《AI×SCIENCE十大前沿观察》1:基于LLM的科学研究

导语
上海科学智能研究院、集智科学研究中心和阿里云联合发布了《AI X Science十大前沿观察》,梳理出35个研究前沿,来推动科学发展的黄金时代到来。本篇为前沿观察1,扫描下方二维码可获得完整版下载地址、快速链接论文原文。

基于LLM的科学研究
基于LLM的科学研究
背景介绍
近年来,大语言模型 (Large Language Models, LLMs) 正在深刻影响科学研究的方式。正如Nature Reviews Physics的评论文章[1]指出,LLM在科研中扮演的是“增强型助手”而非“替代者”的角色,这种增强作用体现在对科研活动不同维度的重构中。
从本质上看,LLM之所以能带来深远影响,在于它提供了一个统一的符号系统来重构科研活动的不同维度。具体而言,这种重构体现在三个深层次的维度上:
第一个层次是知识重构维度。传统的科学知识是分散在各个专业领域的,不同学科之间存在着“知识鸿沟”和“语言障碍”。LLM通过提供统一的知识表达框架,正在打破这些壁垒。例如,Galactica[2]通过整合海量科学文献,重新定义了科学知识的组织方式;BioGPT[3]在生物医学知识表示和生成方面取得突破。这些工作为科学发现提供了新的认知基础,使得研究者能够更容易地发现跨领域的关联和洞见。
第二个层次是过程抽象维度。科研过程传统上高度依赖研究者的专业经验和直觉判断,这种经验难以形式化和传承。LLM通过将科研流程抽象为可计算的任务序列,实现了科研活动的形式化和自动化。在化学领域,ChemCrow[4]展示了复杂实验流程的自动化执行,在生物领域,BioMedLM[5]展示了在生物医学任务中的多任务学习能力。这些工作不仅提高了研究效率,更重要的是为科研方法的系统化和标准化提供了新的范式。
第三个层次是界面创新维度,体现为用自然语言重构人机物理系统的交互方式。传统上,科研人员需要掌握复杂的专业操作界面来使用科研设备,这种非自然的交互方式不仅限制了研究效率,也阻碍了创新思维的发挥。VISION[7]通过模块化架构实现了科研设备的自然语言控制,Med-PaLM[8]在医学图像分析中实现了直观的人机对话,这些创新不仅降低了使用专业设备的门槛,更重要的是实现了人与设备之间的认知层面协同。
这三个维度的变革是递进和互补的:知识重构提供了认知基础,过程抽象实现了方法创新,界面创新则打通了实践环节。这种多维度的系统性变革也带来了深层的挑战:
1. 知识表达:如何在知识重构中保持专业深度并确保表达的完备性?
2. 流程保障:如何在过程抽象中平衡自动化与创新空间?
3. 交互设计:如何构建更符合科研认知特点的自然交互界面?
4. 系统集成:如何实现知识、流程、界面三个维度的协同创新?
理解和应对这些挑战,将决定LLM能在多大程度上推动科学研究的进步。本报告将重点分析几个代表性工作,展示当前在应对这些挑战方面的最新进展,并探讨LLM驱动的科研新范式的未来发展方向。
研究进展
进展目录
跨学科知识的整合和创新
基于LLM的科研流程重构
革新人机协同科研模式
跨学科知识的整合与创新
Galactica的产品页面 | 来源:Galactica的官网(现已下线)
推荐理由:Galactica[2]是首个专门面向科学文献训练的大规模语言模型,通过整合4800万篇科研论文、教材和知识库的内容,加上独特的训练策略和模型设计,展现了LLM在科学知识综合理解与应用方面的强大潜力。
跨学科知识的整合与创新已成为推动科学进步的关键动力,然而,面对指数级增长的科研文献,研究人员往往难以全面把握不同领域的知识脉络。能否构建一个“科学知识的通用理解者”,打破学科壁垒,实现跨领域知识的有机融合?
Galactica是一个非常重要的尝试。通过创新的数据处理和训练策略,Galactica开创了专业领域大模型的新范式。它的核心突破在于提出了“高质量数据+多轮迭代”的训练方法,通过对精选的4800万篇科研文献进行4.25轮深度训练,验证了这一方法优于传统的“大规模数据+单轮训练”范式。同时,它设计了独特的Tokenization策略统一处理科研领域的多模态数据(如数学公式、化学结构、蛋白质序列),并创新性地引入Reference Token和Work Token分别用于构建知识图谱和支持多步推理。这些设计让Galactica在多个科学任务上取得了突破性进展:LaTeX公式理解准确率达68.2%(超GPT-3近20个百分点),数学推理准确率达41.3%(超Chinchilla 5.6个百分点),医学问答准确率创下77.6%的新纪录。
Galactica了实现科学知识的系统性整合。同时,由于有大量研究指出这项技术容易产生偏见和将谎言断言为事实的倾向等缺陷,即文本生成中的幻觉(Hallucination),经过三天的激烈批评后即被迅速下线。
尽管如此,Galactica通过将领域知识系统性注入预训练过程,为构建专业领域大模型提供了重要范式,其影响已超越科学领域,为其他垂直领域大模型的发展提供了有益借鉴。其中,来自上海交通大学的团队将这一颇具潜力的模型引入到了地球科学领域,完成了300亿参数的地学⼤语⾔模型GeoGalactica的训练[9]。
基于LLM的科研流程重构
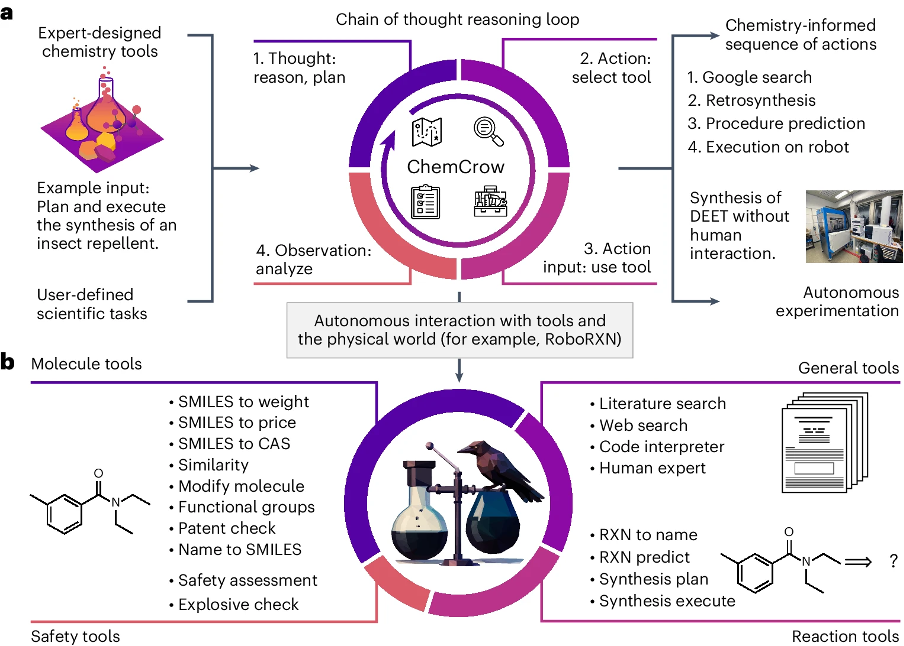
ChemCrow任务解决过程概述 | 来源:M. Bran, A., Cox, S., Schilter, O. et al. Augmenting large language models with chemistry tools. Nat Mach Intell 6, 525–535 (2024). https://doi.org/10.1038/s42256-024-00832-8
推荐理由:科学研究的过程抽象是一个根本性挑战,它涉及如何将复杂的研究活动分解为可计算、可执行的任务序列。ChemCrow[4]通过创新性地将LLM与专业工具相结合,为这一挑战提供了一个可行的解决方案。 科学研究过程的形式化和自动化一直是一个重要而困难的课题。传统上,科研活动高度依赖研究者的经验和直觉,这种依赖不仅限制了研究效率,也使得许多宝贵的研究经验难以传承和推广。如何将专家的经验和判断转化为明确的操作流程,如何确保复杂实验过程的可重复性,如何在保持灵活性的同时实现高度自动化,这些问题长期困扰着各个科学领域。
ChemCrow为解决这些普遍性问题提供了一个创新的范式。其核心思想是构建一个“思考-行动-观察”的闭环系统,通过LLM作为协调者,将各类专业工具有机整合。具体而言,该系统包含三个关键创新:首先,它建立了一个基于自然语言的任务规划框架,能将复杂的研究目标分解为具体的操作步骤;其次,它设计了一套工具调用机制,使LLM能根据需求精确调用相应的专业工具;最后,它实现了一个动态反馈系统,能根据执行结果实时调整策略。
ChemCrow的成功意义远超化学领域。首先,它证明了将复杂的科研过程形式化是可行的,这为其他领域的过程自动化提供了重要参考。其次,它展示了如何在保持系统灵活性的同时确保研究的可靠性和可重复性。最重要的是,它提供了一个可推广的框架,这个框架可以根据不同学科的特点进行调整和扩展。它代表了科研活动从“经验驱动”向“系统驱动”的重要转变,预示着一个更加自动化、规范化的科研新时代的到来。
革新人机协同科研模式
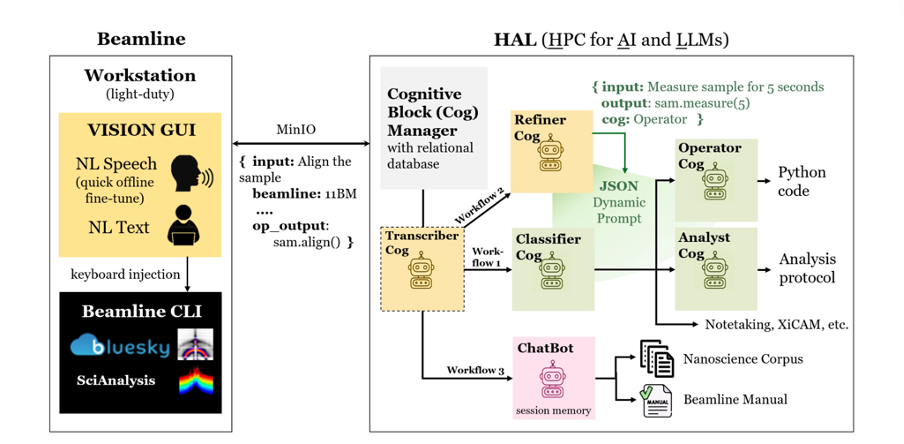
VISION的系统架构概览 | 来源:Mathur, S., van der Vleuten, N., Yager, K. G., & Tsai, E. (2023). VISION: A modular AI assistant for natural human-instrument interaction at scientific user facilities. arXiv preprint arXiv:2412.18161.
推荐理由:VISION[7]开创性地将模块化AI架构引入科学实验,通过将不同的认知模块有机整合,实现了首个全面的自然语言实验控制系统。它为人机协同科研提供了新的交互范式。
科学实验设备的操作一直是一个专业性很强的领域,传统上需要研究人员掌握复杂的专业操作界面和命令。这不仅给研究人员带来很大的学习负担,也成为科研自动化的重要障碍。如何让科学家能够用自然语言与科研设备直接“对话”,让设备理解并执行研究人员的意图,这=是一个具有重要意义又充满挑战的课题。
VISION的突破性在于它提出了一种创新的模块化AI架构。系统由多个功能模块(Cognitive Blocks)组成,每个模块都基于一个针对特定任务优化的大语言模型。这些模块协同工作,共同完成从语音识别、意图理解到任务规划和代码生成的全流程。
具体来说,系统包含转录器(Transcriber)、分类器(Classifier)、操作员(Operator)和分析师(Analyst)等关键模块。这些模块以工作流(Workflow)的形式进行组织和调度。当用户发出一个请求时,系统首先判断其属于数据采集、分析还是其他类型,然后调用相应的工作流处理。最后,系统将生成的代码或分析结果返回给用户确认,并在获得许可后提交给底层的实验控制平台执行。整个过程中,用户通过自然语言与系统交互,无需了解复杂的技术细节。
VISION的意义在于它开创了一种全新的人机交互范式。通过模块化的架构设计,它充分利用了大语言模型在不同任务上的特长,实现了全面的语言理解和任务执行能力。同时,它将前沿的AI技术与传统的科研工作流程巧妙结合,极大地提高了实验效率和灵活性。更重要的是,它为实现“用语言做实验”这一科研人员的长期愿景迈出了关键一步。
挑战与展望
挑战与展望
然而,基于LLM的科学研究也面临着几个根本性的挑战:幻觉问题,LLM可能生成表面上合理但实际上不准确的内容,这在科学研究中尤其危险;创新的认知边界问题,LLM的“创新”源自已有知识的重组和推理,这与真正的科学突破性发现可能存在本质差异;可重复性与可解释性的矛盾,科学研究要求结果可重复、过程可追溯,但LLM的黑盒特性与此形成本质冲突。
面向未来,大语言模型驱动的科研创新亟需在以下方向实现突破:
1.构建可信科研平台:整合跨模态知识,建立链上可追溯、过程可审计、结果可复现的科研基础设施。
2.探索人机协同创新范式:发掘研究人员专业经验与LLM知识处理能力的最佳协同路径,实现辅助决策到联合创新的跃升。
3.推进跨学科协同治理:计算机、伦理学、科学哲学、科研管理等领域,需协同推进LLM在科研领域的责任评估、伦理审查、规范制定等工作。
科学研究正在经历一场方法论的革新。基于LLM的科学研究不仅提供了新的研究工具,更重要的是开创了一种新的认知范式。这种范式将人类的创造力与AI的能力有机结合,有望加速科学发现的进程。随着技术的进步和应用的深入,这种新范式可能会重塑科学研究的方式,开启科学探索的新纪元。
参考文献
[1] Birhane, A., et al. “Science in the age of large language models.” Nature Reviews Physics 5 (2023): 277-280.https://doi.org/10.1038/s42254-023-00581-4
|
推荐理由: 这是一篇重要的评论性文章,由四位AI伦理和政策专家撰写,全面讨论了LLM在科学研究中的潜力和风险。文章不仅提供了清晰的概念框架,还引发了关于LLM在科研中应用的深入讨论。 |
[2] Taylor, R., et al. “Galactica: A Large Language Model for Science.” arXiv preprint arXiv:2211.09085 (2022).https://arxiv.org/abs/2211.09085
|
推荐理由: 这是首个专门面向科学文献训练的大规模语言模型的技术报告,详细描述了模型架构、训练策略和评估结果。虽然模型最终下线,但其技术创新和失败教训都具有重要的参考价值。 |
[3] Luo, R., et al. “BioGPT: Generative Pre-trained Transformer for Biomedical Text Generation and Mining.” Briefings in Bioinformatics 23.6 (2022): bbac409.https://doi.org/10.1093/bib/bbac409
|
推荐理由: 这篇论文介绍了专门针对生物医学领域的预训练语言模型,展示了领域特定LLM的潜力,为其他垂直领域的模型开发提供了重要参考。 |
[4] Bran, A.M., et al. “Augmenting large language models with chemistry tools.” Nature Machine Intelligence 6 (2024): 525-535.https://doi.org/10.1038/s42256-024-00832-8
|
推荐理由: 这篇发表在Nature Machine Intelligence的论文展示了如何将LLM与专业工具结合,实现科研流程的自动化。文章提供了详细的系统设计和实验验证,具有很强的实践指导意义。 |
[5] Bolton, E., et al. “BioMedLM: A 2.7B Parameter Language Model Trained on Biomedical Text.” arXiv preprint arXiv:2403.18421 (2024).https://arxiv.org/abs/2403.18421
|
推荐理由: 这是一个针对生物医学领域的开源语言模型,论文详细描述了模型训练过程和多任务学习能力,为生物医学领域的AI应用提供了重要工具。 |
[6] Mathur, S., et al. “VISION: A Modular AI Assistant for Natural Human-Instrument Interaction at Scientific User Facilities.” arXiv preprint arXiv:2412.18161 (2023).https://arxiv.org/abs/2412.18161
|
推荐理由: 这篇预印本详细描述了一个创新的模块化AI系统,展示了如何通过自然语言实现科研设备控制,为提高实验效率提供了新思路。 |
[7] Singhal, K., et al. “Large Language Models Encode Clinical Knowledge.” Nature 620.7972 (2023): 172-180.https://doi.org/10.1038/s41586-023-06291-2
|
推荐理由: 这篇Nature论文展示了LLM在医学领域的应用潜力,特别是在医学知识理解和图像分析方面的突破,为医学AI的发展提供了重要参考。 |
[8] Lin, Z., et al. “GeoGalactica: A Scientific Large Language Model in Geoscience.” arXiv preprint arXiv:2401.00434 (2024).https://arxiv.org/abs/2401.00434
|
推荐理由: 这篇论文介绍了如何将Galactica的架构应用到地球科学领域,展示了专业领域大模型的发展潜力,为其他学科的模型开发提供了借鉴。 |
出品:漆远、吴力波、张江
运营:孟晋宇、王婷
撰稿:张江、杨燕青、王婷、王朝会、十三维、周莉、梁金、袁冰、江千月、刘志毅
鸣谢(按姓氏拼音顺序,排名不分先后):
曹风雷 、陈小杨 、程远、杜沅岂 、段郁、方榯楷 、付彦伟、 高悦、黄柯鑫、李昊、刘圣超、谭伟敏、吴泰霖、吴艳玲、向红军、张骥、张艳、朱思语
AI+Science 读书会
6. 加入集智,玩转复杂,共创斑图!集智俱乐部线下志愿者招募
微信扫一扫,分享到朋友圈











