Scaling Law的有趣新进展

导语
一、缩放定律(Scaling Law)
一、缩放定律(Scaling Law)
在AI领域,“缩放定律” 描述了损失如何随着模型和数据集大小变化。
即观察到AI模型的性能与参数量和token量成比例,而这些量由其使用的计算量决定。
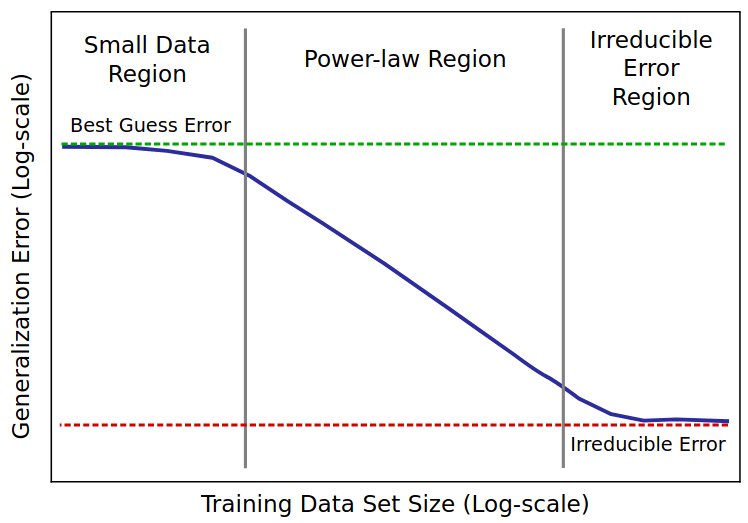
因而通常用4个变量来概述神经网络模型:模型大小、训练数据集大小、训练成本和训练后的性能。
这四个变量都可精确定义为实数,并且在统计学上被发现是相互关联的,即所谓的“缩放定律”。
也有人写成:Y = f(X, Z) 其中Y是模型观测性能,X是模型大小,Z是训练数据集大小,f是缩放函数。很直观,中学生都懂。
二、OpenAI 的定义
二、OpenAI 的定义
2020当年名不见经传的OpenAI 定义了神经语言模型的Scaling Law。

论文研究了语言模型在交叉熵损失下的性能经验性缩放定律。
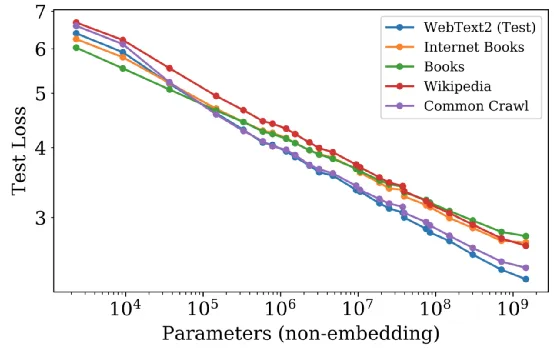
损失与模型大小、数据集大小和用于训练的计算量成指数关系,其中一些趋势跨越了七个数量级的范围。
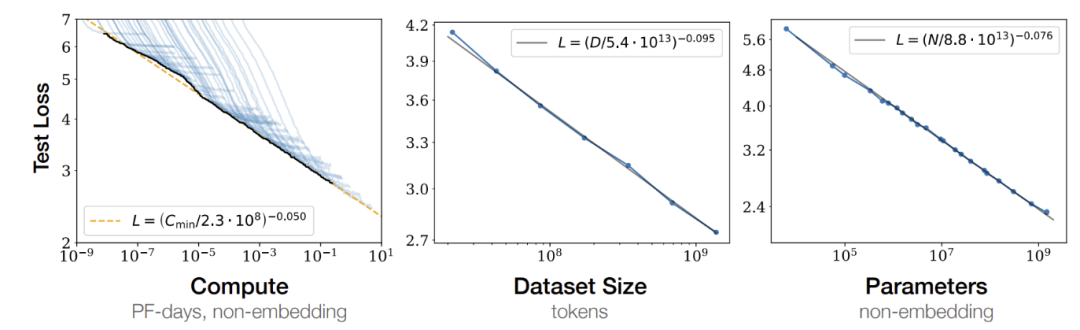
其他诸如网络宽度或深度等架构细节在较大的范围内影响甚微。
简单的方程控制了过拟合与模型/数据集大小之间的关系,以及训练速度与模型大小之间的关系。
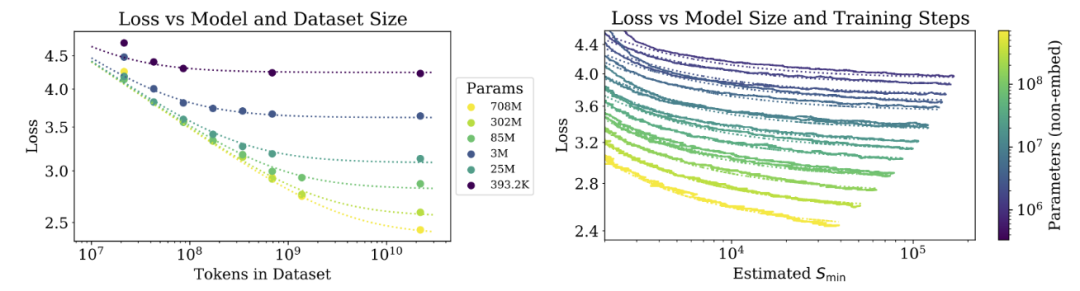
这些关系能够确定在给定计算预算的情况下如何进行最优分配。
较大的模型具有显著更高的样本效率,因此在给定的计算预算下实现最优的计算效率涉及在相对较少的数据上训练非常大的模型。
三、涌现衡量与争议
三、涌现衡量与争议
对缩放定律的信念与坚守,促进了后来ChatGPT的诞生,大语言模型能力涌现。
这些能力,LLMs并没有直接训练,数据集中也不含,但快速且不可预测的凭空出现。
甚至跨任务也有涌现,尽管这些任务相对不相关,但所有这些能力都在相似的规模下出现。
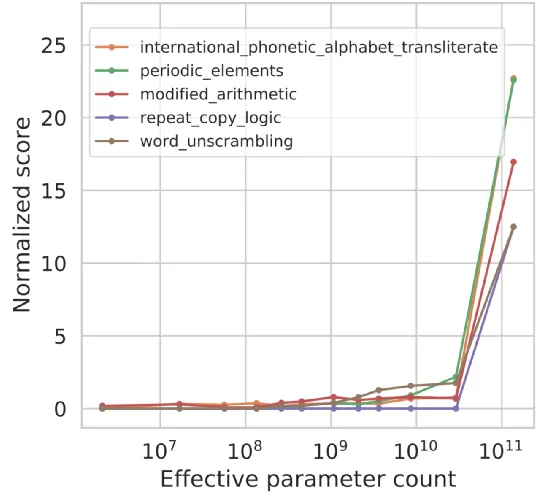
然而,评价指标选择的不一致,带来一些争议,其中最有名是来自斯坦福学者的质疑:“别太迷信大模型涌现能力,那是度量选择的结果”。
笔者的观点:论文作者选择的“Token Edit Distance”这个线性指标,并不适合用来衡量大模型的语义能力。我们只关心AI在人类关心的任务上的表现。
四、缩放定律数据库
四、缩放定律数据库
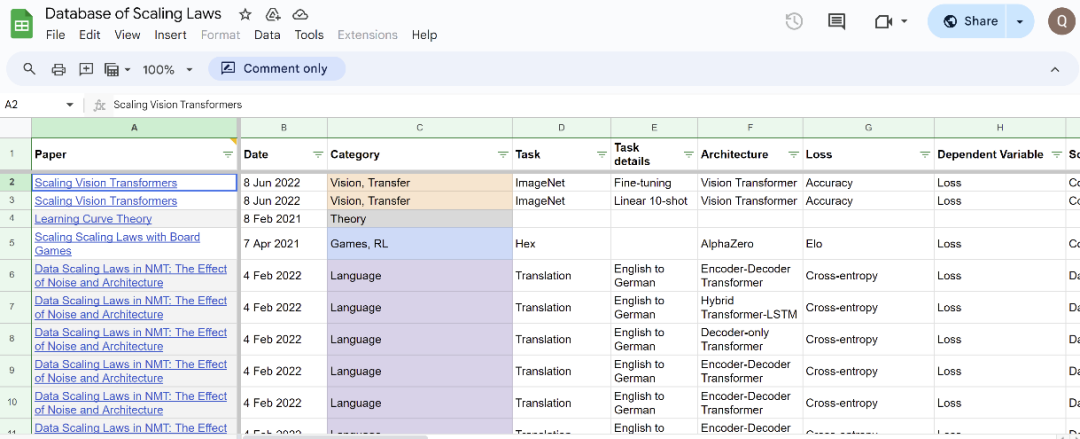
有热心网友搜集整理了不同任务和架构的缩放定律数据库,并对缩放定律文献中的数十篇论文进行了回顾,请参考:
五、广义缩放定律
五、广义缩放定律
研究大模型如何随着计算资源的增加而学习、适应和扩展其功能,对于预测未来能力以及优化训练和部署这些模型所需的资源至关重要。
然而彼时,这几件关于大语言模型的涌现能力还没有很好的研究:
3.我们不知道可能的能力景观
这一困境近期被打破,一篇最新来自斯坦福和多伦多大学的论文提出了观察缩放定律(https://arxiv.org/pdf/2405.10938),找到了复杂缩放现象的惊人可预测性。

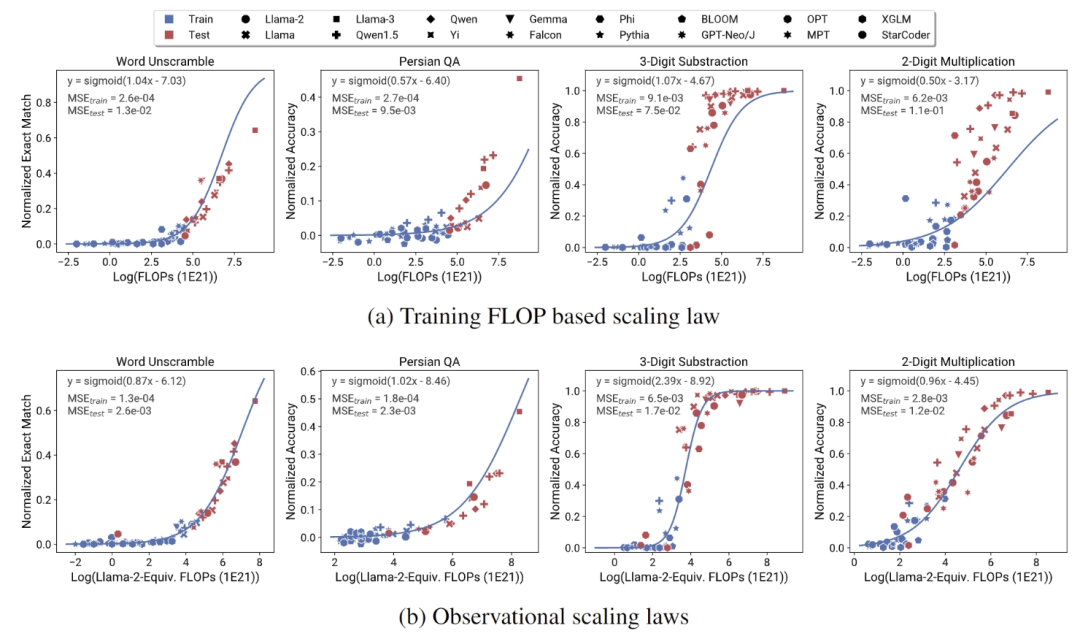
研究缩放定律,传统方法需要跨多个尺度进行大量训练,计算上非常昂贵且耗时。观察缩放定律则尝试使用公开可用的模型来构建缩放定律,避免了大量训练的需求。
该方法分析了大约 80 个公开可用的语言模型的性能数据,包括 Open LLM Leaderboard 和标准化基准,例如 MMLU、ARC-C 和 HellaSwag。
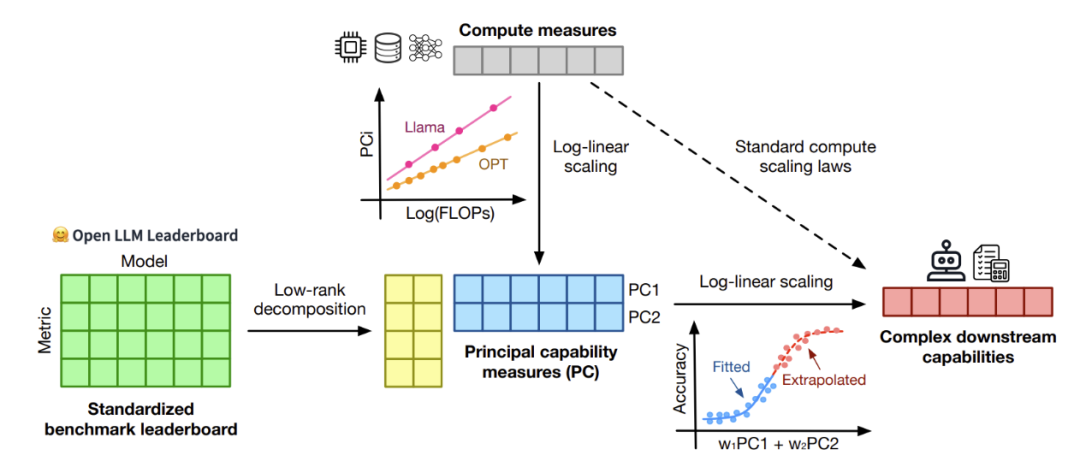
通过假设存在一个低秩的语言模型能力空间 ,即笔者上文提到的“人类关心的任务上的表现”;
使用主成分分析 (PCA) 来识别关键能力指标,并将这些指标与计算资源拟合成对数线性关系,也就是能力空间与计算量呈对数线性关系;
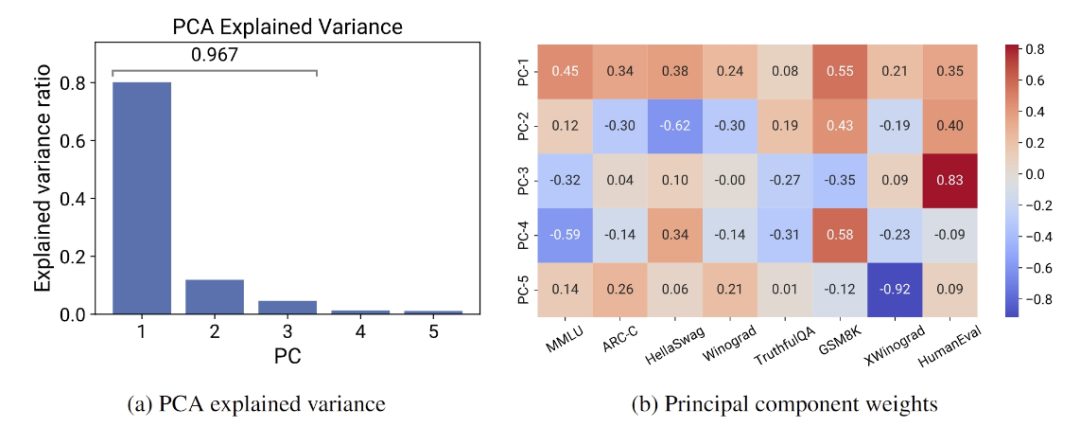
进一步可以直接从标准化的语言模型基准测试中预测出来复杂的下游能力,从而使用这近80个公开可用的语言模型获得低成本、高分辨率的缩放预测。
观察缩放定律泛化了现有的计算方式,是一种广义缩放定律。该方法可以准确预测 GPT-4 等先进模型的性能。
观察缩放定律,与各种基准的实际性能表现出高度相关性 (R² > 0.9)。语言理解和推理能力等涌现现象遵循可预测的 S 形(sigmoidal)模式。
结果还表明,观察缩放定律还可以可靠地预测训练后干预措施(如思维链和自我一致性)的影响,在特定任务中表现出高达 20% 的性能提升。
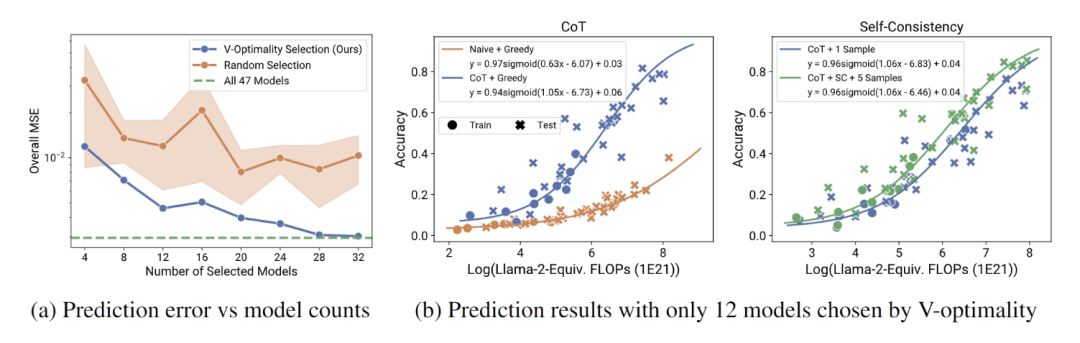
广义缩放定律节省了计算资源并增强了预测模型性能的能力,为研究人员和工程师优化语言模型开发提供了宝贵的工具。
AI By Complexity读书会招募中
大模型、多模态、多智能体层出不穷,各种各样的神经网络变体在AI大舞台各显身手。复杂系统领域对于涌现、层级、鲁棒性、非线性、演化等问题的探索也在持续推进。而优秀的AI系统、创新性的神经网络,往往在一定程度上具备优秀复杂系统的特征。因此,发展中的复杂系统理论方法如何指导未来AI的设计,正在成为备受关注的问题。
集智俱乐部联合加利福尼亚大学圣迭戈分校助理教授尤亦庄、北京师范大学副教授刘宇、北京师范大学系统科学学院在读博士张章、牟牧云和在读硕士杨明哲、清华大学在读博士田洋共同发起「AI By Complexity」读书会,探究如何度量复杂系统的“好坏”?如何理解复杂系统的机制?这些理解是否可以启发我们设计更好的AI模型?在本质上帮助我们设计更好的AI系统。读书会于6月10日开始,每周一晚上20:00-22:00举办。欢迎从事相关领域研究、对AI+Complexity感兴趣的朋友们报名读书会交流!
推荐阅读
点击“阅读原文”,报名读书会
微信扫一扫,分享到朋友圈











