前沿综述:联邦学习在医疗中的应用

导语
联邦学习(Federated learning)可通过中央服务器,在保证数据隐私性的前提下,使用分散在各地的数据,训练机器学习/深度学习模型。从而在遵守隐私保护法律的前提下,通过协作建模,提升机器学习的效率。其在智能零售、金融、自动驾驶等领域已有广泛应用。最近一篇综述文章概述了联邦学习的基本概念及其在生物医学领域的应用场景,本文是对该综述的简介。

郭瑞东 | 作者
赵雨亭 | 审校
邓一雪 | 编辑

论文题目:
Federated Learning for Healthcare Informatics
论文地址:
https://link.springer.com/article/10.1007/s41666-020-00082-4
1. 为什么需要联邦学习
1. 为什么需要联邦学习
2. 联邦学习的定义
2. 联邦学习的定义
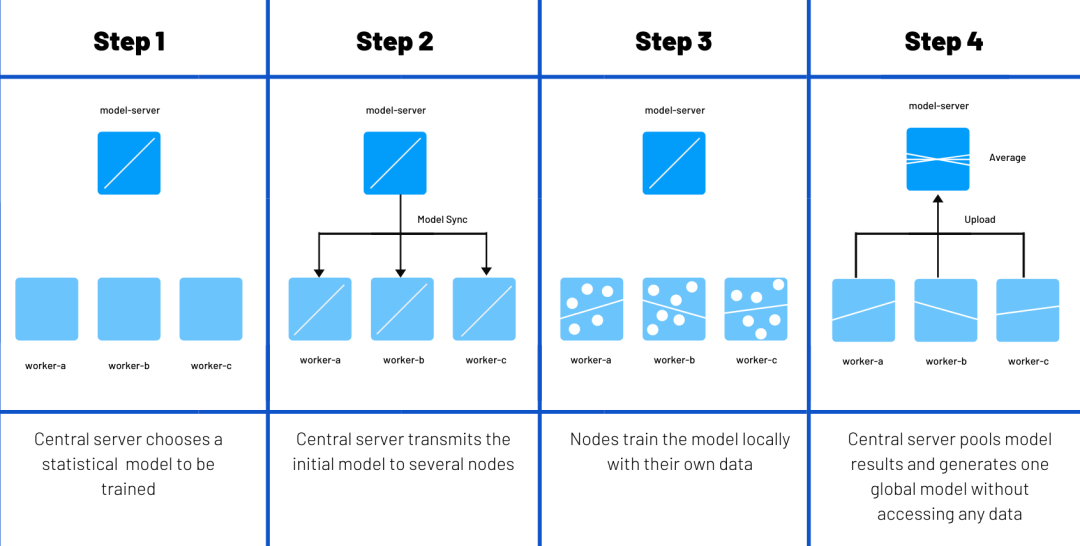 图1. 联邦学习的四个步骤丨图片来源:维基百科
图1. 联邦学习的四个步骤丨图片来源:维基百科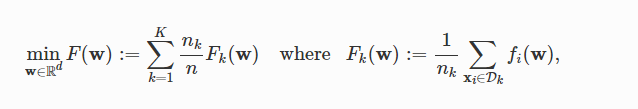
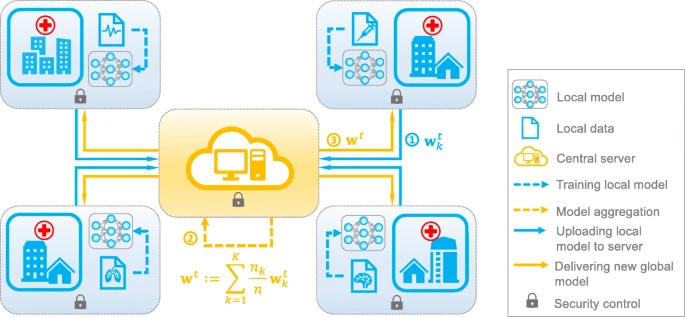 图2. 联邦学习框架示意图。该模型以分布式方式进行训练:各客户端定期与中央服务器通讯,以便在更新后的全局参数上进行优化;中央服务器汇总更新,并将更新的全局模型的参数发送回来
图2. 联邦学习框架示意图。该模型以分布式方式进行训练:各客户端定期与中央服务器通讯,以便在更新后的全局参数上进行优化;中央服务器汇总更新,并将更新的全局模型的参数发送回来
3. 联邦学习面临的三个挑战
3. 联邦学习面临的三个挑战

图3. 四种应对联邦学习通讯上挑战的方法:分别是模型压缩、客户端筛选、减少更新频次、P2P学习(不引入中心节点)
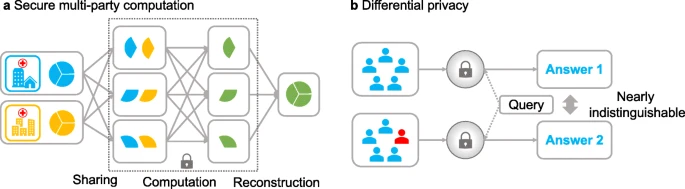 图4. 可信多来源计算和差分隐私示意图
图4. 可信多来源计算和差分隐私示意图
4. 联邦学习在医学界的应用案例
4. 联邦学习在医学界的应用案例
1)电子病例相似性搜索:例如[4]中提出的跨机构的病人相似性学习。他们的模型可以在不共享于患者相关的个人信息的情况下,在多家医院间寻找的相似症状的患者。
2)病人表征学习:[5] 描述了从文档格式的病例中进行特征提取,在不需要获取各个医疗机构的病例数据时,能够从电子病例中提取出超重这一影响健康的因素。
3)SplitNN[6]:一个能够在不共享敏感的原始数据或模型细节的前提下,促进医疗机构协作训练深度学习模型的框架。
4)社区特异性模型:针对不同来源的数据有着不同的分布这一问题,[7]将病人聚集到多个有临床意义的社区中,捕获相似的诊断和地理位置间的关系,同时为每个社区培训一个模型。
5. 总结:
联邦学习在医疗领域应用需解决的困难
5. 总结:
联邦学习在医疗领域应用需解决的困难
1. Mohri M, Sivek G, Suresh AT (2019) Agnostic federated learning. In: Chaudhuri K, Salakhutdinov R (eds) Proceedings of the 36th International conference on machine learning, proceedings of machine learning research, vol 97. PMLR, Long Beach, pp 4615–4625
2. Li T, Sanjabi M, Smith V (2019) Fair resource allocation in federated learning. arXiv:1905.10497
3. Obermeyer Z, Powers B, Vogeli C, Mullainathan S (2019) Dissecting racial bias in an algorithm used to manage the health of populations. Science 366(6464):447–453
4. Lee J, Sun J, Wang F, Wang S, Jun CH, Jiang X (2018) Privacy-preserving patient similarity learning in a federated environment: development and analysis. JMIR Medical Informatics 6(2):e20
5. Liu D, Dligach D, Miller T (2019) Two-stage federated phenotyping and patient representation learning. arXiv:1908.05596
6. Gupta O, Raskar R (2018) Distributed learning of deep neural network over multiple agents. J Netw Comput Appl 116:1–8
7. Huang L, Liu D (2019) Patient clustering improves efficiency of federated machine learning to predict mortality and hospital stay time using distributed electronic medical records. arXiv:1903.09296
复杂科学最新论文
集智斑图顶刊论文速递栏目上线以来,持续收录来自Nature、Science等顶刊的最新论文,追踪复杂系统、网络科学、计算社会科学等领域的前沿进展。现在正式推出订阅功能,每周通过微信服务号「集智斑图」推送论文信息。扫描下方二维码即可一键订阅:

推荐阅读
-
Cell 长文综述:机器学习如何助力网络生物学 -
扛鼎之作!Twitter 图机器学习大牛发表160页论文:以几何学视角统一深度学习 -
AI经济学家:强化学习如何促进市场平等并提升生产效率 -
加入集智,一起复杂!
点击“阅读原文”,追踪复杂科学顶刊论文
微信扫一扫,分享到朋友圈











