Nature:类脑计算亟需宏大蓝图

导语
与日俱增的算力需求下,现代计算系统能耗也越来越高,很难作为可持续的平台支持人工智能技术的未来发展。这一能源问题很大程度上源于传统数字计算系统采用经典冯·诺依曼结构,即数据处理和存储需要在不同地方进行;而在人脑中,数据处理和存储在同一个区域完成,且大规模并行。生物学的灵感启发了类脑计算,神经形态系统可以处理非结构化数据、完成图像识别、对噪声和不确定数据集进行分类、并参与建构更优的学习和推断系统,有望从根本上改变处理信号和数据的方式,无论是在能源效率方面,还是在处理现实世界的不确定性方面。然而,目前对神经形态计算的关注和投资远远落后于数字人工智能和量子技术,该如何发挥神经形态计算的潜力?近期发表于 Nature 的文章认为,类脑计算亟需一幅宏大蓝图。
研究领域:类脑计算,神经科学,人工智能

A. Mehonic & A. J. Kenyon | 作者
任卡娜 | 翻译
JawDrin | 审校
邓一雪 | 编辑

论文题目:
Brain-inspired computing needs a master plan
论文链接:
https://www.nature.com/articles/s41586-021-04362-w
摘要
摘要
类脑计算(Brain-inspired Computing,或译作“脑启发计算”)向我们描绘了一幅美好的愿景:按照根本不同的方式以极高的能源利用效率处理信息,并且能够处理人类正在增速产生的越来越多的非结构化与噪声数据。要想实现这样的愿景,我们亟需一张宏图,在资金、研究重点等方面提供支持,将不同的研究团体协调地聚集在一起。昨天,我们在数字技术上如此走过;今天,在量子技术上一如既往;那么明天,在类脑计算上所做的是否也应如此?
背景
背景
现代计算系统能耗过高,不能作为可持续的平台支持日益应用广泛的人工智能技术的发展。我们仅仅关注了速度、准确度、每秒并行操作数等功能,而忽略了可持续性,特别是在基于云的系统(Cloud-based Systems)的例子中。瞬间获取信息的习惯让我们忘记了实现这些功能的计算机系统会带来怎样的能源和环境消耗。例如,每次谷歌搜索都有数据中心的支持,而这样一个数据中心每年大约使用200太瓦时(terawatt)的能量,预计到2030年能耗还将增加一个数量级[1]。无独有偶,在高端人工智能系统中,以DeepMind引以为傲的、能够在复杂策略游戏中击败人类专家的 AlphaGo 和 AlphaGo Zero 为例,它们需要数千个并行处理单元,每个单元的功率大约200瓦,远超人脑的约20瓦[2]。
尽管并非所有数据密集型运算都用得上人工智能和深度学习,我们仍然需要担心应用越来越广的深度学习所带来的环境成本。此外,我们还应考虑包括物联网(Internat of Things, IoT)和自主机器人代理(Autonomous Robotic Agents)等不需计算密集型深度学习算法的应用,减少其能耗。若能耗需求过高,需要接入无数设备来运行的物联网也就无从谈起。分析表明,激增的算力需求远超摩尔定律(Moore’s Law)带来的提升,算力需求翻倍现在只需要两个月(图1a)[3]。通过智能架构和软硬件协同设计的结合,我们正在取得越来越显著的进步。以NVIDA的图形处理器(Graphics Processing Units, GPU)为例,其性能自2012年已经提高了317倍,远超摩尔定律的预言(图1b),尽管与此同时,处理器能耗从25W增长到320W。研究与开发阶段不凡的性能提升(图1b,红色部分)昭示着我们可以做得更好[4-5]。但遗憾的是,单靠传统的计算解决方案无法满足长期需求。当想到大多复杂深度学习模型惊人的高训练成本时,这种遗憾尤其明显(图1c)。因此,我们需要新的出路。
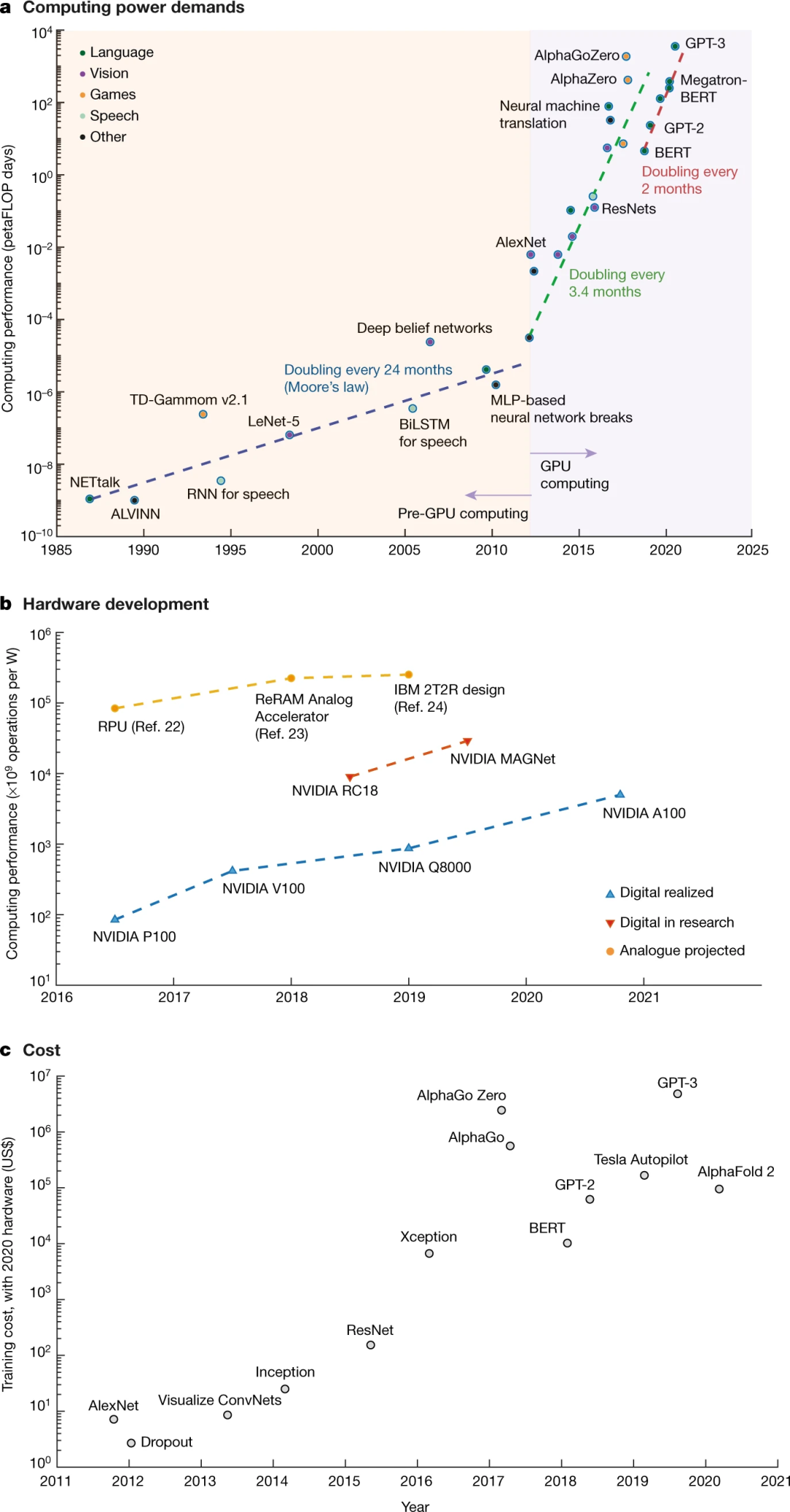
能源问题很大程度上源于数字计算系统处理数据和储存数据是在不同地方,也就是支撑数字计算系统的经典冯·诺依曼结构(von Neumann Architecture),这种结构决定了处理器要在移动数据上花费大部分的时间和能源。幸而生物学所带来的灵感给我们指了一条新的出路——在同一个区域完成储存与处理,以一种完全不同的方式编码信息,或者直接对信号进行操作,并采用大规模并行,这将在方框1中展开论述。其实,能源利用的高效和高级功能的行使可以兼得——我们的大脑就是明证。当然,关于我们的大脑如何做到兼得这二者,还有太多需要探索的奥秘。我们的目标并非仅仅简单模仿生物系统,而是要向过去几十年中神经科学与计算神经科学的重大进展当中找到出路。我们对大脑的了解已足以用来激发灵感。
生物学的启示
生物学的启示
在生物学中,数据存储并非独立于数据处理,比如人脑——主要是神经元和突触——以大规模并行和适应性的结构行使这两种功能。人脑平均包含1011个神经元和1015个突触,消耗大约20瓦功率;而一个相同大小的人工神经网络的数字模拟消耗7900千瓦[6]。这六个数量级的差距无疑是对我们的挑战。大脑直接以极高的效率处理噪声信号;这与传统计算机系统中时间和能源消耗巨大的信号-数据转换和高精度计算形成鲜明对比,即使是最强大的数字超级计算机对于大脑也是望尘莫及。因此,类脑计算系统(另译作神经形态计算)有望从根本上改变我们处理信号和数据的方式,无论是在能源效率方面,还是在处理现实世界的不确定性方面。
当然,这个想法的产生在科学发展历程中也是有迹可循的。“神经形态”(neuromorphic)一词描述的是模仿生物神经系统部分功能的设备和系统,在20世纪80年代末由加州理工学院的卡弗·米德(Carver Mead)创造[7-8]。灵感来自于过去几十年的工作,将神经系统建模为等效电路[9],并构建模拟电子设备和系统,以提供类似的功能。
当我们在说神经形态系统时,
我们在说什么?
大脑带来的灵感使我们能以与现有传统计算系统完全不同的方式处理信息。不同的类脑计算平台(或神经形态计算平台)使用迥异于冯·诺依曼计算机的方法组合:模拟数据处理(Analogue Data Processing)、异步通信(Asychronous Communication)、大规模并行处理(Massively Parallel Processing, MPP)或者脉冲版的深度残差网络(Spiking Deep Residual Network, Spiking ResNet)等等。
神经形态四个字,涵盖了至少三个普遍的研究群体,可根据他们的研究目标进行区分:模拟神经功能(大脑逆向工程)、模拟神经网络(开发新计算方法)和设计新型电子设备。
(1)模拟神经功能
神经形态工程学研究的是大脑如何用突触、神经元这样的生物性结构的物理属性来完成“计算”。类脑工程师们利用模拟电子的物理原理模拟生物神经元和突触的功能,来定义处理音频、视频或智能传感器等行使功能所需要的基本操作,比如载体隧道(Carrier Tunneling)、硅浮栅上的荷电保持能力(Charge Retention)以及各种设备或材料属性对各种场呈指数增长的依赖性。更详细的信息可以在引文[41]中找到。
(2)模拟神经网络
类脑计算从生物学角度寻求新的数据处理方法,这也可以被理解为神经形态系统的计算科学。这个方向的研究着眼于模拟生物神经网络的结构和运作(结构或运作),也就是像大脑一样,在同一个区域完成储存与处理;或者采用基于电压尖峰来模拟生物系统动作电位这样完全不同的计算方法。
(3)设计新型电子设备
当然,巧妇难为无米之炊。我们需要支撑实现仿生功能所需的设备和材料。最近发展的可定制特性的电子和光子元件,能够帮助我们模仿突触和神经元等生物结构。这些神经形态工具提供的激动人心的新技术可以扩展神经形态工程和计算的能力。
在这些新元件中,最重要的是忆阻器:其电阻值是其历史阻值的函数。忆阻器复杂的动态电反应意味着它可以被用于数字记忆元件、人工突触中的可变权重、认知处理元件、光学传感器和模拟生物神经元的设备[42]等等。它们可能具备真正树突的部分功能[43],而它们的动态反应也可以产生类似于大脑的振荡行为,在混沌边缘运行[44-45]。它们可能与单个系统中的生物神经元联系在一起[46]。它们只需很少能量便可完成这些功能。
数据漫谈。我们使用“数据”一词来描述编码在模拟信号或传感器的物理响应中的信息,或者更为标准的纯理论运算中的的数字信息。言及大脑“处理数据”,我们描述的是一套完整的信号处理任务,但是不依赖于传统意义上的信号数字化。想象一下类脑计算系统在从模拟信号处理到处理超大规模数据库这样不同的层次上运行:在前一种情况下,我们可以从一开始就避免生成大数据集;在后一种情况中,我们可以尽可能避免冯·诺伊曼模型的影响来大幅提高处理效率。我们的确有充分的理由来解释,为什么在许多场景中需要使用数字化的方式表示信号:高精确度、可靠性和确定性。然而,在晶体管物理学中发现,数字化抽象剔除了大量信息,而只追求最小的、量子化的信息:一个比特。在这样的过程中,我们付出了巨大的能源成本来用效率换取可靠性。由于人工智能的应用在本质上仍是概率的(probabilistic),因此我们必须考虑这种用效率换取可靠性是否有意义。由传统冯·诺伊曼计算机执行支撑人工智能应用的计算任务是非常计算密集的,也因此是能耗巨大的。然而,使用基于峰值(spike-based)的信号模拟或混合系统或许能够以高能效的方式执行类似任务。因此,人工智能系统的进步和新设备的出现,重新点燃人们对神经形态计算的兴趣。这些新设备提供了新的令人兴奋的方式来模拟生物神经系统的一些能力,详见方框1。
“神经形态”的定义各有千秋。一言蔽之,这是一个关于硬件的故事:类脑芯片旨在整合和利用大脑的各种有用特征,包括内存计算(in-memory computing,或译作“存算一体化”)、基于尖峰的信息处理(spike-based information processing)、细粒度并行性(fine-grained parallelism)、能够弹性应对噪声和随机性的信号处理、适应性、硬件学习、异步通信(asynchronous communication)和模拟处理(analogue processing)。尽管这其中需要具备多少才能被归类为神经形态尚无定论,但这显然是一种不同于主流计算系统上所实现的人工智能。然而,我们不应迷失在术语中,而应关注方法能否行之有效。
目前的神经形态技术方法仍然在解构与建构的两极之间上下求索:解构试图逆向拆解大脑结构和功能之间的深奥联系,建构则尽力从我们对于大脑有限的认识中寻找灵感。漫漫解构之路上,也许最重要的是人类脑计划(Human Brain Project, HBP),这个高调而野心勃勃的十年计划,自2013年起由欧盟开始资助。人类脑计划采用两个现有的类脑计算平台,并将进一步开发开放可访问的类脑计算平台,也就是曼彻斯特大学的 SpiNNaker 和海德堡大学的 BrainScaleS。这两个平台都实现了高度复杂的大脑结构硅模型来帮助我们更好地理解生物大脑的运作。而建构同样是筚路蓝缕,许多团队使用类脑计算的方法来增强数字或模拟电子设备的性能。图2总结了现有神经形态芯片范畴,根据在分析-合成和技术平台中不同的位置将其划分为四类。对我们来说更重要的是意识到,神经形态工程不仅仅是高级认知系统,在认知能力有限的小型边缘设备中它能同时提供能量、速度和安全方面的收益(起码可通过消除与云持续通信的需求来实现)。
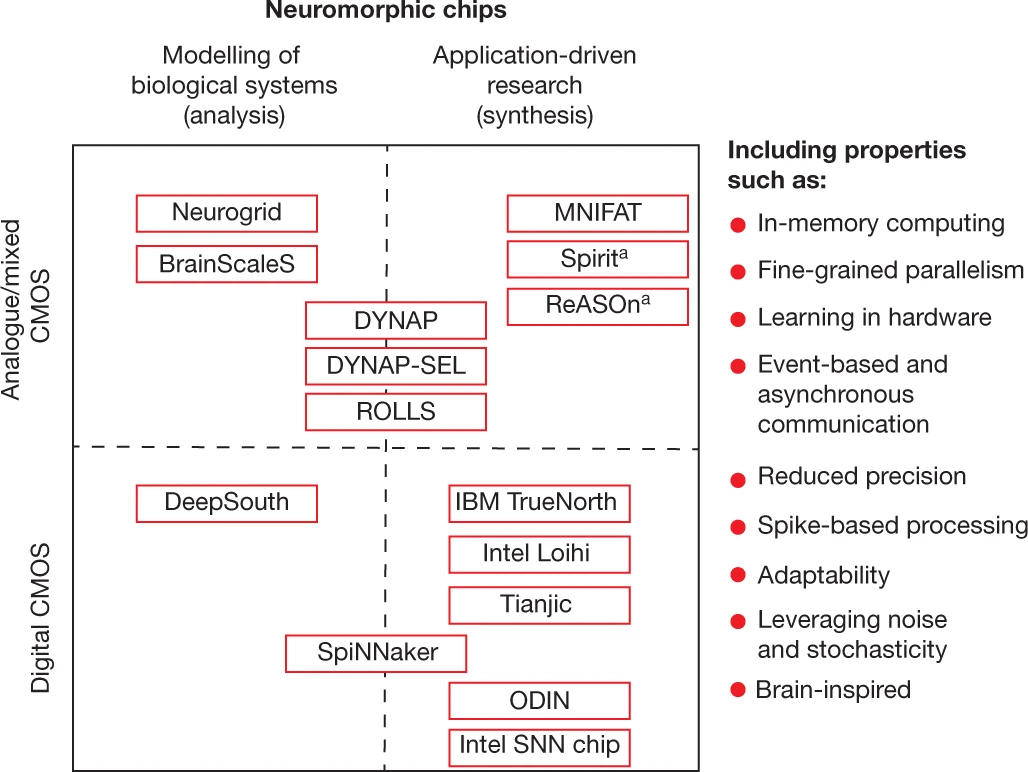
类脑芯片相关参考资料[26-40]:
-
Neurogrid:Benjamin, B. V. et al. Neurogrid: a mixed-analog–digital multichip system for large-scale neural simulations. Proc. IEEE 102, 699–716 (2014). -
BrainSclaseS:Schmitt, S. et al. Neuromorphic hardware in the loop: training a deep spiking network on the BrainScaleS wafer-scale system. In 2017 Intl Joint Conf. Neural Networks (IJCNN) https://doi.org/10.1109/ijcnn.2017.7966125 (IEEE, 2017). -
MNIFAT:Lichtsteiner, P., Posch, C. & Delbruck, T. A 128 × 128 120 dB 15 μs latency asynchronous temporal contrast vision sensor. IEEE J. Solid-State Circuits 43, 566–576 (2008). -
DYNAP:Moradi, S., Qiao, N., Stefanini, F. & Indiveri, G. A scalable multicore architecture with heterogeneous memory structures for dynamic neuromorphic asynchronous processors (DYNAPs). IEEE Trans. Biomed. Circuits Syst. 12, 106–122 (2018). -
DYNAP-SEL:Thakur, C. S. et al. Large-scale neuromorphic spiking array processors: a quest to mimic the brain. Front. Neurosci. 12, 891 (2018). -
ROLLS:Qiao, N. et al. A reconfigurable on-line learning spiking neuromorphic processor comprising 256 neurons and 128K synapses. Front. Neurosci. 9, 141 (2015). -
Spirit:Valentian, A. et al. in 2019 IEEE Intl Electron Devices Meeting (IEDM) 14.3.1–14.3.4 https://doi.org/10.1109/IEDM19573.2019.8993431 (IEEE, 2019). -
ReASOn:Resistive Array of Synapses with ONline Learning (ReASOn) Developed by NeuRAM3 Project https://cordis.europa.eu/project/id/687299/reporting (2021). -
DeepSouth:Wang, R. et al. Neuromorphic hardware architecture using the neural engineering framework for pattern recognition. IEEE Trans. Biomed. Circuits Syst. 11, 574–584 (2017). -
SpiNNaker:Furber, S. B., Galluppi, F., Temple, S. & Plana, L. A. The SpiNNaker Project. Proc. IEEE 102, 652–665 (2014). An example of a large-scale neuromorphic system as a model for the brain. -
IBM TrueNorth:Merolla, P. A. et al. A million spiking-neuron integrated circuit with a scalable communication network and interface. Science 345, 668–673 (2014). -
Intel Loihi:Davies, M. et al. Loihi: a neuromorphic manycore processor with on-chip learning. IEEE Micro 38, 82–99 (2018). -
Tianjic:Pei, J. et al. Towards artificial general intelligence with hybrid Tianjic chip architecture. Nature 572, 106–111 (2019). -
ODIN:Frenkel, C., Lefebvre, M., Legat, J.-D. & Bol, D. A 0.086-mm2 12.7-pJ/SOP 64k-synapse 256-neuron online-learning digital spiking neuromorphic processor in 28-nm CMOS. IEEE Trans. Biomed. Circuits Syst. 13, 145–158 (2018). -
Intel SNN chip:Chen, G. K., Kumar, R., Sumbul, H. E., Knag, P. C. & Krishnamurthy, R. K. A 4096-neuron 1M-synapse 3.8-pJ/SOP spiking neural network with on-chip STDP learning and sparse weights in 10-nm FinFET CMOS. IEEE J. Solid-State Circuits 54, 992–1002 (2019).
前景展望
前景展望
把握机遇
把握机遇
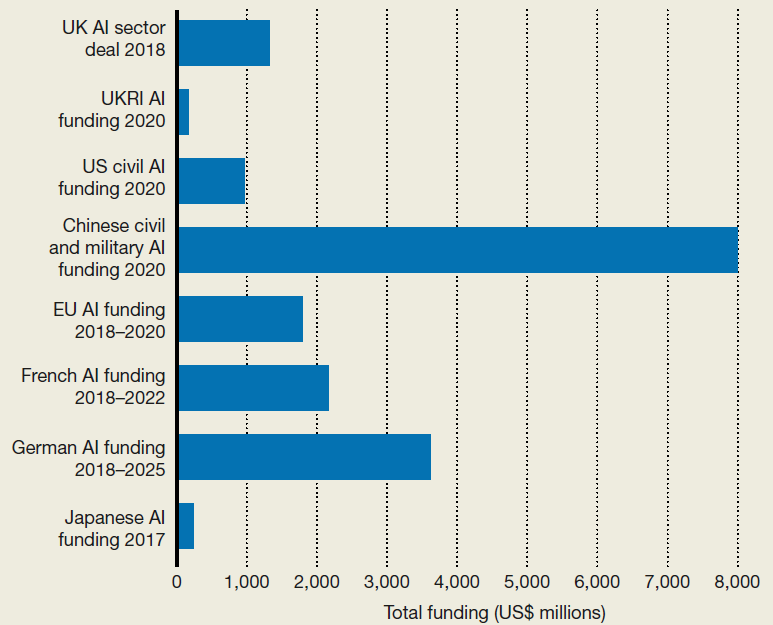
人工智能融资前景
结语
结语
参考文献
(参考文献可上下滑动查看)
神经动力学模型读书会
随着电生理学、网络建模、机器学习、统计物理、类脑计算等多种技术方法的发展,我们对大脑神经元相互作用机理与连接机制,对意识、语言、情绪、记忆、社交等功能的认识逐渐深入,大脑复杂系统的谜底正在被揭开。为了促进神经科学、系统科学、计算机科学等领域研究者的交流合作,我们发起了【神经动力学模型读书会】。
集智俱乐部读书会是面向广大科研工作者的系列论文研读活动,其目的是共同深入学习探讨某个科学议题,激发科研灵感,促进科研合作。【神经动力学模型读书会】由集智俱乐部和天桥脑科学研究院联合发起,已于3月19日开始,每周六下午14:00-16:00(或每周五晚上19:00-21:00,根据实际情况调整)进行,预计持续10-12周。期间将围绕神经网络多尺度建模及其在脑疾病、脑认知方面的应用进行研讨。

详情请见:
推荐阅读
-
类脑计算前沿:基于有机电化学网络的生物信号分类 -
网络神经科学前沿:大脑如何在局部和全局高效处理信息? -
李飞飞团队:如何制造更聪明的人工智能?让人工生命在复杂环境中进化 -
《张江·复杂科学前沿27讲》完整上线! -
成为集智VIP,解锁全站课程/读书会 -
加入集智,一起复杂!
点击“阅读原文”,报名读书会
微信扫一扫,分享到朋友圈











