量子神经网络(Quantum Neural Networks,QNN)已经提出了几种架构,目的是在量子数据上有效地执行机器学习任务。对于特定的量子神经网络结构,迫切需要严格的扩展结果,以了解哪些结构是可以大规模训练的。在这里,研究人员分析了最近提出的一种架构的梯度扩展(以及可训练性),称之为耗散量子神经网络(dissipative QNN,DQNN),其中每一层的输入量子比特在该层的输出被丢弃。研究人员发现,DQNN可以表现出贫瘠高原,即梯度随量子比特的数量呈指数级消失。此外,研究人员提供了不同条件下DQNN梯度扩展的定量界限,如不同的损失函数和电路深度,并表明可训练性并不总是得到保证。这项工作代表了第一个基于感知器的QNN(perceptron-based QNN)可扩展性的严格分析。
研究领域:量子神经网络,机器学习
论文题目:
Trainability of Dissipative Perceptron-Based Quantum Neural Networks
https://journals.aps.org/prl/abstract/10.1103/PhysRevLett.128.180505
神经网络(neural network,NN)已经影响了许多领域,如神经科学、工程、计算机科学、化学和物理学。然而,由于严重的技术挑战,它们的历史发展在进步期与停滞期之间徘徊。感知器很早就作为一种人工神经元被引入,但后来才意识到多层感知器比单层感知器有更大的能力。但仍然存在着如何训练多层感知器的主要问题,这一点最终由反向传播法解决。
在神经网络的成功和 NISQ(Noisy Intermediate-Scale Quantum)设备出现的激励下,人们一直在努力开发量子神经网络(Quantum Neural Network,QNN),希望量子神经网络能够利用量子计算机的力量,在机器学习任务上胜过经典计算机,特别是对于量子数据或本质上属于量子的任务。
尽管有几个QNN方案已经成功实施,但仍需对特定架构的优势和局限性进行更多研究。深入研究QNN的潜在可扩展性问题可以帮助防止这些模型出现“冬天”,就像历史上经典神经网络的情况一样。这推动了最近研究QNN中梯度扩展的工作。该研究表明,旨在训练QNN完成特定任务的变分量子算法,可能表现出梯度随系统大小呈指数性消失。这种所谓的“贫瘠高原现象”,被证明适用于硬件高效的QNN,其中量子门被安排在与量子设备的连接相匹配的块状结构中。
在这里,研究人员考虑一类不同的QNN,称之为耗散量子神经网络(Dissipative Neural Network,DQNN)。在DQNN中,网络中的每个节点都对应于一个量子比特,而网络中的连接由量子感知器模拟。耗散指的是辅助量子比特构成输出层,而输入层的量子比特被丢弃的事实。这种架构最近受到了极大的关注,并被提议作为QNN的一种可扩展的方法。
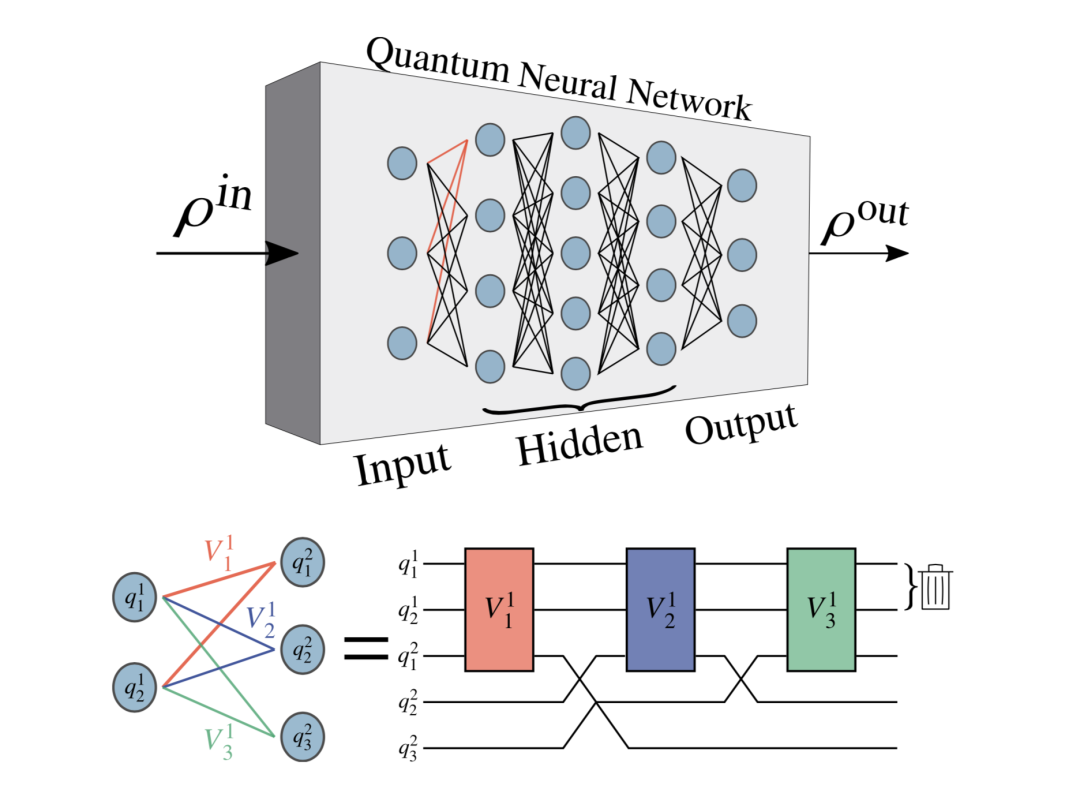
图:基于耗散感知器的量子神经网络(DQNN)的示意图。顶部:DQNN由输入层、隐藏层和输出层组成。网络中的每个节点都对应于一个量子比特,它可以通过感知器(以线表示)连接到相邻层的量子比特。DQNN的输入和输出是量子状态,分别记为ρin和ρout。第l层的第j个量子比特表示为qjl。每个感知器对应于它所连接的量子位上的一个单元操作,Vjl表示第l层的第j个感知器。
研究人员首先证明,DQNN的可训练性并不总是有保证的,因为它们在损失函数中可能表现出贫瘠高原现象。这种贫瘠高原的存在与感知器和损失函数的局部性有关。具体而言,研究人员证明:(1)具有深度全局感知器的DQNN是不可训练的,尽管该结构具有耗散性;(2)对于浅层和局部感知器,采用全局损失函数会导致贫瘠高原现象,而采用局部损失函数则可以避免该现象。
此外,研究人员还为DQNN提供了一种特定的体系结构,该体系结构具有局部浅层感知器,可以精确地映射到分层硬件高效的QNN。这一结果不仅表明DQNN与硬件效率高的QNN一样具有可表达性,而且还允许研究人员为这些DQNN提供可训练性保证。在这种情况下,由于感知器是局部的,每个神经元只从前一层的少量量子比特接收信息。这种结构让人想起经典的卷积神经网络,众所周知,卷积神经网络可以避免完全连接网络的一些可训练性问题。
这些结果表明,要理解QNN的可训练性,并确保它们实际上比经典神经网络具有优势,还有很多工作要做。例如,有趣的未来研究方向是QNN特定的优化器,分析QNN对噪声的容错性,以及防止贫瘠高原现象的策略。此外,探索DQNN和硬件高效的QNN之外的体系结构,尤其是如果此类体系结构具有大规模可训练性,将是一个有意义的课题。
Several architectures have been proposed for quantum neural networks (QNNs), with the goal of efficiently performing machine learning tasks on quantum data. Rigorous scaling results are urgently needed for specific QNN constructions to understand which, if any, will be trainable at a large scale. Here, we analyze the gradient scaling (and hence the trainability) for a recently proposed architecture that we call dissipative QNNs (DQNNs), where the input qubits of each layer are discarded at the layer’s output. We find that DQNNs can exhibit barren plateaus, i.e., gradients that vanish exponentially in the number of qubits. Moreover, we provide quantitative bounds on the scaling of the gradient for DQNNs under different conditions, such as different cost functions and circuit depths, and show that trainability is not always guaranteed. Our work represents the first rigorous analysis of the scalability of a perceptron-based QNN.
集智斑图顶刊论文速递栏目上线以来,持续收录来自Nature、Science等顶刊的最新论文,追踪复杂系统、网络科学、计算社会科学等领域的前沿进展。现在正式推出订阅功能,每周通过微信服务号「集智斑图」推送论文信息。扫描下方二维码即可一键订阅:

点击“阅读原文”,追踪复杂科学顶刊论文