-
链路预测的博弈算法;
-
大型灾害子事件无监督检测;
-
基于跨位置注意的图形信息传递在长期ILI预测中的应用;
-
-
-
-
-
-
-
C-V2X模式4的分散子信道调度:一种用于CAM重传的非标准配置;
-
-
-
具有链式维度的领域主题模型:主要肿瘤学会议的演化建模(1995年至2017年);
-
-
-
-
-
-
蒙特卡罗技术用于逼近迈耶森价值——理论与实证分析;
-
-
Inf-VAE:一种融合同质性和影响的变分自编码框架;
-
-
-
-
A Game-Theoretic Algorithm for Link Prediction
http://arxiv.org/abs/1912.12846
Mateusz Tarkowski, Tomasz Michalak, Michael Wooldridge
摘要:网络边缘预测是社会网络分析中的一个关键问题,它涉及到基于网络结构特性的节点间关系推理。特别是,链接预测可用于分析网络将如何发展,或者(给定有关关系的不完整信息)来发现“丢失”的链接。我们对这个问题的研究源于合作博弈理论,在这个理论中,我们提出了一种新的,结合广义群贴近度中心性和半值相互作用指数的拟局部方法(即考虑半径k内节点的方法)。我们开发了快速算法来计算我们的度量,并在许多现实网络上对其进行评估,在这些网络中,它的性能优于从文献中选择的其他最先进的方法。重要的是,为拟局部方法选择最佳半径k是困难的,并且不能保证选择是最优的。此外,与其他拟局部方法相比,即使以次优半径k作为参数,我们的方法也取得了很好的效果。
Unsupervised Detection of Sub-events in Large Scale Disasters
http://arxiv.org/abs/1912.13332
Chidubem Arachie, Manas Gaur, Sam Anzaroot, William Groves, Ke Zhang, Alejandro Jaimes
摘要:社交媒体在重大自然灾害(如飓风、大规模火灾等)期间和之后发挥着重要作用,因为人们“在现场”发布关于实际发生情况的有用信息。鉴于大量的职位,一个主要的挑战是确定有用和可操作的信息。应急响应人员主要关心的是找出正在发生的事件,以便他们能够正确规划和部署资源。在本文中,我们讨论了自动识别重要的子事件(在一个大规模的紧急事件中,例如飓风)的问题。特别是,我们提出了一个新的、无监督的学习框架来检测Tweets中的子事件,以便进行回顾性危机分析。我们首先从原始tweets中提取名词-动词对和短语作为子事件候选。然后,我们学习抽取的名词-动词对和短语的语义嵌入,并根据特定于危机的本体对它们进行排序。我们过滤掉噪音和不相关的信息,然后对名词-动词对和短语进行聚类,以便排名靠前的词描述最重要的子事件。通过对两个大型危机数据集(Harvey飓风和2015年尼泊尔地震)的定量实验,我们证明了我们的方法相对于最先进的方法的有效性。与基线相比,我们的定性评估显示出更好的性能。
基于跨位置注意的图形信息
传递在长期ILI预测中的应用
Graph Message Passing with Cross-location Attentions for Long-term ILI Prediction
http://arxiv.org/abs/1912.10202
Songgaojun Deng, Shusen Wang, Huzefa Rangwala, Lijing Wang, Yue Ning
摘要:预测流感样病例(ILI)对流行病学家和卫生保健提供者至关重要。疫情的早期预测对疾病的干预和控制起着至关重要的作用。大多数现有的工作要么限制了长期预测性能,要么缺乏全面的能力来捕获数据中的时空相关性。准确和早期的疾病预测模型将显著提高流行病预防和控制流行病的发生。本文设计了一种基于交叉位置注意的图形神经网络(Cola-GNN),用于学习时间序列嵌入和位置注意。我们提出了一个图消息传递框架,将学习到的特征嵌入和注意力矩阵结合起来,以模拟疾病随时间的传播。我们将所提出的方法与最新的统计方法以及对来自美国和日本的真实流行病相关数据集的深度学习模型进行了比较。该方法具有很强的预测性能,可用于长期流行病预测。
Weak Supervision for Fake News Detection via Reinforcement Learning
http://arxiv.org/abs/1912.12520
Yaqing Wang, Weifeng Yang, Fenglong Ma, Jin Xu, Bin Zhong, Qiang Deng, Jing Gao
摘要:如今,社交媒体已成为新闻的主要来源。通过社交媒体平台,假新闻以前所未有的速度传播,影响全球受众,并使用户和社区面临巨大风险。因此,尽早发现虚假新闻就显得尤为重要。近年来,基于深度学习的方法在虚假新闻检测中表现出了良好的性能。然而,此类模型的训练需要大量的标注数据,而手工标注又费时费力。此外,由于新闻的动态性,加注释的样本可能很快就会过时,不能代表新出现事件的新闻文章。因此,如何获得新鲜、高质量的标签样本是利用深度学习模型进行虚假新闻检测的主要挑战。为了应对这一挑战,我们提出了一种强化的弱监督的虚假新闻检测框架WeFEND,它可以利用用户的报告作为弱监督来扩大虚假新闻检测的训练数据量。该框架由三个主要部分组成:注释器、增强选择器和假新闻检测器。批注器可以根据用户的报告自动为未标记的新闻分配弱标签。使用强化学习技术的强化选择器从弱标记数据中选择高质量的样本,并过滤掉那些可能降低检测器预测性能的低质量样本。假新闻检测器的目的是根据新闻内容识别假新闻。我们在通过微信公众号发布的大量新闻文章和相关用户报告上测试了该框架。在该数据集上的大量实验表明,与现有方法相比,本文提出的WeFEND模型具有最佳的性能。
The dynamics of opinion expression
http://arxiv.org/abs/1912.12631
Felix Gaisbauer, Eckehard Olbrich, Sven Banisch
摘要:本文引入了一种舆论表达模式。两组对某一问题有不同意见的主体相互作用,根据他们是否认为自己是多数意见或少数意见的一部分而改变表达意见的意愿。我们将此模型描述为多组多数博弈,并研究纳什均衡。我们还提供了一个动态系统的观点:利用Q-学习的强化学习算法,我们将N-智能系统的平均场方法降到代表两个意见群的二维。对这一二维系统的参数进行了全面的分岔分析。该模型确定了不同群体舆论优势的结构条件。我们还展示了在何种情况下少数人可以主导公共话语。这与社会科学的核心观点表达理论“沉默的螺旋”有着直接的联系。
A Gentle Introduction to Deep Learning for Graphs
http://arxiv.org/abs/1912.12693
Davide Bacciu, Federico Errica, Alessio Micheli, Marco Podda
摘要:图形数据的自适应处理是一个由来已久的研究课题,最近被整合为深度学习领域的一个重要课题。相关研究数量和广度的迅速增长,是以知识系统化程度低和对早期文献的关注为代价的。这项工作是作为一个指南介绍图形领域的深度学习。它倾向于对主要概念和建筑方面进行连贯和渐进的介绍,而不是对最新文献的阐述,读者可以参考现有的调查。本文从自顶向下的角度出发,提出了一种基于局部迭代方法的广义图表示学习方法。本文介绍了基本的构造块,这些构造块可以组合起来设计新颖而有效的图神经网络模型。方法论的阐述辅之以对该领域有趣的研究挑战和应用的讨论。
Scalable Influence Estimation Without Sampling
http://arxiv.org/abs/1912.12749
Andrey Y. Lokhov, David Saad
摘要:在一个网络的扩散过程中,初始扩散者期望有多少个节点受到影响。这个自然问题,通常被称为影响估计,归结为计算给定节点从指定初始条件开始时在给定时间处于活动状态的边际概率。在许多其他的应用中,这个任务对于一个研究得很好的问题是至关重要的:在一个社会网络中找到最佳扩散器,它最大限度地延长一定时间范围内的传播。实际上,为了比较候选种子集,需要多次调用影响估计。不幸的是,在许多感兴趣的模型中,边缘的精确计算是P-hard的。在实践中,通常使用蒙特卡罗抽样方法来估计影响,这种方法需要大量的运行才能获得高保真度的预测,特别是在大多数情况下。因此,开发分析技术作为取样方法的替代方法是可取的。本文提出了一种基于可扩展动态消息传递方法的流行的独立级联模型中的影响函数估计算法。该方法具有单个蒙特卡洛模拟的计算复杂度,并在一般图上提供期望扩展的上界,从而为树状网络产生精确答案。我们还为线性阈值模型的随机版本提供了动态消息传递方程。因此,与基于模拟的技术相比,在运行时间上节省了潜在的大采样因子,从而使解决大规模问题实例成为可能。
backbone: An R Package for Backbone Extraction of Weighted Graphs
http://arxiv.org/abs/1912.12779
Rachel Domagalski, Zachary Neal, Bruce Sagan
摘要:本文描述了如何利用R包骨干网提取加权图的骨干网。加权图的分析和可视化具有内在的挑战性,因此通常只用于检查被认为重要的边。有几种方法可用于从加权图中提取仅保留有效边的未加权或有符号主干。主干包实现了四种不同的主干方法,其中三种方法考虑由二分投影产生的加权图。本文描述了如何使用每个包的函数及其使用的算法。
Wisdom of collaborators: a peer-review approach to performance appraisal
http://arxiv.org/abs/1912.12861
Sofia Dokuka, Ivan Zaikin, Kate Furman, Maksim Tsvetovat, Alex Furman
摘要:公司内部的个人绩效和声誉是影响工资分配、晋升和解雇的主要因素。由于现代业务流程的复杂性和协同性,在大多数组织中对个人影响的评价是一个模棱两可且不平凡的任务。现有的绩效考核方法往往受到个人偏见判断的影响,组织对评价结果不满意。我们断言,在复杂的协作环境中,员工可以提供对其同事绩效的准确测量。我们提出了一种新的评价个人声誉和不可量化的个人影响的指标,即同伴等级得分(PRS)。PRS是基于员工的成对比较。我们在模拟实验中展示了该算法的高鲁棒性,并在一家遗传测试公司的1000多名员工身上用三年的同行评议对其进行了实证验证。
C-V2X模式4的分散子信道调度:
一种用于CAM重传的非标准配置
Decentralized Subchannel Scheduling for C-V2X Mode-4: A Non-Standard Configuration for CAM Retransmissions
http://arxiv.org/abs/1912.13137
摘要:在第14版中,3GPP引入了一种称为蜂窝式车辆的新模式Verything(C-V2X)模式4,专门用于在没有网络覆盖的情况下支持车辆通信。这样一种方案被设计成分布式地利用一种传感机制来运行,通过这种机制,车辆可以监测通过子信道的接收功率。根据测得的功率强度,车辆自动选择合适的子信道,在该子信道上广播安全信息。所选择的子信道在释放以选择另一子信道之前被车辆利用了很短的一段时间。在这项工作中,我们提出了一种基于上述技术的调度方法,我们假设存在一个主子带,支持半持久保留子信道(如3GPP所指定)。此外,我们还考虑到存在辅助子带来传送随机重传,以提高接收可靠性。本文研究了该方法的不同结构,并利用实车轨迹对其性能进行了评估。
A Dynamic Process Reference Model for Sparse Networks with Reciprocity
http://arxiv.org/abs/1912.13144
摘要:许多社会和其他网络表现出稳定的大小缩放关系,使得诸如平均度或往复率的特征缓慢地变化,或者随着顶点数量的增加而近似不变。建立在简单的伯努利基线(或参考)测度之上的统计网络模型在这方面往往表现得不真实,导致稀疏参考模型的发展,这些模型保留了诸如平均度标度等特征。在本文中,我们推广了最近工作的微观基础上的参考模型的情况下,稀疏有向图的非消失互惠,提供了动态过程解释出现的稳定宏观行为。
Systemic liquidity contagion in the European interbank market
http://arxiv.org/abs/1912.13275
V. Macchiati, G. Brandi, G. Cimini, G. Caldarelli, D. Paolotti, T. Di Matteo
摘要:国际货币基金组织将系统性流动性风险定义为多个金融机构同时出现流动性困难的风险,这是宏观审慎政策和金融压力分析中的一个关键课题。可以使用专门的模型来模拟融资流动性风险和传染,但它们不仅需要银行的双边风险敞口数据,还需要具有足够粒度的资产负债表数据,而这些数据很难获得。另外,银行间网络的风险分析是通过基础图的中心性度量来完成的,该图捕获了最相互关联的、因此更容易分散风险的银行。本文以资金流动性短缺机制为传染过程,建立了一个基于传染病模型的银行间市场传染模型。考虑到银行间市场的异质性,该模型具有丰富的国家和银行风险特征。当运行专用模型所需的全套数据不可用时,建议的模型特别有用。由于银行间网络的不完全可用性,本文还提出了一种经济驱动的重建方法,通过将标准重建方法限制在真实的财务指标上来恢复银行间网络。我们证明,传染模型能够在不同年份和国家重现系统性流动性风险。这一结果表明,所提出的模型可以作为更复杂模型的有效替代方案。
具有链式维度的领域
主题模型:主要肿瘤学会议
的演化建模(1995年至2017年)
Domain-topic models with chained dimensions: modeling the evolution of a major oncology conference (1995-2017)
http://arxiv.org/abs/1912.13349
Alexandre Hannud Abdo, Jean-Philippe Cointet, Pascale Bourret, Alberto Cambrosio
摘要:本文介绍了一种新的研究活动及其动力学的计算分析方法。我们的方法名为SASHIMI(多维信息层次推理中的对称和顺序分析),它提供了对科学活动结构的多层次描述,与传统的方法(如主题模型或网络分析)相比具有许多优势。我们的方法根据研究领域(文档集合)和主题(词汇集合)生成了对语料库的双重描述。它还将此描述扩展到关联维度的集群,如时间。SASHIMI只需要访问单个文档的文本内容,而不需要像其他科学映射方法那样访问特定的元数据,如引文、作者或关键字。我们将此方法应用于原始数据集的实证分析,即1995年-2017年在美国肿瘤学会(ASCO)召开的最大年度肿瘤研究会议上发表的摘要集,来说明我们方法的分析能力。我们证明,SASHIMI能够检测出重要的时间模式的存在,并识别出构成这些模式的主要肿瘤主题转换。
The Temporal Dynamics of Belief-based Updating of Epistemic Trust: Light at the End of the Tunnel?
http://arxiv.org/abs/1912.13380
Momme von Sydow (1), Christoph Merdes (2), Ulrike Hahn (3) ((1) Ludwig-Maximilians-Universität München, MCMP, Germany, (2) Friedrich Alexander University Erlangen-Nürnberg, ZiWiS, Erlangen, Germany, (3) Birkbeck College London, Department of Psychological Science, London)
摘要:我们从区分基于结果的贝叶斯模型和基于信念的贝叶斯模型开始。然后重点讨论了由埃里克·奥尔森建立的具有影响力的基于信任更新的贝叶斯模型,该模型对二分事件进行了建模,并明确表示了反可靠性。在为这个可能是最有前途的信念更新模型勾画了一些灾难性的近期结果之后,我们展示了有无信任更新和有无通信的学习信念时间动态的新仿真结果。这一结果似乎至少对通信和信任更新主体提供了一些更积极的启示。这或许是信任更新模型隧道尽头的一道亮光,但对清晰发现的解释却不那么清晰。
Clustering and percolation on superpositions of Bernoulli random graphs
http://arxiv.org/abs/1912.13404
Mindaugas Bloznelis, Lasse Leskelä
摘要:设 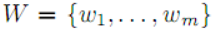 是一个有限集合。给定整数
是一个有限集合。给定整数 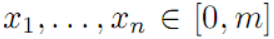 和数字
和数字 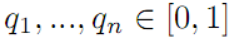 ,设
,设 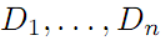 为W的独立均匀分布的随机子集,其大小
为W的独立均匀分布的随机子集,其大小 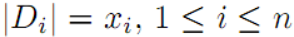 。设Gn是独立伯努利随机图
。设Gn是独立伯努利随机图 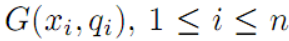 与顶点集
与顶点集  的集合。对于
的集合。对于  ,使得
,使得  ,我们证明了Gn具有可调(渐近)幂律度分布和不消失的全局聚类系数。进一步,聚类波谱承认的可调谐尺度为
,我们证明了Gn具有可调(渐近)幂律度分布和不消失的全局聚类系数。进一步,聚类波谱承认的可调谐尺度为  ,
, 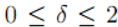 ,其中 ķ为顶点度。此外,我们在最大连接组分的大小上显示了相变,并检验了聚类谱与键渗透阈值之间的关系。
,其中 ķ为顶点度。此外,我们在最大连接组分的大小上显示了相变,并检验了聚类谱与键渗透阈值之间的关系。
The brevity law as a scaling law, and a possible origin of Zipf’s law for word frequencies
http://arxiv.org/abs/1912.13467
Alvaro Corral, Isabel Serra
摘要:计量语言学的一个重要组成部分是一系列关于语言使用的统计规律。尽管这些语言规律很重要,但其中一些规律的表述很差,更重要的是,没有一个统一的框架能涵盖所有这些规律。本文提出了一个新的视角来建立不同统计语言规律之间的联系。用长度(以字符数为单位)和绝对频率这两个随机变量来刻画每一个词的类型,我们证明了相应的二元联合概率分布具有丰富而精确的现象学,其类型长度和类型频率分布是其两个边值,频率的条件分布是在固定长度处,提供了简洁频率现象的清晰公式。这种类型的分布被伽马分布很好地拟合(比先前提出的对数正态分布好得多),定长条件下的频率分布显示出幂律衰减行为,其指数为 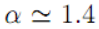 ,特征频率交叉的尺度为长度的反幂
,特征频率交叉的尺度为长度的反幂 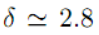 ,这意味着与临界现象热力学相似的尺度律的存在。作为一个副产品,我们找到了Zipf定律起源的一个可能的无模型解释,它应该是由交叉长度相关频率控制的条件频率分布组成的混合物。
,这意味着与临界现象热力学相似的尺度律的存在。作为一个副产品,我们找到了Zipf定律起源的一个可能的无模型解释,它应该是由交叉长度相关频率控制的条件频率分布组成的混合物。
Talent, Luck, Context and Perspective on Success: a disaggregating simulation using Risk
http://arxiv.org/abs/2001.00034
摘要:我们提出一个竞争和零环境下的受控模拟,作为分解成功要素的主体。在模拟风险董事会游戏的情况下,我们认为(a)人才是三种基于规则的策略之一;(b)背景是每一轮比赛的背景,对手是策略、目标和运气;以及(c)视角是每个玩家的目标。成功是在第一个玩家征服目标时获得的。我们模拟了一个基于主体的模型的100000次运行,并对结果进行了分析。模拟结果强烈地表明,运气、天赋和环境都与成功有关。因此,我们提出了一个定量的、可重复的环境,在这个环境中,我们能够显著地分离概念,再现先前的结果,并为上下文和视角添加论据。最后,我们还发现,弹性和机会可能在所提供的模拟中得到检验。
Simultaneous Identification of Tweet Purpose and Position
http://arxiv.org/abs/2001.00051
Rahul Radhakrishnan Iyer, Yulong Pei, Katia Sycara
摘要:推文分类最近引起了人们广泛的关注。现有的Twitter分类的研究主要集中在主题分类上,它将微博消息分为几个预定义的类别和情感分类,它们将微博消息分为正、负和中性。由于推文不同于传统文本,其长度一般有限,包含非正式、不规则或生词,因此很难确定用户发布推文的意图和用户对某个话题的态度。本文旨在同时对推文目的,即用户发布推文的意图,以及对给定主题的立场,即支持、反对或中立进行分类。将该问题转化为多标签分类问题,提出了一种后处理的多标签分类方法。在实际数据集上的实验证明了该方法的有效性,其结果优于单独的分类方法。
蒙特卡罗技术用于逼近迈耶森
价值——理论与实证分析
Monte Carlo Techniques for Approximating the Myerson Value — Theoretical and Empirical Analysis
http://arxiv.org/abs/2001.00065
Mateusz K. Tarkowski, Szymon Matejczyk, Tomasz P. Michalak, Michael Wooldridge
摘要:迈尔森首先引入了图限制博弈,以模拟合作参与者与底层通信网络的交互。一个专门的解决方案概念——迈尔森值,可能是图上合作博弈最重要的规范化解决方案的概念。不幸的是,它具有计算挑战性。特别地,尽管已经提出了精确的算法,但它们必须遍历图中可能存在指数级的多个连接社团。本文讨论了任意图和特征函数逼近迈尔森值的问题。对于Shapley值的相关概念,已经提出了蒙特卡洛近似,但对迈尔森值的适用性还没有研究。鉴于此,我们评估并比较(理论上和经验上)针对迈尔森值的三种蒙特卡洛抽样方法:传统的抽样排列方法;结合精确计算和抽样的新的混合算法;以及连接联盟的抽样。研究发现,我们的混合算法表现得非常好,并且在传统方法的基础上有了显著的改进。
Recursive Formula for Labeled Graph Enumeration
http://arxiv.org/abs/2001.00084
Ravi Goyal, Victor De Gruttola
摘要:本文提出了一个通用的递归公式来估计与代数图相关的纤维的大小,从图表到社交网络分析重要性的汇总统计,如边缘数(图密度)、度序列、度分布、节点协变量的混合和程度混合。也就是说,该公式估计具有给定网络属性值的标记图的数量。该方法可推广到其它网络性质(如聚类)和二分网络性质。对于特殊的设置,其中存在替代公式,仿真研究证明了所提出的方法的有效性。我们说明的方法估计纤维的大小与BA无标度网络模型相关的性质的程度分布和程度混合。此外,我们还演示了如何使用该方法来评估光纤中图形的多样性。
Inf-VAE:一种融合同质性
和影响的变分自编码框架
Inf-VAE: A Variational Autoencoder Framework to Integrate Homophily and Influence in Diffusion Prediction
http://arxiv.org/abs/2001.00132
Aravind Sankar, Xinyang Zhang, Adit Krishnan, Jiawei Han
摘要:近年来,人们对Twitter、Facebook等社交媒体平台上的信息传播的理解和预测产生了极大的兴趣。现有的融合预测方法主要是通过将融合级联投射到其当地社会街区来利用被淹没的用户的顺序。然而,这无法捕获未在任何级联中显式显示的全局社会结构,从而导致历史活动受限的非活动用户的性能较差。在本文中,我们提出了一种新的变分自动编码器框架(inf-VAE)共同嵌入同质和影响通过接近保持社会和位置编码的时间潜变量。Inf-VAE利用强大的图神经网络结构来学习有选择地利用用户的社会联系的社会变量,从而建立社会亲同性模型。在给定种子用户激活序列的情况下,Inf-VAE使用一种新颖的表达性共同关注融合网络,该网络通过共同关注其社会和时间变量来预测所有受影响用户的集合。我们在包括Digg、Weibo和Stack exchange在内的多个真实社会网络数据集上的实验结果表明,与最新的扩散预测模型相比,Inf-VAE获得了显著的收益;对于活动稀疏的用户和在种子集中缺少直接社会邻居的用户,我们获得了巨大的收益。
Deep Learning for Learning Graph Representations
http://arxiv.org/abs/2001.00293
Wenwu Zhu, Xin Wang, Peng Cui
摘要:近年来,随着网络数据量的不断增加,图形数据挖掘已成为计算机科学的一个热门研究课题,并在学术界和工业界得到了广泛的研究。然而,海量的网络数据给高效分析带来了巨大的挑战。这推动了图表示的出现,它将图映射到一个低维向量空间,保持原始的图结构并支持图推理。对图的有效表示的研究具有深刻的理论意义和重要的现实意义,因此本文介绍了图表示/网络嵌入的一些基本思想和一些有代表性的模型。
Understanding the mesoscopic scaling patterns within cities
http://arxiv.org/abs/2001.00311
Lei Dong, Zhou Huang, Jiang Zhang, Yu Liu
摘要:理解城市元素之间的数量关系对于广泛的应用是至关重要的。宏观层面的观察表明,城市总量(如国内生产总值)随城市人口规模的系统变化而变化,即城市规模规律。然而,在介观层面上,我们对城市内部是否存在简单的尺度关系缺乏认识,这是城市尺度空间起源的一个基本问题。本文通过对4个覆盖数百万手机用户和城市设施的大规模数据集的分析,研究了城市内部的尺度现象。我们发现,介观基础设施容量和社会经济活动分别与活跃人口呈次线性和超线性关系;然而,对于相同的尺度现象,在人口规模相似的城市中,幂律指数是不同的。为了解释这些经验观察,我们提出了一个概念框架,考虑到人口和设施的异质分布以及它们之间的空间相互作用。分析和数值结果表明,尽管在城市活动中存在大量的复杂性,但简单的交互规则可以很好地解释城市内尺度行为的观察规律和异质性。
Computational Methods in Professional Communication
http://arxiv.org/abs/2001.00565
André Calero Valdez, Lena Adam, Dennis Assenmacher, Laura Burbach, Malte Bonart, Lena Frischlich, Philipp Schaer
摘要:世界的数字化也导致了通信过程的数字化。传统的研究方法在理解数字世界中的通信方面存在不足,因为使用传统方法研究的范围太大,种类太多,速度太快。本文介绍了计算方法及其在公共和大众传播研究中的应用,以及这些方法如何适用于专业传播研究。本文是一个小组的建议,小组成员包括每个领域的专家,将使用计算方法介绍他们目前的工作,并将讨论这些方法专业通信转移性小组的建议。
Emergent Behaviors from Folksonomy Driven Interactions
http://arxiv.org/abs/2001.00569
摘要:为了反映网络上不断发展的知识,本文根据一种新的概念结构Folksodriven来表示分众分类法,考虑了基于分众分类法的本体论。本文描述了一个研究Folksodriven标记交互导致Folksodriven集群行为的研究程序。研究的目的是了解在Folksodriven标签上产生复杂且有目的的群体行为的简单局部交互类型。我们描述了一个综合的,自下而上的方法来研究群体行为,包括设计和测试各种社会互动和文化场景与分众分类驱动标签。我们提出了一组基本的交互,可以用来构造和简化设计和分析紧急群体行为的过程。所呈现的行为谱是在一个分众分类环境中开发和测试的。
声明:Arxiv文章摘要版权归论文原作者所有,由本人进行翻译整理,未经同意请勿随意转载。本系列在微信公众号“网络科学研究速递”(微信号netsci)和个人博客 https://www.complexly.me (提供RSS订阅)进行同步更新。

集智俱乐部QQ群|877391004
商务合作及投稿转载|swarma@swarma.org
搜索公众号:集智俱乐部
加入“没有围墙的研究所”
让苹果砸得更猛烈些吧!













