因果推断在医学、药学、生物学中的应用 | 周日直播·因果科学读书会

导语


背景
背景
随机化试验可能被破坏。如果部分受试者不依从于治疗分配,如何定义和识别因果作用?意向治疗策略考察治疗分配对结局的影响,符合方案治疗策略考察观察到的依从于治疗分配的个体上的因果作用,实际治疗策略考察实际接受的治疗是否预见了结局的差异。如果在试验的过程中,一些受试者出现不良反应或其他伴发事件,该如何定义结局和因果作用?疗法策略简单地忽略伴发事件,组合策略把伴发事件和主要结局组合成单个结局,假想策略设想了一种不会发生伴发事件的场景,在治策略考察伴发事件发生前结局的变化,主层策略考察不会发生伴发事件的子人群上的因果作用。
长期以来,随机化一直被当成是评估因果作用的金标准。在随机化试验中,每个个体被随机分配到各个处理组,因此理论上各个处理组下的协变量分布相似。使用各个处理组下的观察到的结局均值差异能对平均因果作用进行无偏估计。然而,随机实验的这些性质只对大量重复实验平均而言成立,在实际只做一次实验的情形下,不同处理组下的协变量的分布可能有显著差异,均值差异估计量可能离因果作用的真实值很远。举一个简单的例子,假设在某次随机化临床试验中,随机分配一些个体接受治疗或对照,但治疗组中恰巧大部分都是身体虚弱的个体,而对照组中恰巧大部分都是身体健壮的个体,这样,两组的观测结局均值受到患者身体状况这一不容忽视的混杂因素的影响。
内容简介
内容简介
本次分享关注因果推断框架在近二十年的两项重要进展:主分层(principal stratification)和再随机化(rerandomization)。
1. 主分层。主分层的思路是根据处理后、结局前的潜在中间变量对总体进行分层,由于潜在中间变量(潜在结果)不受处理分配的影响,因此主层可被看作是处理前的基线协变量。主分层通常被应用于两个场景中:非依从和死亡截断,尽管也存在其他场景。
-
非依从。激励试验与工具变量有着紧密的联系。受试者可能不服从分配方案,传统的意向治疗策略估计的是激励的作用,而非真实处理的作用。为了估计真实处理的作用,利用主分层,把整个人群分为四层:依从者,永远接受者,永远拒绝者,抵抗者。永远接受者和永远拒绝者对因果作用的估计不起作用,只有依从者和抵抗者对因果作用的估计是有意义的。
-
中介分析。中介分析可以追溯至Fisher和Cochran的农业试验研。传统的中介分析把结局变量看作是处理变量和中介变量的潜在结果,进而把处理到结局的总作用分解为自然直接作用和自然间接作用。然而,如果中介是不可操纵的,按照定义,中介就不能被称为原因,所以结局只能写作是处理的潜在结果。利用主分层,把感兴趣的因果作用限制为主层直接因果作用。
-
死亡截断。一些个体的潜在结果可能没有定义。死亡截断与缺失不同,缺失指的是结局存在但未被观测到,而死亡截断指的则是结局没有定义。利用主分层,可以找出一个子人群,使得两个潜在结果都是良定义的,称这一子人群为永远幸存者(always-survivors)。因果作用只能在永远幸存者中定义。死亡截断的概念在医学、生物学、经济学等领域有广泛的应用。
2. 再随机化。当面临不合适的随机分配时,Fisher建议进行再随机化。Morgan和Rubin首次对再随机化进行了正规的数学描述,其基本思路是:预先指定某种衡量协变量在不同处理组之间分布是否平衡的准则,不采纳那些协变量不平衡的随机分配,而是一直进行随机化,直到获得协变量平衡的随机分配为止。Morgan和Rubin建议使用处理组和对照组协变量均值的平方马氏距离作为准则,只接受平方马氏距离小于某个阈值的随机分配。他们还指出,通过再随机化,可以实现平均因果作用估计的方差下降。
主讲人
主讲人
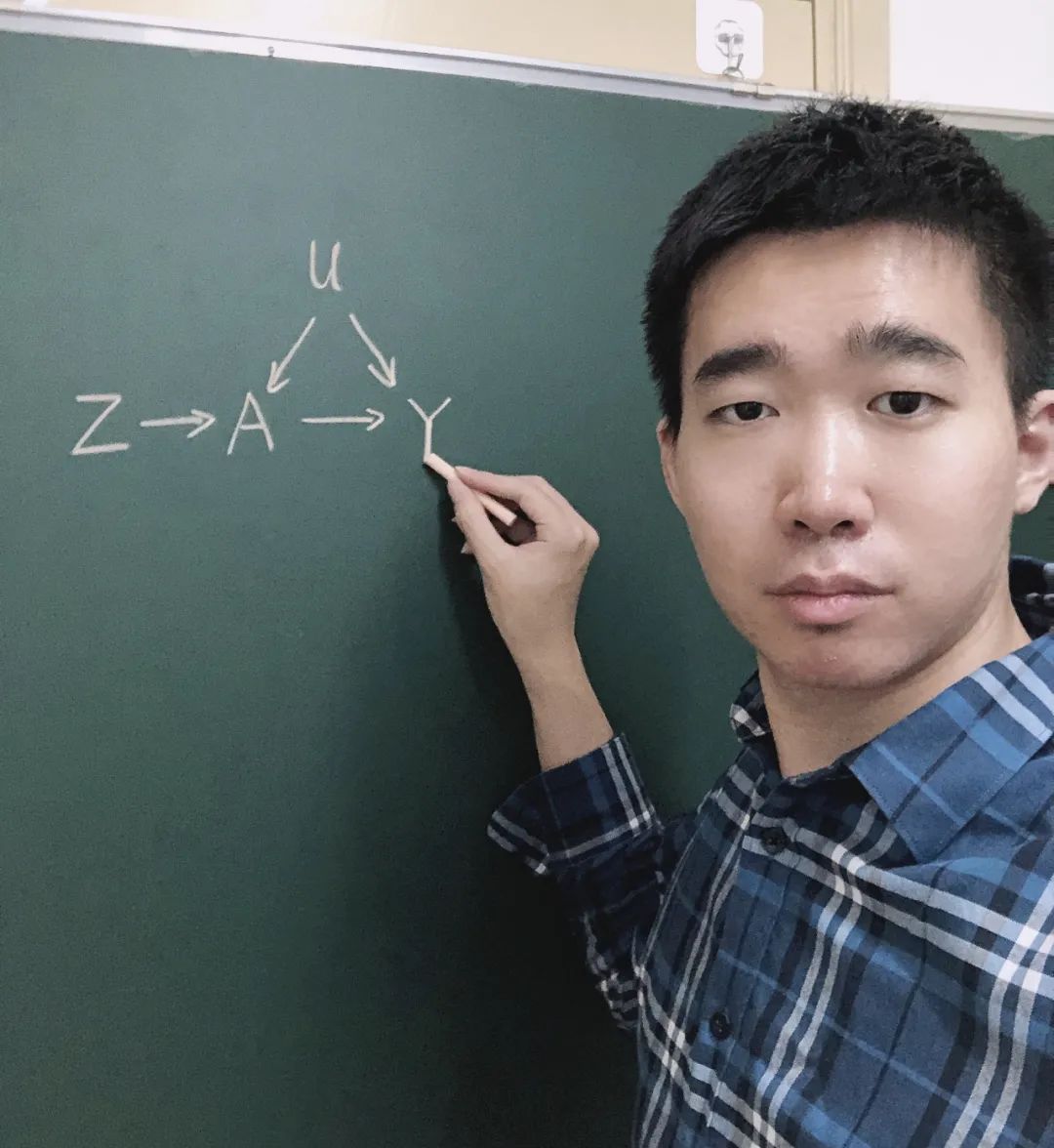
直播信息
直播信息
时间:
2021年12月12日上午9: 00-11: 00
参与方式:
-
文末扫码参加读书会第三季,加入群聊,获取系列读书会回看权限,成为因果社区种子用户,与900余位社区的科研工作者沟通交流,共同推动因果科学的发展。 -
集智俱乐部 B 站免费直播,扫码可预约。

扫码预约
因果科学读书会第三季启动
因果科学读书会第三季启动
读书会大纲一览:
Donald Rubin:Essential Concepts of causal inference
因果推断在观察性研究中的应用(续):ANALYSIS
因果与公平性和可解释性
「深入理论学习」

点击“阅读原文”,报名读书会
微信扫一扫,分享到朋友圈











