核心速递
社会网络分析的四个维度:
研究方法、应用和软件工具综述
The Four Dimensions of Social Network Analysis: An Overview of Research Methods, Applications, and Software Tools
http://arxiv.org/abs/2002.09485
David Camacho, Àngel Panizo-LLedot, Gema Bello-Orgaz, Antonio Gonzalez-Pardo, Erik Cambria
摘要:近年来,基于社交网络的应用呈指数级增长,其中一个方面的原因是,这个应用领域提供了一个特别肥沃的地方,可以测试和开发最先进的计算技术,从 Web 中提取有价值的信息。这项工作的主要贡献有三个方面:(1) 我们对社会网络分析 (SNA) 的最新发展水平进行了文献综述;(2) 我们提出了一套基于 SNA 四个基本特征(或维度)的新度量标准;(3) 最后,我们对一套流行的 SNA 工具和框架进行了定量分析。我们还进行了一项科学计量学研究,以检测该领域中最活跃的研究领域和应用领域。本工作提出了四个不同维度的定义,即(a)模式、(b)知识发现、(c)信息融合、(d)集成、可伸缩性和可视化,用于定义一组新的度量(称为度),以评估 SNA 的不同软件工具和框架(根据之前的度量对一组 20 个 SNA-软件工具进行分析和排序)。这些维度连同定义的程度,可以评价和衡量社会网络技术的成熟度,寻求对它们的定量评估,从而揭示这一活跃领域的挑战和未来发展趋势。
The Outbreak Evaluation of COVID-19 in Wuhan District of China
http://arxiv.org/abs/2002.09640
Yimin Zhou, Zuguo Chen, Xiangdong Wu, Zengwu Tian, Liang Cheng, Lingjian Ye
摘要:2019年12月,在中国武汉发现了27例新型冠状病毒肺炎,曾被暂时命名为2019-nCoV,并于2020年2月11日被世界卫生组织正式命名为COVID-19。2019年12月和2020年1月,COVID-19在人群中大规模传播,给中国人民的生命财产安全带来了巨大灾难。在本文中,我们首先分析了病毒传播的特点和模式,并基于公共数据讨论了疫情传播的主要影响因素和不可控因素。然后,我们建立病毒传播模型,并将其应用于疫情发展的拐点和灭绝周期分析,为中国政府防疫决策和经济生产的恢复提供理论支持。此外,本文论证了中国政府采取的多层次行政区域隔离等防范措施的有效性。本研究对世界应对突发公共卫生事件有非常重要的现实意义。
COVID-19局部爆发的
分数TDD重构和预测算法
The Reconstruction and Prediction Algorithm of the Fractional TDD for the Local Outbreak of COVID-19
http://arxiv.org/abs/2002.10302
Yu Chen, Jin Cheng, Xiaoying Jiang, Xiang Xu
摘要:从 2019 年 12 月下旬开始,新型冠状病毒开始在中国内地蔓延。为了预测冠状病毒的传播趋势,本文提出了一些时滞动态系统(TDD)分析方法。在本文中,我们建立了一个新的分数时间延迟动态系统 (FTDD) 来描述柯惠-19 的局部爆发。通过引入分数阶导数来解释确诊和治愈人群增长的子扩散过程。基于政府提供的公共卫生数据,本文提出了一种稳定的系数重构算法。本文利用重构系数预测冠状病毒的变化趋势,得到的数值结果与公开数据吻合较好。
From spherical chicken to the tipping points of a complex network
http://arxiv.org/abs/2002.10380
Gui-Yuan Shi, Rui-Jie Wu, Yi-Xiu Kong, Kim Sneppen
摘要:流行病的爆发、金融危机的出现、生态系统的崩溃以及谣言的爆炸性传播,使当今世界面临着诸多挑战。这些现实世界问题可以抽象成一个复杂系统在日益紧张的环境中的连续故障。由于系统和环境都需要大量的参数来描述,故对分解条件进行了严格的估计。我们使用一个高度对称的系统来衡量一个复杂的环境,这使我们能够提出一个标量基准来描述环境。这使得我们能够证明复杂网络的所有临界点都落在网络的最大 k 核和最大特征值之间。
Information and dimensionality of anisotropic random geometric graphs
http://arxiv.org/abs/1609.02490
Ronen Eldan, Dan Mikulincer
摘要:本文研究随机图中的非各向同性高维几何结构的检测问题。即研究了一个随机几何图模型,其中顶点对应于从非各向同性D 维高斯分布随机独立生成的点。如果顶点之间的距离小于某个预定义阈值,则两个顶点相连。我们得出了新的维数概念,它依赖于高斯分布的协方差的特征值。若表示特征值向量,N 为顶点数,则  和
和 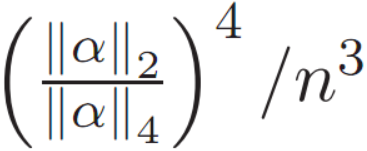 可以确定检测概率的上界和下界。本文基于Bubeck、Ding、Racz 等人的研究成果进行深入研究,指出 d / n ³ 的数量决定了各向同性几何的检测边界。本文通过傅立叶分析和特征函数理论来研究模型的潜在概率。
可以确定检测概率的上界和下界。本文基于Bubeck、Ding、Racz 等人的研究成果进行深入研究,指出 d / n ³ 的数量决定了各向同性几何的检测边界。本文通过傅立叶分析和特征函数理论来研究模型的潜在概率。
On The Microscopic Modeling of Vehicular Traffic on General Networks
http://arxiv.org/abs/2002.09512
Rinaldo M. Colombo, Helge Holden, Francesca Marcellini
摘要:本文介绍了一种处理道路网上车辆的微观模型的方法。每条道路上的交通流都是单向的,并且车辆动力学是通过一个跟踪-领导模型进行描述。从数学上看,这相当于任意网络上的一个普通微分方程组。本文提供了一般存在性和唯一性结果,而连接处的优先级显示阻碍了解决方案的稳定性。在这个模型中,我们在时间依赖的情况下研究了布雷斯悖论的发生。非平稳情况下纳什平衡的出现导致布雷斯悖论的出现,数值模拟支持了这一点。
结构-MMSB:具有可解释
结构先验的混合成员随机块模型
Struct-MMSB: Mixed Membership Stochastic Blockmodels with Interpretable Structured Priors
http://arxiv.org/abs/2002.09523
摘要:混合成员随机区组模型 (MMSB) 是一个流行的社区检测和网络生成框架。它通过利用底层的图结构来学习跨社区的每个节点的低等级混合成员表示。假设节点的成员分布独立于狄利克雷分布,这限制了其建模真实世界网络中存在的高度相关的图结构的能力。在本文中,我们提出了一种灵活的丰富结构的 MMSB 模型,Struct-MMSB,它使用最近开发的统计关系学习模型,铰链损失马尔可夫随机场(HL-MRFs),作为节点属性之间的结构化先验模型复杂依赖性,多关系链接,以及它们与混合成员分布的关系。本文使用加权一阶逻辑规则的概率编程模板语言指定我们的模型,增强了模型的可解释性。此外,我们的模型能够通过有意义的潜在变量(编码为观测特征和成员分布的复杂组合)学习现实世界网络中的潜在特征。我们提出了一种基于期望最大化的迭代学习潜变量和参数的推理算法,推理算法的可扩展随机变化,以及一种学习 HL-MRF 结构化先验权重的方法。我们在三种不同类型的网络和相应的建模场景的六个数据集上评估了我们的模型,并证明我们的模型与最先进的网络模型相比,测试对数似然度平均提高了 15%,收敛速度更快。
Dynamics of large scale networks following a merger
http://arxiv.org/abs/2002.09591
John Clements, Babak Farzad, Henryk Fukś
摘要:我们研究了大规模多人在线游戏 Planetside 2 中的化身之间的关系动态网络,在 2014 年春天,这个游戏的两个单独的服务器被合并,导致两个不同的网络被合并成一个。我们在合并后的七个月内观察了这个网络的演变,并报告了我们的观察结果。我们发现,合并后原有网络的一些结构在合并后的网络中长期存在。随着最初的化身逐渐被移除,这些结构慢慢地溶解,但它们在令人惊讶的长时间内仍然可以观察到。本文提出了一些可视化方法来研究合并后的动力学,并讨论选定的数量表征网络的拓扑结构的时间演变。
Fair and Decentralized Exchange of Digital Goods
http://arxiv.org/abs/2002.09689
Ariel Futoransky, Carlos Sarraute, Daniel Fernandez, Matias Travizano, Ariel Waissbein
摘要:我们构建了一个保护隐私的、分布式的分散市场,在这个市场中,各方可以交换令牌的数据。在这个市场中,买卖双方在一个区块链中进行交易,并与第三方(称为公证人)进行互动,后者有能力为数据的真实性和完整性提供担保。我们为数据令牌交换引入了一个协议,在这个协议中,任何一方获得的信息都不超过它所支付的信息,并且交换是公平的:要么双方都获得了对方的项目,要么双方都没有。设置后不需要第三方参与,不需要争议解决。
Allotaxonometry and rank-turbulence divergence: A universal instrument for comparing complex systems
http://arxiv.org/abs/2002.09770
P. S. Dodds, J. R. Minot, M. V. Arnold, T. Alshaabi, J. L. Adams, D. R. Dewhurst, T. J. Gray, M. R. Frank, A. J. Reagan, C. M. Danforth
摘要:复杂系统通常由许多数量级不同的部分组成:国家的城市人口、经济中的个人和企业财富、生态中的物种丰富度、自然语言中的词频和复杂网络中节点的度。我们通常使用信息理论的工具来比较两个复杂系统或两个不同时间点的系统的尺寸分布,如 Jensen-Shannon 散度。我们认为,这些方法缺乏透明度和可调性,当分量概率不可感知或估计有问题时,不应应用这些方法。在这里,我们介绍一种比较任意两个排列的组分列表的异源旋光仪和秩扰动分叉。我们通过一系列的分析步骤发展了基于秩的散度,然后建立了一个基于秩的异构直方图,该异构直方图根据散度贡献将秩-秩对的类图直方图与有序的分量列表配对。我们在一系列不同的设置中探索了等级-湍流差异的性能,包括:在 Twitter 和书籍中的语言使用、物种丰富度、婴儿姓名流行度、市场资本化、运动性能、死亡原因和职称。我们提供一系列补充,展示了基于等级的同分异构体的可调节性。
Author Name Disambiguation on Heterogeneous Information Network with Adversarial Representation Learning
http://arxiv.org/abs/2002.09803
Haiwen Wang, Ruijie Wang, Chuan Wen, Shuhao Li, Yuting Jia, Weinan Zhang, Xinbing Wang
摘要:作者姓名歧义造成学术信息检索的不足和不便,由此提出作者姓名消歧 (AND) 的必要性。现有的模型和方法可分为两类:以内容信息为中心的模型来区分两篇论文是否为同一作者所写;以关系信息为中心的模型来表示网络上的边缘信息和量化论文之间的相似性。前者需要足够的标记样本和详实的负面样本,并且在测量论文之间的高阶连接时也是无效的,而后者需要复杂的特征工程或监督来构建网络。本文提出了一种新颖的生成对抗框架,使两类模型共同成长:(i) 辨别模块区分两篇论文是否来自同一作者,(ii) 生成模块直接从异构信息网络中选择可能同质的论文,消除了复杂的特征工程。通过这样的方式,辨别模块可以引导生成模块选择同质论文,生成模块生成高质量的负面样本对辨别模块进行训练,使其意识到论文之间的高阶联系。此外,还设计了判别模块的自训练策略和基于随机游走的生成算法,使训练稳定有效。在两个真实世界和基准上进行的大量实验表明,与最先进的方法相比,我们的模型提供了显著的性能改善。
Tree++: Truncated Tree Based Graph Kernels
http://arxiv.org/abs/2002.09846
Wei Ye, Zhen Wang, Rachel Redberg, Ambuj Singh
摘要:图形结构数据在许多应用中无处不在。一个根本的问题是量化它们的相似性。图核通常用于此目的,它将图分解为子结构并比较这些子结构。然而,现有的大多数图核都不具有自适应尺度的特性。他们无法在多个粒度级别上比较图形。为了解决这一问题,我们提出了一种新的图核——TREE++。在TREE++的核心是一个图形内核,称为路径模式图形内核。路径模式图的内核首先构建一个以每个顶点为根的截短BFS树,然后使用从根到截短BFS树中的每个顶点的路径作为特征来表示图。路径图核只能在细粒度处捕获图的相似度。为了在粗粒度处捕获图的相似度,我们引入了一个新的概念——超路径。超级路径包含在顶点处扎根的截短BFS树。我们对各种实际图的评估表明,与以前的图内核相比,TREE++实现了最好的分类精度。
Mixed Integer Programming for Searching Maximum Quasi-Bicliques
http://arxiv.org/abs/2002.09880
Dmitry I. Ignatov, Polina Ivanova, Albina Zamaletdinova
摘要:本文讨论了二部图 (bigraph) 中的最大拟分叉问题。二部图中的最大拟分叉问题是其几乎完整的子图。完备性的松弛可以有不同的理解;这里,我们假设如果子图缺少一定数量的边来形成一个二叉格,使得它的密度伽马属于(0,1] ,那么子图就是拟二叉格。对于一个固定的二部图,搜索最大拟分叉问题是:寻找二部图的一个顶点子集,使得诱导子图是一个拟分叉,并且它的大小对于给定的图是最大的。本文提出了几种基于混合整数规划 (MIP) 的拟分叉搜索模型,并对其工作效率进行了测试。本文使用了与三色簇相似的最小二乘准则,提出并检验了一种由双色簇激发的替代模型,该模型同时最大化了拟双色簇的尺寸和密度。
Steering complex networks toward desired dynamics
http://arxiv.org/abs/2002.09922
Ricardo Gutierrez, Massimo Materassi, Stefano Focardi, Stefano Boccaletti
摘要:我们考虑按照不同的规律随时间演化的动态单元网络,并以高度不规则的方式相互耦合。研究如何引导这类系统的动力学向期望的进化,在许多科学领域都具有巨大的实际意义,同时也提供了对网络结构和动力学行为之间相互作用的洞察。我们提出了一种在网络系统上进行与运动方程兼容的动态演化的协议。该方法不限制节点间的局部动力学行为,也不限制节点间的相互作用,可以采用任何非线性的数学形式,用加权的、有向的或无向的链路来表示。我们首先在混沌振子的小的合成网络上探索我们的方法,它允许我们揭示固定节点的有序序列和它们的拓扑结构之间的关联。然后,我们考虑一个 12 种的营养网络,它是哺乳动物食物网的一个模型。通过固定相对少量的物种,可以使系统从其(典型的不受控的)初始状态向目标动力学的自发进化,或者周期性地控制它,从而使种群在规定的范围内进化。本文讨论了这些发现与环境管理和保护的相关性。
大数据对信用评分的价值:
使用手机数据和社会
网络分析提高金融包容性
The Value of Big Data for Credit Scoring: Enhancing Financial Inclusion using Mobile Phone Data and Social Network Analytics
http://arxiv.org/abs/2002.09931
María Óskarsdóttir, Cristián Bravo, Carlos Sarraute, Jan Vanthienen, Bart Baesens
摘要:信用评分无疑是最古老的分析模型之一。近年来,为了提高信用评分模型的统计性能,人们开发了许多复杂的分类技术。本文没有将重点放在技术本身,而是利用替代数据源来提高统计和经济模型的性能。本研究展示了包括呼叫网络在内,在积极信用信息的背景下,作为一种新的大数据源如何通过应用利润测度和基于利润的特征选择,在利润方面具有附加值。使用独特的数据集组合,包括呼叫详细记录、客户的信用和借方帐户信息,为信用卡申请人创建记分卡。呼叫详细记录被用于建立呼叫网络,而先进的社会网络分析技术被应用于在整个网络中传播来自先前违约者的无能,以产生无能分数。结果表明,将呼叫详细记录与信用评分模型中的传统数据相结合,当用 AUC 测量时,显著提高了它们的性能。就利润而言,最好的模式是只具有呼叫行为特征的模式。另外,无论是在统计还是经济性能方面,呼叫行为特征在其他模型中的预测性最强。结果在电话详细记录的伦理使用、监管影响、财务包容以及数据共享和隐私方面产生了影响。
脑网络案例研究:
基于核ARMA模型和
Grassmannian模型的网络聚类方法
Network Clustering Via Kernel-ARMA Modeling and the Grassmannian The Brain-Network Case
http://arxiv.org/abs/2002.09943
Cong Ye, Konstantinos Slavakis, Pratik V. Patil, Johan Nakuci, Sarah F. Muldoon, John Medaglia
摘要:本文提出了一种用时间序列数据标注节点的网络聚类框架。该框架解决了所有类型的网络聚类问题:状态聚类、状态内节点聚类(即拓扑识别或社区检测),甚至子网络状态序列识别/跟踪。通过自下而上的方法,首先通过核的自回归移动平均模型从原始节点时间序列数据中提取特征,揭示非线性依赖关系和低秩表示,然后映射到 Grassmann 模型上。所有聚类任务都是通过以一种新颖的方式利用 Grassmann 模型的基本黎曼几何来完成的。为了验证所提出的框架,考虑了脑网络聚类,其中对合成和真实功能磁共振成像 (fMRI) 数据进行了广泛的数值试验,证明提倡的学习框架与几种最先进的聚类方案相比是有利的。
引用量系统地误读了
科研论文的质量和影响:
基于数千引用者的调查和实验证据
Citations Systematically Misrepresent the Quality and Impact of Research Articles: Survey and Experimental Evidence from Thousands of Citers
http://arxiv.org/abs/2002.10033
Misha Teplitskiy, Eamon Duede, Michael Menietti, Karim R. Lakhani
摘要:引文在评价研究中无处不在,但它们究竟与它们被认为衡量的东西(质量和影响)有何关系尚不清楚。我们使用一项嵌入式实验调查了引文、质量和影响之间的关系,其中 15 个学术领域的 12,670 位作者描述了25000个具体参考决策。结果表明,引文数量与质量和影响等同时,偏向相反的方向。首先,实验性地揭露调查期间论文实际被引次数,导致受访者认为除了前 10% 外,所有被引论文的质量都较低。因为对质量的感知是引用决定的关键因素,引文计数很可能内源性引起更多的顶级论文引用,并将其与质量等同高估了那些论文的实际质量。相反,54% 的参考文献对引用它们的作者的影响要么为零,要么为轻微影响,但引用高被引论文具有显著的实质性影响。本文将引文等同于影响从而低估了高被引论文的影响。因此,真实的引文实践表明,引文是质量和影响的有偏估计指标。
Angry Birds Flock Together: Aggression Propagation on Social Media
http://arxiv.org/abs/2002.10131
Chrysoula Terizi, Despoina Chatzakou, Evaggelia Pitoura, Panayiotis Tsaparas, Nicolas Kourtellis
摘要:网络攻击行为在各种环境和在线社交平台上都有发现,并利用最先进的机器学习和深度学习算法对不同的数据进行建模,从而能够自动检测和阻断这种行为。用户可能会因为在他们自己的(在线)社交圈中攻击性的增加而表现出攻击性,甚至欺负他人。实际上,这种行为可以从一个用户和邻居传播到另一个用户和邻居,因此,在网络中传播。有趣的是,据我们所知,没有任何工作模拟了攻击行为的网络动力学。在本文中,我们通过研究社交媒体上的攻击行为的传播,向这个方向迈出了第一步。我们研究了广泛用于模拟观点如何通过网络传播的各种观点动力学模型。我们提出了增强这些经典模型的方法,以适应攻击行为如何从一个用户传播到另一个用户,这取决于每个用户与其他攻击性用户或常规用户的连接方式。通过对Twitter 数据的大量模拟,我们研究了攻击行为如何在网络中传播,并通过爬行数据和众包注释验证了我们的模型。我们讨论了我们工作的结果和影响。
Universality of citation distributions and its explanation
http://arxiv.org/abs/2002.10138
摘要:引文分布的普遍性或接近普遍性是十年前凭经验发现的,但其理论上的合理性一直缺乏。在这里,我们系统地研究了不同学科的引文分布,以表征这种假定的普遍性并从理论上理解它。使用我们校准的引文动力学模型,我们发现了引文分布普遍性的微观解释,并解释了由此产生的偏差。我们证明论文的引用计数一方面是由它的适宜性决定的——对于大多数论文来说,这个属性是在发表的那一刻设定的。不同学科的适应度分布非常相似,可用对数正态分布近似。另一方面,论文的引用动力学与科学界关于它的知识传播的机制有关。这种病毒的传播是非普遍性的,而且是有规律性的。因此,引文分布的普遍性可追溯到适应度分布,而偏离普遍性则与论文特定学科的引文动力学有关。
Uncited papers are not unread
http://arxiv.org/abs/2002.10160
摘要:我们研究了1984 年出版的物理学、经济学和数学论文的引文动力学,并重点研究了这三篇文献中未被引用论文的比例。我们的引文动力学模型,把引文过程看作一个非齐次的泊松过程,很好地捕捉到了这一不确定度比。值得注意的是,我们的模型中的所有参数和变量都与引用及其动力学相关,而未被引用的论文作为引用过程的副产品出现,这就是泊松统计,它使被引用论文和未被引用论文不可分割。这表明,大部分未发表的论文构成了科学企业的固有部分,即无引用的论文并非无人阅读。
A knowledge-based model of civilization under climate change
http://arxiv.org/abs/2002.10196
摘要:文明产生知识,知识是文明发展的动力。本文提出了一个宏观的文明模型,它解释了知识生产对人口、能源消耗和环境条件的影响。该模型包括世界人口、文明知识循环量、化石燃料在能源消耗总量中所占份额、大气CO2 浓度和全球平均表面温度的动力学方程。本文考虑了知识生产中的能量耗散和知识的直接损失。本文使用每个变量的历史数据校准模型,计算了约 90 种情况。研究表明,有两个控制参数 C:种群对温度升高的敏感性和知识损失系数 C 决定了文明的未来。在这些参数的二维空间中,存在着可持续发展区域和失稳区域。计算表明,文明正好处于划分这些区域的临界曲线上,即处于稳定的边缘。微小的偏差最终可能导致100 亿人口的稳定状态或文明的完全灭绝。
基于Levy-Levy-Solomon
主体的经济市场模型的新见解
Novel Insights in the Levy-Levy-Solomon Agent-Based Economic Market Model
http://arxiv.org/abs/2002.10222
Maximilian Beikirch, Torsten Trimborn
摘要:Levy-Levy-Solomon 模型是在基于主体的经济市场模型。在一些出版物中对该模型进行了讨论和分析。特别是 Lux 和 Zschischang的研究表明,该模型显示出尺寸效应。在本研究中,我们在几个方向扩展了现有的工作。首先,我们展示了模型的数值模拟结果。其次,我们阐明了这些小尺寸元素的来源。此外,我们证明了 Levy-Levy-Solomon 模型对随机数的敏感性。特别是,低质量的伪随机数发生器对仿真结果有很大的影响。最后,我们研究了停止准则对Levy-Levy-Solomon 模型的市场清除机制的影响。
Latent learning and the formation of a spatiotemporal cognitive map of a road network
http://arxiv.org/abs/2002.10263
Navid Khademi, Ramin Saedi
摘要:本文讨论了两个主题。首先,研究了道路网络在旅行者记忆中的时空认知图(心理意象)的形成,它涉及到旅行者对道路网络拥挤度或拥挤度的整体概念理解。其次,本研究试图探讨旅客从以往经验中获得的潜在学习是如何在旅客不熟悉的网络环境中形成部分心理意象的。为了深入了解认知地图的形成过程和潜在学习能力,对90名参与者进行了路径选择体验实验。在该实验中,下列独立变量被连接到该网络的一个心理图像的形成和所述网络的不熟悉的部分的泛化的质量:推广链接的在整个网络中传播的时间,旅客的数量,旅客的性别,旅客的驾驶经验,旅客的乐观或悲观的自然水平,网络上的明显特征,业务的存在信号。我们利用几个非参数(无分布)检验来检验假设。结果表明,除了旅行者在网络上的性别和显著特征外,所考虑的因素对旅行者对网络要素的识别程度都有显著影响。
Reducing Urban Traffic Congestion Due To Localized Routing Decisions
http://arxiv.org/abs/2002.10298
Bo Li, Andrey Y. Lokhov, David Saad
摘要:通过激励司机的路径选择来缓解交通堵塞,从而达到平衡交通的目的,这种做法在城市交通规划中越来越有吸引力。在这里,我们介绍了一个离散的动力学模型,包括用户在作出自己的路由选择的基础上,当地的信息和那些考虑基于本地化的诱导路由的建议。我们识别交通模式的形成,开发一个可伸缩的最优化方法识别用于用户指导的控制价值,并且在合成和真实世界的道路网络上测试这些措施的有效性。
搜索社会的滞后——WS小世界
网络上独立的对称阈值模型
In search for the social hysteresis — the symmetrical threshold model with independence on Watts-Strogatz graphs
http://arxiv.org/abs/2002.10395
Bartłomiej Nowak, Katarzyna Sznajd-Weron
摘要:本文通过对WS小世界网络的拟合和蒙特卡罗模拟,研究了具有独立(噪声)的齐次对称阈值模型。该模型是著名的Granovetter的阈值模型的修正版:一个投票人以概率p独立行动。即从两种状态l中随机选取一种:以1-p的互补概率。如果某一州的居民中有足够大的比例(高于某一阈值r)处于该州,那么该选民将选择该州。我们证明了由噪声参数p引起的相变特征依赖于阈值和图的参数。当r=0.5时,我们只观察到连续的相变,而对于r>0.5时,也可能出现不连续的相变。滞后随平均次数和重写参数的增大而增大。另一方面,滞后宽度与阈值r之间的关系是非单调的。阈值r,针对其观察到的最大滞后的值,重叠很好用于描述性准则,以操纵社会实验内的人的大部分的大小。我们将本文所获得的结果放在一个更广阔的背景下,并在另外两种二元观点模型的背景下进行讨论,这两种二元观点模型分别是多数票模型和Q-选民模型。
声明:Arxiv文章摘要版权归论文原作者所有,由本人进行翻译整理,未经同意请勿随意转载。本系列在微信公众号“网络科学研究速递”(微信号netsci)和个人博客 https://www.complexly.me (提供RSS订阅)进行同步更新。

集智俱乐部QQ群|877391004
商务合作及投稿转载|swarma@swarma.org
搜索公众号:集智俱乐部
加入“没有围墙的研究所”
让苹果砸得更猛烈些吧!
本篇文章来源于微信公众号: 集智俱乐部













