城市是一个复杂而动态的生态系统,而识别城市不同区域的人口流动是理解这个复杂系统的关键。2021 年发表在 Nature Communications 的一篇文章在传统的引力模型基础上提出了深度引力模型,该模型利用了从自愿地理数据中提取的许多特征(如土地使用、道路网络),并使用深度神经网络来发现这些特征和人口流动之间的非线性关系。作者展示了该模型在英国、意大利和纽约州的人口移动流生成中表现出的优越性能,还使用可解释的机器学习技术来解释深度引力模型生成的流量,并强调了三个国家之间的关键差异。
集智俱乐部组织的「计算社会科学读书会」第二季已经启动报名,将聚焦讨论Graph、Embedding、NLP、Modeling、Data collection等方法及其与社会科学问题的结合,并针对性讨论预测性与解释性、新冠疫情研究等课题。读书会6月18日开始,持续10-12周,详情见文末。
研究领域:移动行为,引力模型,城市计算,可解释的机器学习
论文题目:
A Deep Gravity model for mobility flows generation
https://www.nature.com/articles/s41467-021-26752-4
世界上大部分人口都生活在城市地区,其流动的结构和规模的演变影响着我们社会的关键方面。近年来,人类移动行为已经成为一个研究热点,特别是对城市之间和从农村到城市的人口迁移、人群移动模式的研究和建模,城市人口的估计,气候变化和自然灾害引发的迁徙的预测以及对流行病传播的预测。准确描述以上过程动态的能力取决于我们对潜在空间流动特征的理解。因此,理解人口空间流动的模式对于提高城市的包容性、安全性、韧性和可持续性至关重要。
在人类流动研究的所有相关问题中,移动流的产生(流生成)特别具有挑战性。简单地说,这个问题包括在没有任何历史信息的情况下,根据人口和地理特征(如人口和距离),生成一组地点之间的流动(例如,有多少人从一个地点移动到另一个地点)。
这项工作最经典的是由哈佛大学教授齐普夫(George K. Zipf)提出的引力模型,即与牛顿的万有引力模型类似,两个地点之间的出行者的数量(流量)随着地点的人口增加而增加,同时随着它们之间的距离增加而减少。
鉴于引力模型的可解释性较强,且只需要几个参数,它已经在交通规划、空间经济学和流行病传播建模等领域得到广泛应用。但这个模型也存在很明显的缺陷。
首先,由于引力模型依赖于一组有限的变量,通常只是人口和地点之间的距离,流量的产生没有考虑与地理景观的复杂性有关的重要信息,如土地利用、兴趣点(POI)的多样性和交通网络。
其次,已经由很多研究表明城市建成环境与出行行为之间存在非线性的关系,两地实际流量的可变性大往往是大于预期的,而忽略了这种非线性关系的引力模型很难准确地捕捉实际流量的结构。
这种非线性关系可以通过机器学习强大的非线性模型进行捕捉,比如深度学习领域的各种交通流量预测模型,已经是很成熟的领域。本质上,交通预测是一个带有时空附加信息多步的时间序列预测问题,即给定历史交通流量和外部环境,预测未来交通状况。但很多地区往往没有历史流量的数据,在多大程度上可以在不了解历史流量的情况下生成现实的流量就成了一个值得探讨的问题。
论文作者提出的深度引力模型(Deep Gravity)结合了传统引力模型和深度学习流量预测模型的优势,引入更多能反映城市复杂环境的的地理信息,并通过深度神经网络引入非线性特征。该模型能够在没有历史流量数据的前提下,实现两地人口移动流的生成。
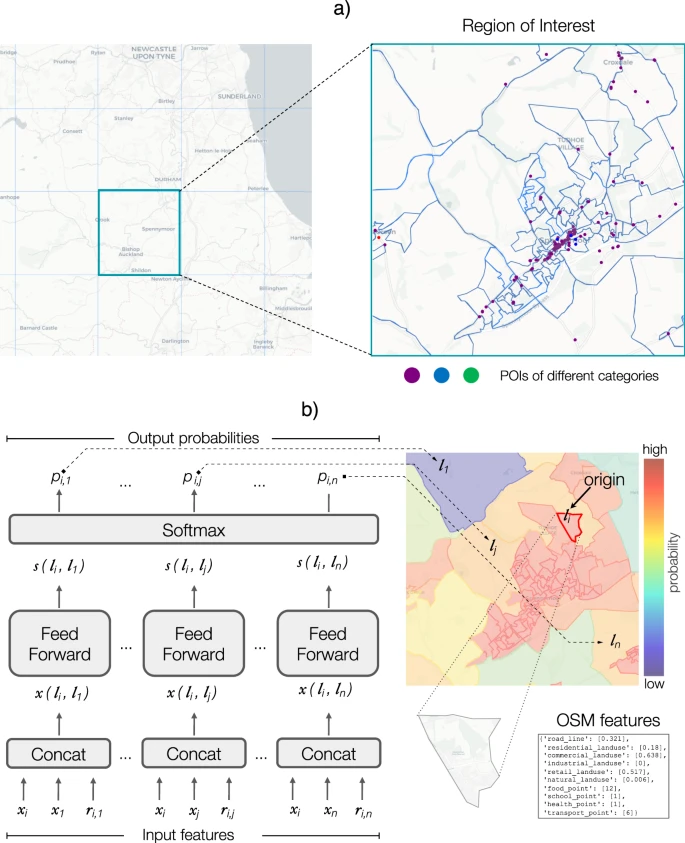
图1. 深度引力模型的的流生成和模型架构。(a)地理空间被划分为感兴趣的研究区域(网格),每个感兴趣的区域被进一步分割成不同的地点。在训练阶段,一半的兴趣区域用于训练模型,剩下的一半用于测试模型的性能。(b)深度引力模型的结构。输入特征 xi(起点位置 li 的特征向量)、xj(目的地位置lj的特征向量)和 ri, j(原点和目的地之间的距离)被连接起来,得到输入向量 x(li,lj) 。这些向量被平行地送入具有 LeakyReLu 激活函数的 15个 隐藏层的同一前馈神经网络。最后一个隐藏层的输出是一个得分 s(li, lj) 。一对地点(li,lj)的得分越高,观察到从 li 到 lj 的出行的概率就越高。最后,一个 softmax 函数被用来将得分转化为概率 pi, j,它是总和为 1 的正数。
图 1 展示了深度引力模型的框架。该模型先把研究区域划分割为不同的地点,分割的标准可以是行政区划也可以是人口普查区。每个地点都有地理信息变量,这些信息都是从 OpenStreetMap(https://www.openstreetmap.org)这一公共和开源的地理信息系统中提取的兴趣点计算得到。这些变量描述了城市地区的基本方面,如土地使用(商业、住宅和工业等)、道路网络特征(不同类型道路长度)、交通、食品、卫生、教育和零售设施。
作者通过在传统引力模型中添加非线性和隐藏层以及额外的地理特征来定义了深度引力模型。
因此,每个移动流由 39 个特征(18 个起点的地理特征和 18 个终点的地理特征、起点和终点之间的距离及其人口)来描述,模型输出为两地的出行的概率。
为了评估深度引力模型的性能,作者分别分析了英国、意大利和美国纽约州的人口普查区之间的流动性。模型性能指标用的是评估交通流量生成模型性能的最常用指标是 Sørensen-Dice 指数,也称为 Common Part of Commuters (CPC),该指标等价于准确度,即模型正确预测的出行目的地的比例。
在人口密度高的地区,相比于经典的引力模型,深度引力模型的性能提高了 66%(意大利)、246%(英国)和 1076%(纽约州)。不同国家是性能差异现可能是由空间单元的形状和大小、流量的稀疏性和流动性数据来源的差异造成的。此外,深度引力模型还具有良好的泛化能力,使其适用于在地理上与用于训练模型的地区不相连的地区。
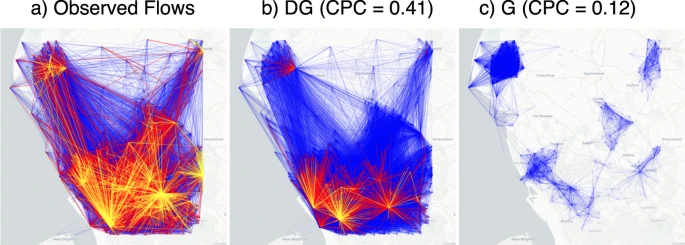
图2. 实际流量与生成流量的对比。(a)描述英国利物浦北部观察到的实际流量。(b)有深度引力模型生成的移动流量。(c)有经典引力模型生成的流量。
图2 将英国利物浦的实际人口移动流与深度引力模型和经典引力模型的生成流进行了对比。无论在流量值的结构和分布方面,深度引力模型的流量网络都比经典引力模型的流量网络在视觉上更类似于真实网络。虽然深度引力模型和经典引力模型都低估了流量,但深度引力模型比经典引力模型更准确地抓住了流量网络的整体结构。
尽管总体 CPC = 0.41 可能看起来很低,但考虑到人类流动性是一个高度复杂的系统:一方面,影响人们移动决策的因素数量远远超过可用地理特征捕获的因素;另一方面,移动流具有内在的随机成分,因此无法以确定性方式对单个移动事件的预测。
论文作者还对比了模型在人口密度高和低不同地区的表现。无论是深度引力模型还是经典引力模型,它们在人口稀少的感兴趣区域更准确,因为在人口稠密的区域有许多相关位置,因此预测出行的正确目的地变得更加困难。但随着人口密度的增加,深度引力的性能下降得更少。
深度引力模型不依赖于特定的地理环境,只要有适当的信息,如区域方格、每个地点的总流出量、地点的人口和关于兴趣点的信息,就能在任何城市聚集区的地点之间产生移动流。这就为模型的地理可解释性和可转移性打开了一扇大门。
但是,该模型使用的深度人工神经网络本质上是一个黑箱。而对于现实的城市管理和规划,知道每个变量发挥怎样的作用是十分重要的,因此十分有必要打开这个黑箱。这涉及近年来学界倡导的可解释的机器学习,即人工智能系统的行为应该是透明的、可解释的和可信的。
为此,作者使用 SHapley Additive exPlanations (SHAP)值来了解不同地理特征如何在模型中发挥作用。SHAP 值估计了每个特征的在模型预测中的贡献,表示与数据集的平均预测相比,该特征的存在或不存在如何改变对特定实例的模型预测。
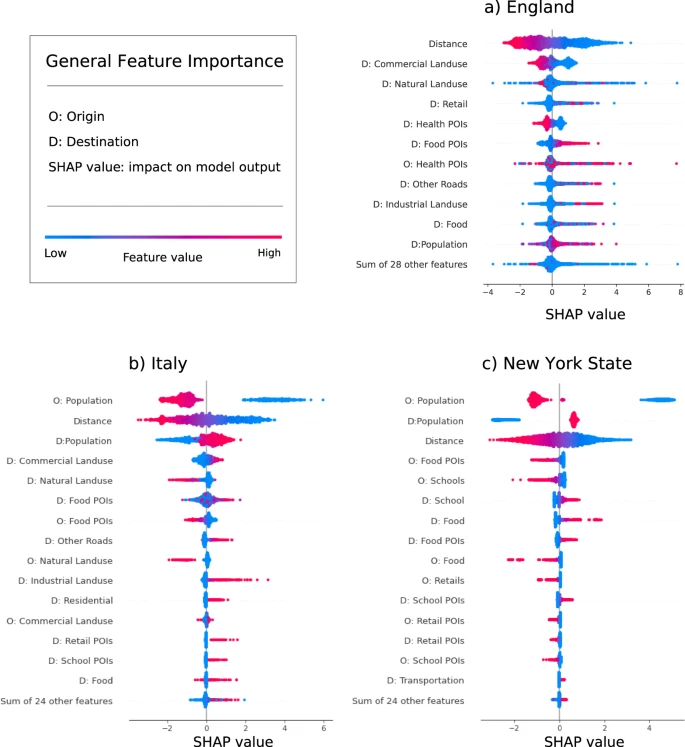
图3. 解释深度引力模型。英格兰(a)、意大利(b)和纽约州(c)的深度引力模型中所有特征的 SHAP 值分布。特征在纵轴上报告,并从上面的最相关到下面的最不相关进行排序。以“D: ”和 “O: ”开头的特征名称分别表示目的地和出发地的特征。每个点表示一个出发地-目的地对,其中蓝色的点代表特征值低的对,红色的点代表特征值高的对。该点在横轴上的位置代表了该特征对出发地和目的地的 SHAP 值,也就是说,该特征是否有助于增加或减少该对的流量概率。例如,长距离往往是一种出行障碍,而短距离则与出行者的增加有关。
图 3 展示了英格兰、意大利和纽约州的深度引力模型中所有输入特征的 SHAP 值分布。具有较大SHAP 值的最相关特征之一是地理距离,正如预期的那样,出发地和目的地之间的大距离有助于减少流动概率,而小距离则会使其增加。目的地的人口也与人口移动很相关,特别是在意大利和纽约州。
然而,在英国,与引力模型的通常假设(即流动概率是人口的递增函数)相反,发现人口具有混合效应,人口特征的高值(图3a中的红色点)也可能导致预测流量的减少。一个可能的解释是,住宅区的人口较多,但不可能是通勤旅行的目的地,而与商业和工业用地、医疗和食品有关的其他地理特征比人口更相关。例如,拥有大量食品设施、零售和工业区的地点被预测会吸引通勤者。另一方面,拥有与健康有关的兴趣点和商业用地的地点,预计会有较少的通勤者。
与英国不同,在意大利和纽约州(图3b、c),出发地和目的地的人口是对模型输出影响最大的特征。特别是,出发地人口少和目的地人口多都会增加流动概率。在意大利和纽约州,人口和距离比其他地理特征更相关。
以上发现反映了不同变量在不同地区的非线性关系。因此,一个能够捕捉人口和距离之间现有非线性关系的深度学习模型能够准确预测流动概率,而其他地理特征只带来边际贡献,所以模型的解释应该考虑到流动生成的特殊性(如空间性、网络性)。
总而言之,这篇论文的分析清楚地表明,深度神经网络和自愿地理信息的结合显着提高了移动流生成的真实性,为新型数据驱动的流生成模型铺平了道路。在模型可解释性方面,正如从深度引力模型中提取的解释所描述的,自愿地理信息和非线性的影响因国家而异:虽然在英格兰,地理信息在模型性能中的作用最强,但非线性在意大利和纽约占主导地位状态。需要做更多的工作来深入研究这些有趣的差异。
值得注意的是,除了传统的引力模型,也有很多其他在人口移动建模中表现不错的模型,比如介入机会模型、辐射模型和矢量场模型,因此能否将这些模型与现有的数据驱动和深度学习结合起来,也值得关注。
计算社会科学作为一个新兴交叉领域,越来越多地在应对新冠疫情、舆论传播、社会治理、城市发展、组织管理等社会问题和社科议题中发挥作用,大大丰富了我们对社会经济复杂系统的理解。相比于传统社会科学研究,计算社会科学广泛采用了计算范式和复杂系统视角,因而与计算机仿真、大数据、人工智能、统计物理等领域的前沿方法密切结合。为了进一步梳理计算社会科学中的各类模型方法,推动研究创新,集智俱乐部发起了计算社会科学系列读书会。
新一季【计算社会科学读书会】由清华大学罗家德教授领衔,卡内基梅隆大学、密歇根大学、清华大学、匹兹堡大学的多位博士生联合发起,自2022年6月18日开始,持续10-12周。本季读书将聚焦讨论Graph、Embedding、NLP、Modeling、Data collection等方法及其与社会科学问题的结合,并针对性讨论预测性与解释性、新冠疫情研究等课题。读书会详情及参与方式见文末,欢迎从事相关研究或对计算社会科学感兴趣的朋友参与。
详情请见:
数据与计算前沿方法整合:计算社会科学读书会第二季启动