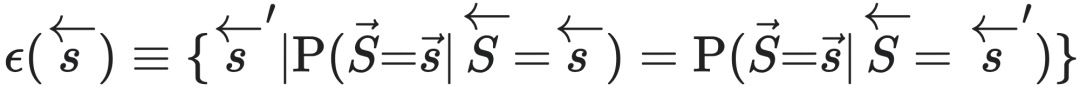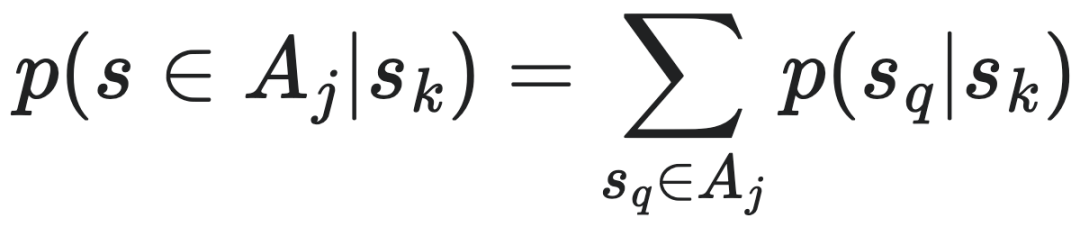计算力学(Computational Mechanics)是一套用于量化涌现的框架。它以一种计算的视角,研究观察者建立的模型在识别涌现时,模型发生的变化。计算力学以信息论和生物进化的思想为基础,是目前最早的对涌现的定量化研究。在应用当中,该理论提出了对复杂性度量的新指标,即统计复杂度,同时还提出了一套识别涌现的算法。
为了系统梳理因果涌现最新进展,北京师范大学系统科学学院教授、集智俱乐部创始人张江老师领衔发起「因果涌现第六季」读书会,读书会将从2025年3月16日开始,每周日早9:00-11:00,持续时间预计10周左右。每周进行线上会议,与主讲人等社区成员当面交流,之后可以获得视频回放持续学习。诚挚邀请领域内研究者、寻求跨领域融合的研究者加入,共同探讨。
“集智百科精选”是一个长期专栏,持续为大家推送复杂性科学相关的基本概念和资源信息。作为集智俱乐部的开源科学项目,集智百科希望打造复杂性科学领域最全面的百科全书,欢迎对复杂性科学感兴趣、热爱知识整理和分享的朋友加入,文末可以扫码报名加入百科志愿者!

↑↑↑扫码直达百科词条
关键词:因果态理论,计算力学,因果涌现,因果态,统计复杂度,香农熵率,世界模型
目录
2. 问题背景
3. 因果态和复杂度
3.5.1 柯氏复杂度的问题
3.5.2 统计复杂度
3.5.3 两种复杂性的对比
4. 混沌动力学实例
5. 与相关研究的比较
计算力学源于 20 世纪 70 年代和 80 年代早期非线性物理学领域对流体力学领域湍流问题的研究。为了识别流体湍流中的混沌动力学,Packard和 Crutchfield等人开发了一套吸引子重构方法[1][2],使用测量的时间序列来重构流体动力系统的状态空间,可以在其中观察混沌吸引子并定量测量它们的不稳定程度及其伴随的复杂性。这套重构方法的有效性在 1983 年通过实验得到了验证[3],之后就被广泛用于识别和量化确定性混沌系统的行为。但是,这套方法无法简明扼要地表达被重构系统的内部结构。为了解决这个问题,计算力学理论应运而生。
计算力学的首次提出是在1989年,Crutchfield在他的一篇论文中[4],基于时间序列重构的状态空间[1] 和自动机理论[5][6][7]定义了一种预测等价关系。利用这种关系分析时间序列数据,识别和量化其中有规律的部分,计算力学就可以构建一个能够预测系统未来行为的模型。
计算力学的核心概念是因果态(Causal State),它是一种与微观状态预测等价的特殊的宏观态。基于这种预测等价性的宏观态划分思想可以追溯到70年代的马尔科夫链的成块性(Lumpability)理论。Kemeny和Snell在1969年针对马尔科夫链提出成块性这一概念,目的在于判断一个马尔科夫动力系统是否是可被简化归并的。对于任意一个马尔科夫链,我们可以判断某种划分是否是成块的。成块的划分要求对状态的归并要尽可能地保留马尔可夫链中的原始重要信息,并保证划分操作与动力学操作的可交换性。不过在马尔科夫链中,成块性只是对于划分的一种要求,而没有追求最优的划分。对成块性的进一步了解,请参考词条马尔科夫链的成块性。与之相比,计算力学首先关注的不只是马尔科夫动力学,而是要囊括更广泛的动力学形式。此外,计算力学试图提出一种最优的划分,能极大地保留对预测有用的信息。此外,当一般的动力学过程退化到马尔科夫动力学的时候,成块性的成立条件实际上与因果态的定义具有一定的相似性。
2.1 自然和社会现象中的涌现
有一些自然和社会现象非常引人入胜,但也很令人困惑,比如行为简单的蚂蚁可以形成复杂的社会,在没有控制中心的情况下自发产生特异化的社会分工[8]。在没有领导者引导的情况下成群的鸟以步调一致的队形飞行,成群的鱼以连贯的阵列游动,突然一起转向[9]。经济中商品的最佳定价似乎源于主体遵守局部的商业规则[10]。这些现象中的全局协调是如何出现的?是否有共同的机制引导着这些不同现象的出现?在复杂系统理论中把这类许多独立子系统相互作用后产生高度结构化的集体行为的现象称作涌现。
目前对涌现的研究理论有基于有效信息的因果涌现理论、基于信息分解的因果涌现理论、基于可逆性的因果涌现理论,基于转移熵的动力学解耦理论[11]、基于格兰杰因果的G-emergence理论[12]等等。计算力学是基于统计复杂度对涌现的定量化研究理论,它提出的时间最早,虽然对涌现的的研究方法与上述理论均不同,但有很多研究思路是相似的,它定义的统计复杂度、因果态、斑图重构机器等概念对涌现的研究有很大启发和借鉴意义。
2.2 计算力学中的涌现
什么是涌现?从直觉上来说,涌现现象就是系统出现了新的特征。但是什么是“新特征”呢?特征的新又“新”在哪里?所以,我们还需要更精确的语言对涌现的概念进行描述。涌现通常被理解为一个过程,该过程所产生的结构并不能直接由控制系统的定义所约束以及被瞬时力所描述。比如一堆随机运动的粒子,虽然它们受到的瞬时力可以用运动方程描述,但是从宏观尺度上却会表现出诸如压强、体积以及温度等新特征。我们需要引入斑图的概念来明确说明什么是新特征,否则涌现这一概念几乎没有内容,因为几乎任何时间依赖的系统都会表现出涌现特征。
在计算力学中[13],斑图通常指的是从时间序列中总结出的规律性结构。实际上,检测到的斑图通常是通过观察者选择的统计数据来隐含假定的,可能某些斑图的功能表现与其数学模型一致,但这些模型本身依赖于一系列理论假设。简而言之,斑图通常是被猜测出来的,观察者通过固定的规律库来预测这些结构,然后再进行验证。可以用通信信道做一个类比,观察者就像是一个已经手握密码本的接收者,任何未能通过密码本解码的信号本质上都是噪声,即观察者未能识别的斑图。
在系统内部的协调行为中,有一种斑图变得尤为重要,这种斑图会相对于该系统的其他结构显现其“新颖性”。由于没有外部的参照来定义这种新颖性,我们可以将这个过程称为内在涌现(Intrinsic Emergence)。比如在高效的资本市场中,主体根据从集体行为中涌现出的最优定价,调整其个人生产-投资和股票所有权策略[10]。对于主体的资源配置决策而言,通过市场的集体行为涌现出的价格是准确的信号,它完全反映了所有可用信息。内在涌现的独特之处在于系统形成的斑图赋予了系统额外的功能性,并支持全局信息处理,如设定最优价格等。更具体地说,内在涌现可以直接嵌入系统非线性计算过程之中,能够被系统直接利用,这样就赋予了系统额外的功能性。
总而言之,计算力学区分了三个概念:
-
对涌现的直觉定义:系统中出现任何可以被称为新颖的特征。
-
斑图涌现(Pattern Formation):观察者在系统中识别出的有规律的结构。
-
内在涌现(Intrinsic Emergence):系统本身捕捉并利用它自身出现的斑图。
2.3 进化的系统模型
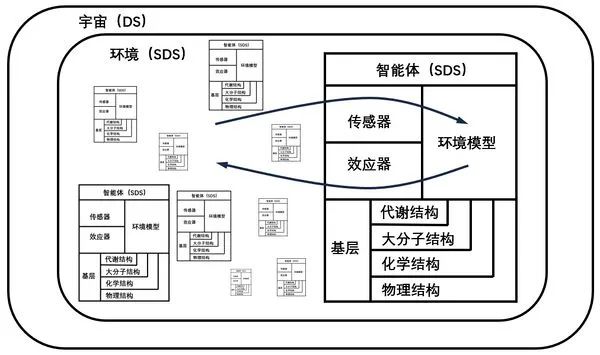
我们可以从多智能体系统的视角来阐述内在涌现的问题[13],从而为一个高度有序的系统是怎么从混沌中涌现的提供一种可能的解释。但是该视角在解释生命形式的多样性方面依然能力有限。因此要将系统限制在一个结构和生物特征明确的确定性动力系统(Deterministic Dynamical Systems,简称DS)中,并把它简化为包括一个环境和一组适应性观察者或“智能体”的模型,这样才能清晰地定义智能体的性质。智能体(Agent)试图构建和维持一个对其环境具有最大预测能力的内部模型。每个智能体的环境是其他智能体的集合,可以被视为一个随机的动力系统(Stochastic Dynamical Systems,简称SDS)。在任何给定的时刻,智能体感知到的是当前环境状态的投影。随着时间的推移,感官装置产生一系列测量,这些测量引导智能体利用其可用资源(下图中的“基层”)来构建环境模型。基于环境模型捕捉到的规律,智能体可以通过效应器采取行动,最终改变环境状态。
上图为以智能体为中心的环境视图:宇宙可以被视为一个确定性动力系统,即使规则和初始条件是确定的,随着规模的增长,系统也会变得极为复杂。每个智能体所看到的环境是一个由所有其他智能体组成的随机动力系统。其随机性源于其内在的随机性和有限的计算资源。每个智能体本身也是一个随机动力系统,因为它可能会从其基层和环境刺激中采样或受到无法控制的随机性所困扰。基层代表了支持和限制信息处理、模型构建和决策的可用资源。箭头表示信息流入和流出智能体的方向。
智能体面临的基本问题是基于对环境状态的建模,来对未来环境进行预测。这需要一个量化的理论来描述智能体如何处理信息和构建模型。
智能体需要一种有效的描述方式处理所接受到的环境信息,使其可以把环境信息压缩成一个有限的状态空间,并存储于内部环境模型中。为了找到这种有效的描述方式,我们首先需要定义所谓的智能体状态的概念:状态可以被理解为智能体所接收到的全部历史信息,即历史信息即状态。之后,我们将引入”因果态”的概念,它相当于是对状态的一种粗粒化描述。下面给出正式定义:
3.1 状态的定义
智能体对环境的测量精度一般都是有限的,测量结果只能描述环境状态的某种投影。我们可以将环境从过去到未来的变化用一个离散的稳定随机过程描述,状态的取值空间则为双无限序列可数集合 =⋯s−2s−1s0s1s2⋯,也就是说,一个智能体的状态指的是一个无限长的时间序列。
基于当前的时刻t,我们可以将
=⋯s−2s−1s0s1s2⋯,也就是说,一个智能体的状态指的是一个无限长的时间序列。
基于当前的时刻t,我们可以将 分为单侧前向序列
分为单侧前向序列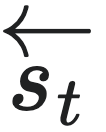 =⋯st−3st−2st−1和单侧后向序列
=⋯st−3st−2st−1和单侧后向序列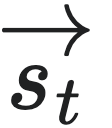 =stst+1st+2st+3⋯两个部分,所有可能的未来序列
=stst+1st+2st+3⋯两个部分,所有可能的未来序列 形成的集合记作
形成的集合记作 ,所有可能的历史序列
,所有可能的历史序列 形成的集合记作
形成的集合记作 。某一个时刻的状态指的是截止到当前时刻的历史序列。
。某一个时刻的状态指的是截止到当前时刻的历史序列。
3.2 因果态的定义
3.2.1 划分
通过对状态空间进行划分(partition),智能体可以用一种更加粗糙的方式来描述同样的状态,这一过程也被人们叫做粗粒化。划分可以被理解为一种映射,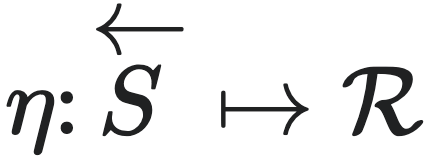 ,其中
,其中 是状态空间的子集的集合,要满足其元素彼此互斥,而且所有元素的并集等于
是状态空间的子集的集合,要满足其元素彼此互斥,而且所有元素的并集等于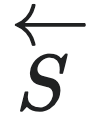 的条件。通过划分映射,智能体能够得到的所有子集都可以被视为对应着一个宏观态。
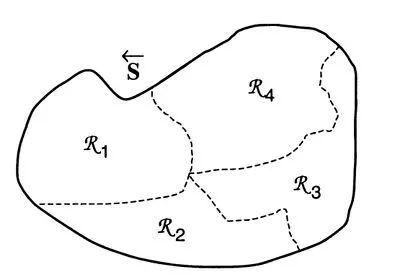
上图为某种划分的示意图[14],值得注意的是,
的条件。通过划分映射,智能体能够得到的所有子集都可以被视为对应着一个宏观态。
上图为某种划分的示意图[14],值得注意的是,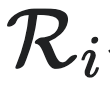 不必形成紧致集,也可以是康托集或其他更特殊的结构,上图为了示意清楚才这样画的。
于是,智能体就需要学习到一种有效的划分,即如何从观测到的状态(可以称之为微观态)到智能体压缩后得到的隐空间上的状态(可以称为宏观态)能够很好对应,使得宏观态更加有效地反映微观态中的重要信息。那么,什么叫做有效呢?
不必形成紧致集,也可以是康托集或其他更特殊的结构,上图为了示意清楚才这样画的。
于是,智能体就需要学习到一种有效的划分,即如何从观测到的状态(可以称之为微观态)到智能体压缩后得到的隐空间上的状态(可以称为宏观态)能够很好对应,使得宏观态更加有效地反映微观态中的重要信息。那么,什么叫做有效呢?
3.2.2 因果态
对于集合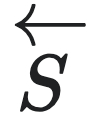 的划分可以有很多种,若某一种划分能够在预测能力最强的同时又非常简洁,那么它肯定是最优的划分,我们把这种用最优的划分方法得到的宏观态称为因果态。因果态就是智能体对测量结果进行处理后,根据其内部模型(尤其是状态结构)识别出的斑图,并且这种斑图不随时间发生变化。
的划分可以有很多种,若某一种划分能够在预测能力最强的同时又非常简洁,那么它肯定是最优的划分,我们把这种用最优的划分方法得到的宏观态称为因果态。因果态就是智能体对测量结果进行处理后,根据其内部模型(尤其是状态结构)识别出的斑图,并且这种斑图不随时间发生变化。
3.2.2.1 预测等价关系
对于任意时刻t 和t′,在给定过去状态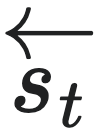 的条件下,未来状态
的条件下,未来状态 的分布与给定过去状态
的分布与给定过去状态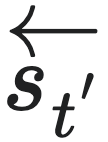 的条件下,未来状态
的条件下,未来状态 的分布完全相同。那么我们就称
的分布完全相同。那么我们就称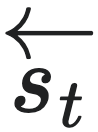 与
与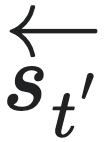 等价,记为:
等价,记为: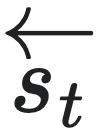 ∼
∼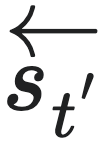 ,或简记为t∼t′,其中“∼ ” 表示由等效未来状态所引起的等价关系,也叫预测等价性(predictive equivalence),可以用公式表示为:
,或简记为t∼t′,其中“∼ ” 表示由等效未来状态所引起的等价关系,也叫预测等价性(predictive equivalence),可以用公式表示为:
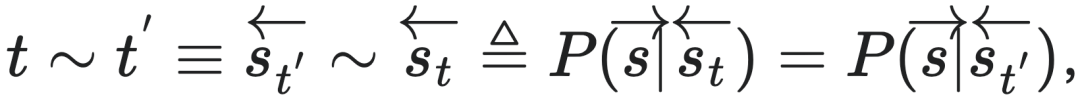
也就是说,若t 和t′对未来状态预测的分布相同,则它们对应的状态就都具有一种等价性,这就是因果态定义的来源。
3.2.2.2 因果态
我们可以直接将因果态定义为一个从状态集到状态子集的映射,即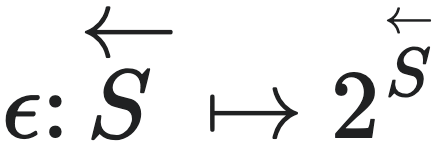 ,其中
,其中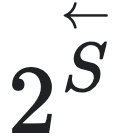 是
是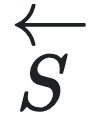 的幂集,且ϵ需要满足如下条件:
的幂集,且ϵ需要满足如下条件:
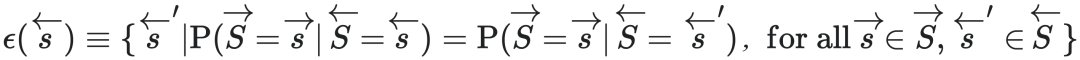
其中,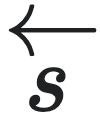 为历史序列的随机变量。
所有的因果态的集合,可以由预测等价关系”∼“诱导的对状态空间的一种划分来定义,即状态集与等价关系的商集:S=
为历史序列的随机变量。
所有的因果态的集合,可以由预测等价关系”∼“诱导的对状态空间的一种划分来定义,即状态集与等价关系的商集:S= /∼,其中S为因果态划分。
/∼,其中S为因果态划分。
3.2.2.3 举例说明
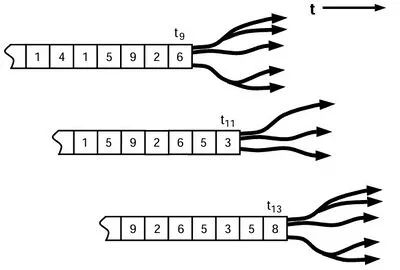
为了说明因果态的概念,我们绘制下面的示意图以举例说明:
如上图所示[13],左侧的数字代表t时刻的状态序列,右侧的箭头形状代表对未来状态预测的分布,可以观察到t9和t13时刻的箭头形状完全相同,说明它们对未来状态预测的分布相同,则处于相同的因果态;同样的道理,在t11时刻,它的箭头形状与t9和t13时刻不同,则处于不同的因果态。
3.2.2.4 小结
内在计算(intrinsic computation)的核心思想是预测等价性[15],即系统的历史能够用来预测其未来行为的一种等价性。通过构建预测模型,内在计算能够识别系统中的结构,并量化这些结构的复杂性和稳定性。它可以让我们能够将自组织视为系统中规律性和规则性的涌现,而这些规律性和规则性是系统在特定的初始条件和外部驱动下自发形成的。内在计算的一个重要应用是在于理解从完全规则到完全无序之间组织结构的差异和过渡。比如,木星的大红斑是一个经典的自组织现象,其规模和稳定性无法通过流体力学方程的求解而获得直接解释。然而,内在计算能够通过分析该现象的历史数据,构建出一个能够准确预测其未来行为的模型,从而揭示出其背后的自组织机制。
3.3 因果态的主要性质
为什么我们要关注因果态这样一种特定的宏观态呢?下面是因果态的两个主要性质,能够体现出因果态是一种最理想的宏观态:
3.3.1 最大预测性
性质1(因果态具有最大预测性):对于宏观态 和正整数L,都有
和正整数L,都有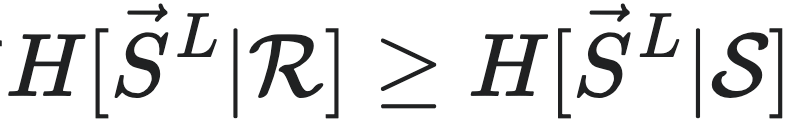 ,
,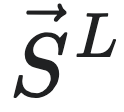 为长度为L的未来序列集合,S为因果态划分,所有可能的历史序列记作
为长度为L的未来序列集合,S为因果态划分,所有可能的历史序列记作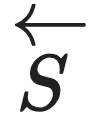 。
。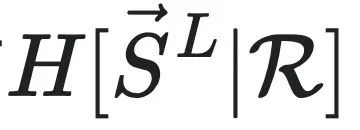 和
和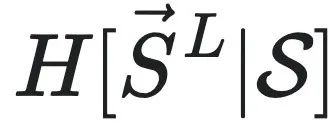 是
是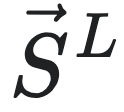 的条件熵。可以理解为因果态集合S是在所有的划分宏观态集合R中,预测能力最强的一种宏观态,证明过程如下:
的条件熵。可以理解为因果态集合S是在所有的划分宏观态集合R中,预测能力最强的一种宏观态,证明过程如下:
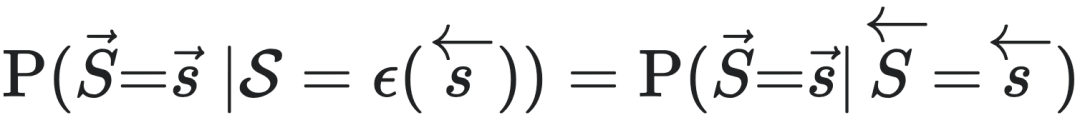
因为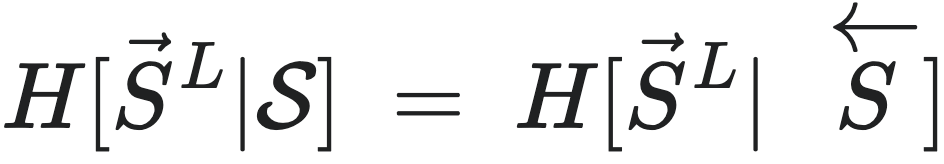 ,且
,且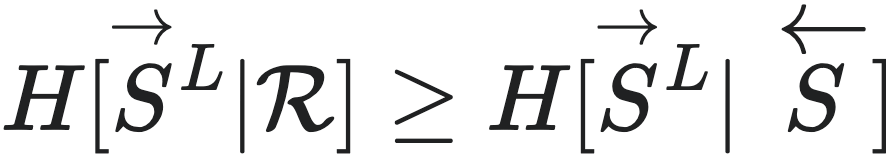 所以
所以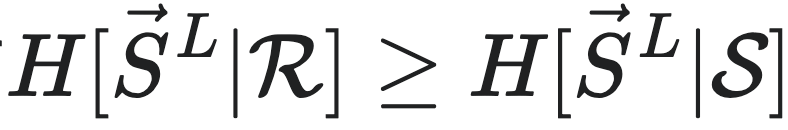
3.3.2 最小随机性
性质2(因果态具有最小随机性):设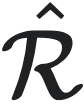 和
和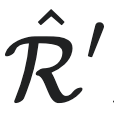 为满足性质1中不等式等号成立的宏观态,则对于所有的
为满足性质1中不等式等号成立的宏观态,则对于所有的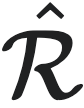 和
和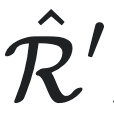 ,都有
,都有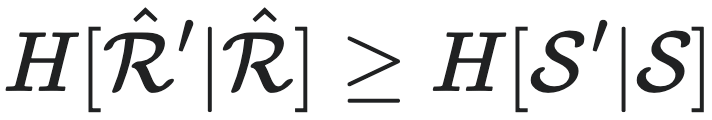 ,其中
,其中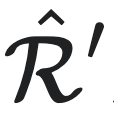 和S′分别是该过程的下一时刻状态和下一时刻因果态。
该性质可以被理解为在相同预测能力的前提下,因果态集合S在所有的宏观态
和S′分别是该过程的下一时刻状态和下一时刻因果态。
该性质可以被理解为在相同预测能力的前提下,因果态集合S在所有的宏观态 的集合中,随机性最小。
用互信息的角度去理解的话,上式等价于
的集合中,随机性最小。
用互信息的角度去理解的话,上式等价于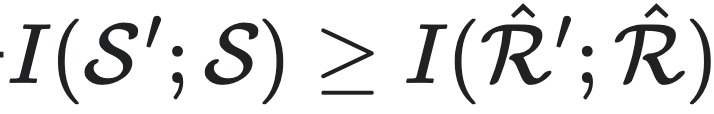 ,可以理解为因果态为所有的与它自己的下一时刻的互信息中的最大的一个宏观态。
若想更深入的理解因果态的性质可以阅读Cosma Rohilla Shalizi 和James Crutchfield合写的一篇论文[14],里面有因果态更多的性质和对应的形式化证明过程。
,可以理解为因果态为所有的与它自己的下一时刻的互信息中的最大的一个宏观态。
若想更深入的理解因果态的性质可以阅读Cosma Rohilla Shalizi 和James Crutchfield合写的一篇论文[14],里面有因果态更多的性质和对应的形式化证明过程。
3.4 斑图重构机器
前面给出了因果态的定义,接下来讨论一个智能体是如何从观测到的时间序列数据中,自动地发现因果态的问题。为了解决这个问题,计算力学建立了名为斑图重构机器(ϵ-machine)的模型,其中因果态所对应的划分映射被记为ϵ。它可以重构测量结果中的序列,去除随机噪声后识别其中的因果态。它的形式化定义可以用公式表示为M=(S,T),S为因果态的集合,T为因果态到因果态跳转的集合,它类似于一个粗粒化后的宏观动力学。T可以表示为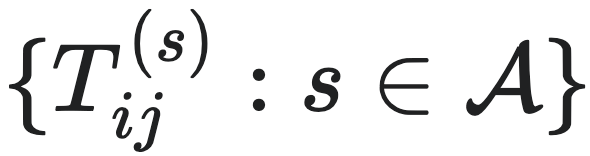 ,其中
,其中 为可数集。
为可数集。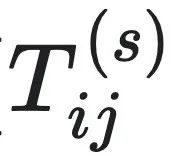 的定义为:
的定义为:
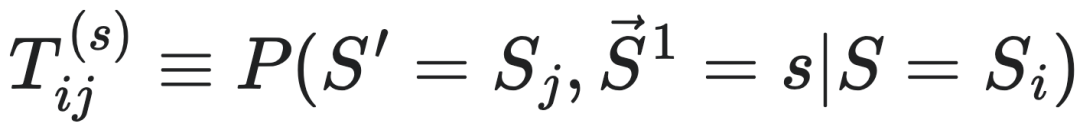
其中: S表示当前因果态。 S′表示下一时刻因果态。 代表未来序列的第一个符号,所以因果态S′的第一个符号都是s。 s是从可数集
代表未来序列的第一个符号,所以因果态S′的第一个符号都是s。 s是从可数集 中取值的一个符号。 Si和Sj分别表示第i个和第j个因果态,它们是对历史序列的一种划分。
中取值的一个符号。 Si和Sj分别表示第i个和第j个因果态,它们是对历史序列的一种划分。 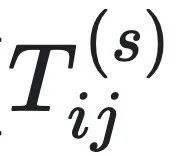 表示在当前因果态为Si的条件下,下一个因果态变为Sj且未来序列第一个符号为s的转移概率。这个公式可以描述斑图重构机器中因果态之间的转移关系以及与过程输出符号的对应关系,从而刻画了过程的动态行为和内在结构。
每个S都对应一个ϵ映射,它和T函数一起组成一个有序对{ϵ,T},这就是“斑图重构机器”(ϵ-machine)。后文“模型的重构”一节中会详细介绍如何获得这个斑图重构机器,以及智能体的内在模型会如何根据观测到的新数据,动态更新ϵ映射和T函数。
表示在当前因果态为Si的条件下,下一个因果态变为Sj且未来序列第一个符号为s的转移概率。这个公式可以描述斑图重构机器中因果态之间的转移关系以及与过程输出符号的对应关系,从而刻画了过程的动态行为和内在结构。
每个S都对应一个ϵ映射,它和T函数一起组成一个有序对{ϵ,T},这就是“斑图重构机器”(ϵ-machine)。后文“模型的重构”一节中会详细介绍如何获得这个斑图重构机器,以及智能体的内在模型会如何根据观测到的新数据,动态更新ϵ映射和T函数。
3.5 统计复杂度
3.5.1 柯氏复杂度的问题
智能体在构建和优化斑图重构机器的过程中,由于计算资源的限制,不能无限制地增加模型的大小。因此我们需要一个能够量化模型复杂度的指标,以便监控和调整模型的大小,确保模型能匹配已有的计算资源。柯式复杂度K(x),也就是在通用确定性图灵机(Universal Turing Machine,简称UTM)上运行时生成字符串x的最小程序长度,是人们常用的一个复杂性度量指标。
然而,柯式复杂度存在两个明显的问题,第一个问题是它的不可计算性,柯氏复杂度仅仅是一个理想化的概念;第二个问题是它可能无法度量程序的结构和动态特性。因为柯式复杂度K(x)需要考虑字符串中的所有比特,这就包括随机生成的比特。因此,柯氏复杂度会在随机生成的比特上计算出较大的复杂性,而这与我们的直觉不符:复杂性不能等价于随机性。
3.5.2 统计复杂度
为了解决这两个明显问题,计算力学提出了统计复杂度Cμ(x)的概念,用来量化模型的复杂性,它可以反映x的结构和动态特性,以及能够计算出有效建模所需的计算资源。它的公式为:

这里, Cμ(x)是统计复杂度[4],表示时间序列x的复杂性度量。它反映了在给定精度μ下,能够生成该序列的最小伯努利图灵机的程序长度。
这里,伯努利图灵机(Bernoulli-Turing machine,简称BTM)是一种概率性图灵机,是确定性图灵机的一种扩展。它通过引入随机数发生器,可以生成离散的随机序列。伯努利图灵机包含输入纸带、输出纸带、有限状态控制单元和工作纸带。在运行过程中,伯努利图灵机按照常规图灵机的方式读取纸带上的符号和自身的当前状态,并依据内置的规则表进行操作。与普通图灵机不同的是,其规则表中有一些可随机执行的规则,它会根据随机数发生器的采样结果来决定具体的执行路径。例如,在某个状态下,图灵机可能有两种可选的操作,普通图灵机根据确定的规则选择其中一种,而伯努利图灵机则通过随机源(即随机数发生器)以一定的概率来执行其中的某一种操作。
Mmin(x∣BTM)代表在能够捕捉数据x条件下的所有伯努利图灵机中的最小的模型[16]。这个模型是能够在允许误差为μ的条件下有效预测x的最简单形式。‖⋅‖这个符号表示对模型复杂度的量化,例如图灵机的指令表长度。
由于内部模型(ϵ-machine)作为一种伯努利图灵机,本身也是用字符串(因果态)来描述的,所以可以用长度、香农熵等指标来度量内部模型的复杂度。当我们使用香农熵来刻画内部模型的复杂度时,我们可以给出对于观测序列来说一个等价的可计算的定义[4]:

统计复杂度的一个特征是,对于完全随机对象,有Cμ(x)=0,如抛硬币产生的序列;以及对于简单的周期性过程,如x=00000000…0,都会有Cμ(x)=0。因此,统计复杂度的值对于(简单的)周期性过程和完全随机过程都很小。所以,与柯氏复杂度相比,统计复杂度这种度量Cμ(x),相比于柯氏复杂度来说,剔除了通用图灵机在模拟随机比特时所花费的计算努力。
3.5.3 两种复杂性的对比
下图展示了柯式复杂度和统计复杂度随着序列从简单周期性变为完全随机的过程中二者的差异。如图(a)所示,柯式复杂度会随着序列随机性的增加而单调递增。相反,统计复杂度在周期和随机两个极端点上均为零,并在中间达到最大值(见图(b))。这反映出如下的观点:随机性在统计上是简单的,一个完全随机的过程具有零统计复杂度;周期性在统计上也是简单的,一个完全是周期性的过程具有较低的统计复杂度。复杂过程是在这两个极端之间产生,并且是可预测机制和随机机制的混合,有中等程度随机性的数据具有最大的统计复杂度。
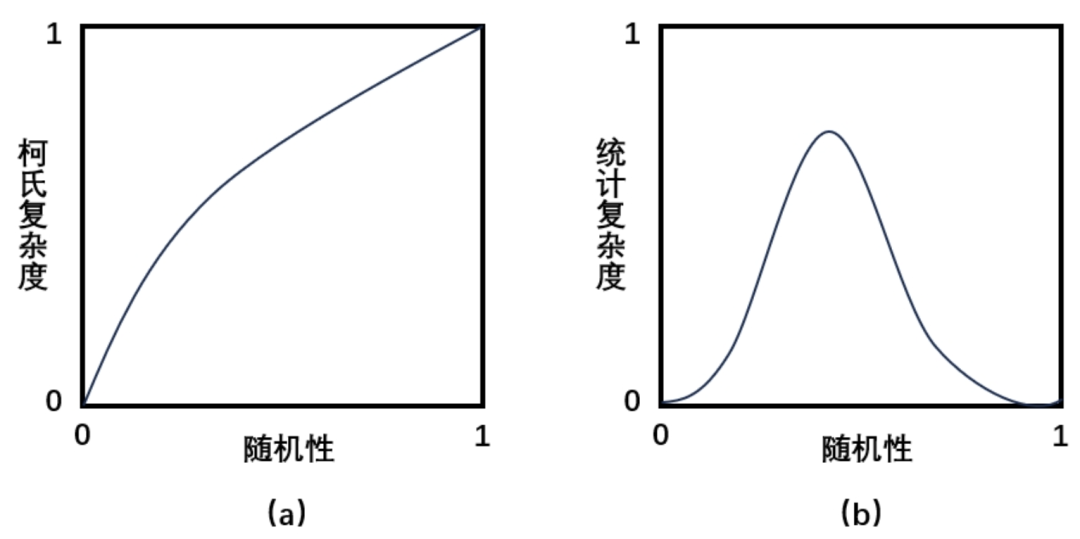
3.6 香农熵率与复杂度
上文中提到的一个序列的随机性可以用香农熵率(Shannon Entropy Rate)来度量,香农熵率是信息论中的一个概念,它是香农熵的扩展,主要用于描述时间序列在单位时间上的平均信息量。在这里,香农熵率可以定义为:
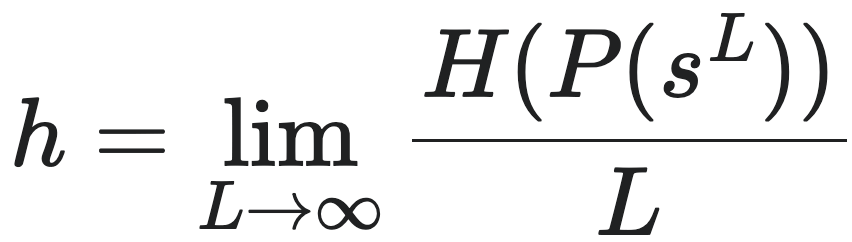
其中,sL是环境信息生成的离散符号序列,L为序列的长度,P(sL)是序列sL的边际分布,H是香农熵。在建模框架中,h可以解释为智能体在预测序列sL的后续符号时的误差率。由该公式可见,熵率也就是自信息的平均值。
香农熵率是归一化的度量信息不确定性程度的指标,信息的不确定性越高,香农熵率越大。对于简单的周期性过程,如x=00000000…0,香农熵率为0,对于完全随机的对象,如抛硬币产生的序列,香农熵率为1。
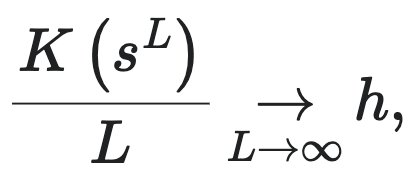
上文中我们介绍了柯式复杂度、统计复杂度和香农熵率这三个与复杂性相关的指标,其实这三者之间存在一个近似关系,可以用公式表示为:
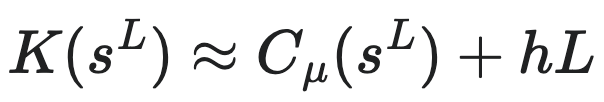
如果在已确定描述语言(程序)的情况下,柯式复杂度K(sL)可以理解为描述sL所用的总信息量。hL为允许损失的信息量。统计复杂度Cμ(sL)可以理解为允许存在误差率h的情况下,描述sL所用的最少信息量。
3.7 模型重构
由于智能体的计算资源是有限的,当测量结果中的数据量超过模型能够处理的极限时,我们就需要构造模型,以更简洁地描述数据。这样做的目的是在保持计算资源不变的情况下,确保智能体仍然能够对外界进行有效的预测。这一过程可以反复迭代地进行,也就是说,因果态序列也可以被看做是原始状态序列,因此智能体可以在因果态基础上再次重构生成该因果态的模型。于是,这便形成了一系列不断升级的层级化的重构过程。
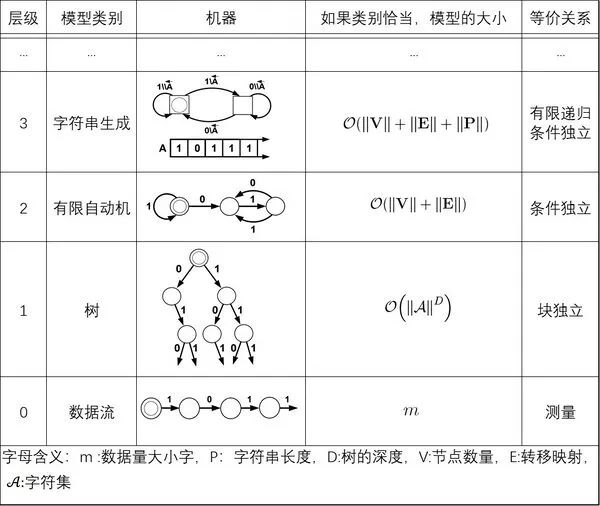
重构的方法主要是通过寻找原有模型中相似的状态组,从而形成因果态;然后,在已经识别出的因果态中,我们进一步抽象出更高层级的因果态组。这样,随着数据量的增大,我们就可以不断地在上一层级抽象出更高的层级,从而在计算资源有限的情况下,仍然能够应对更大量的数据。譬如,当智能体观测到“121212”时,会把“12”看成是一个模块,用一个字符“A”来表示,于是原本的微观态字符串就可以被重构为“AAA”这样的宏观态字符串,复杂度就降低了。而当模型进一步观测到更长的字符串是“12121231212123”时,它便需要跳出原本的分组,而把“1212123”看成是一个新的模块,可以用一个字符“B”来表示,于是内部模型可以进一步用“BB”这样的新字符串来表示同一个观测对象。这便是一次模型重构不断升级的过程。下表中列举了一种模型重构的可能途径:
上表为因果时间序列建模层级,展示了可能的前四个层级,每个层级根据其模型类别定义。但这个过程仅仅是一个示例,可以不止四个层级。模型本身由状态(圆圈或方块)和转移(标记箭头)组成,每个模型都有一个独特的起始状态,由一个双重圆圈表示。数据流本身是最低层级,通过将序列测量分组为重复子序列,从数据流中构建出深度为D的树。下一个层级的模型,即具有状态和转移的有限自动机(Finite Automaton,简称FA),可以通过将树节点分组从树中重构。图中所示的最后一个层级,字符串生成机器(Pattern Matching,简称PM),可以通过将有限状态自动机的状态进行分组并推断出操控寄存器中字符串的生成规则来构建。
考虑一个由m个测量结果构成的数据流s,如果它是周期性的,那么第0级(Level 0),即测量结果本身,它的表示方法依赖于m。在极限m→∞情况下,第0级会产生一个复杂度无穷大的表示。当然,第0级是最准确的数据模型,尽管它几乎没有任何帮助,几乎不值得被称为“模型”。相比之下,一个深度为D的树将给出一个有限表示,即使数据流的长度是无限的,只要数据流具有小于等于D的周期。这个树有长度为D的路径,由数据流的周期给出。这些路径中的每一个都对应于s中重复模式的一个不同阶段。如果s是非周期性的,那么树模型类将不再是有限的,并且与m无关。事实上,如果数据流具有正熵率(>h>0),那么树的大小将呈指数增长,≈‖ ‖Dh ,因为D的增加解释了s 中长度D不断增加的子序列。粗略地说,如果数据流具有随时间衰减得足够快的相关性,则下一级(随机)有限自动机将给出有限表示。状态数‖V‖表示数据流中的内存量,因此表示s中测量值之间存在相关性的典型时间长度。但也有可能第 2 级不提供有限表示。那么就需要另一个级别(第 3 级)。
‖Dh ,因为D的增加解释了s 中长度D不断增加的子序列。粗略地说,如果数据流具有随时间衰减得足够快的相关性,则下一级(随机)有限自动机将给出有限表示。状态数‖V‖表示数据流中的内存量,因此表示s中测量值之间存在相关性的典型时间长度。但也有可能第 2 级不提供有限表示。那么就需要另一个级别(第 3 级)。
3.8 模型重构算法
上面介绍了斑图重构机器,是智能体识别因果态的一种方式。若结合模型重构的概念,我们可以给出斑图重构机器的完整定义:斑图重构机器(ϵ-machine)是能够用最少的计算资源对测量结果进行有限描述同时复杂度最小的模型。模型重构的算法步骤如下:
1. 在最低水平上,设定0级模型为描述数据本身,即M0=s,将初始层级l设置为比0级高一级,即l=1;
2. 从更低模型重构模型Ml=Ml−1/∼,其中∼表示l级上的因果等价类;
Ml=Ml−1/∼的含义是,在l−1级上被区别对待的状态在l级上可以被视为同一个因果态。此时因果态集合S和因果态上的转移概率映射集合T都被更新了;
3. 收集更多的数据,增大序列长度L,得到更加精确的一系列模型Ml和因果态集合S;
4. 根据统计复杂度可计算的定义Cμ(x)≡H[S],计算模型Ml的统计复杂度。如果随着L增大,模型的统计复杂度发散,即 ,那么回到第二步,得到更高级模型Ml+1;
5. 如果模型复杂度收敛,意味着算法已经重建好了一个合适的斑图重构机器,程序退出。
,那么回到第二步,得到更高级模型Ml+1;
5. 如果模型复杂度收敛,意味着算法已经重建好了一个合适的斑图重构机器,程序退出。
4.1 逻辑斯谛映射
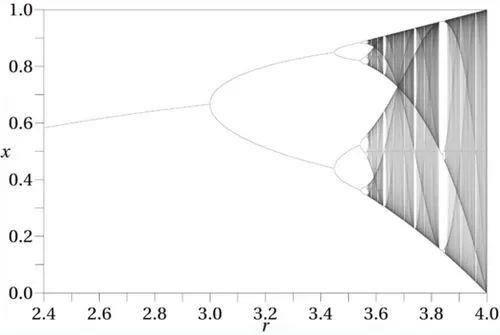
接下来将演示如何将计算力学和模型重构算法应用于一个具体的实际案例[13]。这个案例是混沌动力学中的逻辑斯谛映射 (logistic map),作者特别展示了算法在周期倍增的混沌路径上的表现。用于重建模型的数据流来自逻辑斯谛映射的轨迹,该轨迹是通过迭代映射xn+1=f(xn)生成的,迭代函数为f(x)=rx(1−x),其中非线性参数r∈[0,4],初始条件x0∈[0,1],迭代函数的最大值出现在xc=1/2。
上图为迭代函数f(x)=rx(1−x)中极限状态x与参数r的关系图[13],当<r<3.5699...时函数存在倍周期现象,当>r>3.5699...时会出现混沌现象。由于观察者观测的精细程度有限,若要识别混沌中的有序结构,就需要对x进行粗粒化操作,方法是通过二元分割观察轨迹x=x0x1x2x3… ,将其转换为离散序列 ={xn∈[0,xc)⇒s=0,xn∈[xc,1]⇒s=1},这种划分是“生成”的,这意味着足够长的二进制序列来自任意小的初始条件间隔。因此,可以使用粗粒化的观测P来研究逻辑斯谛映射中的信息处理。
={xn∈[0,xc)⇒s=0,xn∈[xc,1]⇒s=1},这种划分是“生成”的,这意味着足够长的二进制序列来自任意小的初始条件间隔。因此,可以使用粗粒化的观测P来研究逻辑斯谛映射中的信息处理。
4.2 统计复杂度-熵率图
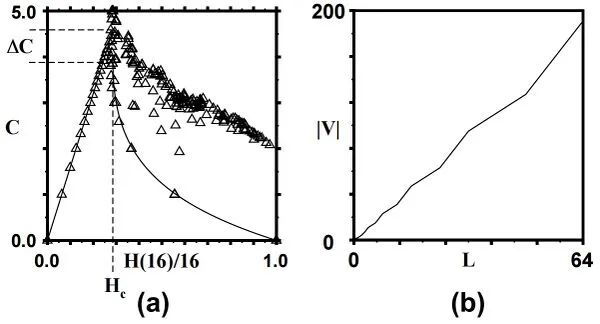
上图(a)为逻辑斯谛映射中统计复杂度Cμ与香农熵率H(L)/L的关系[13],三角形表示(Cμ,H(L)/L)的大概位置,对应非线性参数r的 193 个取值,其中子序列长度L=16,覆盖部分实验数据的粗实线是Cμ=0时对H(L)/L得出的解析解曲线。
本图表现了两个重要特征。第一个特征是熵率的极值导致零复杂度,也就是说在H(L)/L=0处最简单的周期过程和在H(L)/L=1处最随机的过程在统计复杂性上看都是简单的,它们都具有零复杂度,因为它们是由具有单一状态的斑图重构机器描述的;第二个特征是在两个极端情况之间,复杂度明显升高,并在临界熵率值Hc附近出现明显峰值(此处r=3.5699...)。rc=3.5699...刚好是逻辑斯蒂映射的临界相变点,当r<rc时,模型处于周期行为;当r>rc时,模型进入混沌行为区域。因此,当熵率H(L)/L<Hc时,此时的数据集是由呈周期性(包括在混沌区域也呈周期性的参数)变化的参数下产生,大于Hc时数据集由混沌的参数下产生。本图可以对照统计复杂度小节中的图(b)一起理解。
上图(b)为逻辑斯谛映射中在Hc(r=3.5699...)处,L与宏观态数量|V|的关系,序列的长度L=64时,|V|=196,从图中可以看出,随着L的增长,|V|的值是发散的,若要用有限的L来描述|V|,就需要将模型进行重构,升级为描述能力更强的模型。
4.3 模型升级
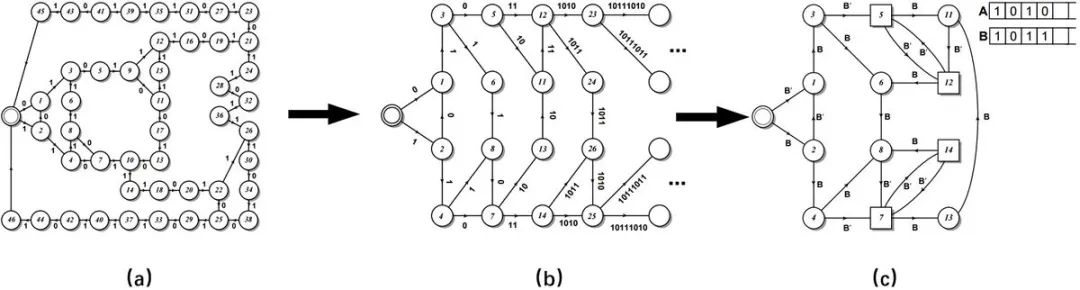
下面三张图[13]展示了模型重构升级进化的一种路径。(a),(b),(c)三张图分别对应了由低到高不同阶次的重构机器的状态转移图。图中的圆圈代表状态,连边代表状态之间的转移,连边上的数字代表一次伯努利过程采样的0或1。
上图(a)为逻辑斯谛映射在Hc(r=3.5699...)处,序列长度L=16时用斑图重构机器重构后的47个状态的状态转移图。图中每条闭合的链路长度都是16步,例如初始圆圈-1-3-5-9-12-16-19-21-23-27-31-35-39-41-43-45这条路径,它的总步数为16,每两步之间的数字是通过伯努利过程采样的二元分割的结果,每个分支代表它经历了一次伯努利随机过程。但是图(a)捕捉到的规律并不明显,我们将它进行一个简单的转换,用每两步之间的数字组成的序列替换机器中未分支的路径后就得到图(b),图(b)中的分支状态相当有规律。更进一步将图(b)升级为用字符生成器来描述增长的规律性就得到了图(c)。该图的有限自动机有两种状态(原有类型用圆圈表示,新类型用方块表示)和两个寄存器 A 和 B,A 和 B用于保存二进制字符串,初始状态 A 中保存的是0,B中保存的是1,B’表示对保存在B中的字符串的最后一位取反。
图(b)中的字符串操作可以通过将 A 的内容副本附加到 B 上,并用 B 的内容的两个副本替换 A 的内容来描述。这些字符串在方块处迭代,迭代式表示为A→BB 和B→BA。例如图(c)中从起始点-2-4-7-13这条链路,起始字符是1,可以用B描述,在4-7处发生变化,用B’描述,在7处产生了新的类型,B中字符变为10,在这里B’就是11,依此类推,就得到了图(c)。显然(c)的描述方式比(a)的方式更加节省计算资源,它的描述能力也更强。
5.1 计算力学与因果涌现
5.1.1 概念对比
计算力学的许多概念上都可以在因果涌现理论框架下找到对应,通过进行两者之间的对应和比较,我们可以拓展对涌现的理解和研究。

计算力学中的斑图重构机器(ϵ-machine)和识别因果涌现的NIS和NIS+都可以理解为是智能体观察外部世界的内部模型。斑图重构机器通过重构算法得到理想的划分和因果态的过程,与NIS或NIS+通过最大化宏观动力学的有效信息(Effective information,EI)得到最佳粗粒化策略与涌现的宏观动力学的过程是类似的。可以说,NIS或NIS+就是一个通过神经网络、机器学习技术实现的斑图重构机器(ϵ-machine)。
二者的等价可以体现在两方面:一方面我们希望重构的模型应该足够简洁(因果态具有最小随机性,NIS+中最大化宏观的EI);另一方面则希望宏观模型仍保留微观态变化的重要信息,有能力预测未来的微观态。
计算力学中,因果态的定义保证了它对微观态具有最大预测性,而香农熵率便可以衡量该预测误差的大小。在NIS或NIS+中,有效信息的最大化保证了模型的简洁性,而微观态预测误差的约束则体现了模型准确性的要求。
另外,我们在前文讨论了统计复杂度关于熵率的变化曲线,该图说明,涌现发生在随机性程度中等的情形下。而在NIS+的框架中,我们用机器的重构预测误差来约束模型,要求其在保证对微观预测尽可能准确(误差低于一定阈值)的前提下,最大化宏观的EI。此时,我们也可以计算宏微观的EI以及它们的差值来判断是否发生因果涌现。如下图所示,最高强度的因果涌现也发生在观测噪音处于中等强度时。
上图中,左图是前文中出现过的示意图。它描述了统计复杂度与数据随机性之间的关系,其中随机性通过香农熵率来度量(见前文中的实验部分)。当随机性处于中等强度时,统计复杂度出现峰值。右图来自NIS+应用在SIR(病毒感染动力学)为模型的生成数据上的实验。其中横轴为该数据中观测噪音的强度,纵轴为因果涌现强度ΔJ。总共5次重复实验,实线表示5次实验的均值,填充条带的宽度为5次实验结果的标准差大小。详情可参考词条NIS+。
右图中,ΔJ在σ=10−2和σ=10−1之间达到峰值,这与作者模拟中使用的时间步长(dt=0.01)的大小相对应,是噪音与信号比例大致相同的情形。对比左右两张图,NIS+所识别的因果涌现强度与统计复杂度有着相似的变化趋势和性质。
5.2 计算力学与马尔科夫链的成块性理论
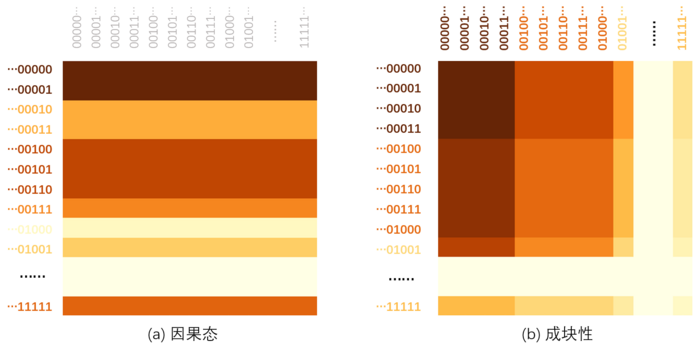
马尔科夫链是计算力学的一类特殊情形,即当未来状态仅依赖于上一步历史的情形。在马尔科夫链中,人们很早就开始讨论马尔科夫链的成块性(lumpability),所谓的成块性是一种描述马尔科夫链的状态是否可聚类并约简的性质。判断一个马尔科夫链上的划分是否是成块的(lumpable),是看它的马尔科夫状态转移矩阵P中的元素经过划分能不能结成一个个小方块(也就是按照聚类对马尔科夫链进行粗粒化表示)。具体来说,对于成块的马尔科夫链来说,我们可以把N个微观状态划分成M<N个宏观状态,在这个划分过程中,我们能定义微观状态s1到宏观状态A1的转移概率就等于s1到A1中的各个微观状态的转移概率的加和。我们会发现,在成块的马尔科夫链中,宏观状态中的每一个微观状态转移到另一个宏观状态的转移概率都是一样的。这样会使得马尔科夫状态转移概率矩阵P这个方阵中,出现一个个方块,所以称之为成块性。
判断一个马尔科夫链对给定划分 A 是否成块的充分必要条件为:对于∀i,j为两个分组的下标, 那么对于任意两个分组Ai中的微观态: ,都必须满足:
,都必须满足:
另一方面,在讨论因果态的时候,我们也有类似的条件。对于某个划分得到的宏观态集合 ,其为因果态的充要条件是:对于任意的宏观态
,其为因果态的充要条件是:对于任意的宏观态 ,对于任意的
,对于任意的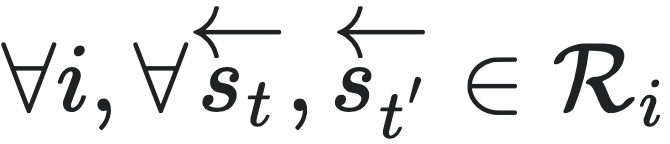 ,有:
,有:
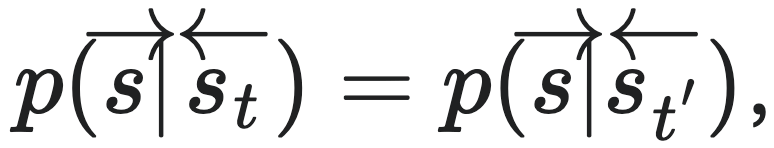
其中 。
如果将马尔科夫链的状态分组就看作是因果态理论中的粗粒化划分,那么成块性的要求和因果态的要求非常相似,它们都给出了一种对未来状态做预测的等价性。但是,二者又有区别,区别有以下三点:
因果态并没有马尔科夫性的假设,但我们总可以把一个序列看成是一个状态,于是就能得到序列映射到序列的马尔科夫转移矩阵。在该概率转移矩阵上,我们可以比较因果态对应的划分映射和满足成块性的划分。
上文提到,因果态的状态划分方式能保持微观层面上的最大预测性。也就是说,我们根据微观状态找到对应的因果态之后,即使我们不知道原本的微观状态了,我们还是能准确的得到未来的微观状态的分布。
而成块性与其不同的是,我们根据微观状态找到对应的宏观状态之后,能够准确的得到未来的宏观状态的分布。但是在粗粒化过程中,我们会丢失微观状态的辨别信息,而这个信息的损失是不可逆的。所以,我们就无法从宏观状态再还原到微观状态了。
所以,因果态同时保持了微观和宏观的最大预测性,而成块性只能保持宏观的最大预测性。
3. 因果态比成块性更严格,划分的成块性是满足因果态要求的必要条件
按照上面的叙述,我们会发现,因果态是比成块性更严格的限制,因为它要求在状态转移矩阵中,属于同一个因果态中的状态的行必须完全一致。
因果态的划分一定是一种成块的状态划分,但反之则不一定。所以说,划分的成块性是满足因果态要求的必要不充分条件。
该图展示了我们是怎么处理和理解因果态和成块性的。首先,我们把每条序列看作是一个状态,把序列压缩到了一个t时刻的状态空间,并用一个转移矩阵来描述状态(序列)之间的转移概率。
在因果态中,我们只需要对比转移矩阵的行,把相同的行划分成一组;而在成块性中,我们需要同时考虑矩阵的行与列,通过比较每一行到某几列的转移概率来做分组。
。
如果将马尔科夫链的状态分组就看作是因果态理论中的粗粒化划分,那么成块性的要求和因果态的要求非常相似,它们都给出了一种对未来状态做预测的等价性。但是,二者又有区别,区别有以下三点:
因果态并没有马尔科夫性的假设,但我们总可以把一个序列看成是一个状态,于是就能得到序列映射到序列的马尔科夫转移矩阵。在该概率转移矩阵上,我们可以比较因果态对应的划分映射和满足成块性的划分。
上文提到,因果态的状态划分方式能保持微观层面上的最大预测性。也就是说,我们根据微观状态找到对应的因果态之后,即使我们不知道原本的微观状态了,我们还是能准确的得到未来的微观状态的分布。
而成块性与其不同的是,我们根据微观状态找到对应的宏观状态之后,能够准确的得到未来的宏观状态的分布。但是在粗粒化过程中,我们会丢失微观状态的辨别信息,而这个信息的损失是不可逆的。所以,我们就无法从宏观状态再还原到微观状态了。
所以,因果态同时保持了微观和宏观的最大预测性,而成块性只能保持宏观的最大预测性。
3. 因果态比成块性更严格,划分的成块性是满足因果态要求的必要条件
按照上面的叙述,我们会发现,因果态是比成块性更严格的限制,因为它要求在状态转移矩阵中,属于同一个因果态中的状态的行必须完全一致。
因果态的划分一定是一种成块的状态划分,但反之则不一定。所以说,划分的成块性是满足因果态要求的必要不充分条件。
该图展示了我们是怎么处理和理解因果态和成块性的。首先,我们把每条序列看作是一个状态,把序列压缩到了一个t时刻的状态空间,并用一个转移矩阵来描述状态(序列)之间的转移概率。
在因果态中,我们只需要对比转移矩阵的行,把相同的行划分成一组;而在成块性中,我们需要同时考虑矩阵的行与列,通过比较每一行到某几列的转移概率来做分组。
5.3 斑图重构机器与世界模型
计算力学中的斑图重构机器关心智能体是如何从观测到的时间序列数据中自动地发现因果态,并构建内在的环境模型的,这一点与强化学习领域中的世界模型(也被称为以及模型的强化学习)的想法不谋而合。
强化学习所解决的问题通常可以建模为马尔可夫决策过程(Markov Decision Process,缩写MDP),形式上可表示为(S,A,T,R,γ),其中集合S为状态空间包含所有可能的状态,每个状态s∈S描述了系统在某一时刻的情形。集合A为动作空间,包含所有的动作。T为状态转移概率,T(s′|s,a)表示在状态s下执行动作a转移到s′的概率。奖励函数R(s,a)定义了在状态s采取动作a后获得的即时奖励,折现因子γ是一个在 [0, 1] 之间的数,用于折扣未来奖励的影响。当智能体的观测o等于系统状态s时,对应一般的马尔可夫决策过程,当智能体无法直接观测到系统完整的状态时,问题可以描述为部分可观测马尔可夫决策过程(Partially Observable Markov Decision Process,缩写POMDP),POMDP可以描述为一个7元组(S,A,T,R,Ω,O,γ),Ω表示观测空间,智能体的观测o∈Ω,概率为O(o|s′,a)。
在强化学习世界模型中,智能体根据和真实环境互动过程所产生的数据训练一个内嵌的世界模型,世界模型作为对真实环境的替代,从而可以通过和世界模型互动学习行动策略,减少和真实环境的互动。对于观测不包含完整的状态信息的POMDP问题,以及观测维度过高导致难以准确建模的MDP问题,人们通常让Agent去学习一个状态的粗粒化表征,这种方式可以帮助算法提升学习效率和任务表现。这种粗粒化表征就是所谓的“世界模型”。
因此,强化学习的世界模型往往需要学习一个低维的隐状态动力学。隐状态的世界模型可以表示为T(z′|z,a),其中z表示粗粒化之后的隐状态(或者宏观状态),这一点和计算力学中的因果态,以及因果态的转移概率具有一定的相似之处。
1. 强化学习世界模型中的状态转移包含动作,而在斑图重构机器中建模因果态的转移,不涉及智能体动作的建模。
2. 在世界模型的学习中,宏观状态粗粒化的另一个需要考虑的点是状态转移和粗粒化的可交换性,也就是从s粗粒化的表示z经过宏观动力学(世界模型)转移到下一时刻的宏观状态分布P1(z′),应该尽可能接近从s经过微观动力学(未做表征学习)转移到s′,然后再构建表征z′,从而得到的宏观状态分布P2(z′),也就是P1(z)≈P2(z′)。而斑图重构机器中状态的粗粒化不涉及这一问题的讨论。
作者简介:

本词条由集智俱乐部众包生产,难免存在纰漏和问题,欢迎大家留言反馈或者前往对应的百科词条页面进行修改,一经修改,可以获得对应的积分奖励噢!
我们正在寻找对知识分享充满热情的志愿者,加入我们的集智百科词条编写团队!无论你是某个领域的专家,还是对某一主题有浓厚兴趣,我们都欢迎你的加入。通过编写和编辑百科词条,你将有机会为全球读者提供准确、权威的信息,同时提升自己的写作和研究能力。
我们需要的帮助
编写新的集智百科词条,涵盖复杂系统、人工智能等多个领域
更新和完善现有词条,确保信息的准确性和时效性
我们希望你具备
良好的写作能力,能够清晰、简洁地表达复杂的概念
对某一领域有深入了解或浓厚兴趣
具备基本的网络搜索和信息整理能力
有责任心和团队合作精神,愿意为知识共享贡献力量
如果你对知识分享充满热情,愿意为全球读者提供有价值的信息,请立即加入我们!

-
Packard, N. H.; Crutchfield, J. P.; Farmer, J. D.; Shaw, R. S. (1980). “Geometry from a time series”. Physical Review Letters. 45 (9): 712.
-
Takens, D. A. (1981). Detecting strange attractors in fluid turbulence. 898. Berlin: Springer-Verlag. pp. 366.
-
Brandstater, A.; Swift, J.; Swinney, Harry L.; Wolf, A.; Farmer, J. D.; Jen, E.; Crutchfield, J. P. (1983). “Low – dimensional chaos in a hydrodynamic system”. Physical Review Letters. 51 (16): 1442.
-
Crutchfield, James P.; Young, Karl (1989). “Inferring Statistical Complexity”. Physical Review Letters. 63 (2): 105–108.
-
Minsky, M. (1967). Computation: Finite and Infinite Machines. Englewood Cliffs, New Jersey: Prentice – Hall.
-
Chomsky, N. (1956). “Three models for the description of language”. IRE Transactions on Information Theory. 2: 113–124.
-
Hopcroft, J. E.; Ullman, J. D. (1979). Introduction to Automata Theory, Languages, and Computation. Reading: Addison – Wesley.
-
Holldobler, B.; Wilson, E. O. (1990). The Ants. Cambridge, Massachusetts: Belknap Press of Harvard University Press.
-
Reynolds, C. W. (1987). “Flocks, herds, and schools: A distributed behavioral model”. Computer Graphics. 21: 25–34.
-
Fama, E. F. (1991). “Efficient capital markets II”. Journal of Finance. 46: 1575–1617.
-
Barnett, L.; Seth, A.K. (2023). “Dynamical independence: discovering emergent macroscopic processes in complex dynamical systems”. Physical Review E. 108 (1): 014304.
-
Seth, A. K. (2008). “Measuring emergence via nonlinear granger”. Artificial Life XI: Proceedings of the Eleventh International Conference on the Synthesis and Simulation of Living Systems. 2008: 545–552.
-
Crutchfield, James P. (1994). “The Calculi of Emergence: Computation, Dynamics, and Induction”. Physica D: Nonlinear Phenomena. 75: 11–54.
-
Shalizi, C. R.; Crutchfield, J. P. (2001). “Computational Mechanics: Pattern and Prediction, Structure and Simplicity”. Journal of Statistical Physics. 104 (3/4): 817–879.
-
Rupe, Adam; Crutchfield, James P. (2024). “On principles of emergent organization”. Physics Reports. 1071: 1–47.
-
Bennett, C. H. (1988). Pines, D. (ed.). “Dissipation, information, computational complexity, and the definition of organization”. Emerging Syntheses in the Sciences. Redwood City: Addison-Wesley.
在霓虹灯的闪烁、蚁群的精密协作、人类意识的诞生中,隐藏着微观与宏观之间深刻的因果关联——这些看似简单的个体行为,如何跨越尺度,涌现出令人惊叹的复杂现象?因果涌现理论为我们揭示了答案:复杂系统的宏观特征无法通过微观元素的简单叠加解释,而是源于多尺度动态交互中涌现的因果结构。从奇异值分解(SVD)驱动的动态可逆性分析,到因果抽象与信息分解的量化工具,研究者们正逐步构建起一套跨越数学、物理与信息科学的理论框架,试图解码复杂系统的“涌现密码”。
为了系统梳理因果涌现最新进展,北京师范大学系统科学学院教授、集智俱乐部创始人张江老师领衔发起「因果涌现第六季」读书会,组织对本话题感兴趣的朋友,深入研读相关文献,激发科研灵感。
读书会将从2025年3月16日开始,每周日早9:00-11:00,持续时间预计10周左右。每周进行线上会议,与主讲人等社区成员当面交流,之后可以获得视频回放持续学习。诚挚邀请领域内研究者、寻求跨领域融合的研究者加入,共同探讨。
推荐阅读
6. 加入集智,一起复杂!
点击“阅读原文”,报名读书会