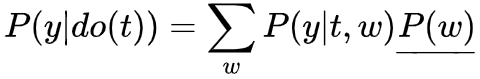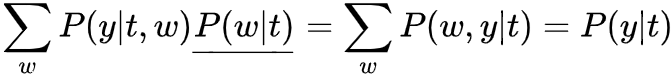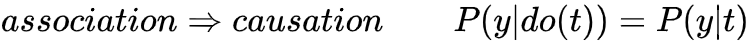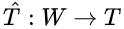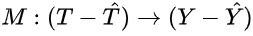统计因果推断近期在工业界应用越来越多,很多新人在这个快餐式、碎片化信息繁多且杂的时代,学习新知识渠道多,但难度更大。 情报搜集、整理并内化是当今必要的方法。
刚开始接触因果推断(其他比如量子机器学习),听到各种名词、方法,查阅包括请教身边的人,一段时间发现很多概念还是不够理解,系统性很弱,太过于碎片化,缺少方法论的联系,甚至不知道一些方法的优化点。这样对自己的理解非常不利,甚至阻碍自己思考和创新。
故此篇,针对新手,从整体框架的角度介绍因果推断的原理和一些常见方法论,并简单回顾工业界一些方法所处位置。本文目标用户为对概率论、概率图模型、因果推断感兴趣的新老手朋友
本文大纲 (这里假设一些基本知识和符号大家都了了解)
Causal Inference:目标、假设、框架 (复习回顾并总结框架)
Identification:backdoor、frontdoor criterion、 do-calculus
Conditional Outcome Modeling (COM、S-Learner)
Grouped COM (GCOM、T-learner)
Double Machine Learning (DML)
工业界因果推断应用:uplift、debias、可解释性
1. Causal Inference: 目标、假设、框架
研究目标变量T对结果变量Y的作用 (effect of T on Y) 之前介绍过基于Potential Outcomes基于{Y(1), Y(0)}表达计算causal effect,并说明了由于Fundamental Problem (Counterfactual) 导致个体效应ITE无法识别,所以计算总体平均水平ATE。并说明了为什么相关性 因果性,且介绍当满足哪些条件时,可以相关性⇒因果性,进而可以基于数据计算得到ATE。我们在此先做一个总结!
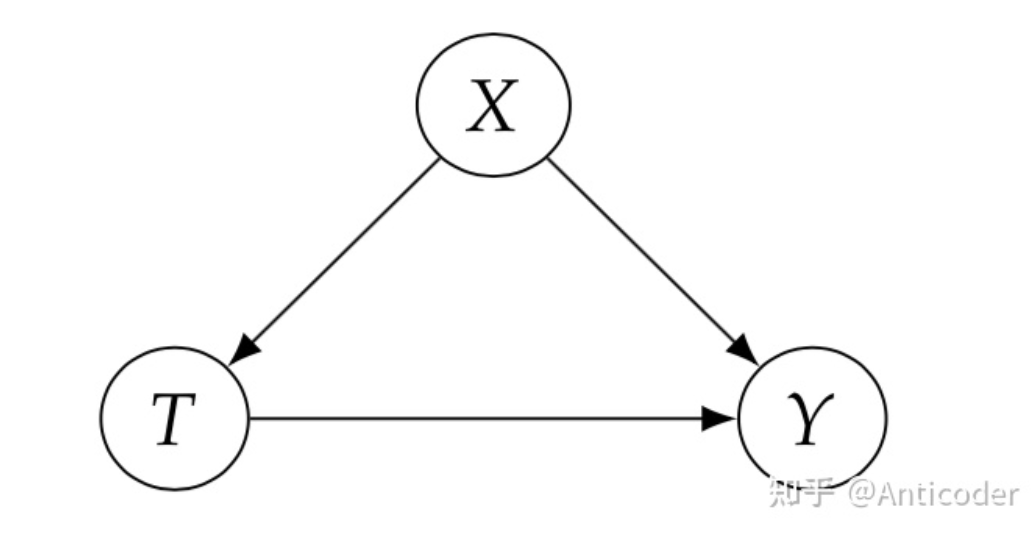
graphical example
简单描述一下,我们目标是计算average treatment effect (ATE) ,研究T对Y的因果效应。Y(t)是 potential outcome的简写,这是一个causal quantity,无法直接计算 (我们获取的数据都是计算statistical quantities的) 。之前也介绍过随机试验RCTs对于因果推断是神圣的!这也很好理解,但是一般很多原因 (比如伦理原因、可行性、资源利用等) 导致获取数据并非是随机的 (w.r.t T)。在这情况下,如果X完全描述了数据分配的关系 (sufficient adjustment sets) ,那我们还是可以一致且无偏估计ATE (consistent & unbiased) ,这里涉及一些研究时的假设 (目的是: Identifiability)
Unconfoundedness (conditional ignorability / conditional exchangeability)
明给定X时,potential outcome Y(t)与T无关,这步对于ATE非常关键,是上面公示第二行等号成立的条件!
conditional exchangeability 为 ,说明了Y(1)不论在treatment组还是control组期望是不变的,也说明了Y(t)与T无关
并且这个条件是无法测试的,想想为什么? [因为世界之大]
(且在部分概率推到中导致除0)
根据贝叶斯公式,这条假设也叫Overlap between P(X|T=1) & P(X|T=0)
如果某些变量违背此假设,叫positivity violation,某些情况下我们可以extrapolate,可以想想哪些情况下,可以外推呢? (比如门当户对时候)
Consistency
这里值得一提的是,Unconfoundedness 和 Positivity看起来是相互制约的tradeoff的假设,在文章最后我们再来讨论。 (希望能看到最后~) 从公式看到,我们开始估计的ATE为causal quantities,基于一系列假设最后得到一个statistical quantities,进而就可利用data进行数值计算!简单回顾完之前的东西,我们这里总结一下Causal Inference整体框架 介绍一些统计话术
Causal Inference整体框架:大致分为2步
Identification:我们感兴趣的是Causal Estimand (如ATE),但是没法直接计算(因为我们只能计算统计量),需要转化为statistical Estimand (统计量),这个过程叫Identification
Estimation:根据statistical Estimand,利用data进行估计的数值,这个过程叫Estimation
The Identification-Estimation Flowchart
接下来基于这个Causal Inference的框架流程,系统介绍一下原理与方法,帮你对整体与细节都有一定了解。
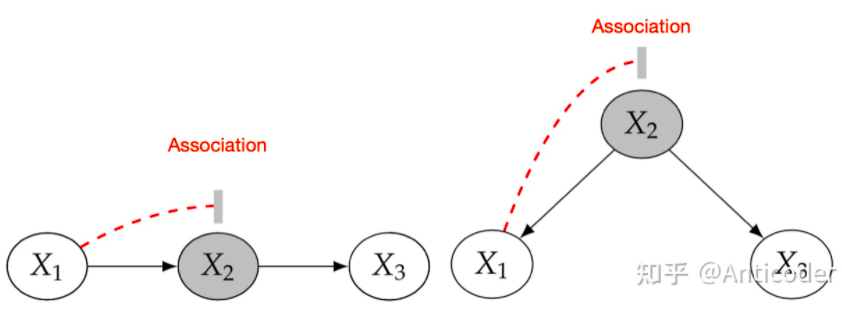
本节目的:介绍整体框架非常重要2步内容之前,先介绍一些Causal Model包括graph内容,因为根据之前介绍可以看出,我们计算ATE时使用了很多假设,这些假设是基于Causal Model而来,所以为了更好讲解Identification,必须先知道这些假设来由! (当然也可以跳过,影响不大,关注一下基础结构和d-seperation即可) graph model内容非常多,这里只介绍针对因果推断相关内容,包括如何表达intervention,及intervention分布等,Causal model一般为graph model (directed graph),先非常简单介绍一些相关且重要的graph model,具体细节以后再补充。 研究因果,通常我们期望的因果关系是非对称的,一般基于传统directed graph (Bayesian Network)建模,Bayesian graph提供了很多可用工具,比如简化概率建模的bayesian network factorization等,整个模型思路就是,基于概率图基础上再增加一些causal假设,可以进行causal的操作。 之前介绍中也提过,相关性 因果性 ,就是因为在研究过程中,我们不同的假设,对graph (DAG) 赋予了概率性 (independent & dependent) 和因果性 (dependent) ,通常的观测数据中既包含causal association也包含 non-causal association! 所以,给定图我们最关心就是那些association是如何flow的,这样我们就可以分离出来我们关系的causal association!DAG图中有三种基本结构,帮助我们分析: 首先介绍常用术语,在graph中,阻断了association称为block the path,否则unblock the path。在概率中我们block主要手段就是conditioning (这是一个非常general的话题,conditioning strategy连接并总结了matching和regression方法,以后再写) ,下面介绍基本结构
Chain:x1 2 3 ; Fork:x1 2 3
没有condition on x2 1 3 1 3
condition on x2
blocked path(左:chain 右:fork)
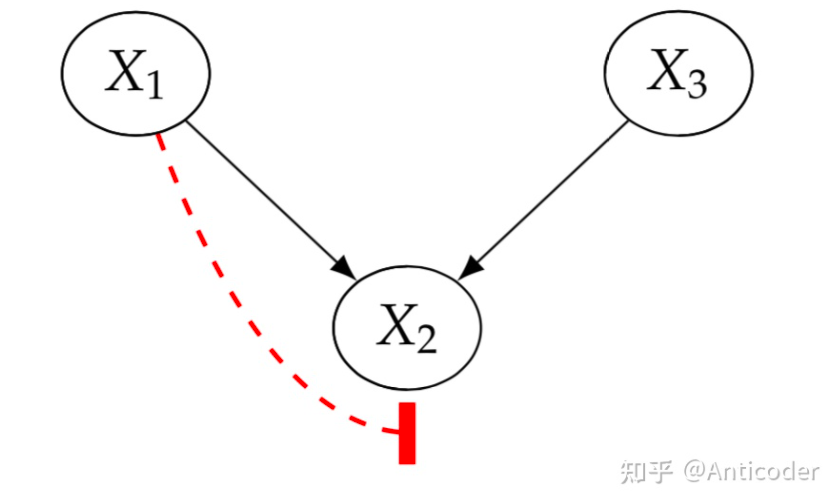
immorality (collider) : x 1 → x2 ← x3
这个结构正好与上面相反,没有condition on x2
condition on x2 2
这个直观上可以理解为:x2 1 3 2 1 3 2
blocked path for collider
基于三种基本结构和各自如何block the path,在任意graph中我们就可以知道association flows & blocked.
block chain和fork结构的中间节点
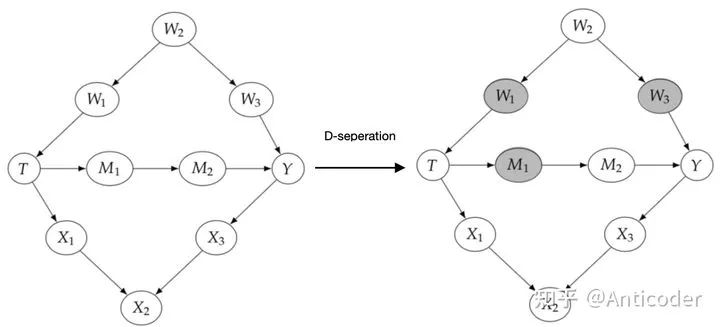
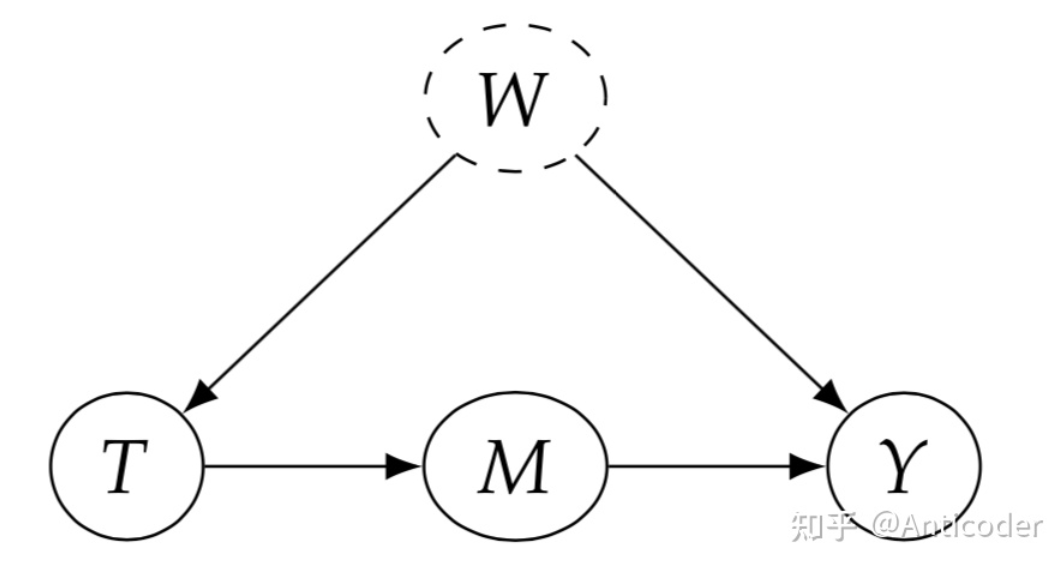
基于path block规则,再介绍一个经常见到的概念,d-seperation (X and Y are d-seperated by Z) ,是说condition on Z,block X到Y的全部path T and Y are d-seperated by W&M
之前介绍的贝叶斯图更多涉及statistics,基于此引入更多因果操作及假设,最终得以计算因果效应。之前介绍过因果模型相对于传统统计模型,最大的区别在于一个是研究干预 (intervention) ,还有就是研究反事实 (conterfactual) 。 首先介绍相对于intervening的表达do-operator,这是一个causal op,对应一个causal distribution (interventional distribution) ,因为是引入概率模型概念,我们可以对比分析。 核心区别在于统计分析是基于观测数据,可以conditioning操作对数据划分约束 (sub-population) ,属于被动分析;而因果推断希望主动获取数据,通过intervening操作干预数据分配 (whole-population) ,属于主动分析。
Interventional distribution:
用do(T=t)来表达我们强制用户进行treatment分配(T = t)
causal quantities (无法直接计算,需要识别(Identification)转化为统计量才能计算)
可以通过experimental (随机试验) 获取 (相对于statistical distribution P(X,Y,T), 可直接从data中获得)
ATE则为 一阶矩的差
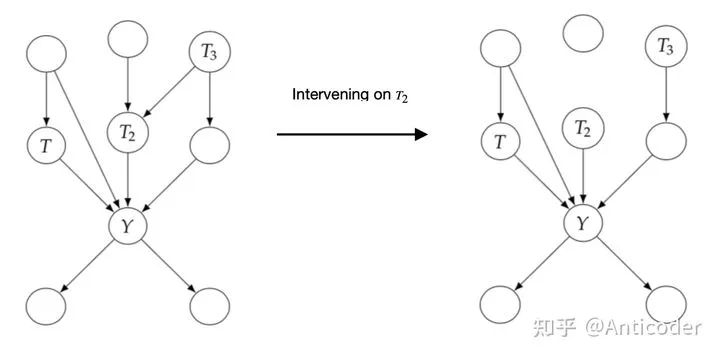
基于以上介绍,你可以对比 (含有do op) 为statistical estimand (不含do op) ! Causal Model就是基于graph获取信息 (Assumption) ,进而从graph中分离出causation,举个 (Assumption) 例子如下: 接下来介绍一个重要且直观的假设,Modularity Assumption,它为我们formalize interventional distribution提供了方法。这个假设也很直观,我们intervening on Xi ,则graph里面除了 改变,其他factor保持不变。 Modularity Assumption:Intervening on sets S, factor of variables i 2. 根据Baysian Network Factorization和Modularity Assumption,我们就可以写出interventional distribution的分布,得到truncated factorization (把干预变量因子替换0或1) 。 最后以一个例子看如何运用这些知识,目标为Identify
causal graph to manipulated graph
Bayesian Network Factorization:
Truncated Factorization:
Marginalize:
4. Identification: backdoor、
frontdoor criterion、 do-calculus
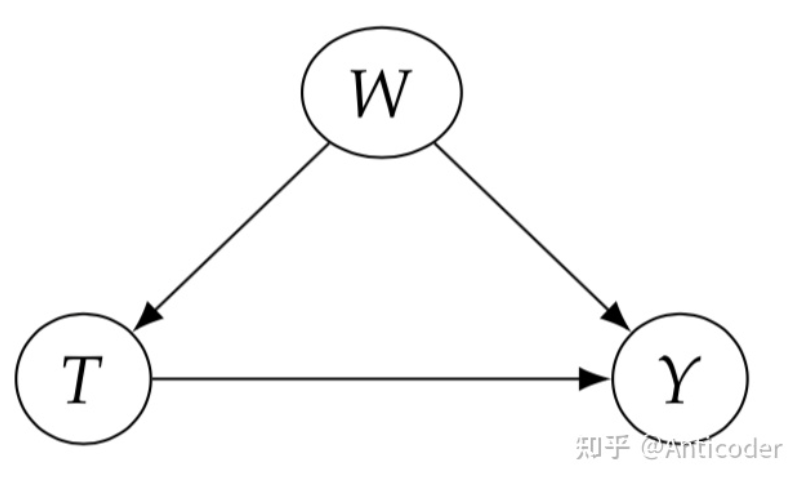
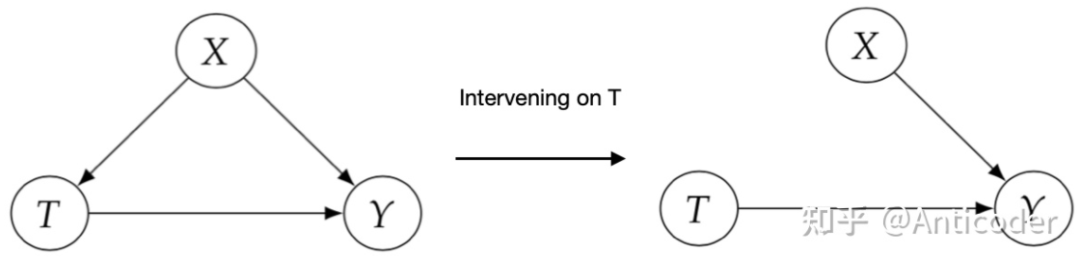
接下来介绍因果推断核心流程之一,Identification,值得一提的是,并不是所有的因果关系都是identifiable,其中有很多实现方法,这里介绍常用且直观的入门方法。 基于刚才的介绍,再回忆一下为什么随机试验 (RCTs) 对于因果推断如此神圣? 由此引出Identification的核心思路之前提到过,大部分基于观测数据的研究,因果图类似上面图左,通常存在confounder X (T并非随机) ,导致相关性 因果性 , 即 (intervening on T) 时,切断了T的in-coming edge,消除了confounder (block non-causal path) ,则可以直接进行因果计算!所以我们希望基于观测数据,模拟这个操作基于统计的conditioning that block the non-causal path,实现Identification!这些non-causal path为backdoor path。 值得多说的是,在一些经典领域比如社会经济医学等,常常提到balance the data,在conditioning strategy或者matching method等,我们说Identification通过balanced data实现,这里和其他篇幅写的comparable group对应,也是RCTs自带属性之一!即 Backdoor Path:我们研究T on Y的因果效应,backdoor path为那些T到Y且指向T的path,这些path为non-causal association,希望block分离出causation,结合之前介绍的graph中block path方法,得到第一个identification方法 backdoor adjustment. backdoor criterion: variable sets W satisfy 1. block all backdoor path 2. not contains descents of T. then W is called sufficient adjustment sets.
第二个等号中 的do(t)是因为W为sufficient adjustment set,切断了所有backdoor path,T->Y仅留下causation
第三个等号消除 的do(t)是因为 1. do(t)切断了T的parents,没有in-edge association流向T->W; 2. 如果存在association则为T 的 out-edge association,则会与Y形成一个collider,association 被 collider 切断。所以T与W独立!下面举个例子,
conditioning sets
回顾一下上面介绍的d-seperation,我们可以用d-seperation来表达backdoor path , 表达manipulated graph,删掉T outgoing edge。 值得一提的是,backdoor criterion中第二条,不要阻断T的子孙,这个直观来说就是别把T的效应提前阻断了,还有一种是基于SCMs来说明,SCMs本质也应该在Causal Model介绍,更多作用是在后面介绍counterfactuals时和存在unobserved variables使用,为了篇幅在这先不介绍了。 前面提过unconfoundedness是untestable的,也即存在unobserved variable为confounder,我们没法conditioning,这个时候backdoor adjustment就没法使用了,如下所示
这里核心点是,M承载了全部T -> Y的causation,我们通过focus on M来分离causation,实现frontdoor adjustment,主要由3步组成,总结如下。 frontdoor criterion: variable sets M satisfy 1. all causal path from T on Y through M 2. no unblocked backdoor path from T to M 3. T block all backdoor path from M to Y
step 1,T->M,没有backdoor path
step 2,M->Y,存在backdoor path M←T← W→ Y ,可以被T block
之前介绍backdoor、frontdoor adjustment都是很直观直接可以从causal graph中判断identifiable。同时也存在以上两种方法不能Identity的情况。这里我们介绍一个complete 方法,只要是identifiable的都可以通过do-calculus识别!下面进行介绍说明:
Rule 1:
描述在这种情况下,Z与Y独立,则可以消除condition on z
便于直观上理解,我们先把do(t) 删掉,得到 ,可以发现这个就是d-seperation,所以此为d-seperation在intenventional distribution推广
Rule 2:
描述在这种情况下,只有causation,则可以消除do(z)
同样便于直观上理解,我们把do(t) 删掉,得到 ,可以发现这个就是backdoor adjustment,所以此为backdoor adjustment在intenventional distribution推广
Rule 3:
Z(W)为variable sets Z中排除W祖先的那些
因为condition on W,存在Z为collider,容易block collider的子孙带来额外association,所以这里仅切掉Z(W)的incoming-edge
最后值得一提的是,do-calculus是Identification的充要条件 (可以识别的情况下) ,但它不是基于Graph的,有些方法可以直接从causal graph判断Identification。比如作为充分条件的unconfounded children criterion;充分必要条件hedge criterion,感兴趣可以自行阅读。
前面介绍完Causal Model和Identification,帮助我们把causal estimand转化为可以估计的statistical estimand,接下来我们就是计算的部分,如何用data来计算具体的casual effect的数值,这个过程就是Estimation。首先介绍一些常用的估计量,我们之前一直以ATE为例,实际观测数据中我们经常估计conditional ATE (CATE) ,有些研究可能只关注treatment或者control组的ATE,分别叫ATT和ATC (有些情况下ATE无法估计) ,我们以后有机会再细讲,这里先介绍常用的CATE 本小节默认假定unconfoundedness & positivity,即Identification成立,且CATE中X和covariates W都是sufficient adjustment sets. (X不需要all observed),接下来介绍常用方法。 Conditional Outcome Modeling (COM) 基于之前讨论我们得到ATE的识别为 右边式子只包含statistical quantities,是statistical estimand。estimation需要我们用data估计estimate。最直接的办法就是我们可以先使用statistical model或者ML model估计conditional expectation,之后进行样本估计。
step1: model conditional expectation:
step2: average over sample:
step1 :
step2: average over sample:
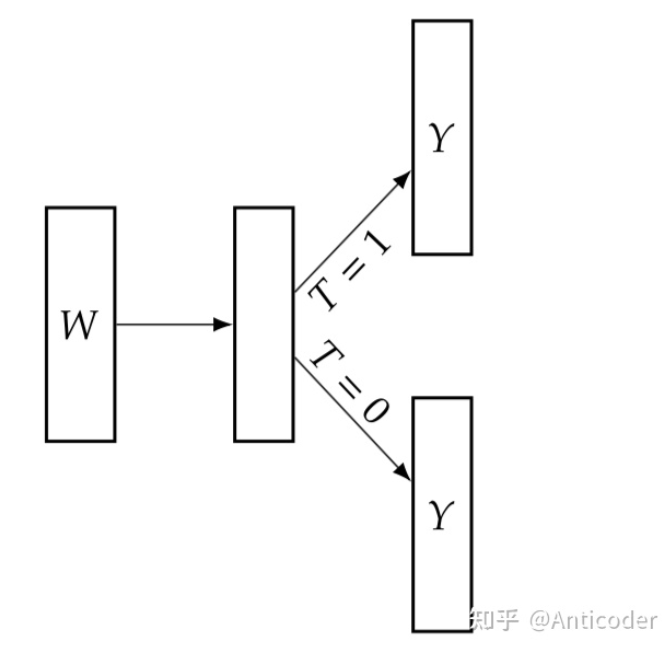
COM有很多其他名字,比如S-learner等,S代表singe model,表达对于treatment和control组使用的是同一个model。 存在问题:当数据纬度变大时,容易产生估计偏差 (estimate biased towards 0!) ,这个很直观,假设数据有100维,T只是其中1维,模型训练时容易忽略这个维度,导致计算出来ATE -> 0,进而引出Grouped COM。 GCOM引入为了解决COM中estimate biased towards to 0的问题,为了加强模型对T的权重,我们在估计 μ时 ,分别对treatment组和control组使用不同的模型,其他流程与COM一样,也常叫T-Learner。
model
model
step2: average over sample:
存在问题:每个estimator只使用部分数据,尤其当样本不足或者treatment、control样本量差别较大时,模型variance较大 (对数据利用效率低) ,我们需要提升数据利用率!进而引出接下来2个model TARNet和X-Learner。 借 鉴神经网络share-bottom结构,我们可以使用如下结构,增强数据利用。
可以发现,其实bottom结构参数使用了全部数据,但是head结构还是仅使用部分数据,数据利用率并不是最高的。这种结构在神经网络经常用到且问题不大,我猜主要原因是神经网络一般数据量都太大,这种问题可以忽略。 充分利用数据估计每个group的estimator,对于数据倾斜很严重的估计有很好的弥补作用。X-learner估计步骤如下:
step1 :Estimate ,这个和T-Learner一样,分别用treatment和control数据估计条件期望
2a. 针对treatment组, ;针对control组,
2b. 分别学习2个model 使用treatment组数据预测 , 使用control组数据预测
step3: 利用weight function 组合2个model 进行预测:
观察可以发现,X-Learner在step1中训练 时,与T-Learner一样仅使用treatment组数据但是在step2训练 时是基于 训练的,其中 使用control组的potential outcome ,所以在训练 时使用了全部的数据,同样训练 也是一样。 值得一提的是,paper说用g(x) propensity score效果不错;或者其他也行,一般数据量多的组权重给大一些;或者额外学习g(x),用以最小化模型方差等。 propensity score based的方法有很深的背景和思想,一定程度上从形式上解决了一些不可行的情况,这里我们简单介绍些基础,以后深入讨论。 propensity score定义为 ,衡量了在W=w下分配T=1的概率,直觉上如果W是sufficient adjustment sets且e(W)估计模型正确的,那e(W)包含了全部treatment assignment的信息,那我们仅通过e(W)就可以consistent & unbiased估计ATE了! Propensity Score Theorem ,则 这里有个很明显的好处是e(W)仅是一维的!记得开头我们使用potential outcome model识别ATE提到的两个核心假设unconfoundedness 和 positivity是一对tradeoff,因为我们考虑更多变量加入sufficient adjustment sets,则我们有更多的机会block all backdoor path,实现unconfoundedness,但是考虑的维度越高,我们实现positivity难度就越大 (维度灾难) ,样本稀疏度呈指数级增加! 既然维度灾难存在导致Identification的假设存在tradeoff,那是否基于propensity score就可以完美解决这个问题了?答案肯定是否定的!前面也提到e(W)指定正确的模型也是很关键的,这里只是把高维问题转化成了e(W)预估准确的问题,同样是棘手的问题! 这里值得一提的是,时常会有人把问题形式转化而认为问题得到解决,这是欠缺思考的!比如用ML预测金融市场难度大,而使用RL进行预测,或者简单更换不同的模型结构等等,No Free Lunch是永恒成立的! 接下来介绍Inverse Probability Weighting (IPW)如何估计ATE,as always,为了直观介绍其思想,我们先介绍Pseudo-population。 通常情况下,观测数据中存在backdoor,如下图左所示,无法直接计算ATE,因为 。在介绍backdoor时,我们得到当W满足backdoor criterion时,ATE可以识别 (公式角度,图形角度参考前述)
作如下分析 :
对比可以看出,问题的区别就在于P(W)与P(W|t)是否相等,即 W) 或者 p(T|W)=1,加权分析思路为: 。从图的角度我们就切断了W -> T,则就可以直接估计了!
这里介绍一些耳熟能详的其他Estimation方法,并简单介绍它们一些核心思想,给大家留个印象,以后有机会再详细介绍。 简单回顾一下刚介绍的方法,COM是预估Conditional Expectation μ(t,ω ) ,IPW是预估propensity score e( ω) 。结合之前介绍的propensity score theorem,很自然可以同时预估2个量,并把 e( ω) 带入 μ(t, ω ) 得到 μ(t, ω )→μ(t, e( ω) ) Doubly Robust Methods明显优点是两个预估量如果有一个是consistent,则ATE是估计是consistent;还有一个优点是理论上比COM/IPW收敛更快,也就是说理论上数据利用效率更高,但是理论研究一般是基于infinite data进行的,真实环境中收敛速率也不一定。 Matching是一个非常经典发展历程也很长,且在很多领域比如政治经济社会医学等非常核心的方法,其思想淳朴但是底层逻辑稳固。一个完整的问题建模基本从两个角度入手,一个是样本角度,一个是目标角度,matching完美从样本角度入手,使研究者正式treatment exposure和样本稀疏性问题 (实干家) !有很多实用且trick的操作可以极大提升业务效果,以后有机会深入介绍!!! matching方法大致从2个角度入手
采样匹配,类似最开始提到的生成comparable groups。对treatment组里每个case匹配counterfactual control case
作为一种非参数估计方法,常用于修正regression 存在omiited-variable引入的误差 (balance variables over treatment-assign variables)
其中采样匹配如上图所示,则存在类似KNN,如何度量和匹配方法的问题。如度量空间选择 (raw、coarsened 、propensity score) 、距离函数、选择规则等。
Double Machine Learning (DML)
上面matching提到了从样本角度入手分析问题 (causal graph上即focus on T) ,而从目标角度则是regression (causal graph上即focus on Y) , (adjusting for all other causes of the outcome Y) 限于篇幅太长,regression下次有机会再说。regression进行估计存在一个问题是,对其他变量W估计有偏,则估计T的ATE存在偏差。 DML则是在进行HTE (Heterogenous Treatment Effect) 研究中,通过残差估计矩 (服从Neyman orthogonality) ,即使W估计有偏,依旧可以得到无偏ATE估计! as always,本文仅从直观角度给新手介绍基本思路,结合下图,
训练模型
训练模型
训练模型 partial out confounding W,
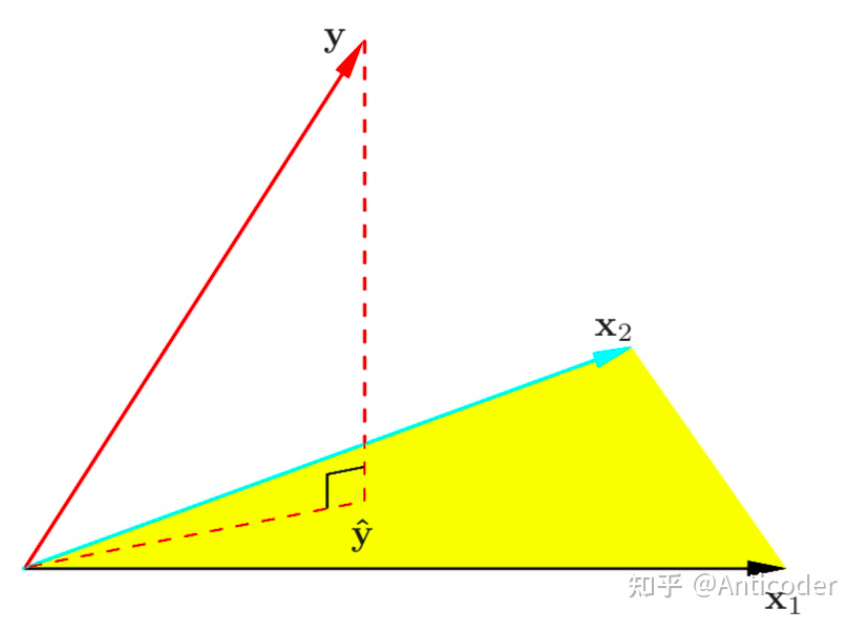
直观角度上,这里对回归比较熟悉的朋友可以知道,线性回归是拟合Y在特征空间X的最佳投影 (即误差最小化) ,所以残差是垂直样本空间X的,即最大限度消除了 (独立) X的相关性!如下图所示。
regression of y on (x1, x2)
Causal Trees & Forests就是决策树和森林的扩展,这方面内容也比较多,篇幅有限不过多介绍。核心就是结合了tree的优点进行casual inference。比如tree相对来说更加flexible,且可以进行区间估计,相对于之前介绍的都是点估计。当我们数据有限时,存在采样偏差,可能不同样本估计值不一样,这时候有个置信区间会更加valid。
7. 工业界因果推断应用:uplift、debias、可解释性
工业界越来越多因果推断应用,这里只简单举例,并非本文重点。 之前提到过营销类模型uplift,目标是最大化ROI,比如如何发券能最大化新增用户。业界常常基于ABTest做随机实验,所以一般需要预跑一段时间收集数据,根据之前提到的positivity假设,当特征越多需要的数据是指数级增加的!因为基于随机实验,所以Identification是天然成立的,那重点关注在Estimation,所以业界基于随机实验,常常关心用什么模型预估estimate更加准确,如S-Leaner、X-Learner等。当然,完全随机可能不能保证,并且实验安排 (比如推全时间点、不同人群实验) 和分析 (选择数据维度和时间范围) 时,不恰当可能导致数据存在confounder,得到失误的判断 (Simpson’s Paradox) ,这些都是需要注意的!了解到的涉及一些优化如下: Debias现在在推荐广告中也应用很多,毕竟很卷。推荐中需要考虑的目标非常多,比如多样性、公平性。因为数据是观测数据,存在很多bias,如selection bias、position bias、conformity bias、exposure bias、population bias、unfairness等。主要借鉴causal Inference中的IPW和Counterfactual思想进行Debias。 可解释性在不同层面的定义是不一样的,也是非常深的话题。这里主要指缓解机器学习中存在的不稳定性。利用因果推断发掘数据中的因果关系,在因果关系的约束下指导机器学习实现稳定学习。还有一个方向就是结合可解释性中常用的distangle learning等。
本文核心思想是介绍causal inference的基本框架,包括基于experimental和observable data的推断。我们目标是通过data计算causal effect,我们感兴趣的causal effect是个causal estimand,无法直接通过数据计算,所以我们首先把causal estimand转化为statistical estimand (Identification) ,然后基于data得到ATE的etimate (Estimation) 。 目前为止我们知道了如何计算causal effect,但都是基于causal graph的,如果我们不知道graph怎么办?后面有机会介绍的causal discovery就派上用场,这样整个统计因果分析方法论就完备了,暂且应该算入门了! 如果仅关注机器学习的朋友,了解些CI也是有好处的!从业务角度比如刚提到的debias,还有ROI类任务;从技术角度causal inference和强化学习、半监督学习和迁移学习都有非常强的关系! 仔细对比,会发现Uplift和强化学习几乎如出一辙,目标都是最大化reward(uplift),希望通过action(do-operator)主动收集数据,核心优化都是提高数据利用率,使用observed data或者offline learning。值得一提的是,现在推广搜太卷,导致各种花里胡哨方法堆,比如RL在推荐中本身是一个非必要的工具,硬去做就很难产生RL的特点。当然RL核心问题还是数据利用率的问题,优化搜索的广度和深度降低机器成本和探索的效率,是RL能否在业界产生价值的核心。 迁移学习中的domain adaptation是非常重要的方向,一个直观思路是,causal inference可以通过causal graph,结合我们之前提到的association flow,进行最大化domain adaptation。其他包括针对covariate shift问题,这些我还没看,有机会再学!
Introduction to Causal Inference from a Machine Learning Perspective
Counterfactuals and Causal Inference Methods and Principles for Social Research
The elements of Statistical Learning Data Mining, Inference, and Prediction
Metalearners for estimating heterogeneous treatment effects using machine learning
Double Machine Learning for Treatment and Causal Parameters
Causal Inference and Uplift Modeling A review of the literature
Elements of Causal Inference Foundations and Learning Algorithms
来源:https://zhuanlan.zhihu.com/p/403098221
由智源社区、集智俱乐部联合举办的因果科学与Causal AI读书会第三季 , 将主要面向两类人群:如果你从事计算机相关方向研究,希望为不同领域引入新的计算方法,通过大数据、新算法得到新成果,可以通过读书会各个领域的核心因果问题介绍和论文推荐快速入手;如果你从事其他理工科或人文社科领域研究,也可以通过所属领域的因果研究综述介绍和研讨已有工作的示例代码,在自己的研究中快速开始尝试部署结合因果的算法。读书自2021年10月24日开始,每周日上午 10:00-12:00举办,持续时间预计 2-3 个月。
详情请见:
因果+X:解决多学科领域的因果问题 | 因果科学读书会第三季启动
点击“阅读原文”,报名读书会


 因果性,且介绍当满足哪些条件时,可以相关性⇒因果性,进而可以基于数据计算得到ATE。我们在此先做一个总结!
因果性,且介绍当满足哪些条件时,可以相关性⇒因果性,进而可以基于数据计算得到ATE。我们在此先做一个总结!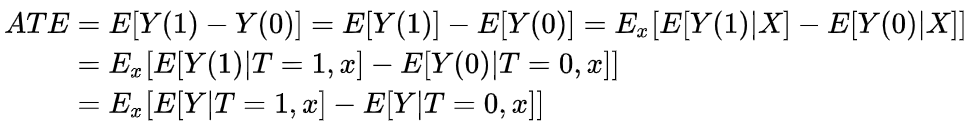
 说明给定X时,potential outcome Y(t)与T无关,这步对于ATE非常关键,是上面公示第二行等号成立的条件!
说明给定X时,potential outcome Y(t)与T无关,这步对于ATE非常关键,是上面公示第二行等号成立的条件!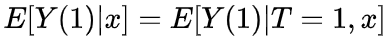
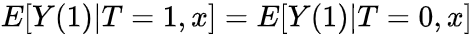 ,说明了Y(1)不论在treatment组还是control组期望是不变的,也说明了Y(t)与T无关
,说明了Y(1)不论在treatment组还是control组期望是不变的,也说明了Y(t)与T无关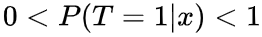 看起来似乎没什么,但也是非常关键的一个假设!intuition为如果边界达成,则某个x下,要么全是treatment要么全是control,则无法计算真实ATE,此时causal effect是ill-defined(且在部分概率推到中导致除0)
看起来似乎没什么,但也是非常关键的一个假设!intuition为如果边界达成,则某个x下,要么全是treatment要么全是control,则无法计算真实ATE,此时causal effect是ill-defined(且在部分概率推到中导致除0) 此假设一般默认成立,是说我的结果与他人无关
此假设一般默认成立,是说我的结果与他人无关 此假设一般默认成立,是说T对结果是一致的。简单举个例子,T为是否养猫,Y为是否开心,不希望养了一只加菲T=1, 结果Y=1;养了一只美短T=1, 结果Y=0。说明T定义不好,这常在设计实验时容易出错。也叫No multiple version of Treatment
此假设一般默认成立,是说T对结果是一致的。简单举个例子,T为是否养猫,Y为是否开心,不希望养了一只加菲T=1, 结果Y=1;养了一只美短T=1, 结果Y=0。说明T定义不好,这常在设计实验时容易出错。也叫No multiple version of Treatment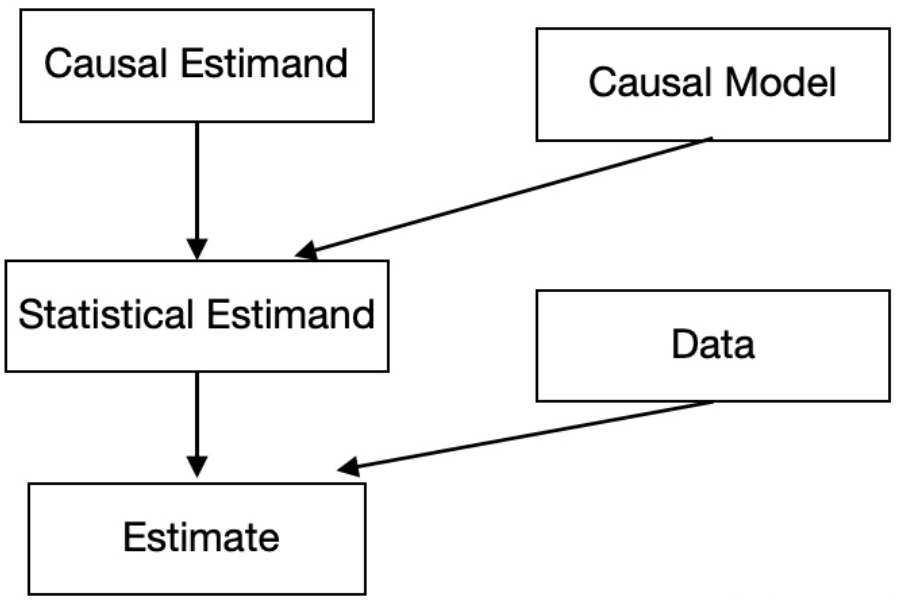


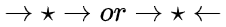
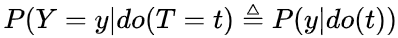
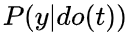 一阶矩的差
一阶矩的差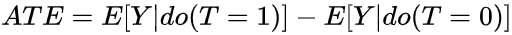

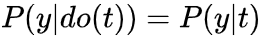 ,这种情况 相关性→因果性
,这种情况 相关性→因果性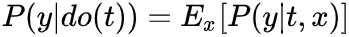
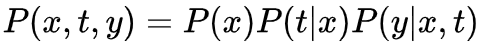
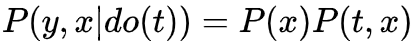
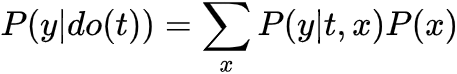
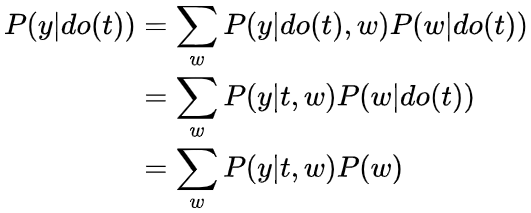
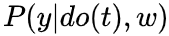 的do(t)是因为W为sufficient adjustment set,切断了所有backdoor path,T->Y仅留下causation
的do(t)是因为W为sufficient adjustment set,切断了所有backdoor path,T->Y仅留下causation 的do(t)是因为 1. do(t)切断了T的parents,没有in-edge association流向T->W; 2. 如果存在association则为T 的 out-edge association,则会与Y形成一个collider,association 被 collider 切断。所以T与W独立!下面举个例子,
的do(t)是因为 1. do(t)切断了T的parents,没有in-edge association流向T->W; 2. 如果存在association则为T 的 out-edge association,则会与Y形成一个collider,association 被 collider 切断。所以T与W独立!下面举个例子,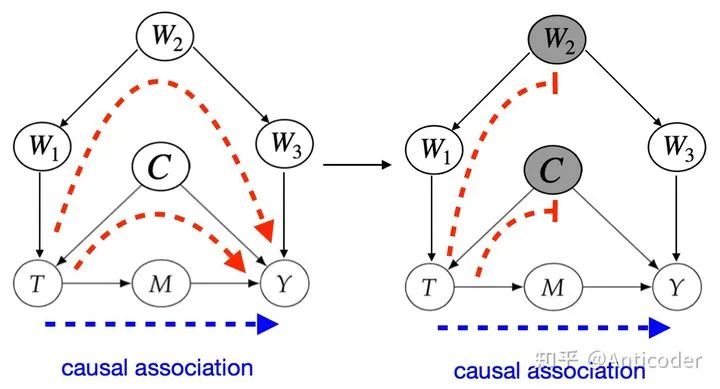


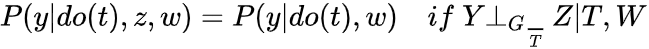
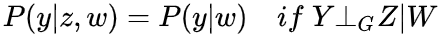 ,可以发现这个就是d-seperation,所以此为d-seperation在intenventional distribution推广
,可以发现这个就是d-seperation,所以此为d-seperation在intenventional distribution推广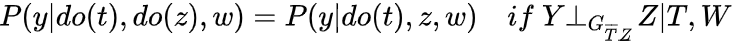
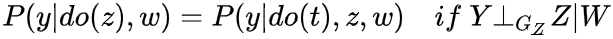 ,可以发现这个就是backdoor adjustment,所以此为backdoor adjustment在intenventional distribution推广
,可以发现这个就是backdoor adjustment,所以此为backdoor adjustment在intenventional distribution推广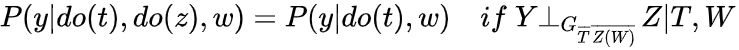
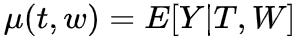

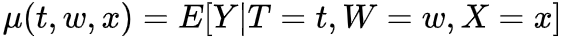



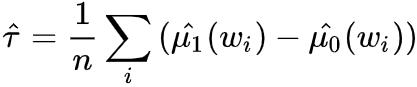
 ,这个和T-Learner一样,分别用treatment和control数据估计条件期望
,这个和T-Learner一样,分别用treatment和control数据估计条件期望 ;针对control组,
;针对control组, 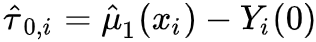
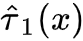 和
和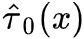 ,其中
,其中  ,
,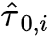
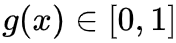 组合2个model
组合2个model 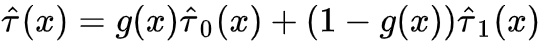
 时,与T-Learner一样仅使用treatment组数据但是在step2训练
时,与T-Learner一样仅使用treatment组数据但是在step2训练 ,所以在训练
,所以在训练 ,衡量了在W=w下分配T=1的概率,直觉上如果W是sufficient adjustment sets且e(W)估计模型正确的,那e(W)包含了全部treatment assignment的信息,那我们仅通过e(W)就可以consistent & unbiased估计ATE了!
,衡量了在W=w下分配T=1的概率,直觉上如果W是sufficient adjustment sets且e(W)估计模型正确的,那e(W)包含了全部treatment assignment的信息,那我们仅通过e(W)就可以consistent & unbiased估计ATE了!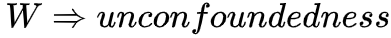 ,则
,则 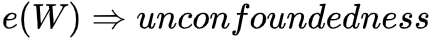

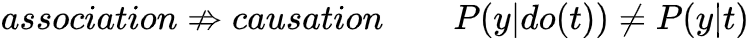 。在介绍backdoor时,我们得到当W满足backdoor criterion时,ATE可以识别 (公式角度,图形角度参考前述)
。在介绍backdoor时,我们得到当W满足backdoor criterion时,ATE可以识别 (公式角度,图形角度参考前述)