速递:RNN可在加入白噪音后学到数据合适的隐藏维度

摘要
神经网络需要输入数据的正确表征来学习。近日发表于 Nature Machine Intelligence 的新研究考察梯度学习如何塑造循环神经网络(RNN)表征的一个基本属性ーー它们的维数。通过模拟和数学分析,研究展示了梯度下降法如何引导 RNN 压缩其表征的维度,在一定程度上满足训练期间的任务需求,同时支持泛化到未知示例。为达成这一目标,需要在训练的早期扩展维度,在训练后期压缩维度,研究发现具有强混沌特性的 RNN 似乎特别擅长学习这种平衡。该研究除了有助于阐明适当初始化的 RNN 对训练的益处,还揭示了大脑中的神经回路与混沌的关系。总之,该发现显示了简单的基于梯度的学习规则如何引导神经网络产生可解决任务的鲁棒性表征,这样的表征可以泛化到新情况。
研究领域:表征学习,剃度下降,循环经济网络,混沌,网络动力学

郭瑞东 | 作者
邓一雪 | 编辑

论文题目:
Gradient-based learning drives robust representations in recurrent neural networks by balancing compression and expansion
论文链接:
https://www.nature.com/articles/s42256-022-00498-0
1. 如何确定合适的表征维度?
1. 如何确定合适的表征维度?
在有监督学习前,将原始数据转换为适合的特征必不可少,该步骤被称为表征学习。其中关键的步骤是确定数据的维度,高维表征可以包含有用特征的非线性组合,适合据此构建简单的分类模型,而低维的表征可以保留关键特征,允许基于更少的参数和例子进行学习,因此具有更好的泛化能力。
由此一个有现实意义的问题是,如何确定合适的表征维度。该研究证明,RNN 的动力学特征能够基于梯度下降产生适合的表征维度。具体的算法步骤如图1,其中输入是待分类的高维数据,之后模型在训练过程中,以上一层的输出为输入构建数据表征(尝试构建一个能够区分两类数据的超平面),最后将前9步的表征加和,通过分类算法的准确度评价表征模型。而表征模型的训练则依据评价结果,使用梯度下降进行。
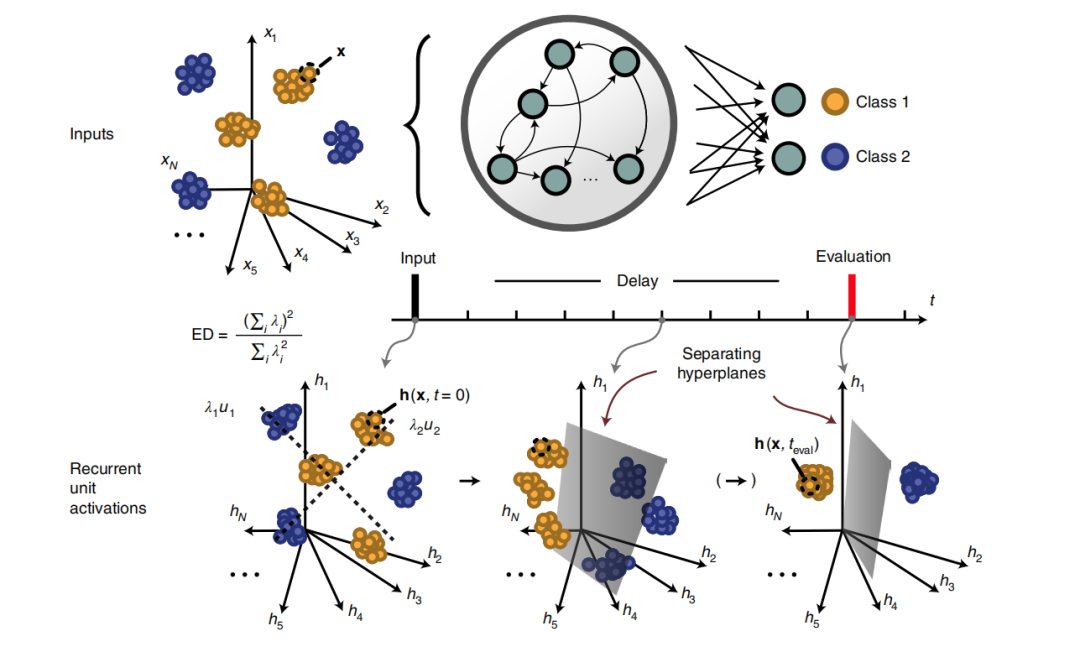
图1:算法的任务和使用模型的图示
2. 神经网络与混沌
2. 神经网络与混沌
在已知数据隐藏的维度是两维时,该实验对比了处在混沌边缘与强混沌状态的RNN网络,发现处于强混沌状态的网络达到相近的分类精度,所需的训练数据更少(图2d);训练后能够得到合适的有效表征维度(图2e),对训练后得到的表征使用线性回归进行分类时,准确性更高(图2f),泛化能力更好(图2g)。
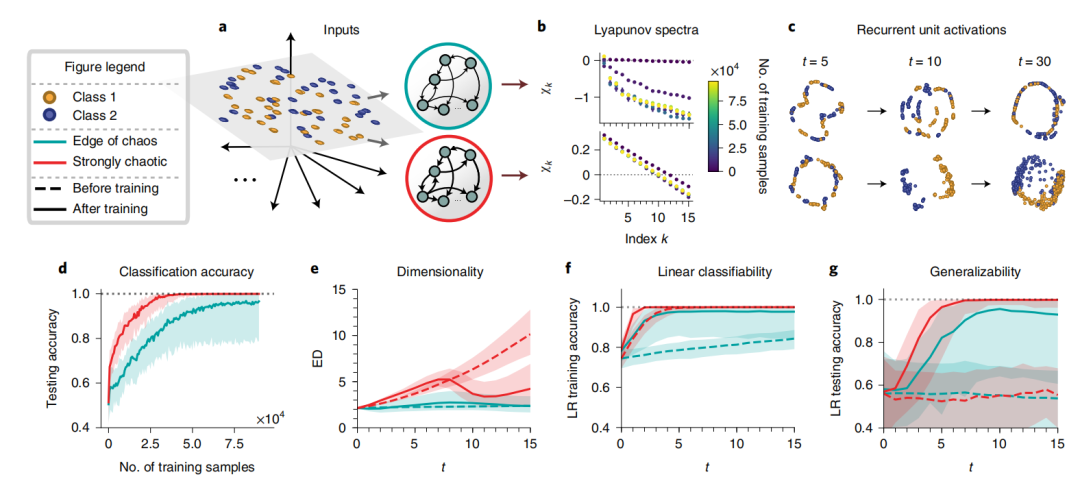
图2:二维输入分类网络学习的动力学和几何性质
以上数据说明,对于隐藏维度大于等于2维的情况,处于强混沌状态的RNN能够学得合适的隐藏维度,并得出可用线性模型进行分类的表征。相比处于混沌边缘的RNN,处于强混沌状态下的RNN效果更好。
之所以RNN能通过学习得到压缩表征,可以来自稳定不动点的形成(对于最初处于混沌边缘的网络),也可以来自低维混沌吸引子(对于强混沌状态下的网络)。这意味着通过训练稳定的网络学习解决任务时,经过训练的评估期前后对比,保持混乱的那部分网络会被重置。前者(处于混沌边缘的网络)可能有利于长期记忆;后者(来自低维混沌吸引子的网络)可以用于灵活地学习新任务。
3. 表征模型的学习机制
3. 表征模型的学习机制
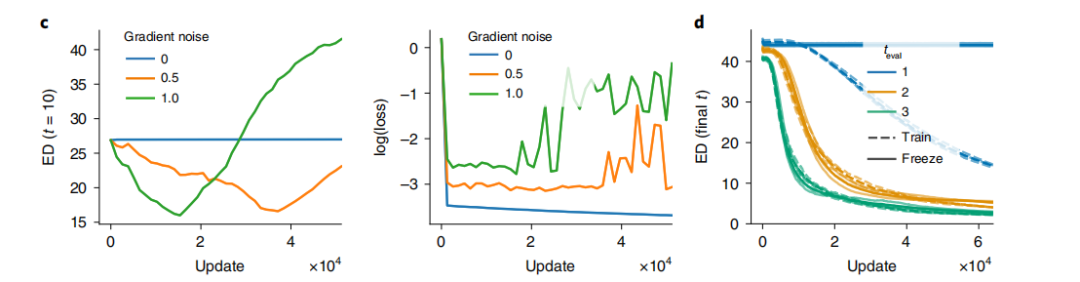
之后,将评价指标由衡量分类结果的交叉熵,变为衡量分类置信度的均方误差损失,通过使用连续而非离散的评价指标,可研究表征模型的学习机制。发现在不向节点加入随机噪音时,训练过程中模型不会试图降低有效维度(图3c左),而是始终让模型的预测误差极低(用更多的表征换取更好的预测效果),然而包含噪音的模型会试图降低有效维度,尽管这样会导致预测误差增大。而图3d展示了训练完成时最终的有效表征维度,训练过程中,神经元梯度增加的高斯噪音比例越大,模型就能够更快学到合适的隐藏维度。
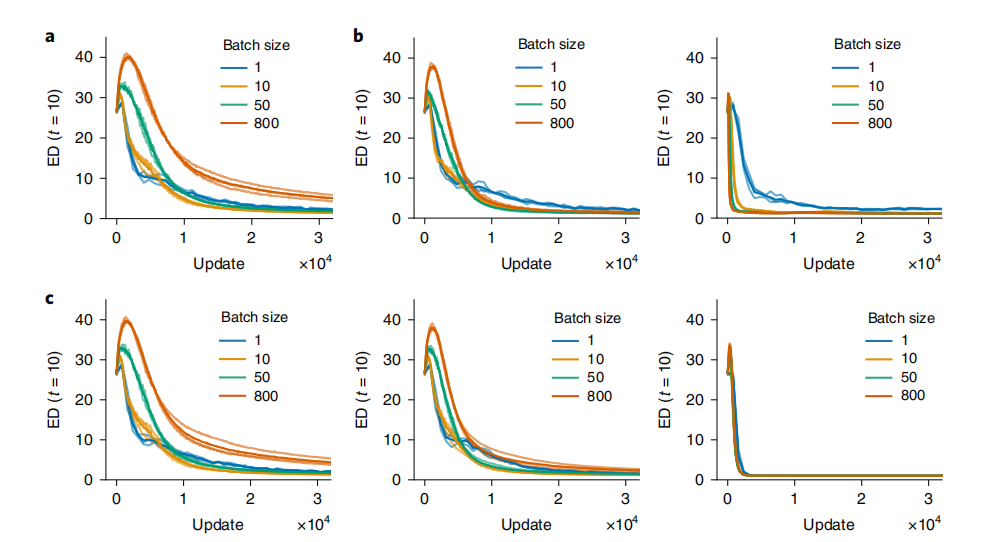
进一步对比不同的正则化方法带来的影响:图4a是不包含噪音时,不同大小的训练批次(batch size)最终学到的维度;图4b左边是训练过程中神经元梯度添加白噪音时的情况,右边是包含白噪音,且采用dropout进行正则化的影响;图4c从左到右分别展示了加入较弱、中等水平、较强L2正则化项时的情况。可以看到使用强L2正则,以及drop out时效果接近,都能够在包含白噪音时,学到合适的隐藏维度。这说明该RNN学习的机制正是基于学习过程中的随机噪音。
总结来看,该研究指出RNN可以学会以一种适合于手头任务的方式来平衡表征学习中的压缩和混沌,从而得到适合的表征维度,而学习过程中的驱动力来自神经元梯度改变过程中的噪音。目前对大脑所使用的学习规则的理解仍然处在早期阶段,而一个常见的假设是大脑以梯度下降的方式进行学习,该研究增强了该假说的可行性范围,并提出了两个可能的学习机制(白噪音及正则化)以及对应的验证方式。
论文 Abstract
神经动力学模型读书会
随着电生理学、网络建模、机器学习、统计物理、类脑计算等多种技术方法的发展,我们对大脑神经元相互作用机理与连接机制,对意识、语言、情绪、记忆、社交等功能的认识逐渐深入,大脑复杂系统的谜底正在被揭开。为了促进神经科学、系统科学、计算机科学等领域研究者的交流合作,我们发起了【神经动力学模型读书会】。
集智俱乐部读书会是面向广大科研工作者的系列论文研读活动,其目的是共同深入学习探讨某个科学议题,激发科研灵感,促进科研合作。【神经动力学模型读书会】由集智俱乐部和天桥脑科学研究院联合发起,已于3月19日开始,每周六下午14:00-16:00(或每周五晚上19:00-21:00,根据实际情况调整)进行,预计持续10-12周。期间将围绕神经网络多尺度建模及其在脑疾病、脑认知方面的应用进行研讨。

详情请见:
推荐阅读
-
PNAS速递:基于相似加权交叉学习的深度神经网络和大脑学习 -
PRL速递:在耗散量子神经网络上训练机器学习模型 -
PRL速递:重整化理论描述神经网络动力学 -
《张江·复杂科学前沿27讲》完整上线! -
成为集智VIP,解锁全站课程/读书会 -
加入集智,一起复杂!
微信扫一扫,分享到朋友圈











