种自监督任务,即跨度掩蔽轨迹恢复和轨迹对比学习,以在训练过程中引入轨迹的空间-时间特征。
[34] Xinglei Wang, Meng Fang, Zichao Zeng, et al. Where Would I Go Next? Large Language Models as Human Mobility Predictors. arXiv:2308.15197, 2024
该论文探讨了大型语言模型在人类移动性预测任务中的潜力。作者提出了一个名为LLM-Mob的新方法,该方法利用LLMs的语言理解和推理能力来分析人类移动性数据。通过历史停留和上下文停留的概念,LLM-Mob能够捕捉人类移动的长期和短期依赖性,并使用目标停留的时间信息进行时间感知预测。此外,作者设计了包含上下文的提示,使LLMs能够生成更准确的预测。
[35] Haru Terashima, Naoki Tamura, Kazuyuki Shoji, et al. Human Mobility Prediction Challenge: Next Location Prediction using Spatiotemporal BERT. HuMob-Challenge@SIGSPATIAL, 2023
[36] Weijia Zhang, Jindong Han, Zhao Xu, et al. Towards Urban General Intelligence: A Review and Outlook of Urban Foundation Models. arXiv:2402.01749, 2024
该论文是关于城市基础模型(Urban Foundation Models, UFMs)的综述和展望。文章首先介绍了城市通用智能(Urban General Intelligence, UGI)的概念,这是一种针对城市系统和环境的高级人工智能形式。文章强调了机器学习技术在提升城市服务智能化、效率和宜居性方面的关键作用,特别是基础模型在理解和适应城市环境方面的巨大潜力。
[37] Zheng Zhang, Hossein Amiri, Zhenke Liu, et al. Large Language Models for Spatial Trajectory Patterns Mining. arXiv:2310.04942, 2023
该论文探讨了大型语言模型在检测人类空间轨迹模式方面的潜力。这篇文章的研究表明,即使没有特定的线索,LLMs如GPT-4和Claude-2也能够实现合理的异常检测性能。此外,提供关于潜在不规则性的上下文线索可以进一步提高它们的预测效率。
[38] Chenyang Shao, Fengli Xu, Bingbing Fan, et al. Beyond Imitation: Generating Human Mobility from Context-aware Reasoning with Large Language Models. arXiv:2402.09836, 2024
该论文提出了一个名为MobiGeaR的新型框架,以利用利用大型语言模型生成更接近人类真实行为的移动性数据。MobiGeaR通过设计一种上下文感知的链式思考提示技术,使LLM能够递归地生成移动行为,并结合机械重力模型来映射活动意图到具体地点。
[39] Jiawei Wang, Renhe Jiang, Chuang Yang, et al. Large Language Models as Urban Residents: An LLM Agent Framework for Personal Mobility Generation. arXiv:2402.14744, 2024
该论文提出了一个名为LLMob的新型框架,该框架利用大型语言模型作为智能主体来生成个人的移动性活动轨迹。该方法通过结合LLMs的语义解释能力和模型的多样性,有效地与真实世界的活动数据对齐,并开发了可靠的活动生成策略,并且能够适应特定情境,如疫情情况下的城市流动性模拟。
致谢:感谢此次读书会发起人梁宇轩、姚迪、薛昊、金明、文青松五位老师对读书会的大力支持以及推荐的论文阅读材料。
主办方:集智俱乐部
协办方:集智学园
集智俱乐部成立于 2003 年,是一个从事学术研究、享受科学乐趣的探索者的团体,也是国内最早的研究人工智能、复杂系统的科学社区。它倡导以平等开放的态度、科学实证的精神,进行跨学科的研究与交流,力图搭建一个中国的 “没有围墙的研究所”。
集智学园成立于2016年,是集智俱乐部孕育的创业团队。集智学园致力于传播复杂性科学、人工智能等前沿知识和新兴技术,促进、推动复杂科学领域的知识探索与生态构建。
集智俱乐部读书会是面向广大科研工作者的系列论文研读活动,其目的是共同深入学习探讨某个科学议题,了解前沿进展,激发科研灵感,促进科研合作,降低科研门槛。
读书会活动始于 2008 年,至今已经有 50 余个主题,内容涵盖复杂系统、人工智能、脑与意识、生命科学、因果科学、高阶网络等。凝聚了众多优秀科研工作者,促进了科研合作发表论文,孵化了许多科研产品。如:2013 年的“深度学习”读书会孕育了彩云天气 APP,2015 年的“集体注意力流”读书会产生了众包书籍《走近2050》,2020年的开始因果科学读书会孕育了全国最大的因果科学社区等。