崔鹏:稳定学习——挖掘因果推理和机器学习的共同基础

导语
近年来,人工智能技术的发展和其在生产生活中的运用得到了广泛关注;在医疗、交通、金融等众多领域的应用实践中,如何提升人工智能 (神经网络) 模型的可靠性问题得到了众多研究者的关注。在近期举行的集智俱乐部年会中,来自清华大学的崔鹏老师带来了题为“因果推理和机器学习的共同基础”的主题报告,从特征和目标之间的因果性角度出发为解决人工智能稳定学习问题提供了一种思路。本文整理自崔鹏老师于2021年1月2日在集智俱乐部学术年会的分享。
崔鹏老师清华大学副教授,研究方向包括大数据环境下的因果推理与稳定预测、网络表征学习,及其在金融科技、智慧医疗及社交网络等场景中的应用。 崔鹏 | 讲者
崔鹏 | 讲者
方宏波 | 整理
邓一雪 | 编辑
1. 人工智能模型在运用过程中的两大困境:缺乏可解释性和未知环境下的稳定性
纵观人工智能(AI)技术的发展史,在过去的20年中,人工智能的进步紧密伴随着互联网经济的发展,在诸如网上搜索、推荐商品等众多场景中都有人工智能技术的运用。在这些场景中,AI做出错误决策的危害较小(比如推荐了用户不感兴趣的商品),使用者对AI模型算法的稳定性和可靠性要求相对较低。如今,AI技术逐渐渗透进了包括医疗、司法、运输等与民众生活紧密相关,对人类的生存和发展有重大影响的领域中。在这样的背景下,AI模型的可靠性和稳定性问题变得日益重要,也很大程度上决定了我们能在多大程度上利用和依赖人工智能技术帮助决策。
我们认为,当前人工智能模型在实践利用中存在两个重要问题。一是模型缺乏可解释性;也即人们无法理解模型做出判断的逻辑和原因。这就导致人们面对模型的决策时,只能无条件地完全肯定或否定其提供的答案,我们认为可以通过建立人机协作(human in the loop)的机制合作决策解决这个问题。第二个问题则是模型缺乏在位置环境下性能的稳定性;目前大多数人工智能模型依赖于iid假设(Independent and identically distributed), 即训练数据集和测试数据集的数据分布是相似的;而在实际运用中,无法完全预见可能出现的数据分布(无法了解测试数据集的分布),此时模型的性能无法保证。本文将重点解决模型在未知环境下的性能稳定性问题。
以识别图片中是否存在狗的人工智能应用为例。图1中的左图是训练集中包含狗的图片集,其中大多数图片的背景是草地。而在测试集中,模型对同样为草地背景的图片有良好的判断力(右图上);对非草地背景的图片判断准确度下降(右图中、下)。
 图1. 人工智能识别图片中的狗任务训练集(左),测试集结果(右)
图1. 人工智能识别图片中的狗任务训练集(左),测试集结果(右)
2. 对模型稳定性问题的一个探讨:基于特征相关性的不可靠决策
我们提出,当前的人工智能系统试图寻找输入特征和输出结果之间的相关性,而相关性特征并不是一个可靠的判断依据。图2是肯塔基地区从渔船上落水溺死的人数和当地的结婚率随时间变化的趋势图;可以计算出两者在时间轴上的变化趋势是高度相关的。但是很难想象人们可以在未来继续依靠结婚率推测溺水人数(或者反之),因为溺水人数和结婚率之间不存在明显的因果关系。事实上,类似的相关,但不构成因果的联系在现实世界中并不罕见。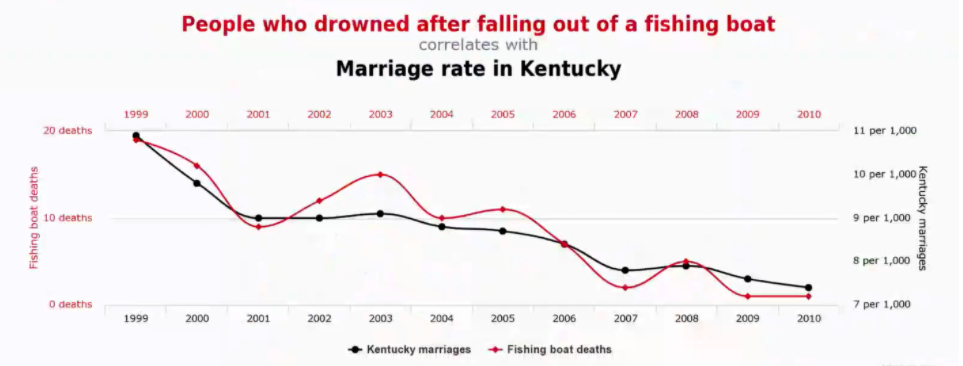 图2. 肯塔基溺水人数和结婚率历年变化图(1999-2010)
图2. 肯塔基溺水人数和结婚率历年变化图(1999-2010)
在人工智能模型中,依赖具有相关性的特征做决策容易使得模型被训练集误导,导致模型在未知环境下的性能不稳定。图3是采用可视化方法分析人工智能模型识别狗所依赖的特征(方框框出的位置)。可以看到红框框出的特征指向背景信息,是与识别结果在训练集上有相关性,但是缺乏因果性;而黄框指示的特征与识别结果有相关性,同时也有因果性。若依赖有相关性的特征输出结果,则模型可能被不含有因果性的特征误导,使得其在与训练集不同的测试集下(如非草地背景的图片)性能显著下降。 图3. 可视化分析人工智能模型识别狗图片任务依赖的特征
图3. 可视化分析人工智能模型识别狗图片任务依赖的特征
事实上,两个变量之间的相关性有三种来源,第一是由因果性导致的相关性,比如夏季气温高导致冰激凌销量上升,这种因果关系会导致冰激凌销量和季节之间的相关性。第二种是干扰变量导致的相关性,如吸烟人口的比例随着年龄的增长而增加,而肥胖的比例随着年龄的增长同样也增加,即使肥胖和吸烟比例之间没有直接的因果性,两者之间也存在着相关性。第三种是由样本选择偏差导致的相关性,即上文给出的如果在样本中大多数存在狗的图片都以草地为背景,而不存在狗的图片大多以非草地为背景,则草地背景和图片中含有狗的信息存在相关性,虽然两者之间不存在因果联系。在这三种相关性中,只有由因果性导致的相关性是可以保证在各种环境下稳定成立,且可以被解释的。而目前的神经网络模型并没有对特征是否存在因果性加以区分,我们认为这是导致模型训练不稳定的重要原因。
3. 解决人工智能性能稳定性问题的一种思路:基于因果性特征的稳定学习
图4给出了常见的独立同分布模型,迁移学习模型和稳定学习模型的异同。独立同分布模型的训练和测试都在相同分布的数据下完成,测试目标是提升模型在测试集上的准确度,对测试集环境有较高的要求;迁移学习同样期望提升模型在测试集上的准确度,但是允许测试集的样本分布与训练集不同。独立同分布学习和迁移学习都要求测试集样本分布已知。而稳定学习则希望在保证模型平均准确度的前提下,降低模型性能在各种不同样本分布下的准确率方差。理论上稳定学习可以在不同分布的测试集下都有较好的性能表现。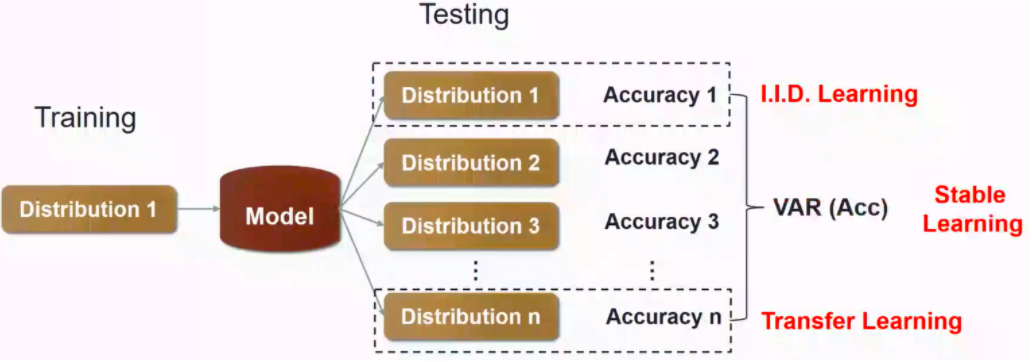 图4:独立同分布学习、迁移学习和稳定学习
图4:独立同分布学习、迁移学习和稳定学习
在前文的讨论中,我们认为与输出变量存在因果联系的输入变量是模型做出决策应该依赖的特征。要推理变量之间的因果关系,根据因果关系的定义:“变量A对变量B有因果关系,当且仅当保持其它所有变量不变时,若改变A的值,B的值发生改变。”以上文神经网络识别图片中的狗为例,输出变量为是否存在狗,输入变量为背景状态(是否为草地)和狗的形态特征(如是否存在狗鼻子、狗眼睛);要判断某个输入变量是否和输出变量有因果关系,则需要控制另一个输入变量的值(比如选取所有包含狗形态特征的图片,判断背景是否为草地和存在狗的结论之间是否有因果性)。
我们认为,可以通过干扰变量平衡(Confounder Balancing)的方法来使得神经网络模型能够推测因果关系。具体而言,如果要推断变量A对变量B的因果关系(存在干扰变量C),以变量A是离散的二元变量(取值为0或1)为例,根据A的值将总体样本分为两组(A=0或A=1),并给每个样本赋予不同的权重,使得在A=0和A=1时干扰变量C的分布相同(即D(C|A=0) = D(C|A=1),其中D代表变量分布),此时判断D(B|A=0) 和D(B|A=1)是否相同可以得出A是否与B有因果关系。
更进一步地,神经网络模型的输入往往包含多个变量,我们希望找到一组样本权重,使得所有变量之间都可以做到互相独立,即任意选取一个变量为目标变量,目标变量的分布不随其它变量的值的改变而改变。从理论上来说,可以证明在样本量足够大的前提下找到这样一组样本权重是可行的(引用)。在有限样本量的前提下,假设输入变量全部为二元变量(值为0或1),可以尽可能降低图5左图的算式取值,使得样本各变量之间尽可能独立。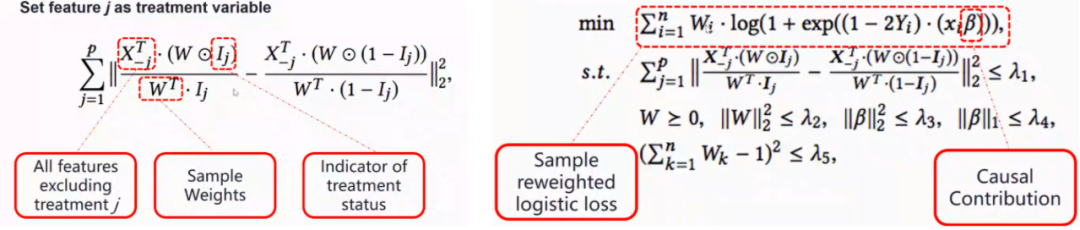 图5:样本变量之间独立性函数(图左);神经网络优化算式(图右)
图5:样本变量之间独立性函数(图左);神经网络优化算式(图右)
而在满足图5左式足够低的情况下,优化神经网络的损失函数(图5右)即可以得到依赖因果性特征的神经网络模型。
我们在NICO(Non-I.I.D Image Dataset with Contexts)数据集下测试以上方法的有效性。NICO是一个用于测试模型图像识别性能的数据集,它不仅有图片和其对应的种类,并且提供了同一种物体在不同环境下的不同图片(图6)。将在指定环境下的图片用作训练集,将同物体的不同环境下的图片用作测试集可以测试模型在不同环境下的性能稳定性。 图6:NICO 数据集中不同的类别和环境
图6:NICO 数据集中不同的类别和环境
实验结果表明,我们给出的方法在NICO数据集上的表现明显好于传统方法(图7左),且训练集和测试集的环境差异越多同时可视化分析显示基于因果性的神经网络模型更多借助物体本身的特征,而传统神经网络方法依赖于物体背景等非因果关联的特征(图7右)。总体而言,基于因果性特征的模型在未知环境下的表现更稳定。
图7:训练集和测试集的图片差异大小和因果性网络性能提升(图左),其中红色条柱代表训练集和测试集的差异大小,蓝色折线代表因果性网络相比于传统神经网络的性能提升(百分比)。可视化显示网络依赖的特征(图右),其中红框标出因果性网络利用的特征,绿框标出传统网络利用的特征。
4. 对连续性输入变量的稳定学习和稳定学习的优化
上文的优化方式仅仅适用于二元离散变量,我们同样提出了可以在连续性输入变量下训练的优化方程(图8)。实验表明在连续输入的环境下,基于因果性的模型在各种不同的环境下表现更为稳定,测量可得其准确率在各个环境下的方差更小(图9)。
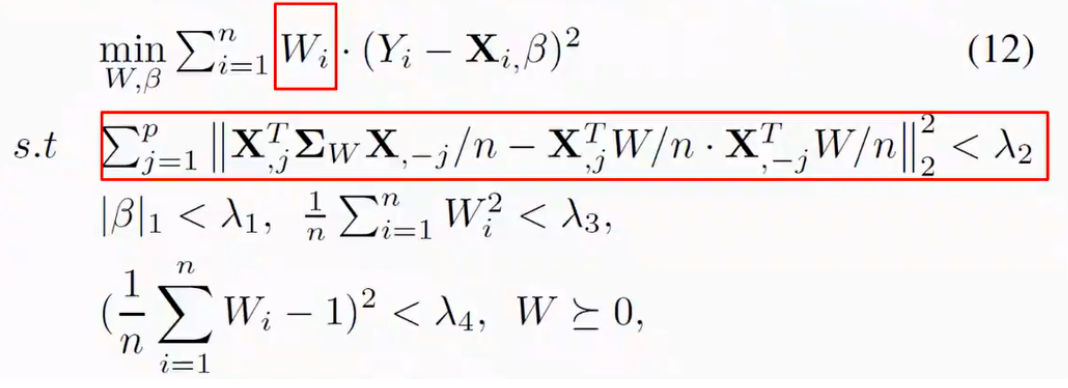 图8:对连续性输入变量的损失函数和限制条件
图8:对连续性输入变量的损失函数和限制条件
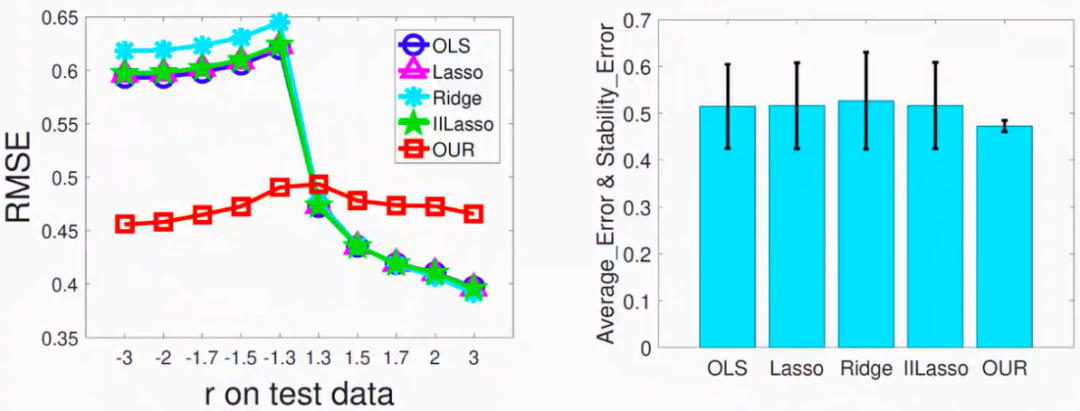 图9:因果性模型和其它网络模型在不同环境下性能的比较,左图横轴代表不同的环境,纵轴代表误差,不同颜色代表不同的模型。右图横轴代表不同的模型,纵轴代表在不同环境下的平均错误,性能的方差在条柱顶端用黑实线标出。
图9:因果性模型和其它网络模型在不同环境下性能的比较,左图横轴代表不同的环境,纵轴代表误差,不同颜色代表不同的模型。右图横轴代表不同的模型,纵轴代表在不同环境下的平均错误,性能的方差在条柱顶端用黑实线标出。
更进一步地,导致模型依赖于相关,但无因果关系的变量的原因是因果性变量和相关性变量之间的相关性,从而导致模型依赖仅有相关性的变量使得性能不稳定。但是因果性变量之间的相关性以及相关性变量之间的相关性并不会导致模型性能的不稳定。通过将输入变量进行聚类,将变量分为相关性变量和因果性变量,这使得在平衡干扰变量时只需要保证相关性变量和因果性变量之间独立即可。如前文所述,样本量越大,理论上可以保证变量之间的独立性越强;而通过减小需要保证独立的变量数量,可使得在给定固定样本量的前提下保证变量之间的独立性更强,更有助于模型在各种环境下的表现稳定。
本文基于神经网络模型在高风险领域的应用实践,深入探讨了稳定性问题在模型应用过程中产生的影响,并据此提出了利用因果性特征训练模型的解决方案。人工智能的稳定性,泛化性,和在人类生产生活中至关重要的领域的可用性,将会是学界在很长一段时间的重要研究方向;基于因果性特征的模型训练丰富了对这一问题的探索与实践,为解决这一问题提供了新的思路和视角。
参考文献1. Yue He, Zheyan Shen, Peng Cui. Towards Non-I.I.D. Image Classification: A Dataset and Baselines. Pattern Recognition, 2020.2. Zheyan Shen, Peng Cui, Kun Kuang, Bo Li, Peixuan Chen. Causally Regularized Learning with Agnostic Data Selection Bias. ACM Multimedia, 2018.3. Kun Kuang, Peng Cui, Susan Athey, Ruoxuan Xiong and Bo Li. Stable Prediction across Unknown Environments. KDD, 2018.4. Zheyan Shen, Peng Cui, Tong Zhang, Kun Kuang. Stable Learning via Sample Reweighting. AAAI, 2020.5. Zheyean Shen, Peng Cui, Jiashuo Liu, Tong Zhang, Bo Li and Zhitang Chen. Stable Learning via Differentiated Variable Decorrelation. KDD, 2020.6. Kun Kuang, Ruoxuan Xiong, Peng Cui, Susan Athey, Bo Li. Stable Prediction with Model Misspecification and Agnostic Distribution Shift. AAAI, 2020.7. Jiashuo Liu, Zheyan Shen, Peng Cui, Linjun Zhou, Kun Kuang, Bo Li, Yishi Lin. Stable Adversarial Learning under Distributional Shifts. AAAI, 2021.
录播地址
 https://campus.swarma.org/course/2323?from=wechat
https://campus.swarma.org/course/2323?from=wechat
推荐阅读
借助因果推断,更鲁棒的机器学习来了!因果科学:连接统计学、机器学习与自动推理的新兴交叉领域PC算法:缺失数据下的因果发现
加入集智,一起复杂!
点击“阅读原文”,追踪复杂科学顶刊论文
微信扫一扫,分享到朋友圈











