时间、信息与人工智能:从信息动力学角度看大模型的未来
导语
1. 大语言模型简介
1. 大语言模型简介
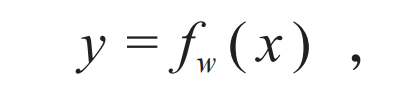

图1 克劳德·香农在关于信源编码定理(source coding theorem)的论文中研究的语言模型
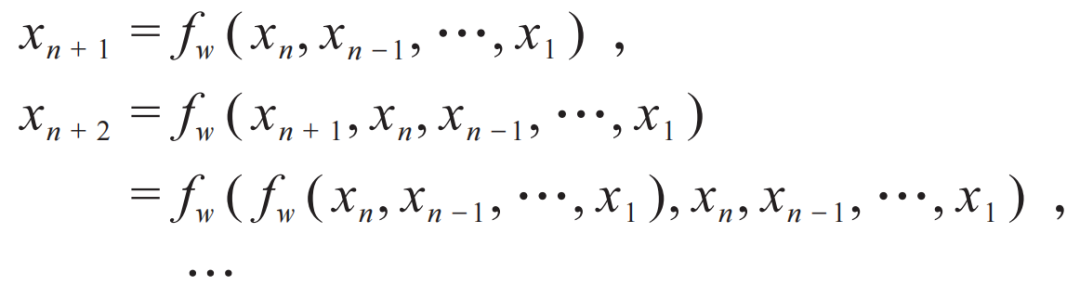
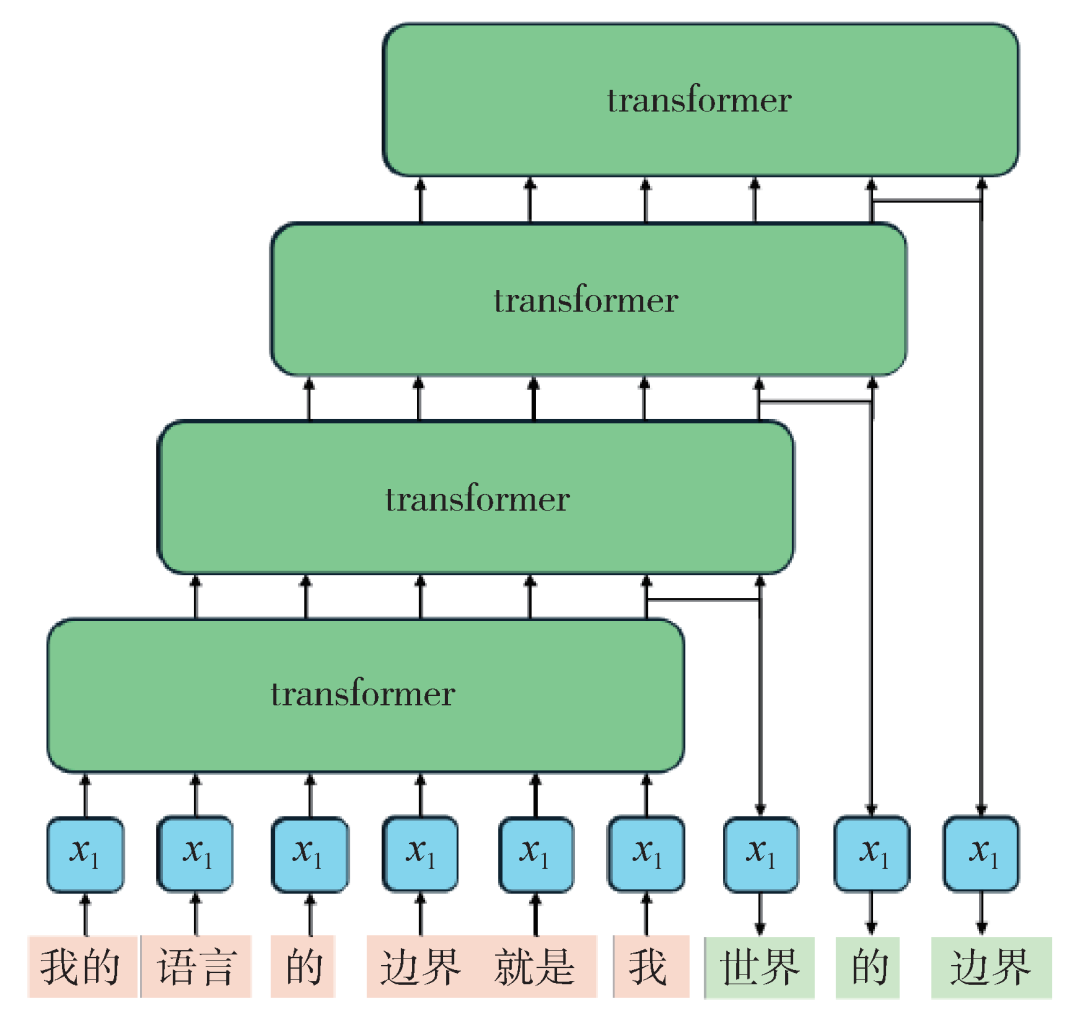
图2 大语言模型的示意图。输入内容(粉色)经过运算预测输出下一个词(绿色),如此迭代
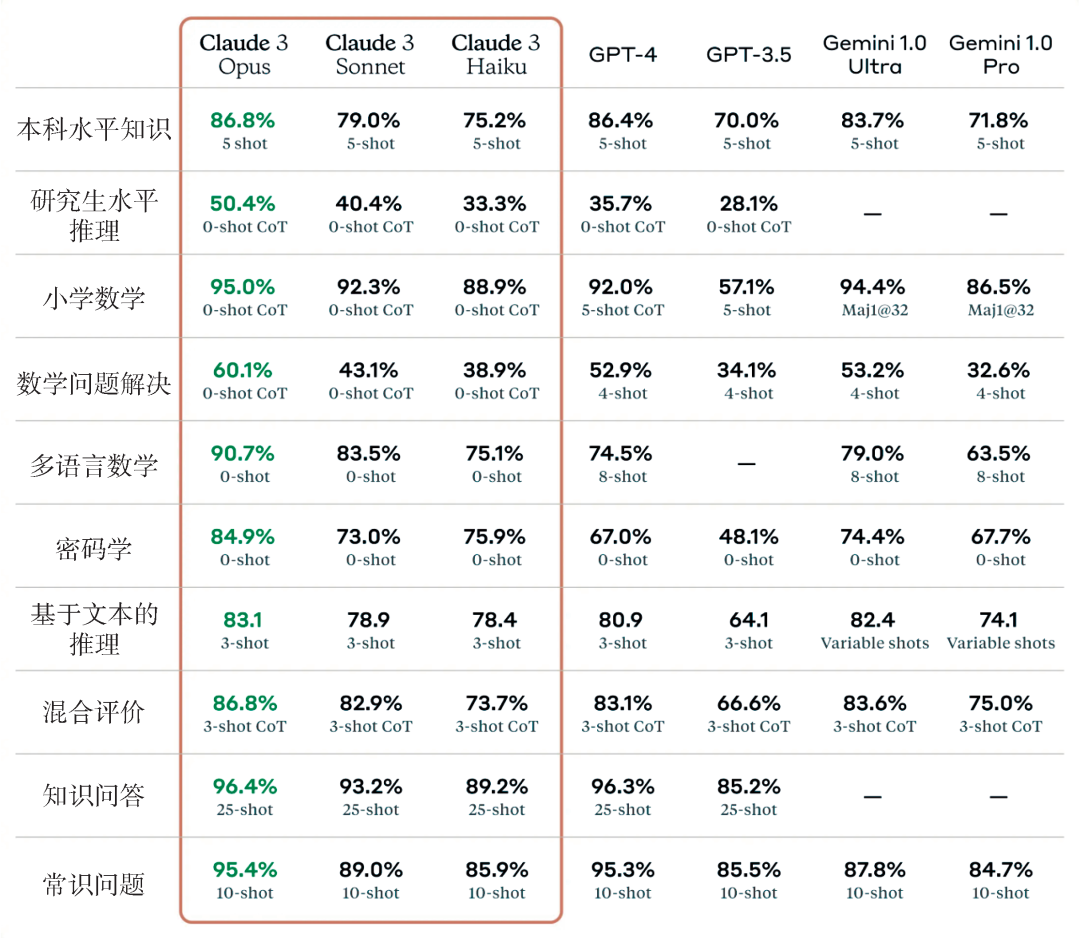
图3 美国人工智能公司Anthropic的模型Claude 3在2024年3月发布时的评测结果,其中红框中的三个模型Opus,Sonnet和Haiku是Claude 3的三个不同版本,能力依次减弱(图片引自:https://www.anthropic.com/news/claude-3-family)
2. 信息复杂度的临界点
2. 信息复杂度的临界点
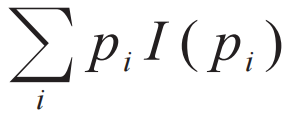 。而如果我们要求两条不相关的消息i和a的信息量等于它们之和,这就会要求I(piqa)=I(pi)I(qa),由此得知I(pi)是一个对数函数,这就是香农定义的信息熵
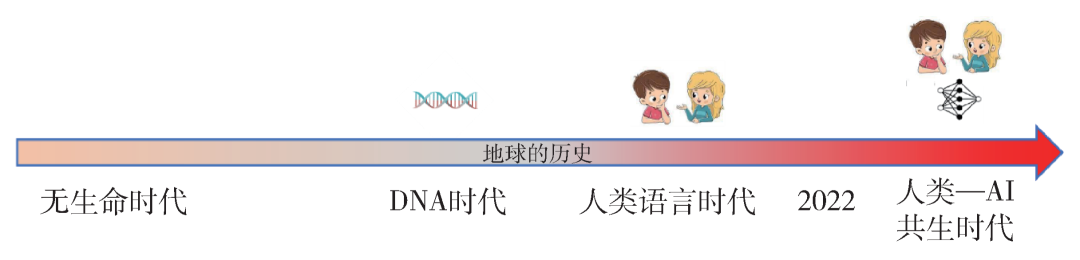
。而如果我们要求两条不相关的消息i和a的信息量等于它们之和,这就会要求I(piqa)=I(pi)I(qa),由此得知I(pi)是一个对数函数,这就是香农定义的信息熵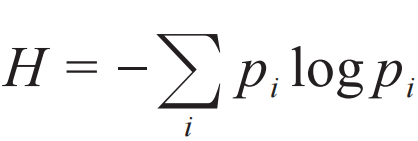 。一条消息中包含的信息量,只和这个概率有关,而与这条消息是通过电话、文字还是口头传递的无关。这正是反映了信息这个概念特别普适的一面。一切人类行为,乃至一切物理过程,都伴随着信息的传播和演化,或者用一个更准确的名词,可以称它们为信息动力学 (information dynamics) 过程。比如今天宇宙学观测到的微波背景辐射,带给了我们关于极早期宇宙的信息。微波背景辐射来自于某一个时刻,在这个时刻宇宙变得透明了。在比这个时刻更早的时候,宇宙是不透明的,光子会不停的被散射,所以我们今天无法直接接收到那时候的信息。从信息的角度来说,可以说在宇宙变透明的时刻,信息动力学发生了一个质变,光子携带的信息从转瞬即逝变成可以穿越百亿年。同样的质变发生在人类语言出现的“时刻” (当然这个并不是某个特定的时刻,而可能是一个漫长的进化过程) 。在语言出现之前的人类,以及其他动物,虽然也能互相传递信息,但信息的内容太有限,用途也仅限于当下,从长期来看,信息在代际之间的传递只能靠基因的遗传和变异。因此一种生物对新环境的适应,只能通过自然选择,在很长的时间尺度上才能做到。人类语言的出现,或者更准确地说,是语言达到一种通用的程度,能够描述生活中的各种复杂场景和思想,根本地改变了这一点。即使在没有文字的时代,人类也已经可以通过口口相传,积累很多宝贵的经验,发展出农业这样的复杂技能。一个人发明了轮子,所有其他人就不需要再发明轮子,只需要把制作轮子的技术不断传下去。今天的人类与一万年前相比,基因和智商的差异大约可以忽略,但能够建立起如此复杂的社会结构,创造出璀璨的科学、技术、文化,从信息动力学的角度就是归功于一种新的信息载体——语言,和新的信息动力学过程——人的思考和交流。总结一下,从生命出现到语言出现这段时间,可以称为“DNA时代”,在这个时代中长期起作用的信息的主要载体是DNA,起决定性作用的信息动力学过程是遗传变异和自然选择。语言出现 (大约十几万年前) 以来的时代可以称为“人类语言时代”,在这个时代起决定性作用的信息载体是人类语言,起决定性作用的信息动力学过程是语言的处理 (通过人脑的思考和交流)、记录和传播。
。一条消息中包含的信息量,只和这个概率有关,而与这条消息是通过电话、文字还是口头传递的无关。这正是反映了信息这个概念特别普适的一面。一切人类行为,乃至一切物理过程,都伴随着信息的传播和演化,或者用一个更准确的名词,可以称它们为信息动力学 (information dynamics) 过程。比如今天宇宙学观测到的微波背景辐射,带给了我们关于极早期宇宙的信息。微波背景辐射来自于某一个时刻,在这个时刻宇宙变得透明了。在比这个时刻更早的时候,宇宙是不透明的,光子会不停的被散射,所以我们今天无法直接接收到那时候的信息。从信息的角度来说,可以说在宇宙变透明的时刻,信息动力学发生了一个质变,光子携带的信息从转瞬即逝变成可以穿越百亿年。同样的质变发生在人类语言出现的“时刻” (当然这个并不是某个特定的时刻,而可能是一个漫长的进化过程) 。在语言出现之前的人类,以及其他动物,虽然也能互相传递信息,但信息的内容太有限,用途也仅限于当下,从长期来看,信息在代际之间的传递只能靠基因的遗传和变异。因此一种生物对新环境的适应,只能通过自然选择,在很长的时间尺度上才能做到。人类语言的出现,或者更准确地说,是语言达到一种通用的程度,能够描述生活中的各种复杂场景和思想,根本地改变了这一点。即使在没有文字的时代,人类也已经可以通过口口相传,积累很多宝贵的经验,发展出农业这样的复杂技能。一个人发明了轮子,所有其他人就不需要再发明轮子,只需要把制作轮子的技术不断传下去。今天的人类与一万年前相比,基因和智商的差异大约可以忽略,但能够建立起如此复杂的社会结构,创造出璀璨的科学、技术、文化,从信息动力学的角度就是归功于一种新的信息载体——语言,和新的信息动力学过程——人的思考和交流。总结一下,从生命出现到语言出现这段时间,可以称为“DNA时代”,在这个时代中长期起作用的信息的主要载体是DNA,起决定性作用的信息动力学过程是遗传变异和自然选择。语言出现 (大约十几万年前) 以来的时代可以称为“人类语言时代”,在这个时代起决定性作用的信息载体是人类语言,起决定性作用的信息动力学过程是语言的处理 (通过人脑的思考和交流)、记录和传播。
图4 大语言模型(LLM)和之前的机器(例如AlphaGo,Google)在信息的输入、处理和输出的复杂度对比。虚线代表人类水平
3. AI的快与慢
3. AI的快与慢
3.1 人类的认知系统
那么系统2是和系统1完全独立的另一套认知系统吗?并不是。举个例子,如果我们要计算9乘9,就会根据记忆直接给出结果81,不需要思考,因此这是一个系统1的工作。如果我们要计算999乘999,就不能只凭记忆,就要开始调用系统2开始思考。我们可能会分成如下的步骤去做:
(1)利用999=1000-1,把问题转化为计算(1000−1)×(1000−1);
(2)用乘法分配律展开这个式子;
(3)计算1000×1000,1000×1,1×1;
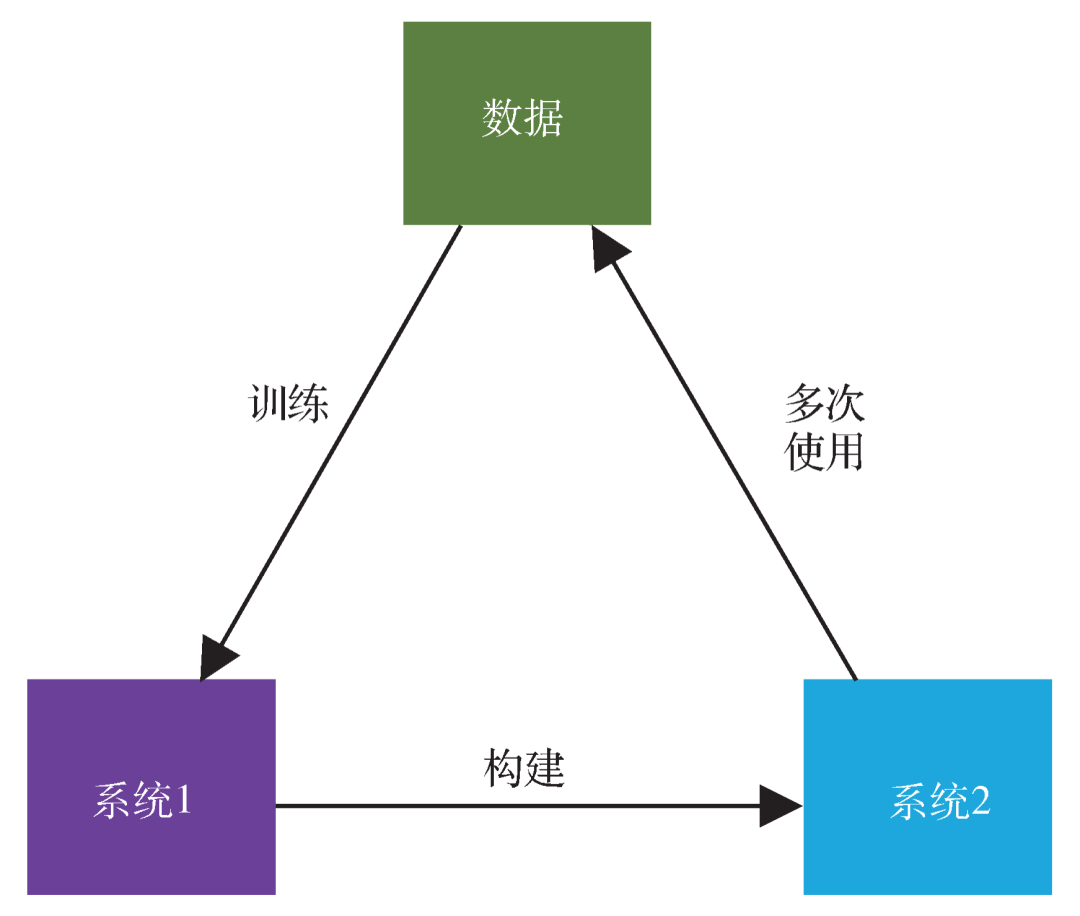
图6 人类的系统1和系统2的关系。系统2是系统1的网络,系统2的使用带来的数据(经验)会反过来训练系统1
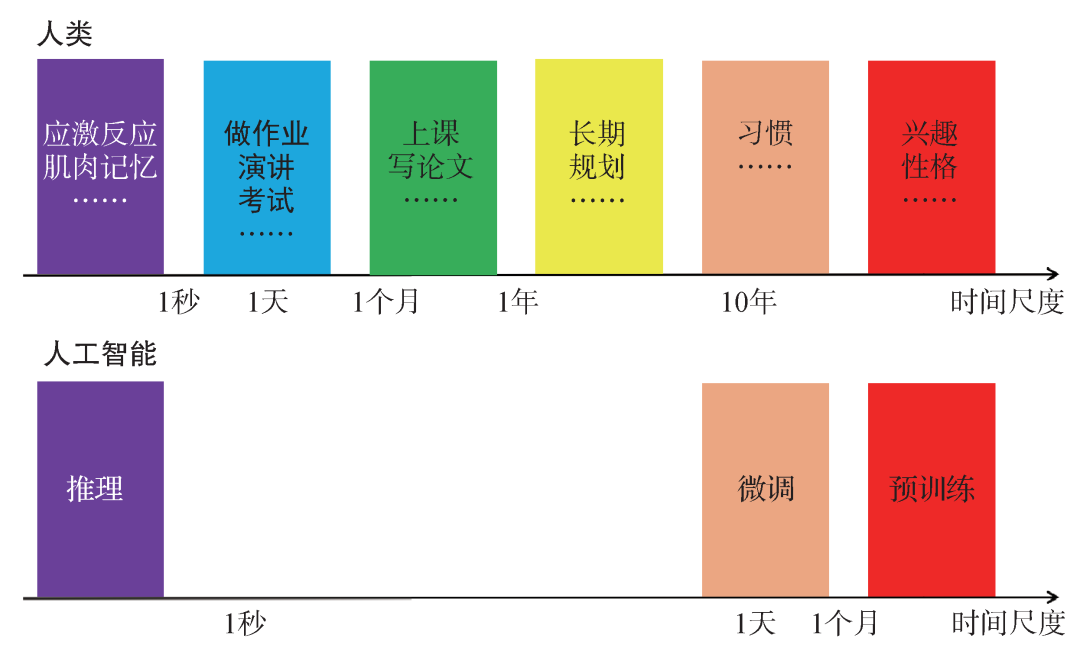
图7 人类和人工智能的时间尺度比较。人类的系统2涵盖了从1秒到几十年的时间尺度范围,可以针对不同的任务调整认知的时间尺度。相比之下,AI的快行为(推理)和慢行为(微调和预训练)之间存在空档,而且微调和预训练要通过人类干预才能完成
4. 通向系统2:AI智能体
4. 通向系统2:AI智能体
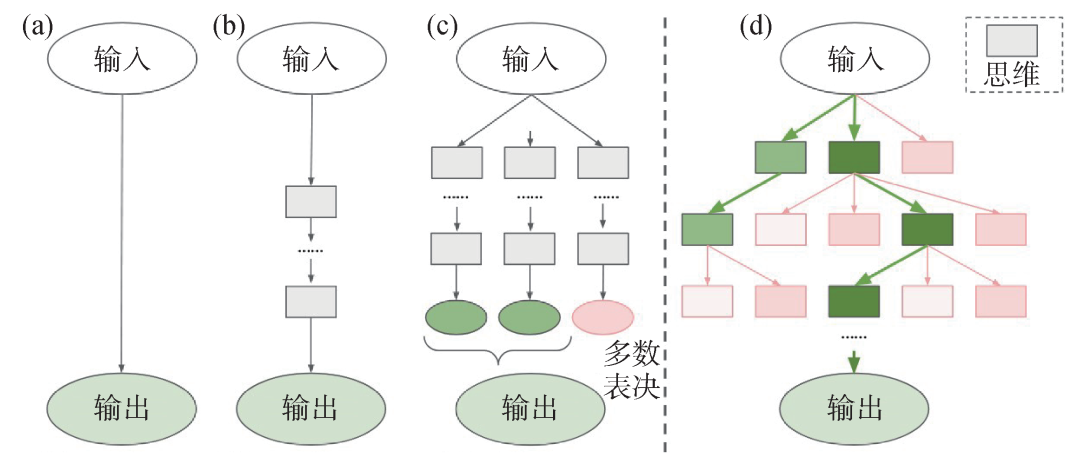
图8 几种不同的对大模型的调用方式 (a)给定问题直接输出答案;(b)思维链提示词;(c)多条思维链再做多数表决;(d)思维树[7]

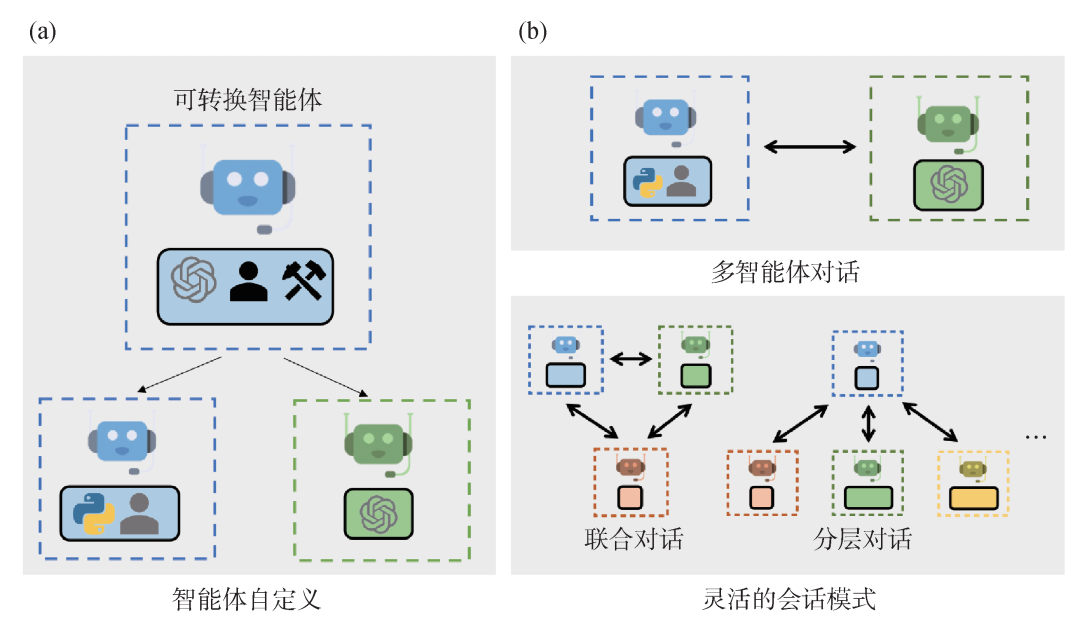
图10 AutoGen示意图[11] (a) AutoGen的智能体可以包括大模型或者其他工具,也可以包括人的输入;(b) AutoGen的智能体之间可以通过对话解决问题
5. 总结与展望
5. 总结与展望
在接下来的5-10年,人工智能的发展将会给人类社会的各方面带来深远的影响,甚至是翻天覆地的变化。在各方面的影响中,对于科学研究等创新工作的影响可能是最深刻的变化之一。如何应用人工智能来帮助科学研究,是非常值得深入思考和探索的问题。
作者简介
报名链接:https://pattern.swarma.org/study_group_issue/480
参考文献
参考文献可上下滑动查看
AI By Complexity读书会招募中
大模型、多模态、多智能体层出不穷,各种各样的神经网络变体在AI大舞台各显身手。复杂系统领域对于涌现、层级、鲁棒性、非线性、演化等问题的探索也在持续推进。而优秀的AI系统、创新性的神经网络,往往在一定程度上具备优秀复杂系统的特征。因此,发展中的复杂系统理论方法如何指导未来AI的设计,正在成为备受关注的问题。
集智俱乐部联合加利福尼亚大学圣迭戈分校助理教授尤亦庄、北京师范大学副教授刘宇、北京师范大学系统科学学院在读博士张章、牟牧云和在读硕士杨明哲、清华大学在读博士田洋共同发起「AI By Complexity」读书会,探究如何度量复杂系统的“好坏”?如何理解复杂系统的机制?这些理解是否可以启发我们设计更好的AI模型?在本质上帮助我们设计更好的AI系统。读书会于6月10日开始,每周一晚上20:00-22:00举办。欢迎从事相关领域研究、对AI+Complexity感兴趣的朋友们报名读书会交流!
AI+Science 读书会

“后ChatGPT”读书会

点击“阅读原文”,报名读书会
微信扫一扫,分享到朋友圈











