信仰陷阱:解决有害信念的惰性 | 复杂性科学顶刊精选9篇
集智斑图顶刊论文速递栏目上线以来,持续收录来自Nature、Science等顶刊的最新论文,追踪复杂系统、网络科学、计算社会科学等领域的前沿进展。现在正式推出订阅功能,每周通过微信服务号「集智斑图」推送论文信息。
扫描下方二维码,关注“集智斑图”服务号,即可订阅Complexity Express: 
Complexity Express 一周论文精选
目录:
1. 信仰陷阱:解决有害信念的惰性
2. 从自然事件的网络结构预测记忆
3. 种子社会网络算法可以促进印度城市公共卫生干预的采用
4. 生物学中温度依赖的一般理论
5. 气候变化下雪生态系统功能的普遍变化
6. 深度学习设计包含特定功能位点的蛋白质
7. 元认知静态测量的动态影响
8. 用于选择性栓塞的微型机器人集群
9. 一种推断冠状病毒重组模式的贝叶斯方法
1. 信仰陷阱:解决有害信念的惰性

论文题目:Belief traps: Tackling the inertia of harmful beliefs 论文来源:PNAS 论文链接:https://www.pnas.org/doi/10.1073/pnas.2203149119
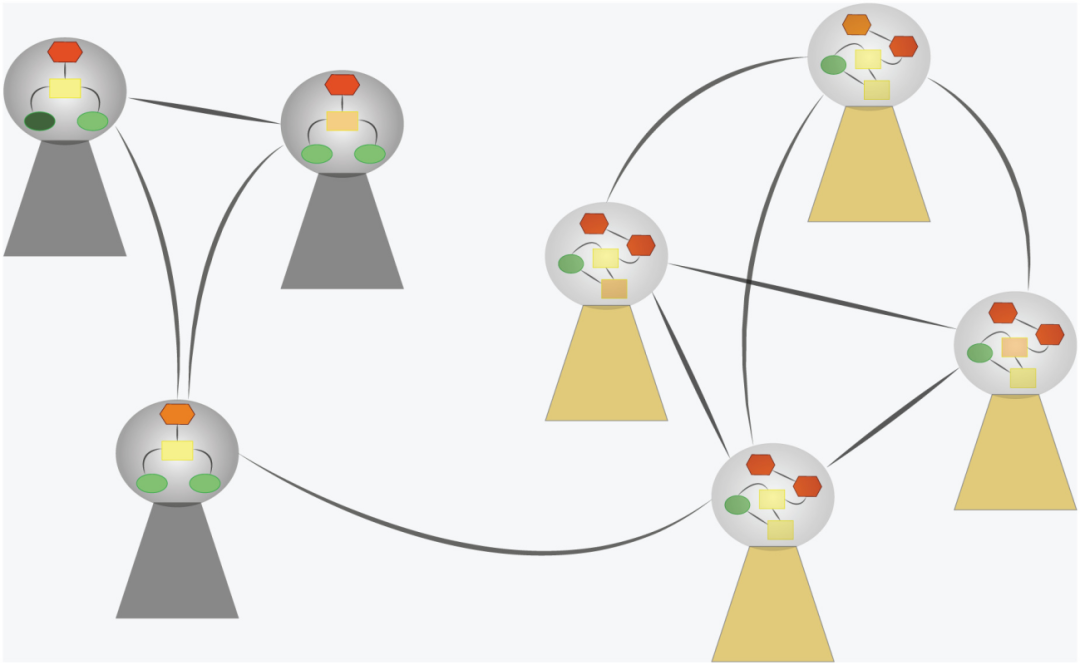
图:替代意识形态作为嵌入社会网络的连贯信念网络。每一个有色元素代表一个个体的信念,与同一个人内部的其他信念相连,形成一个连贯的网络,代表一种意识形态。人们被持有相似意识形态的社交网络所吸引,而这些网络中的传染性促使人们进一步趋同于相同的意识形态。
2. 从自然事件的网络结构预测记忆

论文题目:Predicting memory from the network structure of naturalistic events 论文来源:Nature Communications 论文链接:https://www.nature.com/articles/s41467-022-31965-2
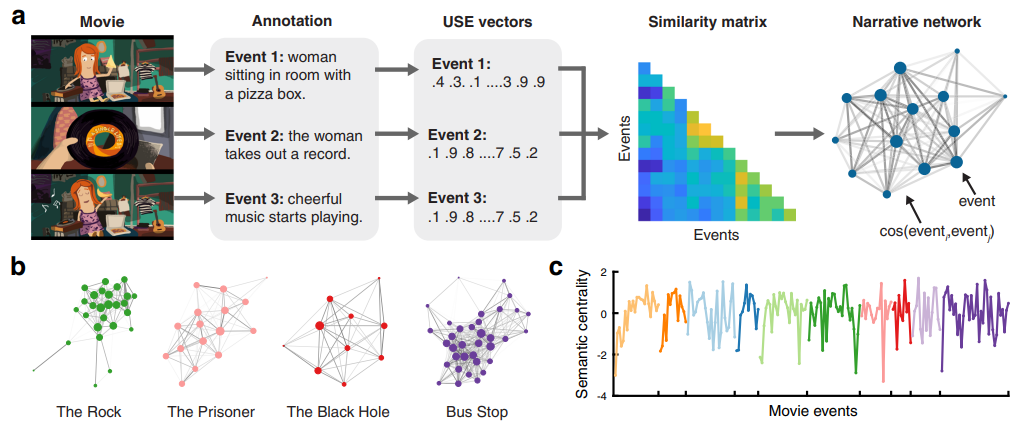
图:(a)语义叙事网络构建流程图。为了创建语义叙事网络,每部电影被分割成事件,独立的注释者提供事件的文本描述。利用谷歌的通用句子编码器(USE) 将文本描述转化为语句嵌入向量。事件之间的语义相似度通过 USE 向量之间的余弦相似度表示。语义叙事网络则可以定义为以电影事件为节点,以事件之间的语义相似度为边缘权值的网络。(b)在功能磁共振成像实验中,四部示例电影构建的语义叙事网络。为了可视化目的,边缘权重阈值为余弦相似度 = 0.6。节点大小与非阈值网络计算的中心性成正比。边缘厚度与边缘权重成正比。(c)实验中,10 部示例电影的全部独立电影事件的语义中心性(归一化程度)。不同的颜色表示不同的电影。
3. 种子社会网络算法可以促进
印度城市公共卫生干预的采用

论文题目:Algorithms for seeding social networks can enhance the adoption of a public health intervention in urban India 论文来源:PNAS 论文链接:https://www.pnas.org/doi/10.1073/pnas.2120742119

图:在随机对照试验的三个治疗组中,对三个选定的小组采用跨社交网络的干预。(A)在随机针对的情况下,所有的种子都得到治疗。(B)在朋友定位的情况下,没有一个蓝色周边节点被涂成红色,因为干预只传递给随机种子的朋友。(C)在配对目标的情况下,蓝色周边的种子也被涂成红色并且有一个邻居被涂成红色,因为随机种子和他或她的朋友都接受了干预。
4. 生物学中温度依赖的一般理论

论文题目:A general theory for temperature dependence in biology 论文来源:PNAS 论文链接:https://www.pnas.org/doi/10.1073/pnas.2119872119

图:温度反应曲线与预测相比较,适用于多种生物实例。图中是 ln(Y) 与 1/T(单位为1/K,其中 K为开尔文)的关系,显示了(A-C)凸的模式和(D-F)凹的模式:(A)多细胞昆虫 Blatella germanica 的代谢率,(B)紫花苜蓿的最大相对发芽率(电导率为32. 1 dS/m),(C)酿酒酵母的生长率,(D)果蝇(Drosophila suzukii)的死亡率,(E)古细菌 Geogemma barossii 的生成时间,以及(F)啮齿动物 Spermophilus parryii 的代谢率(在稳定状态下)。这里的曲线对应的是对环境温度而不是体温的反应的新陈代谢率。
5. 气候变化下雪生态系统功能的
普遍变化

论文题目:Pervasive alterations to snow-dominated ecosystem functions under climate change 论文来源:PNAS 论文链接:https://www.pnas.org/doi/10.1073/pnas.2202393119
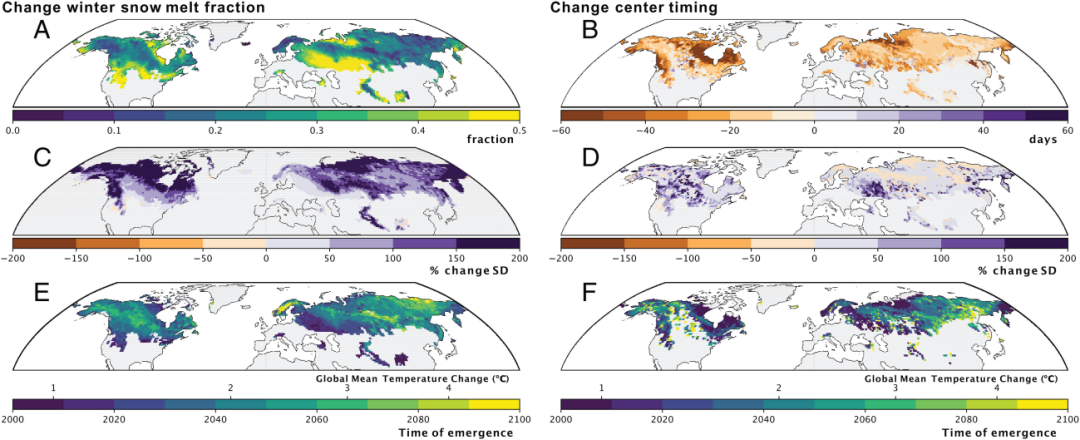
图:冬季融雪量的增加和径流中心时间的提前也显示出可变性的增加。图显示了在雪水当量峰值之前发生的冬季融雪部分和径流中心时间日期的变化(分别为左栏和右栏),包括( A 和 B )集合平均状态的变化,( C 和 D )集合标准差的百分比变化(去除集合平均后),以及( E 和 F )出现的时间与全球平均温度的相关变化。集合平均数和标准差的变化被计算为 21世 纪末( 2070 年至 2099 年)所有集合成员与 20 世纪中期( 1940 年至 1969 年)30 年基线期的差异。出现的时间被计算为10年运行平均值在 1940 年至 1969 年的集合平均值之外 ±2 标准差的年份。(C和D)中的色条范围是为了方便比较不同指标间的变化。在( E 和 F )中没有着色的网格单元在 2100 年之前不会出现。
6. 深度学习设计
包含特定功能位点的蛋白质

论文题目:Scaffolding protein functional sites using deep learning 论文来源:Science 论文链接:https://www.science.org/doi/10.1126/science.abn2100

图:蛋白质功能设计方法。(A)功能位点支架的应用。(B)Constrained hallucination,在每个迭代中,一个序列被传递给 trRosetta 或 RoseTTAFold 神经网络,该网络预测三维坐标和残基间的距离和方向。预测结果由一个损失函数评分,该函数奖励预测结构的确定性以及图案重现和其他特定任务的函数。(C)Inpainting,部分序列和/或结构信息被输入到一个改良的 RoseTTAFold 网络,然后输出完整的序列和结构。(D)蛋白质设计挑战被表述为缺失信息恢复问题。第1栏的问号表示缺失的序列信息;第2栏的灰色漫画表示缺失的结构信息。(E)RFjoint 可以同时恢复一个被掩盖的蛋白质区域的结构和序列。(F-G)动机支架基准数据,比较 RFjoint 与 Constrained hallucination。使用了一组自 RoseTTAFold 训练以来发表的 28 个新设计的蛋白质。
7. 元认知静态测量的动态影响

论文题目:Dynamic influences on static measures of metacognition 论文来源:Nature Communications 论文链接:https://www.nature.com/articles/s41467-022-31727-0

图:速度—准确性指令对元认知准确性的影响。(A)实验任务中的事件顺序。参与者(N = 32)通过用双手的拇指按 “C” 或 “N” 来决定大多数的点是向左还是向右移动。在他们的选择之后,他们立即用六点量表表示他们的信心水平。根据不同的区块,在 ITI 期间的指示是关注选择的准确性或关注速度。(B)漂移扩散模型的拟合参数与额外的决策后积累。拟合的决策边界在速度与准确性条件下较低,t(31) = 5.59,p<0.001,而漂移率没有差异,p=0.478。重要的是,在速度与准确性条件下,M-比率较高,t(31) = 2.29,p = 0.029,而 v-ratio 在两种指令条件下没有差异,p=0.647。(C)经验数据(条形)和模型拟合(线或十字形)的反应时间和置信度分布,分别为正确(绿色)和错误(红色)。(D)参与者在被指示关注速度而不是准确性时,速度更快,t(31)=5.67,p<0.001;准确性更低,t(31)=2.20,p=0.035;信心更低,t(31)=2.41,p=0.022。
8. 用于选择性栓塞的
微型机器人集群

论文题目:Microrobotic swarms for selective embolization 论文来源:Science Advances 论文链接:https://www.science.org/doi/10.1126/sciadv.abm5752

图:在目标结点上保持群体的完整性。(A)示意图说明了使用磁粉群来阻止目标区域内的结点。(B)对尖端粒子施加的力的示意图分析。棕色的圆圈表示磁性粒子。黑色虚线圆圈表示尖端粒子。蓝色细箭头和蓝色粗箭头分别表示磁相互作用力和其结果相互作用力。流体拖曳力和反作用力用粗的红色箭头表示。γ 是结点的分支角。θ 是磁相互作用力与 X 轴的角度。绿框中显示了不同分支角的结点上的粒子的配置。紫色区域代表结点的壁。
9. 一种推断冠状病毒重组模式的
贝叶斯方法

论文题目:A Bayesian approach to infer recombination patterns in coronaviruses 论文来源:Nature Communications 论文链接:https://www.nature.com/article-s/s41467-022-31749-8
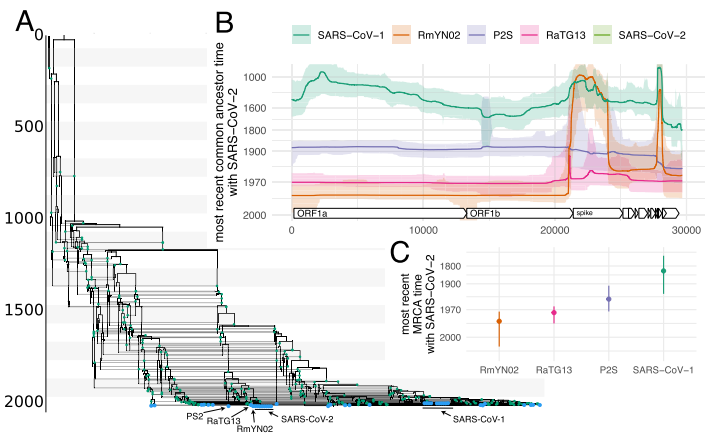
图:SARS样病毒的进化史。(A)SARS 样病毒的最大进化支置信度网络。蓝点表示样本,绿点表示重组事件。(B) SARS-CoV-2 与不同 SARS 样病毒在基因组不同位置的共同祖先时间。y 轴表示对数尺度上的共同祖先时间。彩线表示中位共同祖先时间,而彩色区域表示 95% 最高后验密度区间。(C)SARS-CoV-2 与不同 SARS 样病毒在基因组不同位置的最近的共同祖先时间。误差条表示 95% 最高后验密度区间的上下限。MCC 网络和共同祖先时间作为源数据。
关于Complexity Express
Complex World, Simple Rules. 复杂世界,简单规则。
为了让大家能及时把握复杂系统领域重要的研究进展,我们隆重推出「Complexity Express」服务,汇总复杂系统相关的最新顶刊论文。
Complexity Express 是什么?

Complexity Express 为谁服务?
-
如果你是复杂系统领域的研究者,可获得重要论文上线通知,每周获取最新顶刊论文汇总。
-
如果你是复杂系统领域的学习者,可了解学界关注的前沿问题,把握专业发展脉络。
-
如果你是传统的生命科学、社会科学等学科中的研究者/学习者,可以从复杂科学和跨学科研究中获得灵感启发。
-
如果你是关注前沿研究发现的知识猎手,可获得复杂系统研究对自然和人类世界的最新洞见。
Complexity Express 论文从哪里来?
-
Nature
-
Science
-
PNAS
-
Nature Communications
-
Science Advances
-
Physics Reports
-
Physical Review Letters
-
Physical Review X
-
Nature Physics
-
Nature Human Behaviour
-
Nature Machine Intelligence
-
Review of Modern Physics -
Nature Review Physics -
Nature Computational Science -
National Science Review -
更多期刊持续增补中,欢迎推荐你认为重要的期刊!
Complexity Express 追踪哪些领域?
-
复杂系统基本理论 -
复杂网络方法及应用 -
图网络与深度学习 -
计算机建模与仿真 -
统计物理与复杂系统 -
量子计算与量子信息 -
生态系统、进化、生物物理等 -
系统生物学与合成生物学 -
计算神经科学与认知神经科学 -
计算社会科学与社会经济复杂系统 -
城市科学与人类行为 -
科学学 -
计算流行病学 -
以及一些领域小众,但有趣的工作
更多论文
点击“阅读原文”,追踪复杂科学顶刊论文
微信扫一扫,分享到朋友圈











