作为国内最具影响力的复杂科学社群,集智一直希望能准确把控学科前沿;但当前科学以几何级数之势增长,整体把控对于领域专家尚显困难,更遑论精准追踪创新前沿了——对于与各学科高度交织关联的复杂科学,挑战尤甚。我们可否利用数据和算法的优势来解决这个问题呢?
从2019年开始,集智尝试开发集智斑图论文库,来收录复杂科学前沿研究,使用各类算法加以展现并服务于社群。数据方面,集智斑图在上线近两年中覆盖了越来越多的复杂科学研究,已形成了一定代表性;算法方面,集智科学家吴令飞在2019年的一期Nature封面论文“大团队发展,小团队创新”中,提出 disruption 指标来衡量论文颠覆性,为我们盘点斑图中可能的创新论文提供了依据。今天,集智算法组撰此文以跟进探索成果,致敬斑图两年历程,并向复杂科学社群致以节日问候。
胡乔(集智算法组)、徐恩峤(集智算法组) | 作者
徐恩峤(集智算法组)、梁金、刘培源 | 审校
邓一雪 | 编辑
目录:
一、集智斑图——汇聚社群智慧
二、斑图底层架构:自动化算法筛选复杂科学论文
三、如何发现复杂科学研究新星?disruption 指标衡量论文创新性
四、斑图论文“巡礼”
五、总结
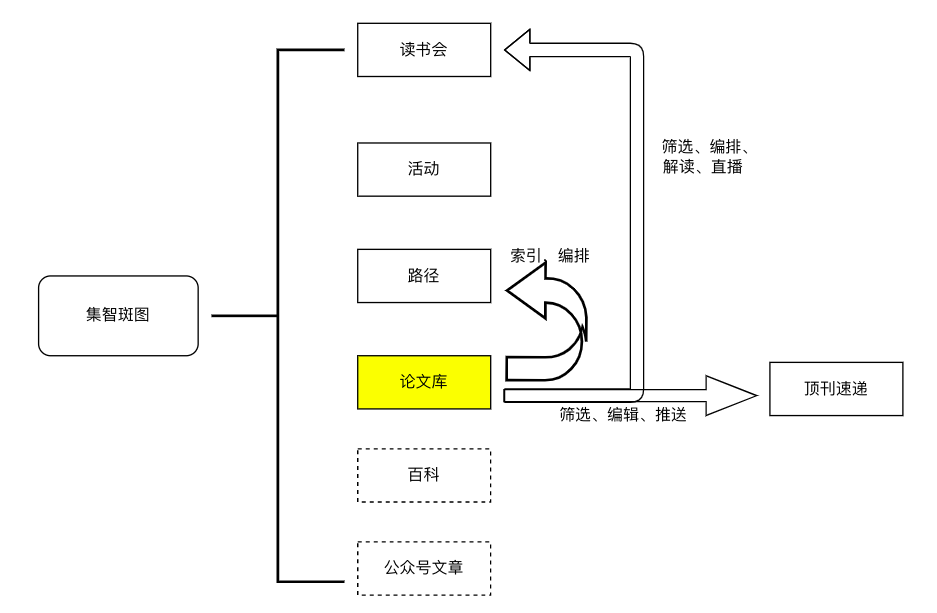
集智斑图(swarma pattern,以下简称“斑图”)是集智体系中的内容聚合器,它聚合了读书会、活动、论文、学习路径等内容,在新版本V2.0中还将包括集智百科和公众号文章。“斑图”音译自 pattern,它是复杂科学的重要研究对象,也代表集智社群涌现出的知识模式;同时又有“版图”的谐音,表达了我们专注复杂科学领域、打造复杂科学版图的愿望。
自成立以来,斑图内容日益充实。当前最活跃的板块当属读书会,参与者众、讨论也最多。而为读书会活动提供文献支撑的模块,则是收录复杂科学前沿研究的斑图论文库(以下简称“论文库”)。千万不要小看这个论文库,它形成了其它各个模块的基础:从论文库中按主题筛选和编排论文,组织起来逐一解读,就形成上述的读书会;如果以长文的形式串起论文,介绍各个研究领域和方向,就形成学习路径;我们也会定期将重点期刊的最新论文打包推送,这就是复杂性研究速递(complexity express,以下简称“顶刊速递”)。
图1. 斑图内容模块结构图
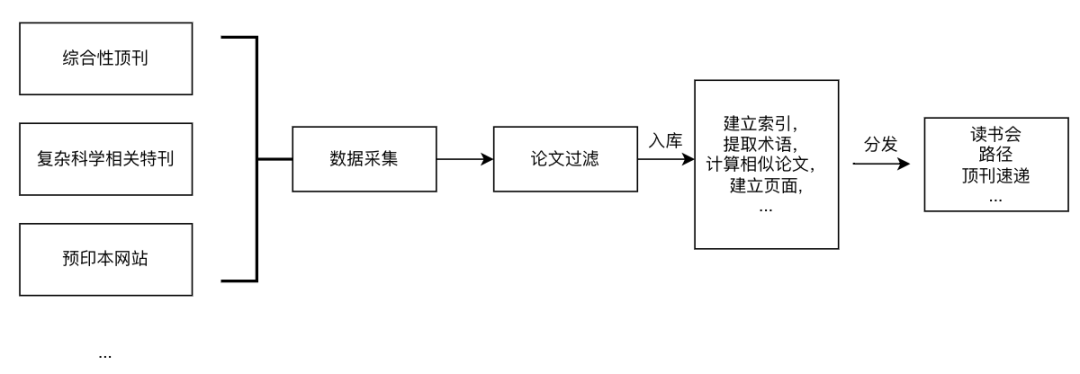
斑图的论文主要来自各大主流综合性期刊(如Nature、Science、Cell)、部分复杂科学相关的top期刊以及预印本网站等。我们还会持续扩大数据采集范围,力求覆盖复杂科学全领域。
对采集到的论文,我们使用复杂性论文过滤器(以下简称“过滤器”)判定该论文是否为复杂科学论文。当前版本的过滤器基于大规模预训练语言模型 BERT,并针对复杂科学领域语料调优而得到,该模型随着我们关注主题的扩展还会不断再训练和优化。作为对过滤器的补充,我们也维护了一批复杂科学术语进行基础的文本匹配。
通过过滤器筛选并入库的论文,我们会做一系列的处理。例如提取论文术语、搜索相似论文以及排序等。收录的论文会建立论文页面,如前所述,部分论文还将根据情况分发到读书会、学习路径、顶刊速递等内容模块中。
图2. 斑图论文处理流程
上线两年来,我们在这个架构下不断搜寻和扩充复杂科学相关的各个领域;经过持续建设,当前我们收录的论文涵盖了与复杂科学密切相关的大部分领域,成为初具规模的复杂科学数据平台。这些领域包括:
这些领域大都经历着快速成长,而作为这一进程的全面见证者和坚定推动者,我们也高兴地看到复杂科学被越来越多的人关注。
以上就是论文作为内容和支撑模块的主要运作流程。其中一些技术,如读书会、论文、学习路径的关联耦合与领域术语的提取等是集智算法组的工作重点,这里不再赘述。本文重点要展示的是论文影响力评价问题,即如何在大量跨学科文献中找出最具颠覆性影响力的作品。
三、如何发现复杂科学研究新星?
disruption指标衡量论文创新性
科学学(science of science)中著名的文献增长定律指示,指数增长为当前不同领域文献的常见增长模式[1]。两年来,斑图收录的复杂科学论文也在快速增长。如何将其中最有潜力的论文挑选出来呢?集智科学家吴令飞提出了 disruption 指标衡量知识成果的颠覆性[2]。
在“大团队发展,小团队创新”这项研究中,吴令飞等人剖析了大团队和小团队研究模式的区别,指出:大团队倾向于渐进式发展,小团队倾向于颠覆式创新。这是近年来科学学关于团队研究的经典之作,曾入选 Nature 封面论文。
图3. Nature 封面论文。研究的生态:大团队发展,小团队创新
这项研究提出了disruption指标来衡量论文的颠覆性,它基于2017年Funk等人[3]提出的CDt指标,并做了简化。其基本想法是,一项工作的颠覆性可以基于该工作(论文、专利、软件等)的引用模式(citation pattern)而不是其引用量(citation counts)来标定,就论文来看:一篇开宗立派的论文,将会被很多后续论文引用,并且成为引用的根节点,也就是说新的研究分支从这里开始,不必要再往前溯源;一篇添砖加瓦的优秀论文,同样会被很多论文引用,但同时这些论文还要引用更早之前的著作才能形成完整的逻辑链和论证链。
为说明这种区别,作者举了两篇论文作为例子,一篇是 self-organized criticality: An Explanation of 1/f Noise[4] ,另一篇是 Bose-Einstein condensation in a gas of sodium atoms[5]。这两篇正好都是复杂科学的经典论文:前者讲的是自组织临界性,解释了众多复杂系统中的幂律分布和分形等特征,著名的沙堆模型就出自这篇论文;后者玻色-爱因斯坦凝聚则是相变现象的一种,作者通过实验证实了Bose和Einstein的预测,即将玻色子冷却到非常低的温度后,它们会聚集到到能量最低的可能量子态中,导致一种全新的物相(论文作者之一Wolfgang Ketterle因为这项研究获得了2001年诺贝尔物理学奖)。
两篇经典论文的引用量相当,但我们观察这两篇论文的引用模式就会发现,引用 self-organized criticality 的论文,基本上没有继续引用其参考文献;而引用 Bose-Einstein condensation 的论文,几乎总是还引用了Bose、Einstein 等人更早先的著作。
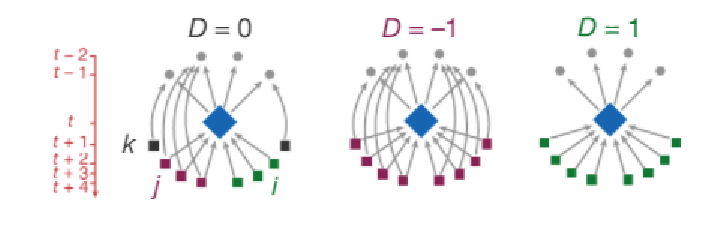
要如何通过引用模式来定量衡量一篇论文的颠覆性呢?我们用p表示当前论文,用citation(p)表示p的参考文献集合,用cited(p)表示那些引用了p的论文集合,那么cited(citation(p))可以表示引用了p的参考文献的那些论文。而我们所要考虑的全体论文是“引用了p”或“引用了p的参考文献”的那些论文,即cited(p)和cited(citation(p))的并集。
接下来,我们将所有论文分为3部分:
①引用当前论文p,而不引用p的参考文献的论文集合I
②既引用了p,又引用p的参考文献的论文集合J
我们记nX为 X 类中的论文数量,disruption 指标定义为
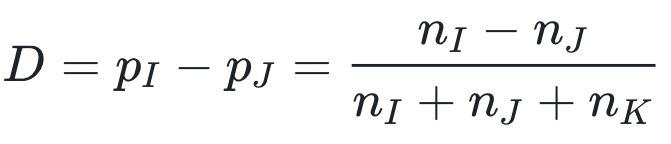
分母是全部论文的数量,分子是“只引用p的论文”与“既引用p又引用其参考文献的论文”的数量差。D的取值区间为[-1,1]。当D=-1时,所有论文既引用p又引用其参考文献,其建设性(developing)最强;反之当D=1时,所有论文只引用p而不引用其参考文献,此时p的颠覆性(disruption)最强。在吴令飞的论文中,self-organized criticality 和 Bose-Einstein condensation 这两篇论文的disruption指标分别为0.86和-0.58,例证了该指标的区分性能。
图4. disruption计算图示。图中每个节点均为一篇研究论文,箭头表示引用关系。其中,中心蓝色方形节点为待研究颠覆性的论文(p),灰色节点为p的参考文献。绿色节点I为仅引用p的论文,紫色节点J为既引用p又引用其参考文献的论文,黑色节点K为引用p的参考文献而不引用p的论文。
了解了disruption指标的妙处,接下来我们就用 disruption 指标,对斑图论文库进行一次盘点分析。
在开始计算之前,我们根据论文库的数据特点做一些针对性的处理。首先,disruption 指标基于论文的引用模式,由于论文库的主体是近年的期刊论文,很多论文发表后还没有引用记录——这部分论文disruption指标没有定义,因此我们筛除掉这些论文,只对所有有引用的论文进行计算。引文数据我们从微软学术图谱(Microsoft Academic Graph,MAG)数据库获取[3]。
其次,disruption 指标的计算隐含了潜在的时间顺序,即施引的论文总是在引用的论文之后。因此上述集合 I, J, K 中所有的论文都是在p发表之后的论文。
做完上述处理之后,就可以正式进行计算了。我们使用的数据是斑图上收录的2020年发表的论文,为了确保引用模式的统计可信度,我们进一步选取了引用量大于10的论文。
现在,disruption 选出的 2020 年复杂科学 top10 论文终于可以隆重登场,让我们来一一揭晓。
表1 斑图论文 disruption 排名 top10
入选的第1篇论文是 COVID-19 Contact-tracing Apps: a Survey on the Global Deployment and Challenges,论文综述了在疫情大背景下,各国为适应流行病学调查的需要而争相开发联系人追踪app的情况。有意思的是,综述类论文的 disruption 值一般会偏低(后文会提到具体的原理),而该文却成为disruption最高的论文,充分体现了疫情对科研乃至整个社会的冲击,也很好地反映了在我们这个时代,信息技术成为抗击疫情的强有力武器。
图5. 各国为适应流行病学调查需要开发的联系人追踪 app
第2篇论文研究了网络数据流的自相似性质,该文指出自相似结构在数据流的多个时间尺度上出现,并基于数值实验研究了多层数据流叠加时呈现的整体性质。自相似、尺度不变性是复杂系统的重要特征,而本文是基于复杂系统基本概念和实验方法研究实际系统(多层网络数据流)的典型。
图6. 网络数据流在多个时间尺度上表现出自相似结构
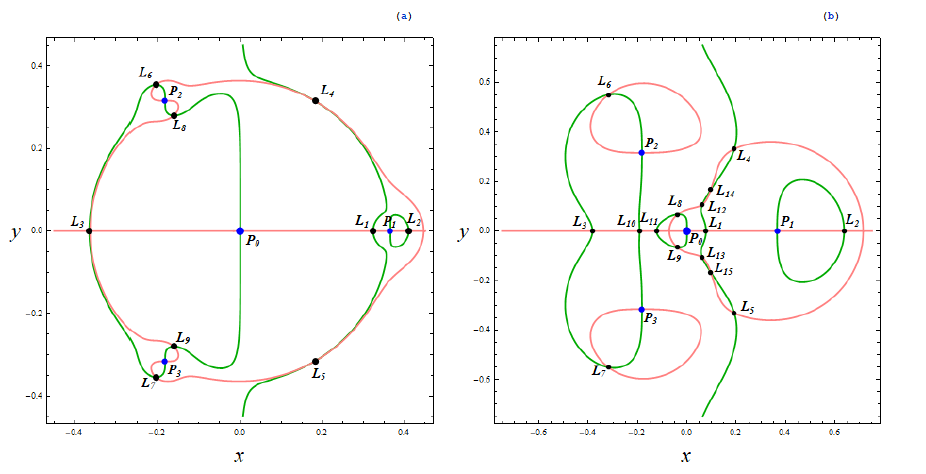
第3篇论文研究了受限五体问题,是典型的多体系统。具体而言,该文详细研究了由于第五个质点质量变化引起的扰动对整个系统特征(如振动点的位置、稳定性)的显著影响。本文是典型的混沌系统研究,将对多体问题的研究从三体、四体进一步推动到更高复杂度的系统。
第4篇和第7篇涉及的是生态和社会系统(这两篇论文并不是近两年新作,但由于去年重新在预印本网站刊发而被我们采集到)。第4篇论述了光污染的危害、发展趋势和治理措施,第7篇论文提出了行为信息学这个新的交叉学科领域,用定量的方法来建模和分析人在组织中的行为表征、行为模式等。
第5篇和第8篇是关于物理系统的论文:第5篇论述的是使用模型无关的Levy成像方法重建高能粒子的弹性散射过程,是一种数据驱动的建模方法;第8篇论述了在远离平衡的随机系统中,熵产生率限制了物理过程的速率,并在此基础上提出耗散-时间不确定性关系——耗散越小,物理过程的执行时间越长。
第6篇和第9篇是复杂系统分析的方法和工具。第9篇使用的是蒙特卡罗模拟方法,对交通出行模式中的过度通勤问题进行了分析;第6篇同样是关于蒙特卡罗方法,但其重点是创建新的python包来进行蒙特卡罗采样分析。
第10篇与第1篇一样,是关于疫情的研究,该研究使用数学模型研究了人群的异质性,尤其是年龄结构和活跃程度的异质性对实现群体免疫的影响。
纵观以上论文,我们发现 disruption 指标的确找出了一些高质量的复杂科学研究样板,既有关于复杂系统基本概念的论文,也有关于方法论和工具的研究,并且覆盖了物理、生态、社会复杂系统等各个领域。该指标对于热点研究同样有很好的识别作用,疫情论文入选就是例证。
颠覆性评价见仁见智,这些新鲜的研究也许还要经过时间检验才知道能否成为经典,但disruption指标无疑给我们提供了非常好的跨学科研究比较视角。
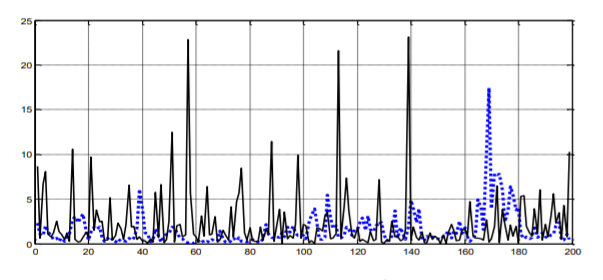
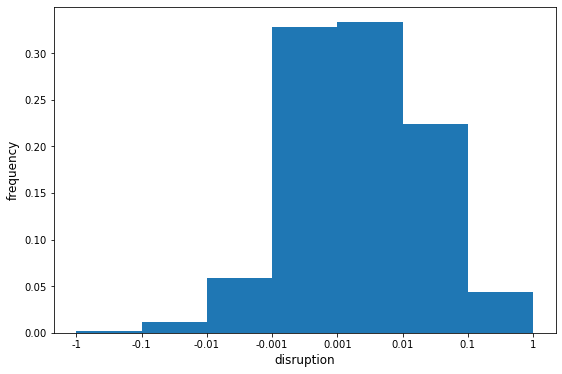
除了筛选出 disruption 排名 top10 的论文,我们再看看到论文库收录论文的 disruption 分布:
图8. 论文库的disruption分布(横坐标为对数坐标)
可以看到,disruption指标呈现明显的钟型分布,大部分值集中在0附近,即使去除掉了没有引用记录的论文也仍然如此,分值大于0.1或小于-0.1的论文仅占所有论文总数的约4%。这一分布与原论文中的分布也基本吻合。也就是说,大多数论文的创新性都不是很高,这也许是因为巨人的肩膀太高而另辟蹊径又太难……
进一步分析,对于不同类型的论文,其disruption指标反映了哪些特征呢?这里我们举一类例子——综述论文,综述论文的任务是要概览当前领域已经发表的有影响力的工作、分析其发展情况,给该领域的其他研究者作为参考。因此,综述论文要大量引用其他论文,并且是有影响力的论文,这使得在计算 disruption 时,分母nI+nJ+nK比一般的论文更大,因而综述论文的 disruption 值一般会较小。而前文我们使用disruption 指标评选的第一名却是一篇综述,可见该综述对之前研究的整合很成功,通过整合和梳理引起了其他研究者的广泛关注。
如果我们单纯根据引用量给论文排名会怎样呢?作为比较,这里列出斑图2020年收录的论文按引用量排名的前10位(即高引用论文)。
表2 按citation排序得到的 top10 论文
我们发现按引用量排名,靠前的大部分是关于疫情和机器学习的研究,几乎没有出现其他学科。这两个领域是当前的热门领域,但如果想要尽可能全面地了解复杂科学的研究全貌,那么引用指标就会遮盖很多子领域的重要研究。
综上,我们目前采用disruption指标来对复杂科学论文的创新性排序,并据此获取概览复杂科学的一种视角。当然,由于斑图仍处于不断开发完善中,2020年可能还有一些潜在的复杂科学研究没有被收录和进入排序结果,也由于使用disruption指标可能还有更多工程因素需要考虑,我们目前的论文创新性排序仅供读者参考,集智算法组欢迎读者朋友们讨论和提出更好的论文影响力评价方案。
本文介绍了斑图的内容架构,以及基础模块——论文库的运作流程。然后详细讲解了衡量论文颠覆性的disruption指标及其计算方法。接着我们用disruption指标盘点了论文库,并重点介绍和点评了评选出的2020复杂科学创新性 top10 论文。
通过比较,我们发现使用引用模式而非引用量衡量论文颠覆性,尤其适用于复杂科学等跨学科领域间的综合比较。通过本文的介绍,希望读者对斑图的运作流程有更多的了解,对使用引文网络评价科学论文影响力有一个初步的认识。
本文是集智算法组创作的一次小小尝试,我们希望以这种形式和读者朋友互动,希望大家多多支持。算法只是斑图的一个方面,作为一个整体,集智大家庭将始终致力于向社群提供更好的知识服务和探索体验。本文作为年终巡礼系列文章之一,在斑图两周年及新年之际祝朋友们节日快乐。欢迎大家加入我们,2022年,我们一起复杂!
参考文献:
1.Price, D. J. (1951). Quantitive measures of the development of science. UNESCO.
2.Wu L, Wang D, Evans J A. Large teams develop and small teams disrupt science and technology[J]. Nature, 2019, 566(7744): 378-382.
3.Microsoft Academic Graph:https://www.microsoft.com/en-us/research/project/microsoft-academic-graph/
4.Bak P, Tang C, Wiesenfeld K. Self-organized criticality: An explanation of the 1/f noise[J]. Physical review letters, 1987, 59(4): 381.
5.Davis, K. B., Mewes, M. O., Andrews, M. R., van Druten, N. J., Durfee, D. S., Kurn, D. M., & Ketterle, W. (1995). Bose-Einstein condensation in a gas of sodium atoms. Physical review letters, 75(22), 3969.
6.Funk R J, Owen-Smith J. A dynamic network measure of technological change[J]. Management Science, 2017, 63(3): 791-817.
我们是集智算法组,为集智俱乐部公众号/集智斑图/集智学园/集智百科等产品提供算法支撑和服务。目前的算法开发范围包括而不限于文本分析、术语和概念挖掘、引文网络分析、科学影响力评价、推荐系统、图神经网络等。我们在集智社群的知识和科技氛围中成长,也将成果反哺于集智社群。如果你是算法爱好者并对上述某个算法分支感兴趣,欢迎加入我们组织的集智计算社群;如果你有其它用科技赋能集智的好点子,期待你的分享。

实习生简历请投至huqiao@swarma.org
集智斑图顶刊论文速递栏目上线以来,持续收录来自Nature、Science等顶刊的最新论文,追踪复杂系统、网络科学、计算社会科学等领域的前沿进展。现在正式推出订阅功能,每周通过微信服务号「集智斑图」推送论文信息。扫描下方二维码即可一键订阅:

点击“阅读原文”,加入集智计算社群