因果发现是在满足某些假设时,从数据中找出变量间因果联系。然而若是真正引起因果关系的变量本身就没有被观测到,那该怎么办?
从数据中提取对指定任务有帮助的特征,正是机器学习成功的原因。通过结合机器学习,可以在更少的假设下,发现因果关系。而借由找出的因果链条,则可以提升机器学习算法的泛化能力。
本文基于凯风研读营郭若城的分享,从以上两方面概述机器学习和因果推断间的关联。郭若城是美国亚利桑那州立大学博士,他的综述“A Survey of Learning Causality with Data:Problems and Methods”对该话题给出了全面的讲解。
自9月20日(周日)开始,集智俱乐部联合北京智源人工智能研究院还将举行一系列有关因果推理的读书会,欢迎更多的有兴趣的同学和相关研究者参加,一起迎接因果科学的新时代。该文的作者郭若城也会在读书会期间再详细具体深入地介绍机器学习和因果推断这个主题系列读书会详情与参与方式见文末。
机器学习的任务,通常是描述式或预测式的,不需要涉及对数据本身因果关系的判断。然而近期的一些列方法学上的进展,使得能够基于更少的先验假设,境界基于大数据,从中学到因果联系。尽管这些方法,并没有直接地判别因果关系,但为因果推断指出了新的可能探索方法。
只使用观察到的数据,那能拿到的只是变量之间的条件概率分布以及联合概率分布,例如下图所示的,不同的人在吃药或没吃药时的健康状况,而要想推断出吃药和健康状况之间是否存在因果关系,可以看成是根据概率信息,计算平均干预影响(ATE average treatment effect)。
为了确保该问题是可解的,需要假设该问题中,所有可能同时对结果和原因产生影响的变量,都已被观测,且所有可能对结果产生影响的干预发生的概率在0到1之间,这被称为强忽略假设(Strong ignorability),这意味着只有给定了不同干预下的概率分布,就可以计算不同干预下的潜在可能结果的统计量。
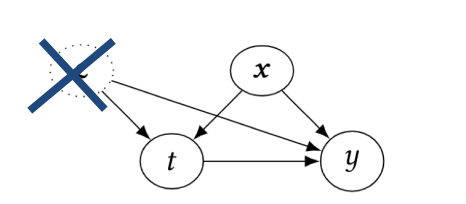
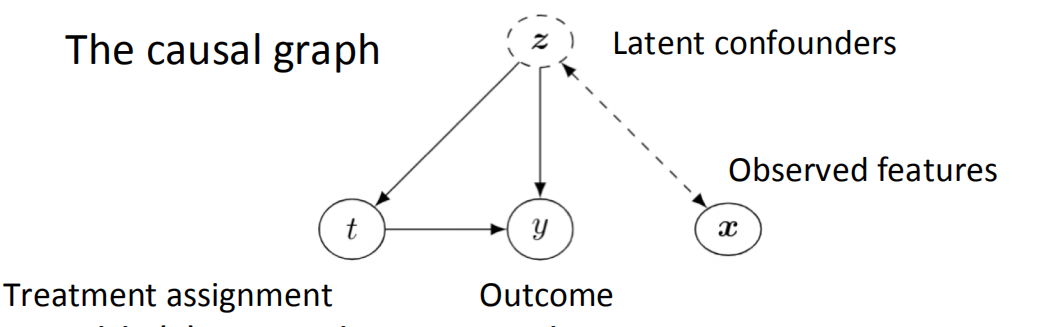
通常,强忽略假设是很难在真实场景下满足的。为此,可以通过隐含变量,即假设能够通过机器学习,提取隐变量。使得即使在混杂变量不可被观察时,通过控制隐变量,来将因果推断变为可解的统计问题。
图3 加入隐变量之后的结构因果图,图中的z可通过机器学习模型获得
第一类判断因果关系的方法,基于神经网络,同时认为强忽略假设满足。这类方法通过隐含层提取出的表征,代表了混杂因素。之后通过不同潜在结果下对应的神经网络,将隐变量的影响分别进行映射,最终得到不同干预下的损失函数,用以代表因果关系。
 图4 CRFNet 网络结构图[1]
图4 CRFNet 网络结构图[1]
第二类方法,不要求强忽略假设满足,但假设变量间独立同分布。其代表是因果效应变分自编码器(CEVAE)[2]。该方法在假设隐变量z符合高斯分布时,通过最小化原因x和结果y的经过自编码器提取特征后差异,通过深度神经网络表征隐变量z,之后可依据学到的模型,做反事实推断。
第三类方法,基于树模型,要求强忽略假设满足,例如因果随机森林,模型学习如何通过将变量所处的空间,进行划分,逐渐地从整体的概率分布,得到具体场景下的干预影响,从而估计异质环境下的影响,以此来间接地评价因果关系。
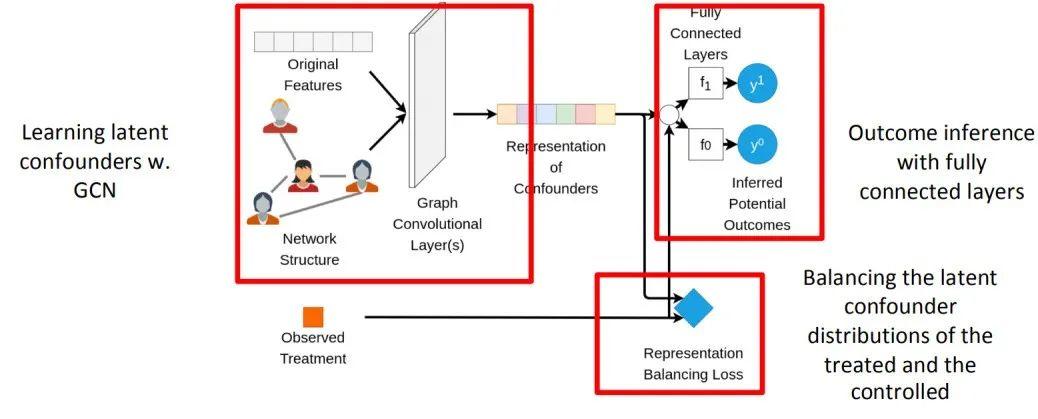
在社交网络中,相互有联系的个人,往往在众多未被观测到的特征上,有着相似性,这被称为同质性(homophily)。因此,在使用机器学习进行因果推断中,如果能考虑社交网络间的连接,能够在强忽略假设不满足时,更好的估计隐变量。
图6 基于图卷积网络,提取社交网络的特征,结合原数据特征。使用表征平衡损失,以平衡干预与否状况下的潜在混杂因素分布[3]。
该如何选择机器学习算法的评价指标?或者问什么样的指标能够避免过拟合?对这两个问题的回答,可以从下图的对比看出。
 图7 因果推断vs机器学习 对比图 [5]
图7 因果推断vs机器学习 对比图 [5]
左图的乌鸦,之所以能够通过将碎石放入瓶中,从而喝到水,这是由于其理解了这背后的因果关系。而右图的鹦鹉,训练者需要的是其学会人类的语言,但实际考察的,却只是其模仿人类语句的能力。
而不涉及因果的机器学习,正如同这个鹦鹉,只是学会了如何做出使评价指标提升的决策,却没有考虑这样的选择和最终的需求之间是否存在因果联系。尤其是当测试数据与验证数据分布不同时,则更可能出现过拟合。
例如在工业界使用机器学习来提升商品总销量(GMV),在算法开发时,使用的是离线的数据集及评价指标,在算法上线后,通过实时数据进行评估。这里有两个挑战。一个是算法线上表现和公司商业表现的关系尚不清楚。一个模块(如推荐系统)更好的线上表现可能并不能使公司盈利增加,因为它可能同时导致其他模块(如搜索)的表现下降。第二个是我们无法直接使用线上表现的标签训练机器学习模型。这是因为正在训练的模型和已经上线的模型在预测上的不同带来的偏差。如何无偏差地利用已经上线的模型搜集到的数据去离线场景下训练新的模型也是一个因果机器学习中重要的问题,这个问题又被称为无偏差机器学习。
图8 离线评价,在线评价与真实商业场景下表现的对比和联系 [5]
然而,如果使用在线的数据进行评测,往往会对用户的体验造成影响。A/B测试意味着用户会看到不同的展示界面。而无偏差的机器学习的目标,则是不进行在线评测,根据算法在离线数据上的评价指标,来估计其在真实商业场景中的效果。
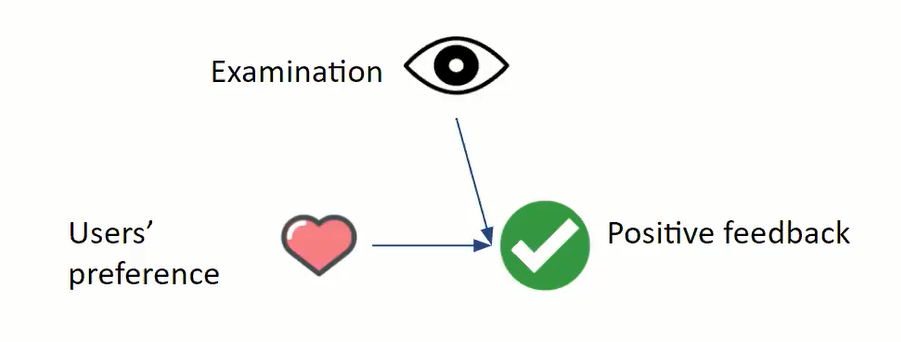
例如,搜索中,排在前的网页被点击得更多,用户点击网站有两个先决条件,用户看到网站,同时还喜欢网站,如果排序算法对网站的评分,没有考虑当前网页排名带来的影响,就会在评估时有偏。然而推荐算法真正想提取的,是用户喜好的信息。
而相比传统的网页搜索,电商网站的搜索结果,往往会以二维的网格呈现,这使得电商搜索数据呈现带来的偏差与传统的网页搜索相比,变得更为复杂,为此在通过用倾向性得分 (Inverse Propensity Scoring) 来对标签进行加权。去校正选择性偏差前,需要根据离线数据或者在线随机实验,评估每个标签(点击或者购买)对应的倾向性得分。
例如,之前的研究指出,触屏中,如果用户对展示的这几项都不感兴趣,则不会看完而会直接滑动换一屏;对屏幕中间展示的商品更容易关注,相比线性的展示,用户的注意力能停留更长时间。而通过实际数据检验,发现对展示位置为的中间商品的偏好不存在,因此在之后,就不需要考虑针对这一偏差,使用Inverse Propensity Score IPS 进行权重再分配。
数据标签和待学习的特征,往往存在着伪关联。例如训练集中骆驼的图片都出现在沙漠中,而羊的图片都出现在草原,如此训练出的模型,会将沙漠的特征当成骆驼的特征,然而这并非是存在着因果关系的特征。
将特征分为两类,一类为因果特征,一类为伪特征。因果特征能够跨越不同的数据类型,在不同的场景下迁移。而后者会随着数据所属范畴的改变而改变。能够提取出因果特征的模型,泛化能力更强。
根据是否找到代表因果关系的特征,可以将训练好的深度学习模型分为是否具有异分步可泛化性(OOD :out of distribution )。如果模型的训练数据,来自从多个来源收集的独立同分布的数据,且测试数据和训练数据不同,则称模型具有OOD泛化能力。
上图中数据E,经由因果特征Xc,影响分类标签Y,而Xs为伪相关特征。在数据E的范畴改变时,给定E是Xc和Xs的分布都会改变,而给定Xc得出标签Y的分布不变,因此将Xc称为表征了因果联系的特征。论文[4]中提出的IRM方法,详述了如何捕捉因果不变特征。
该文在二分类问题中,在训练集和测试集中,加入了颜色和标签之间的伪相关,并使得训练集和测试集之间的之间颜色的分布相反。如下图中左边测试集中,相同标签的数字图片多为绿色,而测试集中的图片为红色。对于IRM,其在训练集和测试集中的分类准确度远高于传统模型,接近了去掉颜色这一干扰因素的理想情况。
然而,IRM作为一种正则项,虽然能够学到因果联系,但不适用于高维数据,且在优化过程中,引入了额外的复杂性。
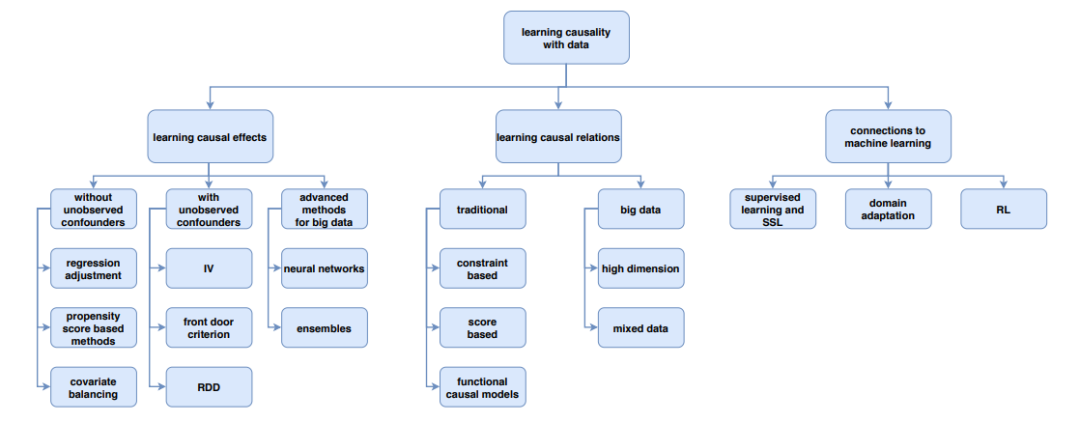
从数据中发现因果关系,按对数据的假设,可以分为假设数据独立同分布,数据不满足独立同分布,但强忽略假设满足,以及包含未观察到的隐变量三种。机器学习相关的方法,主要试图解决后一种问题。而传统因果发现中基于约束或打分模型的方法,需要实际中更难满足的强忽略假设。
从数据中发现因果关系的方法汇总,左边的子树对应从数据中学习包含未观测隐变量的因果联系的强弱,中间代表如何学习因果关系的方向,右边代表了因果性和机器学习方法的关联[6]。
经由因果性特征的发现,除了帮助模型具有更好的迁移能力,具有异分布泛化性,还能够用于半监督学习及强化学习。未来可能的研究方向还包括如何提升模型的可解释性,以及让模型更加公平,例如对少数族裔或女性不进行“算法杀熟”。
而在另一个方向上,即通过寻找特征,间接地寻找因果关系及其影响程度。如何应对高维的数据、时序数据,如何处理结果与原因之间存在的环状结构等,仍然是开放问题。然而对于同样发源于统计的机器学习和因果推断,两者之间的方法学,注定存在可借鉴之处与更多值得进一步研究的联系。
参考文献:
[1] Johansson, Fredrik, Uri Shalit, and David Sontag. “Learning representations for counterfactual inference.” International conference on machine learning. 2016.
[2] Louizos, Christos, et al. “Causal effect inference with deep latent-variable models.” Advances in Neural Information Processing Systems. 2017.
[3] Guo, Ruocheng, Jundong Li, and Huan Liu. “Learning individual causal effects from networked observational data.” In Proceedings of the 13th International Conference on Web Search and Data Mining, pp. 232-240. 2020.
[4] Arjovsky, Martin, Léon Bottou, Ishaan Gulrajani, and David Lopez-Paz. “Invariant risk minimization.” arXiv preprint arXiv:1907.02893 (2019)
[5] Wang, Zenan, Xuan Yin, Tianbo Li, and Liangjie Hong. “Causal Meta-Mediation Analysis: Inferring Dose-Response Function From Summary Statistics of Many Randomized Experiments.” In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pp. 2625-2635. 2020.
[6] Guo, Ruocheng, et al. “A survey of learning causality with data: Problems and methods.” ACM Computing Surveys (CSUR) 53.4 (2020): 1-37.
大数据时代的下一场变革——因果革命正在酝酿之中,通过融合因果推理和机器学习而构建出来的Causal AI系统,有望奠定强人工智能的基石。
集智俱乐部联合北京智源人工智能研究院,邀请了一批对因果科学与Casual AI感兴趣的研究者,开展为期2-3个月的系列线上读书会,研读经典和前沿论文,并尝试集体撰写一部书籍。如果你也从事相关的研究、应用工作,欢迎报名,参与读书会的讨论!
时间:9月20日起,每周日晚19:00-21:00,持续约2-3个月
模式:线上闭门读书会;收费-退款的保证金模式;读书会成员认领解读论文
了解读书会具体规则、报名读书会请点击下方文章:
目前读书会已经有超过150余人的海内外高校科研院所的一线科研工作者以及互联网一线从业人员参与,如果你也对这个主题感兴趣,就快加入我们吧!

针对读书会的主题,由发起人龚鹤扬设置好了内容框架,每个主题下有一个负责人来负责维护组织相关内容,目前已经定好的如图所示,欢迎对主题感兴趣的联系相关负责人,以及来认领相关主题~

集智俱乐部QQ群|877391004
商务合作及投稿转载|swarma@swarma.org
搜索公众号:集智俱乐部
加入“没有围墙的研究所”
让苹果砸得更猛烈些吧!
👇点击“阅读原文”,一起读书吧