面向因果规律的表示学习新方法——因果表征学习最新攻略

导语
我们的生活中无时无刻不在对接受到的信息进行思考和逻辑推理,从而获得可被复现的模块化知识。近年来深度学习AI在预测识别方面取得巨大进展。要如何进一步,使AI具有与人类相似的推理能力呢?因果表征学习或许提供了一条路径。这篇文章概括了 Carnegie Mellon University 副教授张坤老师研究组在因果表征学习方面的最新工作(张坤目前学术休假,在MBZUAI工作)。张坤团队致力于打通因果关系和人工智能的关系:一方面,他们开发机器学习方法来从观测数据中进行因果结构以及因果表征学习。另一方面,他们从因果关系的角度考虑人工智能中的各种学习问题,包括迁移学习、强化学习、推荐系统、自然语言处理,并希望对因果关系的认知和使用能把人工智能带到一个新的高度。
本文主要包含四个部分。第一部分是对因果发现传统工作的简介并且引入因果表征:何为因果表征学习,其与因果发现关系何在,以及为何需要新方法实现因果表征学习。第二部分着重于介绍因果表征学习的最新研究进展和方法, 包括在独立同分布情形、时间序列、分布迁移情形的情况下如何寻找因果隐变量和它们之间的因果关系。第三部分介绍了在迁移学习和适应性强化学习下的应用。因果表征学习为机器学习提供了更有解释性和更有效的方法。在第四部分,我们介绍了目前的分析工具causal-learn以及对未来研究工作和应用场景的展望。
由周晓华教授发起的2022泛太平洋因果推断大会,将于9月17日-9月18日在线举办,汇聚国内外从事因果科学相关工作的一线研究人员,共同探讨因果科学的最新进展。届时集智俱乐部将对会议进行直播。会议仍在开放报名中,议程及会议详情见文末。
研究领域:因果表征学习,机器学习,因果发现

张坤团队(黄碧薇、姚巍然、谢峰、郑雨嘉、张坤) | 作者
邓一雪 | 编辑
目录
(1) 基于Low-rank的方法
(2) 基于GIN的方法
(3) 层级结构学习的方法
(4) 小结
3. 应用
4. 目前的分析工具以及对未来的展望
1. 简介
1. 简介
因果表征学习(causal representation learning)是连接因果科学与深度学习的桥梁。近十年来,深度学习(deep learning)成为了计算机视觉(CV)、自然语言处理(NLP)等人工智能(AI)基础领域的核心技术,同时为机器人,无人驾驶,人机交互系统,虚拟现实、生物制药、智慧城市等行业应用进行智慧赋能。深度学习是一种使用神经网络模型,通过梯度反传的信号反馈将非结构化数据,如图片、语言文字等,转化为可被机器处理的表征(representation),并使用这些表征解决识别、理解等下游任务的计算方法。2015年,在由Geoffrey Hinton, Yann LeCun and Yoshua Bengio(图灵奖获得者,深度学习著名人物)共同署名的Nature论文《Deep Learning》中,表征学习 (representation learning)被归为深度学习和现代AI技术取得巨大成功的主要原因。表征学习的目标是将高维的原始数据降维成低维特征,在保留信息的同时过滤掉原始数据中的噪声。
然而,通过扩大数据和模型的规模学得的表征往往只能对数据进行编码、压缩或记忆。这些表征不具有可供机器进行逻辑推理和规划的高阶语义因子(semantic concept),也不具备像人类一样在新环境下灵活解决问题的变通能力和鲁棒性。因此,如何使深度学习能像人类一样进行有意识的推理、思考与判断是下一代AI急需解决的问题。另一方面,因果(causal)模型,提供了一套系统性的、基于统计的因果推理和思考的计算方法。然而,因果模型往往只能处理结构化的数据,并不能处理生活中常见的高维的原始数据,比如图像。于是,将表征学习和因果模型进行融合,将图像这样的原始数据转化为可用于因果模型的结构化变量,赋予AI如同人类一样有意识的推理和思考的能力,成为了因果表征学习这一新兴学科的主要目标。如果我们能解决这个问题,我们就可以很好地将因果推断与机器学习结合起来,构建下一代灵活,可信的AI。
在因果表征学习中,我们通常假设数据是由因果相关的、满足一定条件的结构因果模型(Structural Causal Model,SCM)的因果隐变量,通过非线性的映射来产生。如果因果隐变量和它们之间的SCM能从原始数据中学习,我们就可以估计在干预了这些变量后的数据分布,或推断指定数据点的反事实结果,比如重新组合因果隐变量生成事实中不存在的数据,或者回答Why,What if等需要显式推理的问题。值得注意的是,因果表征学习与因果发现(Causal Discovery)有密不可分的关系。一方面,因果表征学习是在有很多混淆因子(confounder)下的因果发现问题的一个特例。另一方面,在没有领域知识的情况下,学习整个隐变量空间中的结构因果模型是极其困难的。因此,因果发现中常用的假设,比如Sparsity、Minimal Change Principle和Independent Causal Mechansim,通常可以成为因果表征学习的领域知识和使用的归纳偏置(Inductive Bias)[Schölkopf et al., 2021]。
因果发现传统工作简介
寻找因果关系的传统方法是通过随机对照实验。然而,随机对照实验通常需要耗费大量的时间和资源,有时甚至可能涉及伦理问题。例如,基因敲入是一种广泛用于创建疾病模型的技术。通常导致疾病的不是单个基因,而是由多个基因组成的网络。要找到这个网络可能需要太多的实验才能可行。因此,必须寻求替代方法——从观测数据中发现因果关系,称为因果发现(causal discovery),因为观测数据更容易获得。
经典的因果发现方法通常是寻找观测变量之间的因果关系,其大致分为两类。在 1980 年代末和 1990 年代初,人们注意到,在适当的假设下,可以根据变量之间的条件独立性关系恢复潜在因果结构的马尔可夫等价类 [Spirtes et al., 1993]。这产生了基于约束的方法(constraint-based method),该方法利用条件独立性测试(conditional independence tests)和离散搜索(discrete search)来进行因果发现。由此产生的等价类可能包含多个 有向无环图(DAG,或其他表示因果结构的图对象),这些DAG共享相同的条件独立性关系。所需的假设包括因果马尔可夫条件(causal Markov condition)和忠实度假设(faithfulness assumption),这两个假设建立了因果图中的d-分离属性与数据中的统计独立性属性之间的对应关系。相反,基于分数的方法 [Chickering, 2003, Heckerman et al., 1995] 不是使用统计测试,而是搜索在某些评分标准下给出最高分数的等价类,例如采用贝叶斯信息标准 [BIC, Schwartz, 1978]、给定数据的图的后验 [Heckerman et al., 1997] 和广义评分函数 [generalized score, Huang et al., 2018]。
另一组方法是基于函数因果模型(functional causal model, FCM),将效果表示为直接原因 (direct cause) 的函数以及独立的噪声项。研究表明,通过适当地约束模型类,因果方向是可识别的。具体来说,当在正确的因果方向上估计 FCM 时,估计的噪声项与假设原因独立,但在想反的方向上不成立。可识别的因果模型包括线性非高斯无环模型 [LiNGAM, Shimizu et al., 2006]、非线性加性噪声模型 [additive noise causal model, Hoyer et al., 2009, Zhang and Hyvärinen, 2009a] 和后非线性模型 [post-nonlinear causal model, Zhang and Chan, 2006, Zhang and Hyvärinen, 2009b]。但是需要注意的是,如果函数因果模型的函数空间没有约束,则无法识别因果方向,因为总是可以在反向上找到独立于预测变量的噪声项 [Zhang et al, 2015]。
上面介绍的方法已被扩展到更一般的场景。比如说LiNGAM已被扩展到有环的因果图 [Lacerda et al., 2008] 和存在潜在混杂因素的情况 [Hoyer et al., 2008] 。基于LiNGAM拓展的Specific and Shared Causal Relation Modeling [SSCM, Huang et al., 2019] 不仅可以提供整体的因果关系,还可以提供针对个体的个性化的因果知识, 以及基于因果关系来做聚类。同时,研究表明即使存在选择偏差的情况下,因果模型(包括因果方向)也是可能识别的 [Zhang et al., 2016]。
目前的因果发现方法集中在寻找观测变量之间的因果关系, 但是在现实世界的问题中,很多相关的特征可能没有被观察到,并且一些观测变量可能不是潜在的因果变量。例如,我们不能直接将图像像素视为因果变量。因此,正如在第一部分中所说的,我们想从测量的高维变量中学习潜在的因果表征(causal representation),以及它们之间的因果关系,它在通用人工智能和科学领域都是必不可少的。例如,在 AI 中,我们希望从高维视频序列中自动提取底层的低维因果变量或概念,这些变量或概念对于视频理解至关重要,从而促进下游预测或决策任务。在神经科学中,从 fMRI 记录中测量出数以万计的体素,一个关键问题是如何识别和分层聚类潜在的大脑功能区域并发现信息流。
在本篇推送中,我们将结合传统因果发现,从方法,应用和工具角度,详细探讨如何在独立同分布情形、时间序列和分布迁移情形下进行因果表征学习,寻找因果隐变量和它们之间的关系。我们总结了因果表征学习在迁移学习,适应性强化学习的应用。最后,我们对目前的可直接使用的分析工具做简要介绍和并对未来的研究和应用方向进行展望。
References
(参考文献可上下滑动查看)
2. 寻找因果隐变量和它们的关系
2. 寻找因果隐变量和它们的关系
2.1 独立同分布情形
(1) 基于Low-rank的方法
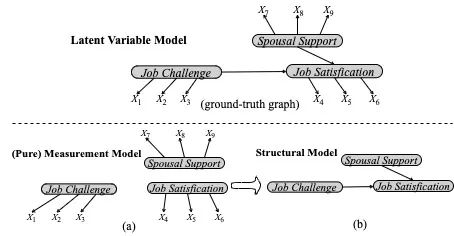
图1:两阶段学习隐变量间因果结构示例图。最上面为真实因果图;子图(a)第一阶段所学模型,即测量模型;子图(b)子图(a)第二阶段所学模型,即结构模型。
(2) 基于GIN的方法
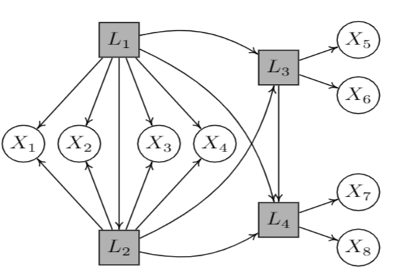
(3) 层级结构学习的方法(latent hierarchical structure)
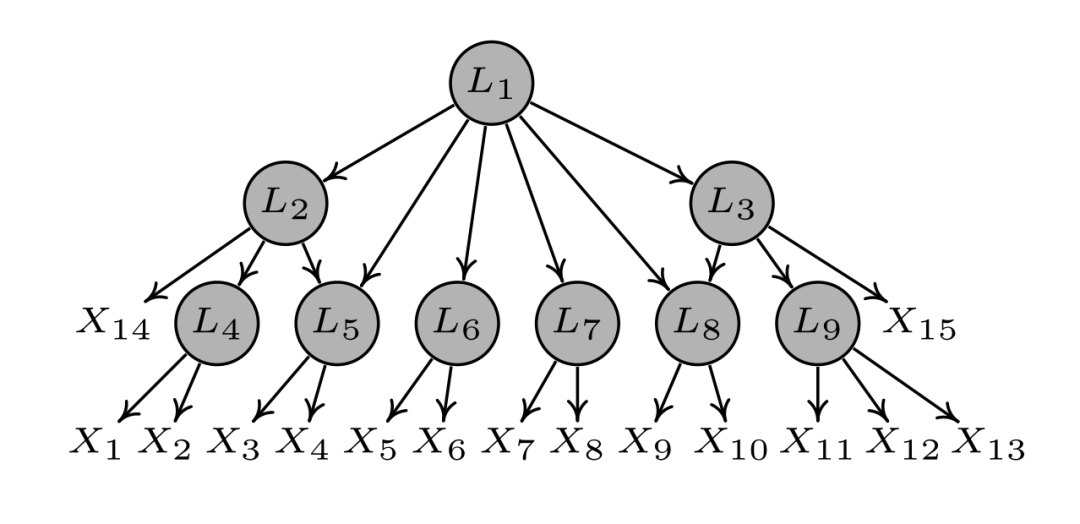
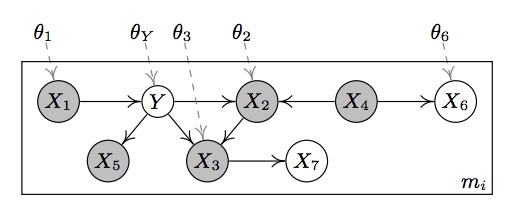
图3:一个涉及9个隐变量(Li, i=1,…,9)和15个观察变量(Xi, i=1,…,15)的层级因果结构。
(4) 小结
2.2 时间序列
(1) 传统因果发现: Granger causality
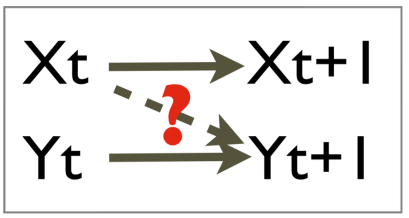
(2) 从静态时间序列中寻找因果隐变量和它们的关系
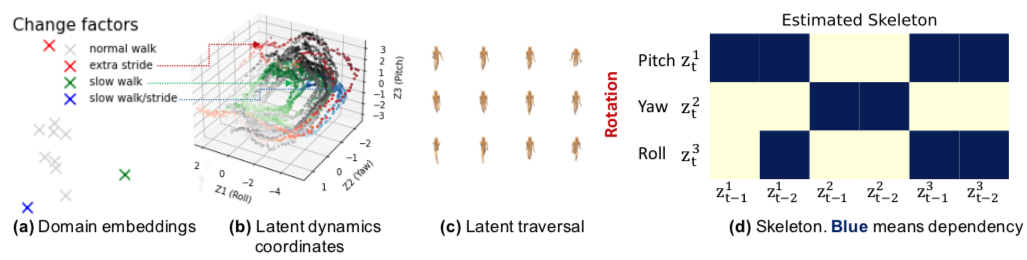
Linear Latent Causal Processes with Generalized Laplacian Noise
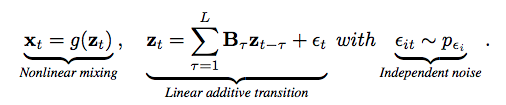
Linear Latent Causal Processes with Generalized Laplacian Noise模型假设
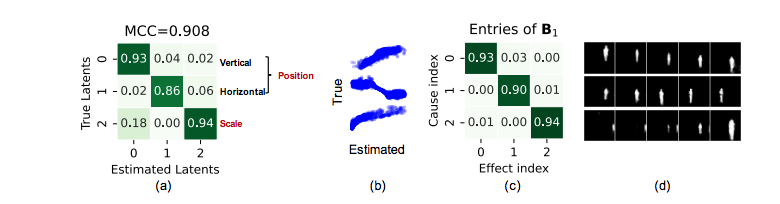
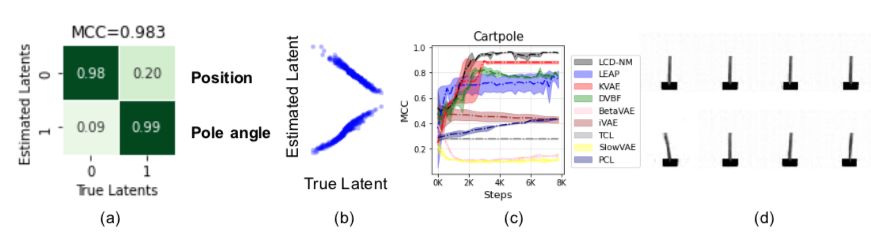
KiTTiMask实验结果:(a)恢复的隐变量和真实因果隐变量之间的相关系数;(b)恢复的因变量和真实因果隐变量之间的散点图;(c)恢复出来的因果关系矩阵;(d)Latent traveral展示因果隐变量如何影响图像内容。
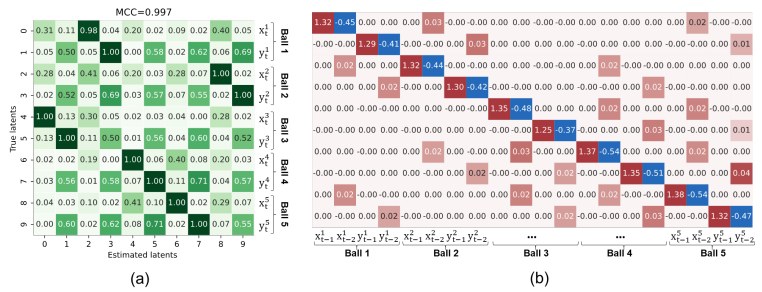
质量弹簧系统视频数据实验结果:(a)恢复的隐变量和真实因果隐变量之间的相关系数;(b)恢复出来的因果关系矩阵。

Nonparametric Latent Causal Processes
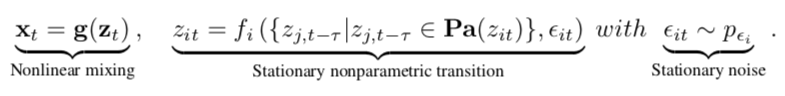
(3) 数据分布变化为时间序列因果表征学习带来的好处
2.3 分布迁移情形
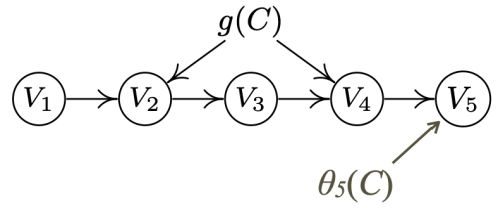
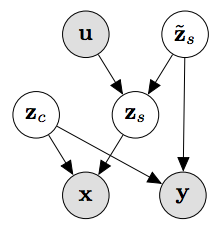
真实的因果关系图。其中g(C)和θ(C)表示未观测到的隐藏的变化因素,它们可以表示为随着C变化的函数。
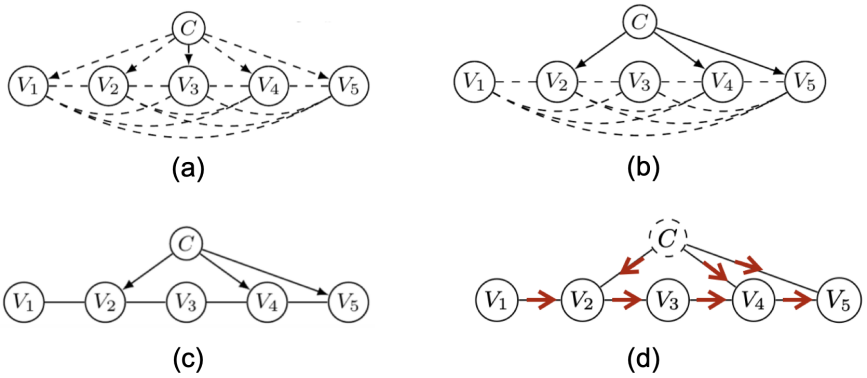
CD-NOD搜索过程示例。(a) 初始图。(b)检测哪些变量对应的因果机制发生了变化。(c)恢复因果骨架。(d)识别因果方向。
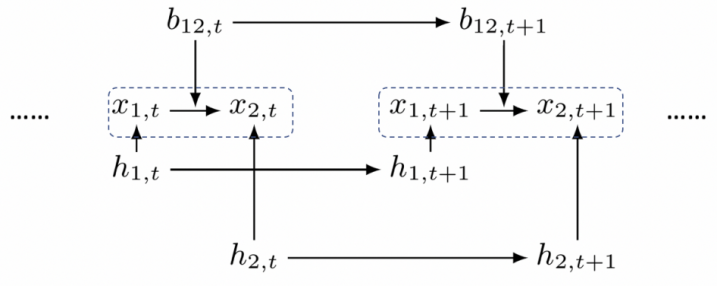
Figure: 时变因果模型示意图。其中b和h是隐变量,他们分别用来表征满足auto-regressive model的因果系数和噪声项方差的对数。
 |
 |

References
(参考文献可上下滑动查看)
3. 应用
3. 应用
3.1 迁移学习
3.2 适应性强化学习
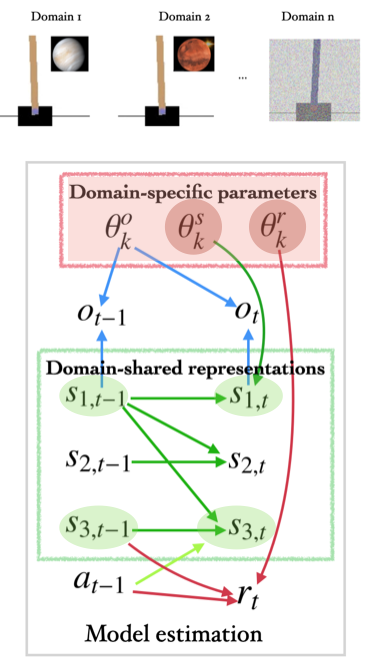
4. 目前的分析工具以及对未来的展望
4. 目前的分析工具以及对未来的展望
4.1 Causal-learn
-
Constrained-based causal discovery methods.
-
Score-based causal discovery methods.
-
Causal discovery methods based on constrained functional causal models.
-
Hidden causal representation learning.
-
Permutation-based causal discovery methods.
-
Granger causal analysis.
-
多个独立的基础模块,比如独立性测试,评分函数,图操作,评测指标。
-
更多最新的因果发现算法,如gradient-based methods等
(1) 平台介绍
i)基于Python的统一算法框架
ii)经典算法的官方实现
iii)持续更新,掌握领域前沿
(2) 简单上手
i)安装
ii)因果发现,只需一步
iii)可视化与评测
4.2 目前的难点和将来的重点
2022第四届泛太平洋因果推断大会





推荐阅读
-
因果表征学习最新综述:连接因果科学和机器学习的桥梁 -
因果推荐系统前沿进展:形式化与去偏 -
图形的逻辑力量:因果图的概念及其应用 -
《张江·复杂科学前沿27讲》完整上线! -
成为集智VIP,解锁全站课程/读书会 -
加入集智,一起复杂!
微信扫一扫,分享到朋友圈











