社区揭示了其成员不同于网络中其他社区成员的特征和联系。在网络分析中,社区发现具有重要意义。除了经典的谱聚类和统计推断方法,凭借处理高维网络数据方面的优势, 用于社区发现的深度学习技术近年来有了显著的发展。本文针对基于深度学习的社区发现技术的最新进展提出了一种新的分类方法,包括基于深度神经网络的深度学习模型、深度非负矩阵分解和深度稀疏滤波。在本文中作者将深度神经网络进一步细分为卷积网络,图注意网络,生成对抗网络和自编码器。在实验设置方面,本文总结了流行的对比基准数据集、模型评估指标和开源实现项目。本文讨论了社区发现在各个领域的实际应用,并提出了实现方案。最后,作者提出了这一快速发展的深度学习领域中具有挑战性的课题,并概述了该领域未来的发展方向。

论文题目:
A Comprehensive Survey on Community Detection with Deep Learning
论文网址:
https://arxiv.org/pdf/2105.12584.pdf
近日,澳大利亚麦考瑞大学计算机学院人工智能与数据科学实验室联合中科院数学与系统科学研究所、武汉大学、澳大利亚 CSIRO 实验室、天津大学、伊利诺伊大学芝加哥分校共同发表了题为「A Comprehensive Survey on Community Detection with Deep Learning」的综述论文,该论文是对该团队于 IJCAI 2020 上发表的论文「Deep Learning for Community Detection: Progress, Challenges and Opportunities」的扩展,详细综述了基于深度学习的社区发现最新研究进展。
据 2022 年 QS 世界大学排名显示,麦考瑞大学位列全球第 200 名,而其计算机与信息系统专业位列全球 151-200。
早在上世纪 20 年代,社会学领域的科学家们就对「社区」展开了研究。然而,直到 21 世纪,研究者们才真正开始借助强大的数学工具和大数据处理技术来解决社区发现任务中的难题。在过去的 10 年间,计算机科学家们通过利用网络拓扑结构和实体语义信息,对不同规模大小的静态、动态网络中的社区发现问题展开了广泛研究。越来越多的基于图的方法被提出,用于在具有复杂数据结构的环境中进行社区发现。通过社区发现,我们可以详细分析社区在网络中的动力学和影响(例如,谣言传播、病毒爆发、肿瘤演化)。
图 1:(a)社交网络图结构示意图,节点代表社交网络中的用户,边代表用户之间的联系;(b)基于用户职业预测的社区 和
和 。预测过程使用了用户在线活动中的亲密度(拓扑关系)和账号的属性(节点特征)。
近年来,社区发现技术的意义逐渐得以凸显。正所谓「物以类聚,人以群分」,我们所处的世界是一个由一系列社区形成的巨大网络。如图 1 所示,通过发现社交网络中的社区,平台运营者可以向目标用户推荐商品。
对于一些小型的网络和简单的场景,研究人员已经发展出了一系列基于谱聚类、统计推断等传统技术的社区发现方法。然而,由于计算及存储空间成本巨大,他们并没有将该任务扩展到大型网络或具有高维特征的网络上。在现实世界的网络中,大量的非线性结构信息使传统的模型并不能够很好地适用于实际应用。因此,我们需要发展出具有良好计算性能的更强大的技术。如今,针对这一问题,深度学习给出了最为灵活的解决方案,理由如下:
(1)深度学习模型可以学习非线性网络属性(例如:节点之间的关系)。
(2)深度学习模型给出了一种低维的网络表征,这种表征保留了复杂的网络结构。
(3)深度学习模型在利用各类信息发现社区的任务中取得了更好的性能。
本文旨在从以下方面帮助研究人员和从业者了解社区发现领域的过去、现在和未来的趋势:
。预测过程使用了用户在线活动中的亲密度(拓扑关系)和账号的属性(节点特征)。
近年来,社区发现技术的意义逐渐得以凸显。正所谓「物以类聚,人以群分」,我们所处的世界是一个由一系列社区形成的巨大网络。如图 1 所示,通过发现社交网络中的社区,平台运营者可以向目标用户推荐商品。
对于一些小型的网络和简单的场景,研究人员已经发展出了一系列基于谱聚类、统计推断等传统技术的社区发现方法。然而,由于计算及存储空间成本巨大,他们并没有将该任务扩展到大型网络或具有高维特征的网络上。在现实世界的网络中,大量的非线性结构信息使传统的模型并不能够很好地适用于实际应用。因此,我们需要发展出具有良好计算性能的更强大的技术。如今,针对这一问题,深度学习给出了最为灵活的解决方案,理由如下:
(1)深度学习模型可以学习非线性网络属性(例如:节点之间的关系)。
(2)深度学习模型给出了一种低维的网络表征,这种表征保留了复杂的网络结构。
(3)深度学习模型在利用各类信息发现社区的任务中取得了更好的性能。
本文旨在从以下方面帮助研究人员和从业者了解社区发现领域的过去、现在和未来的趋势:
-
系统的分类和全面的回顾
-
丰富的资源和具有高影响力的引用文献
-
未来的研究方向
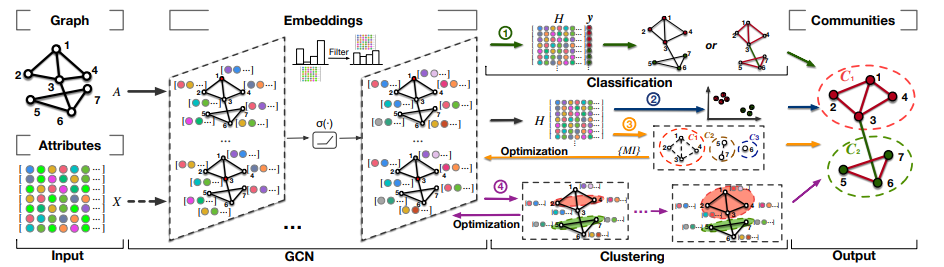
基于深度学习的社区发现模型将网络结构和节点特征、有符号的边等特征信息作为输入。网络结构通过节点和边代表拓扑关系,边上的权重代表连接强度。节点属性代表节点的语义信息(例如,在线社交网络中的用户账号属性),有符号的边代表连接状态。通常而言,社区发现模型会输出一组将节点和边聚合起来的社区。如图 2 所示,这些社区可能不相交也可能重叠。
社区发现是网络分析和数据挖掘领域的重要技术。图 3 展示了社区发现技术的传统方法和深度学习方法的发展历程。传统方法基于网络结构来探索社区,这些方法可以被分为如图 4 左侧所示的 7 大类,它们只能以直接的方式获取到浅层的联系。这些传统方法的社区发现结果往往是次优的。而深度学习方法则可以揭示深层次的网络信息和复杂关系,并处理高维数据。
此类方法也被称为图聚类,它将网络划分为 k 个社区。聚类簇中的边要比聚类簇之间的边更为稠密。代表性的算法包括:Kernighan-Lin 启发式方法、谱二分法等。此类方法在深度学习方法中仍然被使用。
代表性的算法为随机块模型(SBM),这是一类被广泛使用的生成式模型,它将节点分配到社区中,并控制它们的似然概率。其变体包括:DCSBM、MMB、OSBM 等。
此类方法通过「分裂式」、「凝聚式」和「混合式」三种方式发现不同层次上的社区结构。Girvan-Newman(GN)算法通过分裂式方法依次删除网络中的边从而发现新的社区,输出一种关于社区结构的层次化树状表征。FastQ 是一种凝聚式算法,它逐渐将节点合并为一个社区。CDASS 算法同时应用了分裂式和凝聚式策略,基于结构相似度对图进行划分,并将其合并为层次化的社区。
随机游走利用随机游走器在一段较短的游走中陷入某个社区的趋势,是最常见地被用于社区发现任务的动力学方法。代表性的算法包括:WalkTrap、InfoMap、LPA、LPAm。
网络的谱属性可以被用于社区发现任务。谱聚类基于邻接矩阵派生的网络归一化拉普拉斯矩阵划分节点,并且使用伪似然算法将划分结果拟合到 SBM 算法上。
此类方法的代表性算法包括:DBSCAN、SCAN、LCCD。它们通过测量实体密度来确定社区、社区边界和异常。
社区发现方法利用优化算法来达到某个极值,通常期望最大化的该值表明社区的似然。最经典的优化函数为 Modularity(Q) 及其变体。它们被用来估计网络划分得到的社区结构。此外,Louvain 是另一种著名的优化算法,它采用节点移动策略提取具有更大网络模块度的社区结构。此外,贪婪优化方法还包括模拟退火、极值优化、以及谱优化。对于局部学习和全局搜索而言,有效的演化社区发现方法分为「单目标优化」和「多目标优化」。多智能体遗传算法(MAGA-Net)等单目标优化算法利用了模块度函数,而 Combo等算法则融合了归一化互信息(NMI)、Conductance在内的多个优化目标。CE-MOEA 算法基于非支配排序遗传算法(NSGA-II)来优化模块度和相似性目标。
尤其是在大型复杂网络中,深度学习方法可以更好地利用节点、邻域、边、子图的高维非线性特征和高度相关的特征,并且可以编码数据特征。此类模型对于高度稀疏的网络更加灵活适用,对现实世界中的无监督学习任务有更好的适应性。
如图 4 所示,作者将基于深度学习的社区发现方法分为了六大类:
卷积网络是一种为网格式拓扑数据提出的前馈深度神经网络(DNN),其中卷积层降低了计算成本,而池化操作保证了 CNN 在特征表达上的鲁棒性。图卷积网络(GCN)是基于CNN 和图的局部谱滤波器的一阶近似提出的用于图结构数据的卷积网络。
现有的基于 CNN 的社区发现方法在实现 CNN 类模型时,严格限制其输入为图像格式的数据,并且是有标签数据。因此,这些方法需要对其输入进行预处理:(1)将网络样本映射为图像数据格式(2)由于大多数现实世界的网络都没有标签,所以需要提前手动标记节点或社区。图 5 展示了基于 CNN 的社区发现方法的总体框架。
图 5:基于 CNN 的社区发现总体框架。主要的变体包括:TIN、ComNet-R 等。
由于 CNN 只能将类似于图像的网格数据作为输入,因此我们首先需要在节点或边的层面上对网络数据进行预处理。我们通过多个 CNN 隐层对 d 维隐藏特征进行卷积映射。最终通过全连接层输出每个节点或每条边的特征表示,并用于分类。就节点而言,图 5 中的工作流1将社区分类为 k 类,具有相同标签的节点会被划分到同一个社区中;就边而言,工作流2将边分为 2 类(即社区内的边、社区间的边)。在训练过程中,通过删除社区间的边形成社区结构,并且将其反向传播回 CNN 嵌入进行优化,从而得到最佳的度量结果。
GCN 在深度图卷积层中聚合节点的邻域信息,从全局上捕获用于社区发现的复杂特征。基于GCN 的社区发现方法有两类:
(2)基于无监督网络表示的社区聚类。社区分类方法受到现实世界中缺乏标签的限制。相比之下,通过矩阵重构和目标优化等技术,网络表示可以更灵活地对社区进行聚类。
图 6:基于图卷积神经网络的社区发现总体框架。主要的变体包括:LGNN、MRFasGCN、CommDGI、NOCD 等。
该任务的输入为图结构(A)和可获取的节点特征(X)。通过多个 GCN 层,基于社区发现的需求对图潜在特征进行平滑(信息聚合)处理。 (·)为图表示学习的激活函数。如图 6 所示,在4条工作流中,工作流1 和 2 使用了最终的节点表示,而 3 和 4 号框架则使用了隐层中的特征表示。给定节点标签,工作流1 基于节点分类结果划分社区;工作流2 基于嵌入 H 对节点进行聚类;工作流3 通过互信息等评估手段进一步对嵌入进行优化,从而得到最佳的社区关系;工作流4 则同时优化聚类结果和节点表示。
基于图注意力网络的社区发现方法可以在复杂的网络场景下进行社区发现。如图 7 所示,GAT 通过可训练的权重聚合邻域内的节点特征,该权重通过考虑多种因素(尤其是对于具有多种关系类型的网络)的注意力计算而来。
图 7:基于图注意力网络的社区发现总体框架。主要的变体包括:DMGI、MAGNN。
GAT 在每个隐层 l 中为每个节点
(·)为图表示学习的激活函数。如图 6 所示,在4条工作流中,工作流1 和 2 使用了最终的节点表示,而 3 和 4 号框架则使用了隐层中的特征表示。给定节点标签,工作流1 基于节点分类结果划分社区;工作流2 基于嵌入 H 对节点进行聚类;工作流3 通过互信息等评估手段进一步对嵌入进行优化,从而得到最佳的社区关系;工作流4 则同时优化聚类结果和节点表示。
基于图注意力网络的社区发现方法可以在复杂的网络场景下进行社区发现。如图 7 所示,GAT 通过可训练的权重聚合邻域内的节点特征,该权重通过考虑多种因素(尤其是对于具有多种关系类型的网络)的注意力计算而来。
图 7:基于图注意力网络的社区发现总体框架。主要的变体包括:DMGI、MAGNN。
GAT 在每个隐层 l 中为每个节点 及其相连的节点
及其相连的节点 之间分配注意力系数(如图 7 中绿色、蓝色、紫色的箭头所示)。向量
之间分配注意力系数(如图 7 中绿色、蓝色、紫色的箭头所示)。向量 将聚合所有可以得到的信息:(1)multiplex 网络中同一对节点之间的多种关系(2)网络中的异构语义元路径。通过将对于社区结构的分析整合到 GAT 表征中,最后输出嵌入 H 用于对社区进行聚类。
图 8:基于生成对抗网络的社区发现总体框架。主要的变体包括:JANE、ProGAN、CommunityGAN 等。
GAN 通过生成器
将聚合所有可以得到的信息:(1)multiplex 网络中同一对节点之间的多种关系(2)网络中的异构语义元路径。通过将对于社区结构的分析整合到 GAT 表征中,最后输出嵌入 H 用于对社区进行聚类。
图 8:基于生成对抗网络的社区发现总体框架。主要的变体包括:JANE、ProGAN、CommunityGAN 等。
GAN 通过生成器 生成人造样本 Z 来欺骗判别器
生成人造样本 Z 来欺骗判别器 。判别器将多层感知机(MLP)、图神经网络(GCN)等深度神经网络作用于表征上。因此,真实样本和人造样本会通过竞争博弈进行调优,从而得到最优的社区特征。GAN 中使用的真实样本包括:
(3)节点嵌入
。判别器将多层感知机(MLP)、图神经网络(GCN)等深度神经网络作用于表征上。因此,真实样本和人造样本会通过竞争博弈进行调优,从而得到最优的社区特征。GAN 中使用的真实样本包括:
(3)节点嵌入 ;
(4)节点的社团归属
;
(4)节点的社团归属 。我们在表征中分析网络拓扑(三元组、派系、社区)或直接在 GAN 中分析它们。该方法在融合网络拓扑、属性和表征的过程中发现社区。
自编码器(AE)最常被用于无监督社区发现,通常被用到的 AE 变体包括栈式 AE、稀疏 AE、去躁 AE、卷积 AE、变分 AE。AE 可以描绘非线性的、带噪声的真实世界网络,并生成平滑的表征。通用的 AE 架构由一个编码器和一个解码器组成。编码器将网络结构和可获取的语义信息映射到一个低维潜在空间中。解码器则根据编码得到的表示重构一个网络。
栈式 AE 在多个隐层中将一组 AE 堆叠起来,以更加灵活地处理丰富的输入。图 9 总结出 5 种具有代表性的工作流程,其分别考虑了静态图、动态图、跨域图、异构图中多种社区成员的信息。在 5 种工作流程中,都会使用成对约束和重建损失进行优化。
在工作流 1 中,其输入为拓扑结构,优化重建损失和 KL 损失,输出最终用于节点聚类的嵌入 Z。在工作流 2 中,输入为动态图的快照
。我们在表征中分析网络拓扑(三元组、派系、社区)或直接在 GAN 中分析它们。该方法在融合网络拓扑、属性和表征的过程中发现社区。
自编码器(AE)最常被用于无监督社区发现,通常被用到的 AE 变体包括栈式 AE、稀疏 AE、去躁 AE、卷积 AE、变分 AE。AE 可以描绘非线性的、带噪声的真实世界网络,并生成平滑的表征。通用的 AE 架构由一个编码器和一个解码器组成。编码器将网络结构和可获取的语义信息映射到一个低维潜在空间中。解码器则根据编码得到的表示重构一个网络。
栈式 AE 在多个隐层中将一组 AE 堆叠起来,以更加灵活地处理丰富的输入。图 9 总结出 5 种具有代表性的工作流程,其分别考虑了静态图、动态图、跨域图、异构图中多种社区成员的信息。在 5 种工作流程中,都会使用成对约束和重建损失进行优化。
在工作流 1 中,其输入为拓扑结构,优化重建损失和 KL 损失,输出最终用于节点聚类的嵌入 Z。在工作流 2 中,输入为动态图的快照 ,然后使用与(1)中相同的栈式 AE 嵌入过程。基于当前嵌入和前一时刻嵌入的时序平滑性进行聚类,从而集成与前一时刻相似的社区结构。在工作流 3 中,输入为拓扑结构和节点属性,使用两个栈式 AE 对这些属性进行表征,并同时使用重建损失优化由拓扑结构得到的嵌入和由节点属性得到的嵌入。在工作流 4 中,将源域节点对的相似度信息迁移到目标域中。为了分析跨域的关系,通过同时在两个域上最小化可训练变量的损失,旨在最小化源域和目标域嵌入的 KL 损失。在工作流 5 中,输入为不同元路径中对齐后的图,以及图 i 和图 j 之间的锚链接矩阵
,然后使用与(1)中相同的栈式 AE 嵌入过程。基于当前嵌入和前一时刻嵌入的时序平滑性进行聚类,从而集成与前一时刻相似的社区结构。在工作流 3 中,输入为拓扑结构和节点属性,使用两个栈式 AE 对这些属性进行表征,并同时使用重建损失优化由拓扑结构得到的嵌入和由节点属性得到的嵌入。在工作流 4 中,将源域节点对的相似度信息迁移到目标域中。为了分析跨域的关系,通过同时在两个域上最小化可训练变量的损失,旨在最小化源域和目标域嵌入的 KL 损失。在工作流 5 中,输入为不同元路径中对齐后的图,以及图 i 和图 j 之间的锚链接矩阵 。对于每一个,最小化 2-范数损失
。对于每一个,最小化 2-范数损失 ,所有的损失都被施以了栈式 AE 权重。
非负矩阵分解旨在将一个大矩阵分解成两个小的非负矩阵。该方法不仅具有高度的可解释性,而且适合发现如何将节点分配给社区。社区发现任务中应用到的基本的 NMF 模型将邻接矩阵 A 分解为两个非负矩阵 U 和 P。其中,U 对应于将原始网络映射到社区成员空间的矩阵。矩阵 P 中的每一列代表每个节点属于某个社区的概率。
在社区发现领域中,深度自编码器式非负矩阵分解(DANMF)是无监督学习环境下影响最大的模型。与传统的基于 NMF 的社区发现方法映射简单的社区成员不同,DANMF 使用 AE 框架在分层映射上进行网络重构。
尽管深度 NMF 提供了一种在形成社区的过程中映射多个变量的方案,但是其矩阵分解的计算成本相对较高。为此,研究者们提出了模块化的深度非负矩阵分解(MDNMF),直接将模块度应用于基本的多层深度学习结构中。
稀疏滤波是一种简单的双层学习模型,它可以处理高维的图数据,将高度稀疏的输入表征为低维特征向量。为了探索节点的社团归属等更深入的信息,深度 SF 将多个隐层堆叠起来,从而对更多超参数和大量的平滑数据分布进行调优,其代表性的算法为 DSFCD。
,所有的损失都被施以了栈式 AE 权重。
非负矩阵分解旨在将一个大矩阵分解成两个小的非负矩阵。该方法不仅具有高度的可解释性,而且适合发现如何将节点分配给社区。社区发现任务中应用到的基本的 NMF 模型将邻接矩阵 A 分解为两个非负矩阵 U 和 P。其中,U 对应于将原始网络映射到社区成员空间的矩阵。矩阵 P 中的每一列代表每个节点属于某个社区的概率。
在社区发现领域中,深度自编码器式非负矩阵分解(DANMF)是无监督学习环境下影响最大的模型。与传统的基于 NMF 的社区发现方法映射简单的社区成员不同,DANMF 使用 AE 框架在分层映射上进行网络重构。
尽管深度 NMF 提供了一种在形成社区的过程中映射多个变量的方案,但是其矩阵分解的计算成本相对较高。为此,研究者们提出了模块化的深度非负矩阵分解(MDNMF),直接将模块度应用于基本的多层深度学习结构中。
稀疏滤波是一种简单的双层学习模型,它可以处理高维的图数据,将高度稀疏的输入表征为低维特征向量。为了探索节点的社团归属等更深入的信息,深度 SF 将多个隐层堆叠起来,从而对更多超参数和大量的平滑数据分布进行调优,其代表性的算法为 DSFCD。
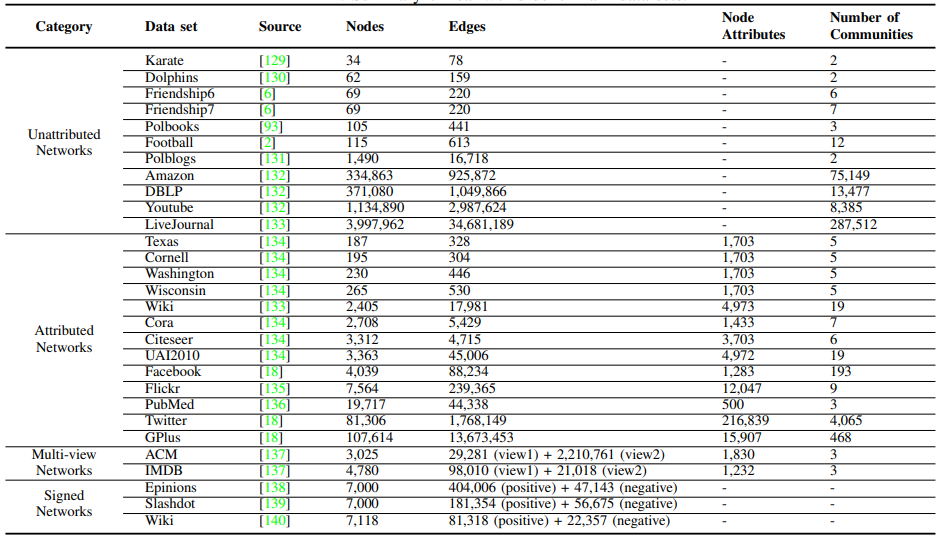
在本文中,作者总结了用于基于深度学习的社区发现研究的重要研究资源,包括对比基准数据集,评价指标,以及开源实现代码。
在社区发现领域,为了更好地测试方法的性能,通常会使用从实际应用中收集到的真实数据集,以及通过具体的模型生成的人工合成数据集。
目前最流行的真实数据集包括论文引用网络、社交网络、生物学网络、网页网络、产品购买网络等。被广为使用的合成对比基准数据集包括 Girvan-Newman(GN)网络,以及 Lancichinetti–Fortunato–Radicchi(LFR)网络。
如图 13 所示,社区发现技术已被应用于各种各样的任务和领域,例如:
(1)推荐系统:社区结构在基于图的推荐系统中起着至关重要的作用,通过检测节点之间的关系,模型可以产生高质量的推荐结果。
(2)生物化学:节点代表化合物和分子图中的蛋白质或原子,边代表它们之间的交互。社区发现可以识别在器官中起作用的新蛋白的免疫复合物、化合物,或疾病的病理因素。
(3)在线社交网络:分析在线社交活动可以识别在线社区,并将它们与现实世界联系起来。Facebook、Twitter 和 LinkedIn 等在线社交网络揭示了在线用户之间相似的兴趣,从而自动给出个人的偏好。同时,社区发现技术可以用于在线隐私保护,基于在线社会行为识别罪犯等场景。
(4)社区欺骗:为了绕开社区发现,我们可以通过社区欺骗技术覆盖 Facebook 等社交网络中的一组用户。有的社区欺骗活动对虚拟社区有害,也有的社区欺骗活动是出于正当利益的考虑。
(5)社区搜索:社区搜索旨在搜索依赖于社区结构的节点。例如,搜索用户所在兴趣社区的其他成员。
尽管深度学习极大促进了社区发现领域研究的繁荣,但是目前仍然存在许多有待解决的问题:
(1)未知的社区数量:现实世界中存在大量无标签数据,因此社区的数量是未知的。现有的无监督社区发现方法要求我们事先指定需要检测出的社区数量,而这往往是不可行的。我们需要使用一种有效的方法来处理这种由于缺乏知识而造成的情况。
(2)社区嵌入:传统的节点嵌入方法会保留直接相连或在低维空间中拥有许多共同邻居的节点,但是在学习过程中却很少利用社区结构。为此,社区发现需要引入能够感知社区结构的学习过程来表征社区信息。
(3)层次化网络:Web 等网络通常具有不同规模的社区的树状组织结构。因此,社区发现需要具有从低到高的层次化过程。
(4)多层网络:实体总是以多种方式进行交互,多层网络提供了一种通用的多层框架,将一组实体之间的多种交互类型表征为不同的网络层。我们需要适当考虑交互类型之间的差异、层间不同的稀疏度、层间可能的连接、以及方法在层数方面的可扩展性。
(5)异构网络:为了准确地描述现实,网络需要包含表征不同类型实体之间关系的异构信息。由于缺乏建模复杂结构和语义信息的能力,针对同构网络设计的社区发现方法往往不适用于异构网络。
(6)网络异质性:相连的节点也可能从属于不同的社区,或具有不相似的特征。对社区发现任务而言,跨社区相连的边界节点往往具有这种属性。捕获网络异质性可以为社区发现任务提供有价值的信息。
(7)拓扑不完备的网络:在现实场景下,并不一定总是能够获取节点之间的关系,因此网络的拓扑结构往往是不完整的。根据有限的拓扑信息获取有意义的社区知识对于这种情况至关重要。
(8)跨域网络:各个节点之间不同类型的交互可以用不同的网络(域)来描述。由于利用来自相关源域的丰富信息有助于提升网络学习的性能,我们可以开发深度学习模型,提升目标域社区发现任务的性能。
(9)多属性视图网络:现实世界中的网络比实验环境下的网络往往更加复杂。多属性识图网络提供了一种根据多个视图描述关系信息的视角,每个视图都包含一种节点属性。利用各个视图之间的互补性,可以提升社区发现的性能。
(10)带符号的网络:并不是所有连接关系都会使节点更接近。边的语义关系的区别可以用符号来刻画。由于正连接和负连接对节点的影响差异较大,以往在无符号网络上设计的社区发现方法并不适用。
(11)动态网络:网络不是静态的,而是随着网络结构和时序语义特征的急剧变化而演变的。深度学习模型应该快速捕获网络上发生的变化,以探索社区的演化情况。
(12)大规模网络:大规模网络可能包含数百万个节点、边和社区等结构模式。它们固有的尺度特征会影响深度学习模型在社区发现任务中的性能。可扩展性是深度学习在大规模网络环境中实现社区检测的关键问题。我们希望开发一种鲁棒而灵活的深度学习方法,从而实现高性能协同计算。
网络科学经过二十年蓬勃发展后,将进入了下一个关键的十年。在新的发展阶段,网络科学迫切需要更多数理人才的加入,为定量化地描述复杂系统的结构和动力学做出跨学科的努力。相信随着更多数学理论和工具的引入,网络科学必将能对更多的现象进行更贴合实际的建模和分析,预期会收获更丰盛的成果。
集智学园在 2021 年 2 月推出了网络科学集智课堂第二期,本期课程以《网络科学导论》教材为框架,邀请了陈关荣、项林英、樊瑛、宣琦、李翔、史定华、李聪、荣智海、周进、王琳十位网络科学专家作为导师,以网络动力学为核心,联系其与网络结构与功能的关系。从一个更加动态的视角看待和研究网络问题。
同时,我们会给学员充分发挥聪明才智、展示个人魅力并赢取奖学金的机会。鼓励学员申请领读书中的章节和相关论文,引领大家进行更深入细化的学习。
“集智课堂”的主旨就是集大家之智,涌个体之现,让每个参与者,从学员到教授都可以从这个课堂上受益。如果你对网络科学感兴趣,需要学习网络科学相关知识和技能,欢迎你加入我们!
课程目的
1. 初步构建较为完善的网络科学知识体系,为你的知识框架增加新的思维和分析工具;
3. 有意识地打造你自己的思维框架,梳理问题,提炼模型;
第一步:扫码付费
第二步:在课程详情页面,填写“学员登记表”
第三步:扫码添加助教微信,入群
点击“阅读原文”,即可报名