2024年诺贝尔物理学奖授予机器学习人工神经网络相关的研究,很多人对此深感意外。如果我们把“物理学”定义为对自然世界的研究,人工神经网络作为完全由人类创造的抽象系统,属于物理学的范畴吗?著名科普杂志 Physics Today 近期发表文章梳理了诺奖得主 John Hopfield 和 Geoffrey Hinton 的主要贡献,认为从神经网络的底层原理,到大模型的涌现能力,物理学对于理解人工智能的底层机制具有重要意义,将物理学思维应用到现实世界系统中,有望为人工智能的突破提供洞察。
关键词:机器学习,统计物理,神经网络,深度学习,自旋玻璃,能量景观
Johanna L. Miller | 作者
杨然、张天汉 | 译者
张天汉 | 审校
梁金 | 编辑
文章题目:Nobel Prize highlights neural networks’ physics roots
文章地址:https://pubs.aip.org/physicstoday/article/77/12/12/3320663/Nobel-Prize-highlights-neural-networks-physics
统计力学和集体现象的理念为如今机器学习的巨大成功奠定了基础。
计算机科学中有句老话:“垃圾进,垃圾出”,是说计算机输出的质量取决于输入数据的质量(垃圾的输入会导致垃圾的输出)。这也暗示着,由于计算机缺乏自主思考的能力,它们无法超越自己接收到的明确指令,完成更复杂的任务。
然而,这种观点似乎已经不再成立。近年来,神经网络作为一种受人脑启发的计算架构,通过“人工神经元”(artificial neurons)传递信号,取得了令人瞩目的突破。单个人工神经元只能执行最基本的计算任务。但当这些神经元数量足够多,并且拥有充足的训练数据时,它们仿佛可以凭空获得堪比人类的智力。
物理学家对简单基本单元产生复杂现象并不陌生。几个基本粒子及其相互作用规则就构成了几乎整个可见世界:从微观到宏观、从超导体到等离子体,无所不包。为什么不能用物理学方法来研究神经网络中涌现的复杂性呢?
事实上,物理学的方法早已用在了神经网络领域,而且一直影响至今。这一点在今年的诺贝尔物理学奖得主身上得到了体现:获奖者是普林斯顿大学的约翰·霍普菲尔德(John Hopfield)和多伦多大学的杰弗里·辛顿(Geoffrey Hinton)。从20世纪80年代初开始,霍普菲尔德为基于物理学的脑启发信息处理奠定了概念基础;而辛顿则长期身处前沿,在物理思想的基础上发展出了今天神经网络模型所使用的算法。
最初,人们并没有意识到神经网络会如此强大。甚至在2011年,人工智能领域最引人注目的里程碑还是由另一种方法实现的:在《危险边缘》节目中战胜了 Ken Jennings 和 Brad Rutter 的 IBM Watson 计算机并没有用到神经网络,而是通过精确编程的语言处理、信息检索和逻辑推理规则。当时,许多研究人员认为,这才是创建实用人工智能的正确选择。
与此相比,早期神经网络的研究更多是好奇心驱使的研究,关注真实的大脑的思考机制,而非计算机和编程应用。但早期的神经科学和物理学的跨界交叉在本质上是非常微妙的,正如普林斯顿大学的 William Bialek 所说:“霍普菲尔德解决的问题和神经科学家们关注的问题是相通的,但这并不是简单地‘把物理学应用到某个领域’,而是引入了一个前所未有的视角。”
在20世纪80年代,神经科学家已经知道大脑是由神经元组成的,这些神经元之间通过突触相连,并在高电活动和低电活动(也就是通俗理解的“放电”和“不放电”)状态之间交替变化。神经科学家们试图通过研究只包含少量神经元的简单系统,来了解一个神经元的放电如何影响与之连接的其他神经元,从而理解大脑的工作机制。如斯坦福大学的 Jay McClelland 所说:“一些人从电子学的角度把神经元视作逻辑门。”
在霍普菲尔德1982年里程碑式的论文中,他采用了不同的观点。[1] 他指出,在物理学中,许多大规模系统的特性并不依赖于微观细节。例如,所有材料都能传导声波,不论它们的原子或分子之间具体如何相互作用。虽然,具体的微观作用机制可能会影响声速或其他声学性质,但研究三四个原子之间的相互作用几乎无法揭示声波的概念如何形成。
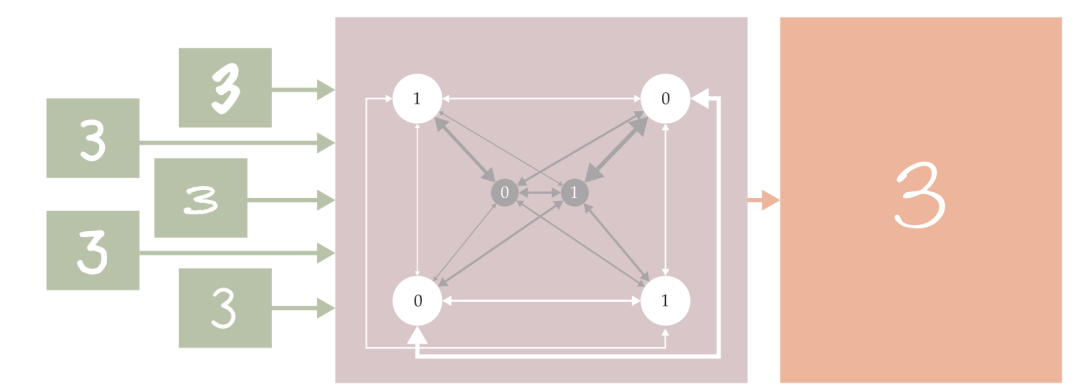
因此,霍普菲尔德提出了一个神经元网络模型,致力于通过简洁的数学假设和计算去揭示大脑工作机制,而非完全照搬神经生物学基本事实。这个模型后来被称为霍普菲尔德网络,如图1所示。(为了便于展示,图中展示的是一个包含五个神经元的简单网络,霍普菲尔德当时模拟的是更大的包含30~100个神经元的网络。)每个神经元可以处于状态1(放电)或状态0(未放电)。神经元之间的连接强度由耦合常数(coupling constant)表示,这些耦合常数可以是任意正值或负值,具体取决于每个突触是否倾向于两个神经元同时放电。
图1. 霍普菲尔德网络在形式上等价于自旋玻璃(spin glass),具备联想记忆功能:当给定一个部分记忆的状态时,它通过能量降低算法来填补缺失。记忆存储在节点之间的连接强度中。当霍普菲尔德证明通过合适的连接权重组合,网络可以同时存储许多记忆时,他为基于物理学的神经网络思想奠定了理论基础。|图由 Freddie Pagani 绘制;兔子照片由 JM Ligero Loarte/Wikimedia Commons/CC BY 3.0提供
这个神经元网络的构造形式与凝聚态物理中的自旋玻璃系统完全相同。不同于简单的铁磁体系统,在铁磁体系统中,所有耦合系数都是正值,并且系统有一个明确的最低能量基态,也就是所有自旋都对齐。相比之下,自旋玻璃就复杂得多,几乎不存在一个最低能量状态让所有自旋都同时满足各自偏好。系统的能量景观(energy landscape)非常复杂,包含很多局部能量最小值。
霍普菲尔德提出,这种自旋玻璃似的能量景观其实代表了一种记忆机制,其中,每一个能量最低构型都代表了一个需要记住的状态。在大脑突触工作模式的启发下,他还提出了一种优雅的方法来设置神经元之间的连接强度,从而让神经网络能够存储任意的状态集合。
需要指出的是,霍普菲尔德网络的记忆功能与传统计算机存储器有着根本区别。在传统计算机中,每一条需要存储的数据被编码为特定硬盘位置的一串“1”和“0”。当需要读取数据时,计算机只需找到对应位置,读取这个二进制字符串。但是,在霍普菲尔德网络中,所有的记忆数据同时存储在整个网络的连接强度中。这个网络还可以通过联想来“回忆”(即读取存储的数据)。只需要给网络神经元赋予合适的初值,使它们和待回忆的状态有几处相同的特征,网络就会自发弛豫到最近的能量最小值状态,从而回忆起相关的记忆。通常情况下,网络会成功找到期望的记忆。
这种记忆模式也正是大脑中真实发生的现象。霍普菲尔德说:“高等动物的实验指出,大脑活动是分散的,涉及到许多神经元的协同作用(而非计算机般的、固定位置的寻址和读取)。”而这种神经网络自发涌现出来的联想记忆模式则是每个人都曾直接体验过的,比如,当你听到一段随机的歌词时,可能会不由自主地想起整首歌,这就是联想记忆(associative memory)。
霍普菲尔德的模型大大简化了真实的大脑。真实的神经元本质是动态的,而非如模型所刻画的静止不变;真实神经元之间的连接也不是对称的(而模型中假设是对称的)。但是,从某种程度上看,模型与真实大脑之间的差异并非模型的缺陷,而是模型的亮点。它们表明,集体的联想记忆是一种大尺度涌现现象,并不依赖于特定的小尺度细节。
来自慕尼黑工业大学(Technical University of Munich)的 Leo van Hemmen 说:“不仅 Hopfield 是一位非常出色的物理学家,而且霍普菲尔德模型本身就是极好的物理学。”尽管如此,1982年的网络模型仍留下了许多有趣的开放性问题。霍普菲尔德主要是通过数值模拟来展示系统如何弛豫到能量最小值。那么,是否可以用更严格的数学方法来分析呢?它能记住多少个不同的状态?如果存储的状态过多会发生什么?有没有比霍普菲尔德更好的方式来设置连接强度?
这一系列的问题吸引了一大批受霍普菲尔德研究启发的物理学家,他们在20世纪80年代开始进入神经网络领域。以色列魏茨曼科学研究所(Weizmann Institute of Science in Israel)的 Eytan Domany 说道:“物理学家们富有才华、好奇心强,而且有一种积极意义上的自负。他们愿意钻研然后解决从未接触过的问题,只要这个问题足够有趣。而且每个人都对理解大脑感到兴奋。”
霍普菲尔德研究的另一个美妙之处在于,他“颠倒”了一个传统的物理问题。恰如耶路撒冷希伯来大学(Hebrew University of Jerusalem)Haim Sompolinsky所说:“在大多数能量景观问题中,一般是先知道微观相互作用,然后求解:什么是基态?局部最小值是什么?整个景观是什么样的?”然而,霍普菲尔德 1982年的论文反其道而行之。他从我们想要的基态开始,也就是从需要记忆的状态开始,然后去问:什么样的微观相互作用会让这样的状态成为基态?
这种思路的转变会自然地引发下一个问题:如果连接强度能够随着各自的能量景观去自发演化,会发生什么?换句话说,系统能否不依赖于预先设定的、特定记忆的参数,而是通过学习来改进自己?
神经网络的机器学习早已尝试过这个思路。比如20世纪50年代的感知机,它是一种类似神经网络的装置,可以将图像分入简单的类别,比如圆形和方形。当给感知机提供一系列训练图像,并用一个简单的算法来更新神经元之间的连接时,它最终可以正确分类甚至没见过的图像。
但由于网络结构的原因,感知机并不总是有效,有的时候无论怎么设置连接强度都没有办法完成给定的分类任务。van Hemmen 说,“一旦碰到这种情况,你可能调一辈子参数但算法就是不收敛,这对感知机是一个很大的打击”。由于没有明确的底层机理去指导研究方向,这个领域一度停滞不前。
辛顿并没有物理学背景,但他的合作者 Terrence Sejnowski 1978年正是在霍普菲尔德的指导下获得物理学博士学位。他们一起将霍普菲尔德网络模型扩展成了一种被称为玻尔兹曼机(Boltzmann machine)的新模型,通过借鉴统计物理学概念,大大增强了模型能力。[2]
在霍普菲尔德1982年的模拟中,他其实思考的是一个零温度时的自旋玻璃网络:他只允许系统以总能量单调下降的方式去演化状态。因此,无论系统最初的状态是什么,它都会逐渐达到附近的局部能量最低点并停在那里。
辛顿说:“Terry 和我立即开始思考随机下降的版本,即非零温度的情况。”他们没有使用确定性的能量降低规则,而是采用了蒙特卡罗算法,允许系统偶尔跳到能量更高的状态。给定足够长的时间,网络的随机模拟会遍历整个能量景观,并最终达到玻尔兹曼概率分布,这样一来,能量低的状态无论是不是局部能量最低点,他们都会以较高的概率出现。
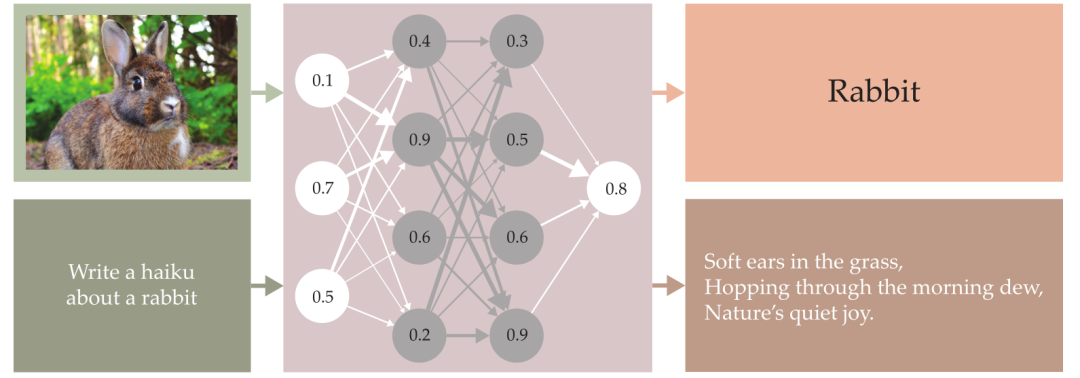
辛顿还说:“1983年,我们发现了一种非常优美的学习方法。”他们通过给神经网络提供训练数据去迭代更新网络连接强度,从而使数据状态在玻尔兹曼分布中出现的概率变得更高。[3]不仅如此,当输入数据具有共性特征时,比如图2中的数字3图像,其他高概率的状态也会共享同样的共性特征。
实现这种同步的关键在于:在原先仅含有编码节点的网络中加入了隐藏节点(在图2中用灰色表示),从而帮助系统发现数据之间更深层次的关联。
理论上,玻尔兹曼机可用于机器手写识别或异常诊断(比如识别发电厂的紧急状况)。但不幸的是,玻尔兹曼机的学习算法对于大多数实际应用来说都太慢了。所以在随后的数十年中,尽管它仍然是一个重要的学术研究课题,但一直没有找到太多实际应用。直到很多年后,它才又一次出人意料地登场。
图2. 玻尔兹曼机。在霍普菲尔德网络的基础上进行了两方面的扩展:首先,它增加了隐藏节点(图中用灰色表示),这些节点不直接参与数据的编码;其次,它在非零有效温度下运行,使得整个构型空间可以通过玻尔兹曼概率分布来描述。辛顿和他的同事们开发了一种方法,可以将玻尔兹曼机训练成生成模型:当输入的数据有某些共同特征时,模型能够生成更多类似的项。|图由 Freddie Pagani 绘制
大约与玻尔兹曼机同一时期, 辛顿与认知科学家 David Rumelhart 一起研究另一种名为反向传播(backpropagation)的学习算法[4],这后来成为了几乎所有神经网络的秘密武器。这个算法当时是为一种不同的网络架构开发的,称为“前馈网络”(feedforward network)。如图3所示,与节点间双向连接的霍普菲尔德网络和玻尔兹曼机不同,在前馈网络中,信号只沿一个方向流动:从输入层的神经元开始,经过若干隐藏层,最终到达输出层。多层感知器(multilayer perceptron)使用过类似的结构。
假设你想训练一个前馈网络来做图像分类。你给它一张兔子的图片,期望它输出“这是一只兔子”。但是不知道什么地方出了问题,输出结果变成了“这是一只乌龟”。那么,怎么才能让结果重回正轨?要知道,这个网络可能有几十个、几百个,今天的网络可能有上万亿个节点连接,每个连接都有自己的数值权重。有无数的方法可以去改变这些参数,但是哪一种才能得到想要的结果呢?
反向传播算法通过梯度下降解决了这个问题。首先,你定义一个误差函数来量化网络输出和期望输出之间的差距。然后,通过反复使用微积分中的链式求导法则,来计算这个误差函数对每个连接权重的偏导数(也就是梯度)。最后,利用这些导数,以降低误差函数为方向来调整网络中的权重。
网络学习的过程可能需要多次重复才能把误差降低到零附近,特别是你还得确保网络对于多种输入都能给出正确的输出,而不仅仅是对某一个特定的输入。但这些简单的步骤已经成为训练各类神经网络的标配,包括概念验证的图像分类器,和大语言模型比如 ChatGPT。
梯度下降方法在直观上非常美妙,但它并不是一个新的概念。正如 McClelland 所说,“要让反向传播(中的梯度下降)发挥作用,还需要几个条件。首先,如果某个东西不可微分,那么就没法计算它的导数。” 真实的神经元或多或少是以离散的“开”和“关”状态工作,最初的霍普菲尔德网络、玻尔兹曼机和感知机也都是离散模型。为了让反向传播奏效,我们需要一种状态连续变化的神经网络节点模型。但是,连续值神经网络早已准备就绪,霍普菲尔德1984年的论文也提到了这点。[5]
下一个必要的突破则花费了更长的时间。当时,反向传播对只有几层的网络效果很好,但当网络层数达到五层或更多时(按照今天的标准,这个层数算是小的),一些偏导数会变得非常小,导致训练过程慢到爆炸。
直到21世纪初,辛顿才为他的玻尔兹曼机找到一个解决方案。更确切地说,是为受限版本的玻尔兹曼机(Restricted Boltzmann Machine,RBMs)。所谓受限,是指这个版本的网络只存在隐藏神经元和可见(非隐藏)神经元之间的连接。[6] 受限玻尔兹曼机在计算建模上非常简便,因为每层隐藏的和可见的神经元可以一次性更新,连接权重可以在同一步中全部调整。辛顿最初的想法是将前馈网络中的连续层对孤立出来,先将它们作为受限玻尔兹曼机训练,使权重大致正确,然后使用反向传播微调整个网络。
加拿大圭尔夫大学(University of Guelph in Canada)的 Graham Taylor(2009年在辛顿门下获得博士学位)评价说,“这种方法看着有点糙,但它确实有效,大家一下子就激动了,我们甚至可以训练五层、六层甚至七层的网络了。人们称它们为‘深度’网络,并开始使用‘深度学习’这个术语。”
受限玻尔兹曼机的技巧并没有持续太久。随着计算能力的暴涨,特别是GPU(图形处理单元)的引入,仅仅几年后,即使没有受限玻尔兹曼机的帮助,人们也可以直接对更大的网络做反向传播训练了。
Taylor 评论说,“如果没有受限玻尔兹曼机学习方法,GPU会不会还被引入?这个问题不好说。但可以肯定的是,受限玻尔兹曼机的热潮扭转了神经网络的颓势:它吸引了新的学生,激发了新的思路。不管怎么说,我认为受限玻尔兹曼机改变了历史的进程。”
图3. 前馈网络,是目前神经网络的基本结构,它通过反向传播算法来训练。这个网络将数字信号从输入层传递到隐藏层,再到输出层,完成像图像分类和文本生成这样的任务。|图由Freddie Pagani绘制;兔子照片由JM Ligero Loarte/Wikimedia Commons/CC BY 3.0提供;俳句由GPT-4生成,OpenAI,2024年10月22日。
今天的神经网络使用数百或数千层神经元,但它们的形式与辛顿当初的版本几乎没有变化。瑞典哥德堡大学(University of Gothenburg in Sweden)的 Bernhard Mehlig 说:“我从20世纪80年代的书学习神经网络,多年以后当我开始教这门课时,我发现其实没什么新的东西,本质上都跟以前的一样。”Mehlig 还提到,他2021年新出版的教科书一共就三个部分,第一部分讲的是霍普菲尔德,第二部分讲的就是辛顿。
现如今,神经网络已经广泛影响了人类社会,包括数据分析、网络搜索和图像创作。那它们具备智能吗?很多人不假思索地否定这一点。恰如马里兰大学(University of Maryland)Sankar Das Sarma说:“机器一直都有很多比人类做得更好的事情,但这与具备人类的智能无关。ChatGPT在某些方面极其出色,但在许多其他方面,它甚至不如两岁的婴儿。”
现在的神经网络和人类在数据掌握方面有巨大的差距。一个受过基本教育的人,生活20年可能只读过和听过几亿个单词。相比之下,今天的大语言模型接受了数千亿个单词的训练,这个数字还随着每个新版本的发布而增长。一旦想到ChatGPT比普通人多一千倍的生活经验,它的表现看起来就不是那么智能了。但可能这也不重要,也许人工智能在某些任务上有失误,但它仍然可以处理好其他合适的任务组合。
辛顿和霍普菲尔德都讨论过不受控制的人工智能的危险。他们的观点是,机器一旦能够将目标拆解为子目标,就会很快推断出:只要不断地给他们自己扩展权限,它们几乎可以胜任一切任务。糟糕的是,因为人工智能经常被要求为其他计算机编写代码(从而获得其他计算机的控制权限),一旦神经网络失控,拔掉一个电源插头并不能阻止它们。
Mehlig 补充说:“我们现在面临着迫在眉睫的风险。有计算机生成的文本和虚假图像正在被用来欺骗公众,甚至影响选举。我认为,大家常常漫谈计算机未来接管世界的事情,这反而让人们忽视了眼下的危机。”
不安主要是源于我们对神经网络实际运作机制知之甚少:数十亿次的矩阵乘法运算如何最终形成预测蛋白质结构或创作诗歌的能力?Das Sarma说:“大公司更关注营收,而不追求理解。获得理解需要更长的时间。理论研究者的工作就是理解现象,而这(人工智能)正是一个有待理解的重大物理现象。物理学家应该对此感兴趣。”
Bialek 说:“面对人工智能领域正在发生的种种突破,我们很难不感到兴奋,同时也很难回避一个事实——我们并不理解底层的机制。如果说这些算是涌现,那么:涌现过程的序参量(order parameter)是什么?涌现出来的到底是什么?物理学有一种量化解析问题的思考方式,这种方式能够带来洞见吗?我们拭目以待。”
作为目前最大的问题,神经网络的底层机制仍然让人无从下手。霍普菲尔德说:“如果有什么明显的可行思路,就一定会有人蜂拥而上。但现在没什么人研究这个问题,因为没人知道从哪里开始。”
但一些小问题更容易解决。例如,为什么反向传播如此可靠地将网络误差降低到接近零,而不会像霍普菲尔德网络那样在高位陷入局部最小值?来自西北大学(Northwestern University)的 Sara Solla 表示:“几年前,斯坦福大学的 Surya Ganguli 做了一项非常精彩的研究。他发现,大多数高位的‘最小值’实际上是鞍点,即这个点在许多维度上是局部最低点,但总有一个维度不是。所以,如果我们继续训练,最终一定把误差继续降低。”
当物理学背景的学者研究这些神经网络的问题时,他们还算在做物理吗?如果我们把“物理学”定义为对自然世界的研究,那么按照这个定义,人工神经网络就不再属于物理学的范畴,因为它们是完全由人类创造的抽象系统,与生物神经元几乎没有相似之处。恰如 Solla 指出:“我们没有仿照鸟拍翅膀飞行去设计我们的飞机,而反向传播之于真实大脑也是如此。工程的目标是创造出能够工作的机器。大自然确实为我们提供了一些启示,但最优解未必是照搬大自然。”
但物理学只能是对自然世界的研究吗?普林斯顿大学的 Francesca Mignacco 说:“无论是数学、计算机科学还是物理学,在多学科领域中,不同学科之间的区别在于它们的方法和思维方式。它们互补但又各不相同。神经网络建模太过复杂,难以实现严格的数学描述。但统计物理恰好有处理高维系统复杂性所需的工具。就我个人而言,我从未因为这个问题可能不属于物理学而停止思考追问。”
霍普菲尔德说:“能够限制我们把物理学思维应用到现实世界系统中的,只有我们的创造力。对于这样的应用物理学,你可以保留狭隘的看法,也可以欢迎更多,我选择后者。”
参考文献
[1]J. J. Hopfield, Proc. Natl. Acad. Sci. USA 79, 2554 (1982).
[2]S. E. Fahlman, G. E. Hinton, T. J. Sejnowski, in Proceedings of the AAAI Conference on Artificial Intelligence, 3, Association for the Advancement of Artificial Intelligence (1983), p. 109.
[3]D. H. Ackley , G. E. Hinton, T. J. Sejnowski, Cogn. Sci. 9, 147 (1985).
[4]D. E. Rumelhart, G. E. Hinton, R. J. Williams, Nature 323, 533 (1986).
[5]J. J. Hopfield, Proc. Natl. Acad. Sci. USA 81, 3088 (1984).
[6]G. E. Hinton, Neural Comput. 14, 1771 (2002); G. E. Hinton, S. Osindero, Y.-W. zzTeh, Neural Comput. 18, 1527 (2006).
[7]M. C. Frank, Trends Cogn. Sci. 27, 990 (2023).
2024年诺贝尔物理学奖授予人工神经网络,这是一场统计物理引发的机器学习革命。统计物理学不仅能解释热学现象,还能帮助我们理解从微观粒子到宏观宇宙的各个层级如何联系起来,复杂现象如何涌现。它通过研究大量粒子的集体行为,成功地将微观世界的随机性与宏观世界的确定性联系起来,为我们理解自然界提供了强大的工具,也为机器学习和人工智能领域的发展提供了重要推动力。
为了深入探索统计物理前沿进展,集智俱乐部联合西湖大学理学院及交叉科学中心讲席教授汤雷翰、纽约州立大学石溪分校化学和物理学系教授汪劲、德累斯顿系统生物学中心博士后研究员梁师翎、香港浸会大学物理系助理教授唐乾元,以及多位国内外知名学者共同发起「非平衡统计物理」读书会。读书会旨在探讨统计物理学的最新理论突破,统计物理在复杂系统和生命科学中的应用,以及与机器学习等前沿领域的交叉研究。读书会从12月12日开始,每周四晚20:00-22:00进行,持续时间预计12周。我们诚挚邀请各位朋友参与讨论交流,一起探索爱因斯坦眼中的普适理论!
详情请见:从热力学、生命到人工智能的统计物理之路:非平衡统计物理读书会启动!
推荐阅读
6. 加入集智,一起复杂!
点击“阅读原文”,报名读书会