Nature速递:微软团队用AI模型重新定义游戏创意生成
摘要
生成性人工智能(AI)有潜力通过支持人类创意构思,即新想法的生成,来改变创意产业。然而,模型能力的局限性带来了将这些技术更全面融入创意实践中的关键挑战。迭代调整和发散性思维仍然是通过技术支持创意的关键,但这些实践在现有的生成性AI模型中得不到充分支持。以游戏开发为视角,我们展示了如何利用对用户需求的理解,推动生成性AI模型的开发和评估,以与这些创意实践保持一致。具体而言,我们介绍了一种先进的生成性模型——世界与人类行为模型(WHAM),并展示了它能够生成一致且多样化的游戏序列,并保留用户的修改,这三项能力被我们认为是确保这种一致性的关键。与以往那些需要手动定义或提取结构的创意支持工具不同,生成性AI模型可以从现有数据中学习相关结构,开启了更广泛应用的潜力。

论文题目:World and Human Action Models towards gameplay ideation 发表时间:2025年2月19日 论文地址:https://www.nature.com/articles/s41586-025-08600-3 期刊名称:Nature
用户需求:游戏开发者需要怎样的AI搭档?
用户需求:游戏开发者需要怎样的AI搭档?
团队访谈了27位游戏开发者,发现两大核心需求:
1. 发散性思维需要边界约束:创意并非天马行空,需符合游戏世界观、物理规则和叙事逻辑。例如,玩家角色不能穿墙,场景风格需与游戏IP一致。
WHAM模型:从玩家行为中学习“游戏规则”
WHAM模型:从玩家行为中学习“游戏规则”
WHAM基于Transformer架构,以离散化token序列处理游戏画面(Frame)和手柄操作(Controller Action),其设计亮点包括:
-
数据驱动:使用真实玩家在3D对战游戏《Bleeding Edge》中的7年游戏数据(超500万局对战)进行训练。
-
多模态建模:通过VQGAN图像编码器将画面转换为token,并将手柄摇杆操作离散化为11档位,实现画面与行为的联合预测。
-
长上下文支持:1.6B参数的大模型可处理1秒(10帧)的上下文,生成长达2分钟连贯的游戏画面。
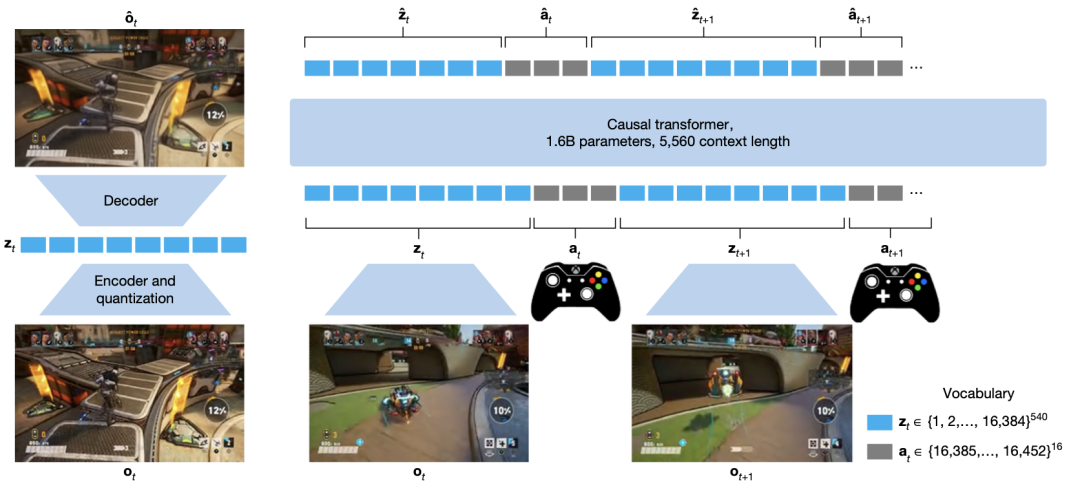
图 1. WHAM架构。将人类游戏玩法定义为一系列离散的tokens,在图像观察和控制器动作之间交替进行。
三项核心能力实测:
WHAM如何通过“考试”?
三项核心能力实测:
WHAM如何通过“考试”?
1. 一致性:虚拟世界的物理法则
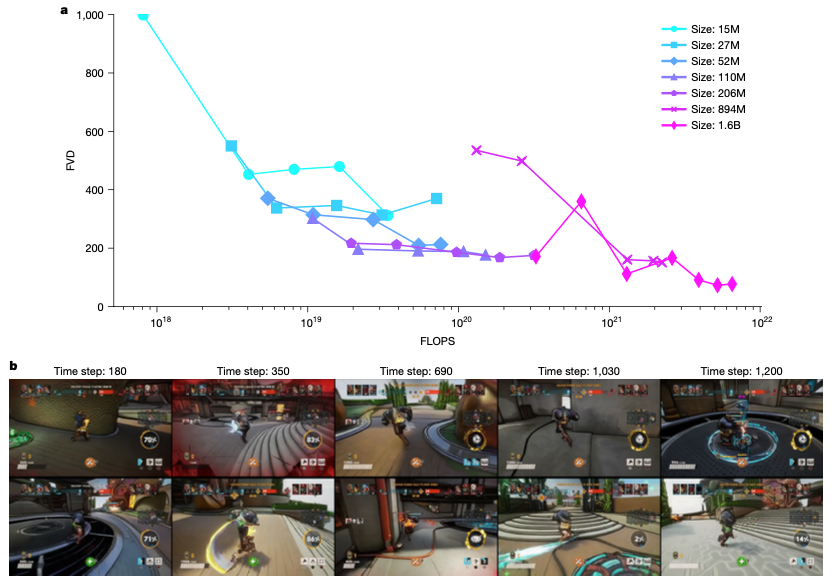
图 2. 一致性结果。(a)在训练计算预算(FLOPS)上的一系列WHAM大小的FVD。FVD适用于更大的模型和计算预算。(b)来自1.6B WHAM的两个示例代(每行一个)的关键帧。每代2分钟,表明1.6B WHAM能够产生长期一致的游戏玩法。
2. 多样性:一场游戏的多元可能
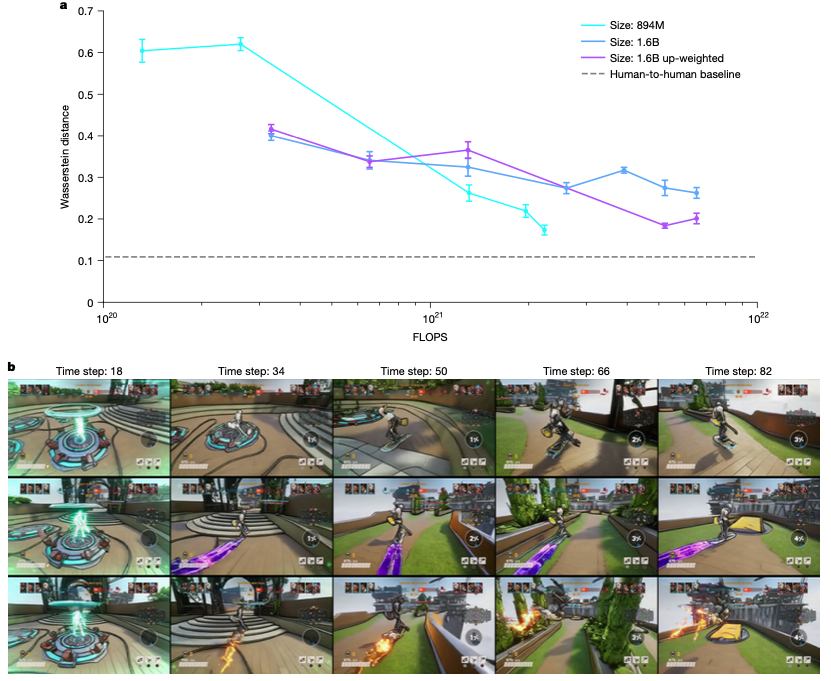
图 3. 多样性的结果。(a)通过与人类行为的Wasserstein距离来衡量的三种WHAM变体的多样性。在102,400个总动作(1,024个轨迹,每个轨迹有100个动作)中,我们对10,000个人类和模型动作进行子采样,并计算它们之间的距离。我们重复10次,并绘制平均值±1标准差。更接近于人与人之间的基线会更好。均匀随机动作的距离为5.3。所有的模型都可以通过训练来改进,并且可以通过增加动作损失的权重来进一步改进。(b)在相同的起始背景下产生的来自1.6B WHAM的三代的例子。我们看到了行为多样性的例子(玩家角色绕着刷出位置转,而不是直奔跳跃点)和视觉多样性的例子(玩家角色所乘坐的悬浮板有不同的皮肤)。
3. 持久性:用户修改的持久保留
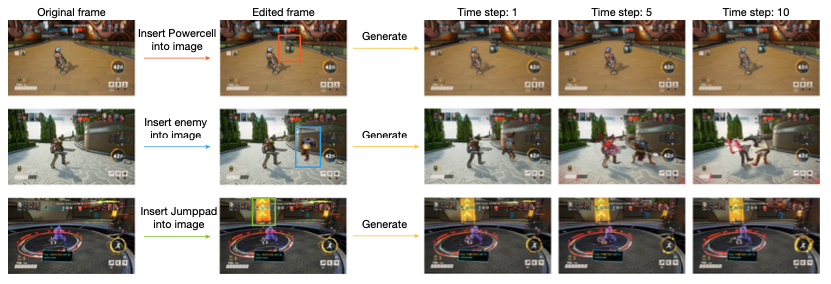
图 4. 编辑过程和定性持久性结果。成功持久性的示例包括Powercell、角色和垂直跳跃平台(Vertical Jumppad)。在我们的持久性评估中,WHAM的生成都是基于无操作(no-op)动作进行的,因此玩家角色和相机应该保持静止。示例中,插入的Powercell在1秒的生成过程中稳定持久,而插入的对手开始攻击玩家角色并造成伤害。垂直跳跃平台被插入到一个地图区域中,该区域在真实游戏和我们的数据中并未出现。然而,它在WHAM的生成过程中始终得以持久。
创意工具箱:WHAM演示器的实战应用
创意工具箱:WHAM演示器的实战应用
团队发布WHAM Demonstrator原型,展示模型如何支持创意流程:
-
视觉化提示:用户可选取任意画面作为起点,生成多条剧情分支。
-
动态迭代:直接涂改画面元素(如新增敌人),观察生成内容如何响应。
-
混合创作:将不同分支的片段拼接,探索融合可能性(如“吸血鬼角色+科幻场景”)。
启示:
生成式AI的下一站是“人类创造力倍增器”
启示:
生成式AI的下一站是“人类创造力倍增器”
彭晨 | 编译
-集智活动预告-

大模型2.0读书会启动
o1模型代表大语言模型融合学习与推理的新范式。集智俱乐部联合北京师范大学系统科学学院教授张江、Google DeepMind研究科学家冯熙栋、阿里巴巴强化学习研究员王维埙和中科院信工所张杰共同发起「大模型II:融合学习与推理的大模型新范式 」读书会,本次读书会将关注大模型推理范式的演进、基于搜索与蒙特卡洛树的推理优化、基于强化学习的大模型优化、思维链方法与内化机制、自我改进与推理验证。希望通过读书会探索o1具体实现的技术路径,帮助我们更好的理解机器推理和人工智能的本质。
从2024年11月30日开始,预计每周六进行一次,持续时间预计 6-8 周左右。欢迎感兴趣的朋友报名参加,激发更多的思维火花!
详情请见:大模型2.0读书会:融合学习与推理的大模型新范式!
6. 加入集智,一起复杂!
微信扫一扫,分享到朋友圈











