跨领域视角下的无偏因果推理

导语
真实数据自然呈现长尾分布,深度学习模型受长尾分布影响易造成尾部类型识别性能不佳,现有去偏方法多以牺牲头部类别性能为代价来提升尾部类别性能。在集智俱乐部因果科学读书会第三季,来自新加坡南洋理工大学的牛玉磊博士详细介绍了他们基于因果理论从跨领域经验风险最小化视角构建无偏推理模型解决长尾分布数据学习问题的最新研究进展,本文是分享的文字整理。
研究领域:因果关系、长尾分布、无偏学习

牛玉磊 | 讲者
郝卓 | 整理
邓一雪 | 编辑
1. 有偏数据与无偏推理
1. 有偏数据与无偏推理
真实场景数据普遍呈现长尾分布的形式,比较有名的涉及长尾分布的研究包括自然语言处理领域的Zipf定律和经济学中的帕累托分布等。长尾分布数据固有的数据偏置为机器学习带来了困难,同时构造均衡分布的数据集费时费力甚至在某些特殊数据环境下难以实现,所以模型在有偏数据条件下进行无偏学习非常重要。
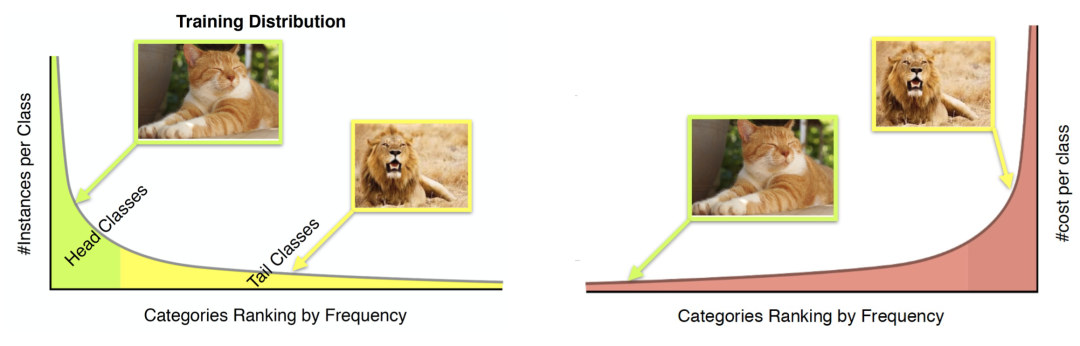
图1. 有偏数据广泛存在且为模型的学习带来了困难
在计算机视觉研究领域,针对有偏数据进行去偏学习的工作很多,但仍难以做到真正的去偏。以视觉问答和长尾分类研究任务为例,在视觉问答领域,如图2所示,去偏模型在提升去偏能力的同时难以保持对于原有数据分布的性能,同样在长尾分类研究领域,如图3所示,无论测试数据集的真实分布如何,去偏模型均以过度倾向尾部类别预测的方式来提升尾部类别性能。通过上述两个例子可以表明,现有去偏模型都存在以牺牲头部类别为代价提升尾部类别性能的不足,并没有做到真正的无偏学习。
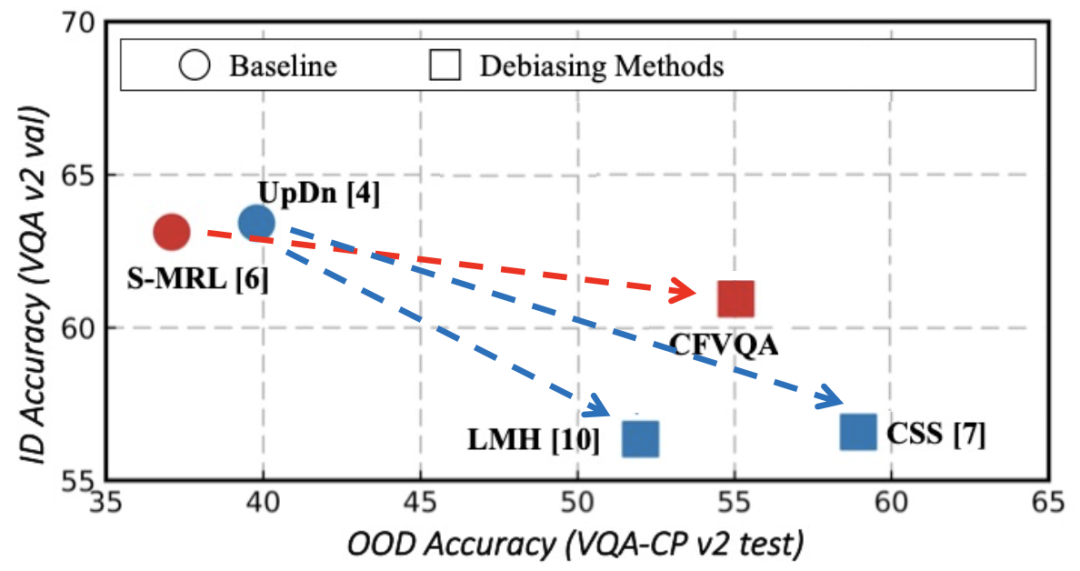
图2. 视觉问答系统去偏模型与有偏模型性能对比
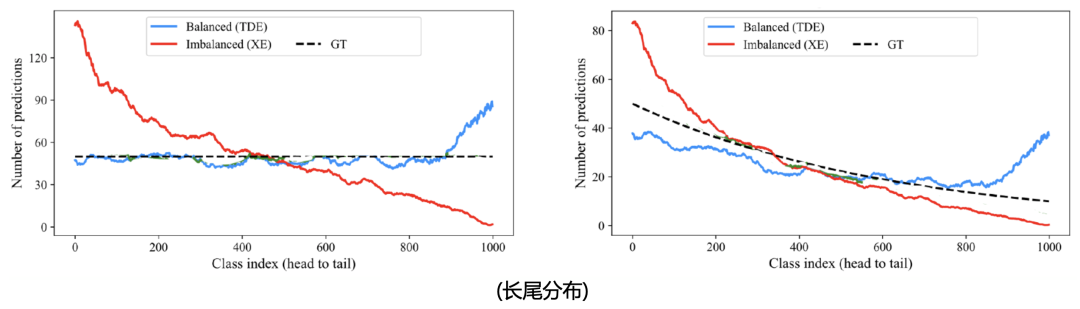
图3. 长尾分布任务去偏模型与有偏模型性能对比
能否在兼顾头部类别性能的同时提升尾部类别的性能实现“两全其美”,我们针对问答系统和长尾分类任务分别介绍从跨领域经验风险最小化视角构建无偏学习模型的具体进展。
2. 应用场景:问答系统
2. 应用场景:问答系统
问答系统的研究包括视觉问答(VQA)和抽取式机器阅读理解等,图4揭示了两类任务预测结果偏见的来源。在VQA任务中,若问题与答案之间有过强的先验相关性,则会对模型的学习结果产生较大的影响。同理,在阅读理解任务中若问题答案与文本位置强相关,同样会造成模型的偏见。综上可以归纳为语言的先验假设过多影响了模型的学习,即去偏模型相当于在与原有数据分布不同的基础上,假设了一个去偏分布进行学习,以牺牲原有数据分布(In-Distribution, ID)的性能为代价获得了部分分布外(Out-of-Distribution, OOD)的泛化能力。因此,针对此类任务无偏模型的改进可以理解为如何使模型获得兼顾ID和OOD分布的泛化能力。

图4. 视觉问答和阅读理解任务中的偏置
3. 反省蒸馏方法
3. 反省蒸馏方法
以视觉问答任务为例,基于融合两种领域知识为出发点我们提出了反省蒸馏方法来实现“鱼与熊掌兼得”。首先针对有偏模型和去偏模型的特点,分析ID和OOD模型在融合时遇到的三种情况,如图5所示,若ID模型的归纳偏置过强,则模型应相应的增加OOD模型的权重,实现无偏的预测,反之亦然。我们用模型对于当前样本的损失XE刻画其置信度s,则相应模型的权重ωID和ωOOD的计算方法如下:
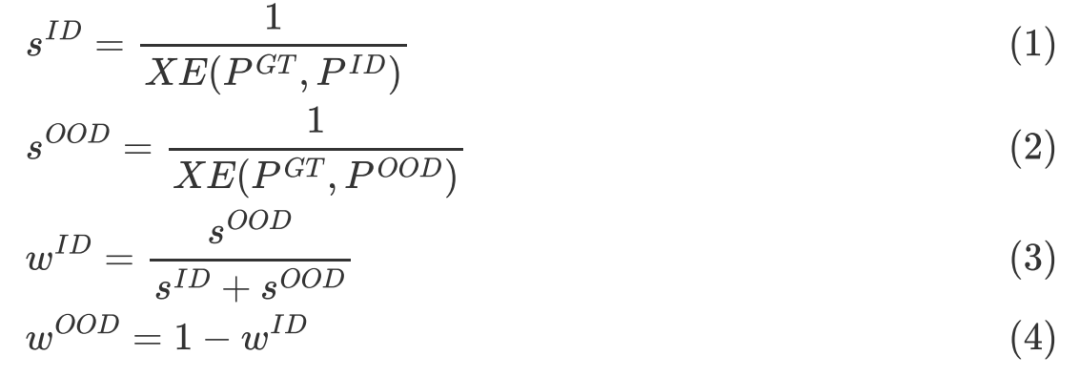

模型计算的具体步骤可以归纳为首先分别训练ID和OOD模型作为教师模型,然后基于ID和OOD模型的loss计算两个模型的权重ωID和ωOOD,进而通过加权计算得到融合后的知识PT,最终基于蒸馏学习框架训练学生模型,以实现融合ID和OOD教师模型知识的目的,模型的整体框架如图6所示。
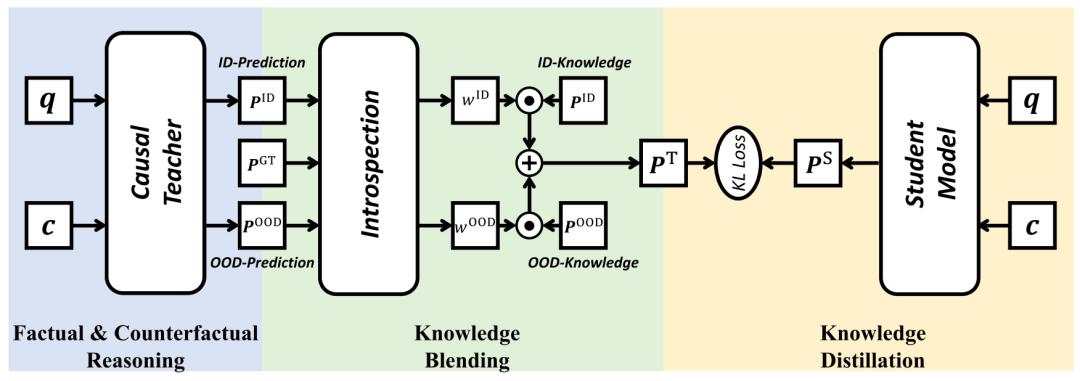
图6. 反省蒸馏方法整体框架图
图7和图8分别展示了反省蒸馏方法在视觉问答和阅读理解任务上的实验效果,结果表明反省蒸馏方法能够在兼顾ID领域知识的情况下实现OOD领域泛化能力的提升。

图7. 反省蒸馏方法在视觉问答任务上的实验结果
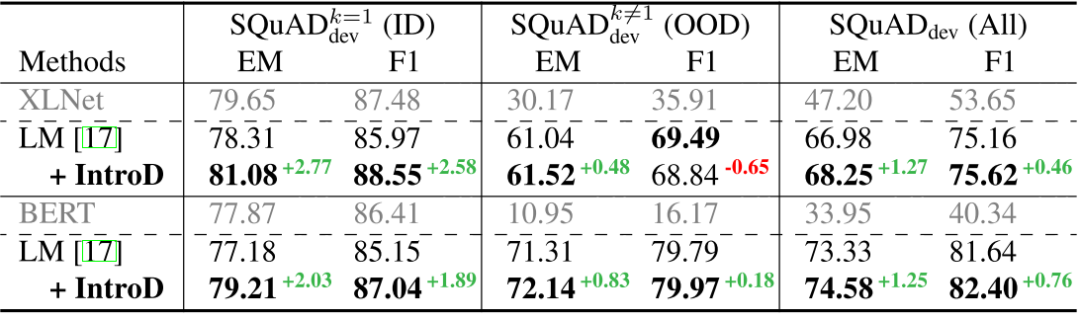
图8. 反省蒸馏方法在阅读理解任务上的实验结果
4. 应用场景:长尾分类
4. 应用场景:长尾分类
问答系统去偏方法遇到的过度归纳偏置问题可以扩展到模型在长尾分布数据条件下学习这类通用问题中。以图像分类任务为例,模型在长尾分布下学习会造成对于头部类别的严重倾向,如图9所示,对于尾部类别狮子,模型仍倾向于判别为猫这个头部类别。同时长尾分类任务模型的评价通常使用均匀分布的测试集来评估模型对各个类别的学习效果,因此对于长尾分布数据的无偏学习可以视作在均匀分布和长尾分布数据条件下的跨领域经验风险最小。

图9. 长尾分布数据条件下不利于尾部类别学习
5. 跨领域风险最小化的因果视角
5. 跨领域风险最小化的因果视角
从因果关系的视角分析跨领域经验风险最小化方法,我们可以发现以往的去偏模型难以实现头尾兼顾的本质是因为其受到了Selection Bias的影响。如图10所示,以s表示不同领域或称为数据的不同分布。x→y表示依据图像预测类别,后门路径x←s→y表示领域对图像采样概率和类别分布的影响,因此可以通过因果干预的方法去除领域因素带来的混杂因子,实现去偏学习。以s取值0或1分别代表均匀分布和长尾分布,将后门调整公式带入,可以得到模型的整体经验风险如下,包括均匀分布下和长尾分布下的经验风险两部分。
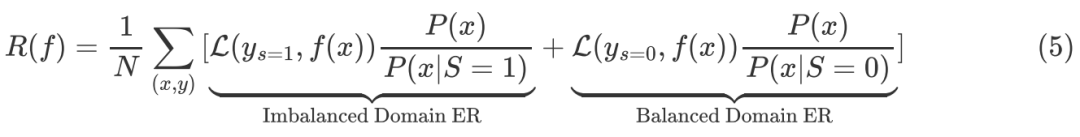
以ωimba和ωba分别代表有偏模型和去偏模型的权重,XEimba和XEba表示相应模型的loss,我们可以发现两部分经验风险权重的设置与前文提到的反省蒸馏方法相一致,即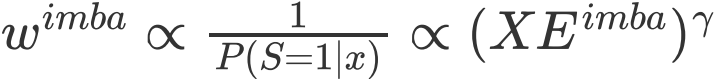 ,
,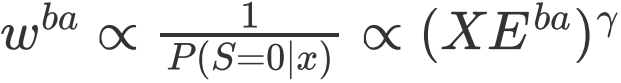 。
。

图10. 跨领域风险最小化方法的因果视角
均匀分布测试集设置和长尾分布测试集设置的实验结果如图11所示,可以发现模型在不同分布的测试集上均能得到较好的实验结果。同样我们将学到的视觉特征可视化,结果如图12所示,模型对于各个类别学到的特征类间区分度更好且热力图定位更准确,表明我们的方法在特征学习上真正得到了提升。
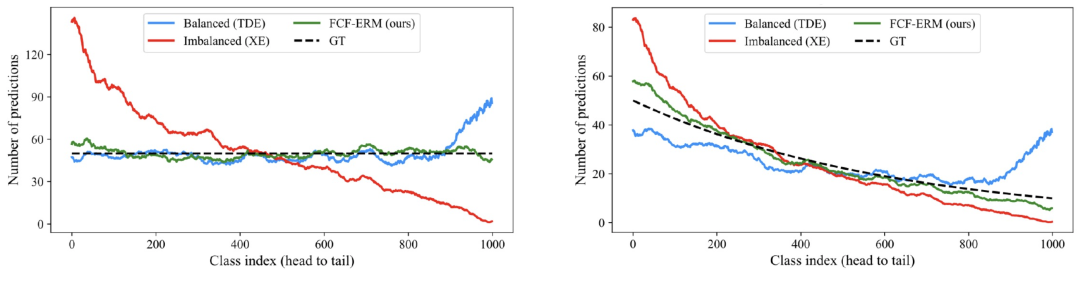
图11. 跨领域风险最小化在长尾分类任务上针对不同分布测试集设置的实验结果

图12. 跨领域风险最小化方法的特征可视化效果
参考文献
[1] Niu, Yulei, and Zhang, Hanwang. Introspective Distillation for Robust Question Answering. NeurIPS 2021.
[2] Zhu, Beier, et al. Cross-Domain Empirical Risk Minimization for Unbiased Long-tailed Classification. AAAI, 2022.
[3] Goyal, Yash, et al. Making the V in VQA Matter: Elevating the Role of Image Understanding in Visual Question Answering. CVPR 2017.
[4] Ko, Miyoung, et al. Look at the First Sentence: Position Bias in Question Answering. EMNLP 2020.
[5] Zipf, George Kingsley. Human behavior and the principle of least effort: An introduction to human ecology. Ravenio Books, 2016.
因果科学读书会第三季启动
由智源社区、集智俱乐部联合举办的因果科学与Causal AI读书会第三季,将主要面向两类人群:如果你从事计算机相关方向研究,希望为不同领域引入新的计算方法,通过大数据、新算法得到新成果,可以通过读书会各个领域的核心因果问题介绍和论文推荐快速入手;如果你从事其他理工科或人文社科领域研究,也可以通过所属领域的因果研究综述介绍和研讨已有工作的示例代码,在自己的研究中快速开始尝试部署结合因果的算法。读书自2021年10月24日开始,每周日上午 10:00-12:00举办,持续时间预计 2-3 个月。

详情请见:
因果+X:解决多学科领域的因果问题 | 因果科学读书会第三季启动
推荐阅读
-
粗看长尾,细辨幂律:跨世纪的无标度网络研究纷争史 -
图模型与因果推理基础- SCM框架和Do-Calculus -
崔鹏:稳定学习——挖掘因果推理和机器学习的共同基础 -
《张江·复杂科学前沿27讲》完整上线! -
成为集智VIP,解锁全站课程/读书会 -
加入集智,一起复杂!
点击“阅读原文”,报名读书会
微信扫一扫,分享到朋友圈











