AI by Complexity 读书会启动:复杂性怎样量化和驱动下一代AI系统

导语
读书会背景
读书会背景
与复杂科学的关系
与复杂科学的关系
读书会框架
读书会框架
发起人团队
发起人团队


报名参与读书会
报名参与读书会
本读书会适合参与的对象
-
基于复杂系统相关学科研究,对统计物理、复杂网络、信息论、复杂系统临界性等视角启发AI系统构建与研究有浓厚兴趣的科研工作者;
-
具有一定统计物理、信息论、复杂网络、神经科学以及计算机科学的学科背景,在领域内有一定的研究基础,想进一步进行交叉学科研究与交流的学者、研究生、本科生。
-
对复杂科学充满激情,对世界,特别是“AI是否能成为一个真正的复杂系统”充满好奇的探索者,且具备一定的英文文献阅读能力的探索者。
-
想锻炼自己科研能力或者有出国留学计划的高年级本科生及研究生。
社群管理规则
运行模式
举办时间
参与方式
报名方式

扫码报名
第二步:填写信息后,付费299元。
共学共研模式与退费机制
加入社区后可以获得的资源:
-
在线会议室沉浸式讨论:与主讲人即时讨论交流。
-
交互式播放器高效回看:快速定位主讲人提到的术语、论文、大纲、讨论等重要时间点(详情请见:解放科研时间,轻松掌握学术分享:集智斑图推出可交互式播放器)
-
高质量的主题微信社群:硕博比例超过80%的成员微信社区,闭门夜谈和交流
-
超多学习资源随手可得:从不同尺度记录主题下的路径、词条、前沿解读、算法、学者等。
-
参与社区内容共创任务:读书会笔记、百科词条、公众号文章、论文解读分享等不同难度共创任务,在学习中贡献,在付出中收获。
-
共享追踪主题前沿进展:在群内和公众号分享最新进展,领域论文速递。
参与共创任务,共建学术社区:
-
读书会笔记:在交互式播放器上记录术语和参考文献
-
集智百科词条:围绕读书会主题中重要且前沿的知识概念梳理成词条。例如:
-
论文解读分享:认领待读列表中的论文,以主题报告的形式在社区分享
-
论文摘要翻译:翻译社区推荐论文中的摘要和图注
-
公众号文章:以翻译整理形式或者原创写作生产公众号文章,以介绍前沿进展。例如:
读书会阅读材料
读书会阅读材料
阅读材料较长,为了更好的阅读体验,建议您前往集智斑图沉浸式阅读,并可收藏感兴趣的论文。

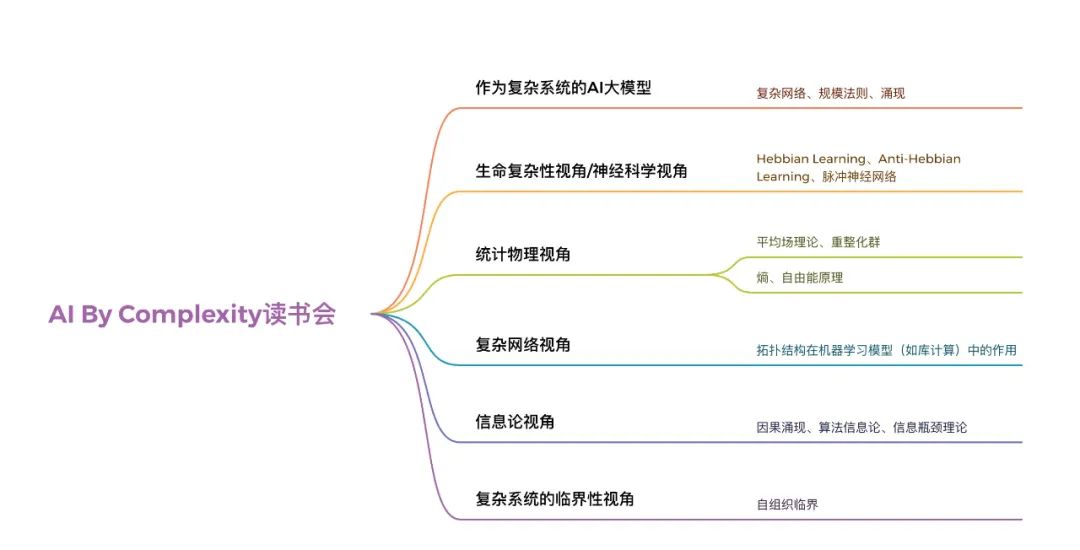
一、作为复杂系统的AI大模型
本视角下关注的核心问题:AI大模型首先是一个典型的复杂系统。如何用复杂系统的视角去研究现在的AI系统,有哪些方法可以借鉴,有哪些规律可以帮助深入理解AI大模型,可以从复杂网络、复杂动力系统的方法来对大模型进行研究,同时也能够去深入理解AI大模型的涌现现象和规模法则。
推荐阅读:https://pattern.swarma.org/article/224
本视角下讨论的核心理论:网络科学、规模法则、涌现
1. Jason Wei, Yi Tay, Rishi Bommasani, et al. Emergent Abilities of Large Language Models. arXiv:2206.07682, 2022
大语言模型中的涌现:大语言模型的涌现现象也是近年来研究的热点问题,但是与传统复杂系统中的涌现定义不同,大语言模型的涌现能力,指的是随着模型规模的增长,一些能力会突然变强,突变式地拥有了小语言模型所不具有的新能力。
2. Jared Kaplan, Sam McCandlish, Tom Henighan, et al. Scaling Laws for Neural Language Models. arXiv:2001.08361, 2020
大语言模型的规模法则:与许多复杂系统一样,大语言模型也遵循着规模法则(Scaling law),也就是它的各项宏观指标会形成两两的幂律关系。
3. Emanuele La Malfa, Gabriele La Malfa, Giuseppe Nicosia, et al. Characterizing Learning Dynamics of Deep Neural Networks via Complex Networks. arXiv:2110.02628, 2021
展示了神经网络训练过程中权重分布的异质化趋势,即赢者通吃的局面。
4. Matteo Zambra, Alberto Testolin, Amos Maritan. Emergence of Network Motifs in Deep Neural Networks. arXiv:1912.12244, 2019
研究了神经网络在训练过程中自发演化出的局部网络结构。
5. Emanuele La Malfa, Gabriele La Malfa, Claudio Caprioli, et al. Deep Neural Networks as Complex Networks. arXiv:2209.05488, 2022
探讨了不同网络结构对神经网络功能和学习能力的影响。
二、神经科学视角
本视角下关注的核心问题:bio-inspired machine learning是一个非常广阔的领域,通过一期读书会来囊括诸多代表性研究是不够的,因此,我们希望在这个部分只节选生物启发机器学习中具有复杂性味道的研究范例进行学习与讨论。例如:Hebbian Learning和Anti-Hebbian Learning。
本视角下讨论的核心理论:Hebbian Learning、Anti-Hebbian Learning、脉冲神经网络
推荐人:张章
推荐论文:2篇
-
Alemanno, Francesco, et al. “Supervised hebbian learning.” Europhysics Letters 141.1 (2023): 11001. https://iopscience.iop.org/article/10.1209/0295-5075/aca55f/meta
Hebbian Learning指人们从生物神经网络中发现了一条简单有趣的规则,即Fire together,wire together。这个简单的规则可以用于指导神经网络的结构设计和训练。
-
Choe, Yoonsuck. “Anti-hebbian learning.” Encyclopedia of Computational Neuroscience. New York, NY: Springer New York, 2022. 213-216. https://link.springer.com/referenceworkentry/10.1007/978-1-0716-1006-0_675
Anti hebbian learning则是另一条与之相反的规则,即尽可能减少神经元的协同激活,从而起到节省能量的作用,相比于Hebbian Leraning,Anti Hebbian Leraning是一个更晚发现的规则,但同样是简单规则指导神经网络结构和动力学的可实践的范例。
三、统计物理视角
本视角下关注的核心问题一:
所有研究关注的核心问题都是如何理解神经网络在初始化、优化(即训练)和部署阶段的行为所符合的物理规律。例如,在初始化时是否有可能使得神经网络避免梯度爆炸或梯度消失?在训练过程中,神经网络是否可以在特点优化器的作用下避开局部极小值,应该如何泛化?在部署阶段,是否可以依据特定统计物理规则对神经网络参数进行筛选和量化以降低计算量?
本视角下讨论的核心理论:平均场理论、重整化群
推荐人:田洋
推荐论文:11篇
神经网络的平均场理论的核心目的在于理解神经网络在无限宽的条件下的动力学行为,确定神经网络在初始化和训练阶段的最优条件(例如最优初始化方案等)。以下是关于人工神经网络的平均场理论的论文,前面为三篇核心文献,分别对应平均场理论、实验效果、经典平均场理论的局限和推广;后面两篇为补充文献。
-
Xiao, Lechao, et al. “Dynamical isometry and a mean field theory of cnns: How to train 10,000-layer vanilla convolutional neural networks.” International Conference on Machine Learning. PMLR, 2018. https://proceedings.mlr.press/v80/xiao18a
-
Schoenholz, Samuel S., et al. “Deep information propagation.” arXiv preprint arXiv:1611.01232 (2016). https://arxiv.org/abs/1611.01232
-
Weng, K., Cheng, A., Zhang, Z., Sun, P., & Tian, Y. (2023). Statistical physics of deep neural networks: Initialization toward optimal channels. Physical Review Research, 5(2), 023023. https://journals.aps.org/prresearch/abstract/10.1103/PhysRevResearch.5.023023
-
Pennington, J., Schoenholz, S., & Ganguli, S. (2018, March). The emergence of spectral universality in deep networks. In International Conference on Artificial Intelligence and Statistics (pp. 1924-1932). PMLR. https://proceedings.mlr.press/v84/pennington18a.html
-
Yang, G., & Schoenholz, S. (2017). Mean field residual networks: On the edge of chaos. Advances in neural information processing systems, 30. https://proceedings.neurips.cc/paper_files/paper/2017/hash/81c650caac28cdefce4de5ddc18befa0-Abstract.html
-
Bahri, Y., Kadmon, J., Pennington, J., Schoenholz, S. S., Sohl-Dickstein, J., & Ganguli, S. (2020). Statistical mechanics of deep learning. Annual Review of Condensed Matter Physics, 11, 501-528. https://www.annualreviews.org/content/journals/10.1146/annurev-conmatphys-031119-050745
重整化群这一个方向的核心研究目的在于从信息论或概率论的角度理解重整化群的设计原理,并结合新的数学工具设计更具有泛用性或计算性能更加高的重整化群,以在原始理论无法涵盖的场景中验证系统是否处于临界点或是否符合特定标度关系。下面5篇文章是重整化群和机器学习想法交融或用于解决数据科学问题的代表。
-
Kline, Adam G., and Stephanie E. Palmer. “Gaussian information bottleneck and the non-perturbative renormalization group.” New journal of physics 24.3 (2022): 033007. https://iopscience.iop.org/article/10.1088/1367-2630/ac395d/meta
-
Cheng, Aohua, Pei Sun, and Yang Tian. “Simplex path integral and renormalization group for high-order interactions.” arXiv preprint arXiv:2305.01895 (2023). https://arxiv.org/abs/2305.01895
-
Lenggenhager, Patrick M., et al. “Optimal renormalization group transformation from information theory.” Physical Review X 10.1 (2020): 011037. https://journals.aps.org/prx/abstract/10.1103/PhysRevX.10.011037
-
Xu, Yizhou, Yang Tian, and Pei Sun. “Fast renormalizing the structures and dynamics of ultra-large systems via random renormalization group.” (2024). https://www.researchsquare.com/article/rs-3888068/v1
-
Gordon, Amit, et al. “Relevance in the renormalization group and in information theory.” Physical Review Letters 126.24 (2021): 240601. https://journals.aps.org/prl/abstract/10.1103/PhysRevLett.126.240601
本视角下关注的核心问题二:利用统计物理对复杂系统进行度量这个研究方向上也有了很多新的进展,如使用自由能度量复杂网络的信息传播速度,使用熵度量复杂网络对抗扰动的能力,使用热机效率度量复杂网络的效率等。而因为我们有一个信仰,“一个好的AI系统首先是一个好的复杂系统”,因此这部分度量方式也可以去学习,并有助于指导AI系统的设计。
本视角下讨论的核心理论:熵、自由能原理
推荐人:张章、牟牧云
推荐论文:9篇
-
Ghavasieh, Arsham, Carlo Nicolini, and Manlio De Domenico. “Statistical physics of complex information dynamics.” Physical Review E 102.5 (2020): 052304. https://journals.aps.org/pre/abstract/10.1103/PhysRevE.102.052304
-
Ghavasieh, Arsham, and Manlio De Domenico. “Generalized network density matrices for analysis of multiscale functional diversity.” Physical Review E 107.4 (2023): 044304. https://journals.aps.org/pre/abstract/10.1103/PhysRevE.107.044304
-
Ghavasieh, Arsham, and Manlio De Domenico. “Enhancing transport properties in interconnected systems without altering their structure.” Physical Review Research 2.1 (2020): 013155. https://journals.aps.org/prresearch/abstract/10.1103/PhysRevResearch.2.013155
-
Ghavasieh, Arsham, and Manlio De Domenico. “Diversity of information pathways drives sparsity in real-world networks.” Nature Physics (2024): 1-8. https://www.nature.com/articles/s41567-023-02330-x
自由能的概念起源于统计物理,后被引入机器学习和信息加工领域,表示对世界表征状态与其真实状态间的差异。自由能原理认为,所有可变的量,只要作为系统的一部分,都会为最小化自由能而变化。本质上,自由能原理希望阐明在生物系统中实现自组织的可能性。在集智“自由能原理与强化学习”读书会中对以自由能原理为基础的主动推断框架进行了详细的介绍,更多偏向从贝叶斯定理出发的认知的视角。在本次AI by Complexity读书会中我们将更多从随机动力系统以及非平衡稳态等视角出发探究自由能原理与智能体感知和行动之间的联系,这对于构建决策AI智能体或许能够带来新的启发。以下5篇论文与自由能原理相关。
-
Karl, Friston. “A free energy principle for biological systems.” Entropy 14.11 (2012): 2100-2121. https://www.mdpi.com/1099-4300/14/11/2100
生命何以存在?这篇文章从随机动力系统的视角出发,基于变分自由能的最小作用量原理,试图解释生命体能够抵抗环境中无序的波动的内在逻辑,并建立了它与信息瓶颈方法在形式上等价的条件。
-
Friston, Karl, and Ping Ao. “Free energy, value, and attractors.” Computational and mathematical methods in medicine 2012 (2012). https://pubmed.ncbi.nlm.nih.gov/22229042/
自由能原理认为行动和感知可以被理解为最小化感觉样本的自由能,而强化学习源于行为主义和工程学,假定代理者优化策略以最大化未来的奖励。这篇文章试图将自由能原理以及强化学习针对行动和感知的两种表述联系起来。
-
Friston, Karl, et al. “The free energy principle made simpler but not too simple.” Physics Reports 1024 (2023): 1-29. https://www.sciencedirect.com/science/article/pii/S037015732300203X
这篇论文提供了自由能原理的简洁推导。自由能量原理是关于自组织和感知行为的规范性描述,它将自组织描述为最大化贝叶斯模型证据,将感知行为描述为最优贝叶斯设计和决策。这篇文章随机动力系统的朗之万方程描述开始,最终得出可以被看作是有感知的物理学的贝叶斯力学。
-
Mazzaglia, Pietro, et al. “The free energy principle for perception and action: A deep learning perspective.” Entropy 24.2 (2022): 301. https://www.mdpi.com/1099-4300/24/2/301
这篇文章建立了自由能原理与深度学习世界模型之间的联系,并对强化学习世界模型架构设计的不同方面进行了讨论。
-
Hafner, Danijar, et al. “Action and perception as divergence minimization.” arXiv preprint arXiv:2009.01791 (2020). https://arxiv.org/abs/2009.01791
基于自由能原理以及自由能原理的具体实现主动推断框架,启发了差异最小化(divergence minimization)的想法,从差异最小化的角度出发,很多深度学习强化学习算法可以看作是智能体在最小化内在模型分布与目标分布之间的差异。从这个角度出发可以将大量已有的的深度学习强化学习(更多针对强化学习)算法进行一个统一的分类,并且能够启发我们设计新的强化学习算法。
四、复杂网络视角
本视角下关注的核心问题:神经网络模型作在机器学习算法中处于核心地位,而现有的神经网络模型以全连接、CNN、RNN、Transformer等为代表,其本身并没有和网络科学直接关联。而我们知道一个全连接的复杂网络在现实中是很少见的。网络科学告诉我们,全连接的网络在成本,鲁棒性,信息传递效率等方面都不是最优的。而现在大多数稀疏神经网络的研究也只考虑了成本的降低,而并不从复杂网络的视角考虑一个稀疏的网络带来的其他性质。因此我们想在这一部分介绍结合网络科学和神经网络模型的论文,一些容易想到的论文是在库计算领域(reservoir computing)中,研究库中不同网络结构对效果的影响。
本视角下讨论的核心理论:库计算
推荐人:张章
推荐论文:4篇
-
Klickstein, Isaac, Louis Pecora, and Francesco Sorrentino. “Symmetry induced group consensus.” Chaos: An Interdisciplinary Journal of Nonlinear Science 29.7 (2019). https://pubs.aip.org/aip/cha/article/29/7/073101/1059583
-
Dale, Matthew, et al. “Reservoir computing quality: connectivity and topology.” Natural Computing 20 (2021): 205-216. https://link.springer.com/article/10.1007/s11047-020-09823-1
-
Kawai, Yuji, Jihoon Park, and Minoru Asada. “A small-world topology enhances the echo state property and signal propagation in reservoir computing.” Neural Networks 112 (2019): 15-23. https://www.sciencedirect.com/science/article/abs/pii/S0893608019300115
-
Zador, Anthony M. “A critique of pure learning and what artificial neural networks can learn from animal brains.” Nature communications 10.1 (2019): 3770. https://www.nature.com/articles/s41467-019-11786-6
五、信息论视角
本视角下关注的核心问题一:目前AI被拓展到各个领域,随着LLM的兴起和各种参数规模的增大(AI本身变为复杂系统)以及需要处理的任务越来越复杂(AI面对的对象是复杂系统),复杂系统所特有的涌现现象一定会是AI研究中不可避免会遇到的问题。那么问题来了:什么是AI自身的涌现?因果涌现理论如何解释甚至优化出更加具有涌现特征的AI?另外,AI能否“理解”涌现?以识别甚至控制涌现为优化目标,能否让AI表现更出色?
本视角下讨论的核心理论:因果涌现
推荐人:杨明哲
推荐论文:2篇
-
Zhang, J., & Liu, K. (2022). Neural Information Squeezer for Causal Emergence. Entropy, 25(1), 26. https://doi.org/10.3390/e25010026
-
Yang, M., Wang, Z., Liu, K., Rong, Y., Yuan, B., & Zhang, J. (2023). Finding emergence in data by maximizing effective information (arXiv:2308.09952). arXiv. http://arxiv.org/abs/2308.09952
本视角下关注的核心问题二:自去年以来,包括Ilya Sutskever、Marcus Hutter、Jack Rae等众多研究者均对压缩与智能之间的关系进行了探讨,有观点甚至将这一理论视为OpenAI的核心哲学。实际上,探究压缩和智能的联系已有悠久历史,最早可追溯至图灵关于可计算性的研究。此后,1960年代Solomonoff、Kolmogorov 和 Chaitin独立提出并发展算法信息论(紧随香农的信息论之后),该领域逐渐引入了诸如柯式复杂度这样的重要概念:即复杂度衡量的是在通用图灵机上生成某个对象的最短程序长度。90年代,研究者已经开始利用压缩方法有效地执行分类等任务,这一应用如今重新受到关注,仿佛它是一个全新的发现。随着大型模型的兴起,这一领域的联系和重要性重新受到关注,这可能使得这一学科从默默发展到再次成为焦点。在当前的人工智能研究中,虽然数据规模和模型规模受到了极大关注,但各种Magic神经网络架构背后,必然有更深层的原理在指导或推动其发展,这可能就像卡诺循环、内燃机、热力学第二定律以及热力学统计之间的微妙关系。
本视角下讨论的核心理论:算法信息论
推荐人:刘宇
推荐论文:5篇
-
Cilibrasi, Rudi, and Paul MB Vitányi. “Clustering by compression.” IEEE Transactions on Information theory 51.4 (2005): 1523-1545. https://ieeexplore.ieee.org/abstract/document/1412045
在算法信息论领域非常有影响力的工作:如何利用压缩机定义距离,进而用来分类、构造系统发生树等。
-
Delétang, Grégoire, et al. “Language modeling is compression.” arXiv preprint arXiv:2309.10668 (2023). https://arxiv.org/abs/2309.10668
DeepMind的最新工作,阐述大模型和压缩的关系,使得算法信息论再次引起人工智能领域的关注。
-
Johnston, Iain G., et al. “Symmetry and simplicity spontaneously emerge from the algorithmic nature of evolution.” Proceedings of the National Academy of Sciences 119.11 (2022): e2113883119. https://www.pnas.org/doi/abs/10.1073/pnas.2113883119
从算法信息论角度去描述分子等结构的复杂性,连接起来演化和压缩的关系。
-
Sharma, Abhishek, et al. “Assembly theory explains and quantifies selection and evolution.” Nature 622.7982 (2023): 321-328. https://www.nature.com/articles/s41586-023-06600-9:
近期Nature正刊发表的充满争议的Assembly Theory
-
Zecheng Zhang, Chunxiuzi Liu, Yingjun Zhu, et al. Evolutionary Tinkering Enriches the Hierarchical and Interlaced Structures in Amino Acid Sequences (近期将在Physical Review Research刊出)https://www.researchsquare.com/article/rs-3440555/v2
算法信息论领域所提出的新方法-梯径方法,并把它应用于蛋白质序列的分析,挖掘序列中亚结构的重复嵌套关系以及演化关系。
本视角下关注的核心问题三:信息瓶颈的核心目的在于探索如何使得神经网络能在无监督或弱监督的条件下进行对比学习,实现对数据的最优低维表征(当然,相关算法也适用于传统的监督学习)。
本视角下讨论的核心理论:算法瓶颈
推荐人:田洋
推荐论文:2篇
以下两篇为信息瓶颈(information bottleneck)在深度学习里最经典的论文。
-
Painsky, A., & Tishby, N. (2018). Gaussian lower bound for the information bottleneck limit. Journal of Machine Learning Research, 18(213), 1-29. https://www.jmlr.org/papers/v18/17-398.html
-
Hjelm, R. D., Fedorov, A., Lavoie-Marchildon, S., Grewal, K., Bachman, P., Trischler, A., & Bengio, Y. (2018). Learning deep representations by mutual information estimation and maximization. arXiv preprint arXiv:1808.06670. https://arxiv.org/abs/1808.06670
六、复杂系统的临界性视角
本视角下关注的核心问题:在生物系统中,用什么量化方法度量一个生物系统(如脑网络)系统是否处于临界态?临界态将为这个系统带来哪些好处?这些问题是否在人工神经网络中也成立?
本视角下讨论的核心理论:自组织临界
推荐人:张章
推荐论文:3篇
-
Bak, Per. How nature works: the science of self-organized criticality. Springer Science & Business Media, 2013.
关于自组织临界性的经典丛书,中文译本为《大自然如何运作》,由自组织临界性的提出人per bak撰写。
-
Tetzlaff, Christian, et al. “Self-organized criticality in developing neuronal networks.” PLoS computational biology 6.12 (2010): e1001013. https://journals.plos.org/ploscompbiol/article?id=10.1371/journal.pcbi.1001013
这是一篇纯生物文章,监测了一个developing的神经网络系统是如何逐渐从低活性状态,经过超临界,亚临界的状态,最终达到临界态的。作者还通过数学模型来解释了这一神经网络developing的过程。
-
Katsnelson, Mikhail I., Vitaly Vanchurin, and Tom Westerhout. “Self-organized criticality in neural networks.” arXiv preprint arXiv:2107.03402 (2021). https://arxiv.org/abs/2107.03402

点击“阅读原文”,报名读书会
微信扫一扫,分享到朋友圈











