拖延行为的神经计算解释 | 复杂性科学顶刊精选7篇
集智斑图顶刊论文速递栏目上线以来,持续收录来自Nature、Science等顶刊的最新论文,追踪复杂系统、网络科学、计算社会科学等领域的前沿进展。现在正式推出订阅功能,每周通过微信服务号「集智斑图」推送论文信息。
扫描下方二维码,关注“集智斑图”服务号,即可订阅Complexity Express: 
Complexity Express 一周论文精选
目录:
1. 基于Transformer 的正则潜在空间优化蛋白质生成
2. 网络效应导致的竞争市场非平衡相变
3. 拖延行为的神经计算解释
4. 噪声传染病曲线中信息的量化
5. 数据驱动神经网络中卷积结构的涌现
6. 科学精英的引用模式存在性别差异
7. 出生时的艰辛改变气候变化对长寿捕食者的影响
1.基于Transformer的
正则潜在空间优化蛋白质生成

论文题目:Transformer-based protein generation with regularized latent space optimization 论文来源:Nature Machine Intelligence 论文链接:https://www.nature.com/articles/s42256-022-00532-1#Fig2
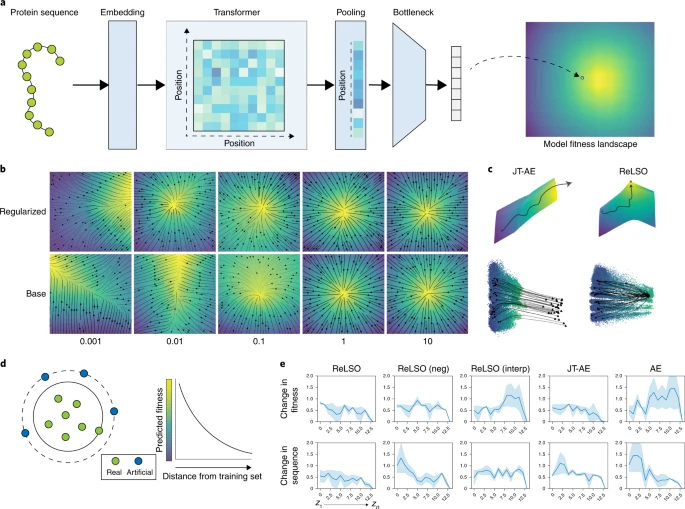
图:(a)为了编码蛋白质序列,ReLSO 使用基于转换器的编码器。Transformer 模块的输出使用基于注意力的池化机制进行池化,然后进一步压缩以产生输入序列的潜在表征。潜在点的集合形成了模型适配性景观。(b)ReLSO 使用辅助网络从潜在空间预测适配性,并使用基于范数的负采样技术在生成的潜在空间中强制执行伪凹形。辅助网络的选择会影响网络对负采样损失的敏感程度。顶行的图是使用惩罚网络生成的,以学习更平滑的函数,而底行的图是由传统的全连接网络生成的。(c)在 JT-AE 中,朴素联合训练方法的一个固有弱点是辅助网络经常学习单调函数。当用于潜在空间优化时,这样的函数缺乏任何停止标准。为了解决这个问题,本文重塑了适应度函数,使全局最大值位于训练数据中/附近。(d)负采样依赖于数据增强策略,其中在潜在空间的外围生成人工的低适配性点。(e)本文使用潜在空间中成对的远距离点之间的 100 次采样游走来监控潜在空间遍历期间序列和适配性的变化。x 轴表示沿所走路径的步长索引。y 轴显示当前步骤 zi 和最后一步 zn 之间表示属性的差异,因此当 zi = zn 时,差异在最后一步变为零。显示了平均值(线)和 95% 置信区间(阴影区域)。
2.网络效应导致的
竞争市场非平衡相变

论文题目:Nonequilibrium phase transitions in competitive markets caused by network effects 论文来源:PNAS 论文链节:https://www.pnas.org/doi/10.1073/pnas.2206702119

图:单一卖家所面临的供需问题。蓝色线为真实需求曲线,黑色虚线为卖家预测需求曲线,黑色方块为导致市场崩溃的利润最大化点。
3.拖延行为的神经计算解释

论文题目:A neuro-computational account of procrastination behavior 论文来源:Nature Communications 论文链接:https://www.nature.com/articles/s41467-022-33119-w#Fig6
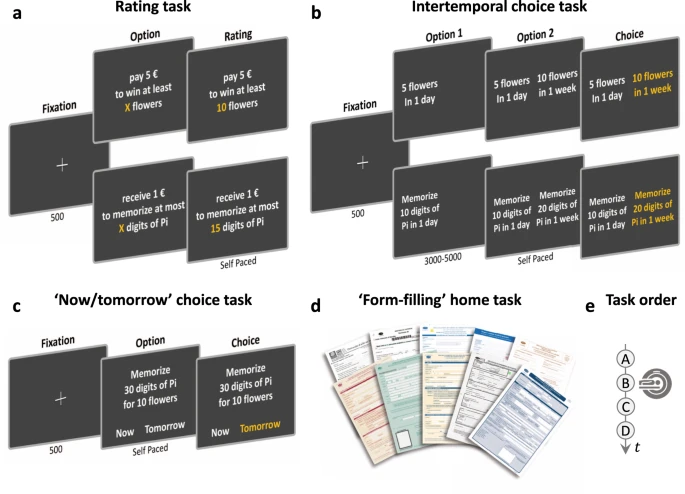
图:在一个试验中显示的连续屏幕从左到右显示,持续时间以 ms 为单位。(a)对任务评分。对于每一种奖励、努力和惩罚(未显示),参与者在键盘上指出主观收益(或主观成本)与获得(或失去)1 欧元和 5 欧元相同的数量。(b)跨期选择任务。参与者首先观察连续显示的两个选项,然后用左手或右手按下两个按钮中的一个来表示他们的偏好。早和晚选项的呈现顺序在试验中得到了平衡。该任务被划分为两种奖励、两种努力或两种惩罚(未显示)之间的跨时间选择块。(c)“现在/明天”选择任务。参与者被提供了一个包含奖励和努力项目的选项。然后他们选择是“现在”努力,立即获得奖励,还是“明天”努力,第二天获得奖励。“现在”和“明天”选项的展示在试验中得到了平衡。(d)“填表”家庭任务。参与者得到了 10 份行政表格,比如护照更新表格。为了获得参与研究的经济补偿,他们必须在 30 天内填写表格,并通过电子邮件发送数字副本。他们被告知,截止日期过后将不会有任何补偿转移。(e)实验进度。任务按字母顺序执行。只有跨期选择任务是在 MRI 扫描仪中执行的。
4.噪声传染病曲线中信息的量化

论文题目:Quantifying the information in noisy epidemic curves 论文来源:Nature Computational Science 论文链接:https://www.nature.com/articles/s43588-022-00313-1
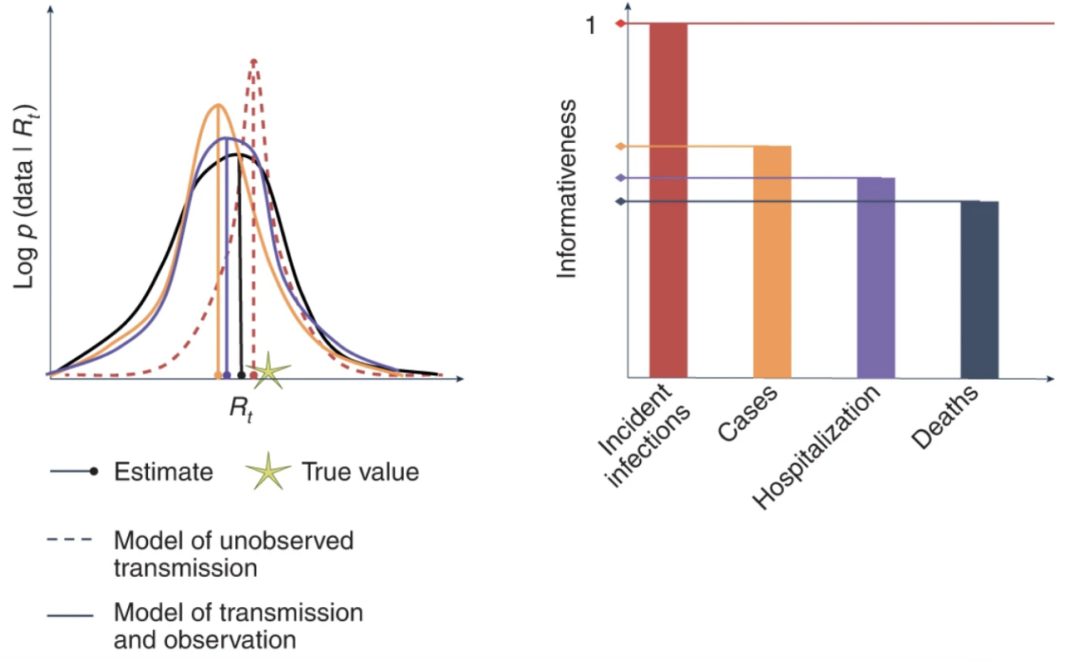
图:将不同病例数据源的对数似然曲率与其信息量相关联的示意图。左侧图中,没有一个最大似然估计值完全等于真实值,包括从事件感染模型中得出的估计值,因为任何疾病传播模型都不能完美反映显示。右侧表明较低曲率的可能性具有较低的信息量。在本研究中,事件感染曲线的信息量被设置为1,然后将不同数据源的信息量与事件感染模型的信息量作标准化对比。图片来自评论文章:https://www.nature.com/articles/s43588-022-00319-9
5.数据驱动神经网络中
卷积结构的涌现

论文题目:Data-driven emergence of convolutional structure in neural networks 论文来源:PNAS 论文链接:https://www.pnas.org/doi/10.1073/pnas.2201854119

图:现有的神经网络学习理论在 RF 的形成过程中被打破。在非线性高斯输入(NLGP[公式1],橙色)和高斯控制任务(GP,蓝色)上训练的具有 K=8 个神经元的网络的 pmse(10),长度尺度为ξ+=2ξ-=16。pmse 是在模拟过程中使用保留的测试数据计算的(实线)。我们还显示了在 GP上训练但在 NLGP 数据上评估的网络的测试误差(GP/NLGP,红色)。十字线给出了通过评估描述等效高斯模型误差的分析表达式得到的 pmse(材料和方法)。虽然分析表达式准确地预测了训练开始时的误差(蓝色阴影区域),但对于在 NLGP 上训练的网络来说,它在时间 102 前后出现了问题。这正是权重开始本地化的时间,正如本地化权重的平均 IPR(2)所衡量的(插图,绿色)。同时,网络预激活的超额峰度也在减少(插图,橙色)。其他参数如下:一维任务,D=L=400,学习率 η=0.05。曲线是 20 次运行的平均数。
6.科学精英的引用模式存在性别差异

论文题目:Gendered citation patterns among the scientific elite 论文来源:PNAS 论文链接:https://www.pnas.org/doi/10.1073/pnas.2206070119
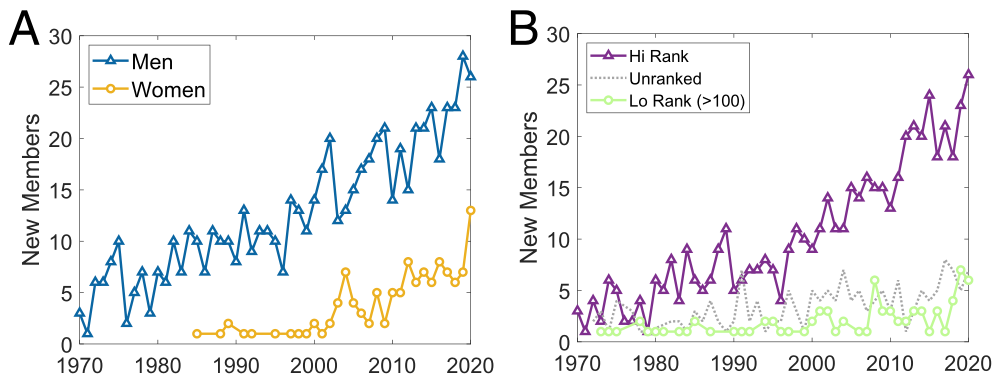
图:历年不同性别或所属机构的影响力环境下当选成员人数,仅考虑截至2021年活跃在七个领域的成员。
7.出生时的艰辛改变气候变化
对长寿捕食者的影响

论文题目:Hardship at birth alters the impact of climate change on a long-lived predator 论文来源:Nature Communications 论文链接:https://www.nature.com/articles/s41467-022-33011-7
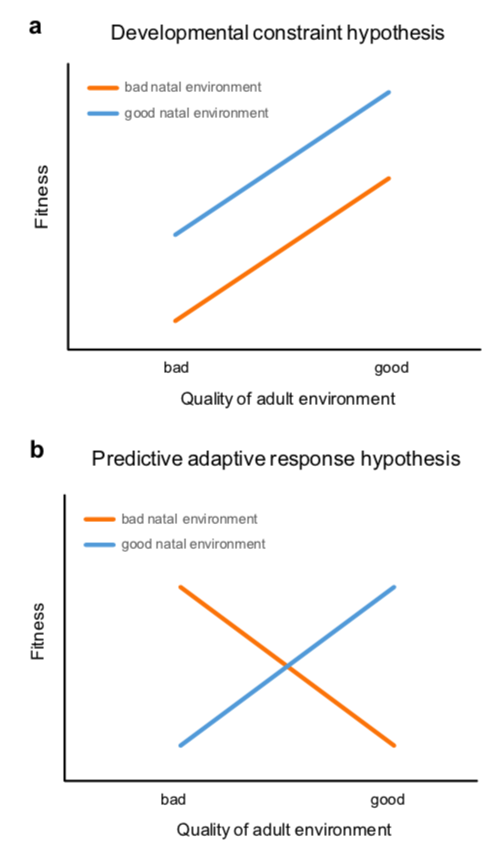
图:两个主要假设考察了在发育过程中与在后来生命中遇到的条件之间相互作用的适应度影响。(a)发育约束猜想,(b)预测适应响应猜想。
关于Complexity Express
Complex World, Simple Rules. 复杂世界,简单规则。
为了让大家能及时把握复杂系统领域重要的研究进展,我们隆重推出「Complexity Express」服务,汇总复杂系统相关的最新顶刊论文。
Complexity Express 是什么?

Complexity Express 为谁服务?
-
如果你是复杂系统领域的研究者,可获得重要论文上线通知,每周获取最新顶刊论文汇总。
-
如果你是复杂系统领域的学习者,可了解学界关注的前沿问题,把握专业发展脉络。
-
如果你是传统的生命科学、社会科学等学科中的研究者/学习者,可以从复杂科学和跨学科研究中获得灵感启发。
-
如果你是关注前沿研究发现的知识猎手,可获得复杂系统研究对自然和人类世界的最新洞见。
Complexity Express 论文从哪里来?
-
Nature
-
Science
-
PNAS
-
Nature Communications
-
Science Advances
-
Physics Reports
-
Physical Review Letters
-
Physical Review X
-
Nature Physics
-
Nature Human Behaviour
-
Nature Machine Intelligence
-
Review of Modern Physics -
Nature Review Physics -
Nature Computational Science -
National Science Review -
更多期刊持续增补中,欢迎推荐你认为重要的期刊!
Complexity Express 追踪哪些领域?
-
复杂系统基本理论 -
复杂网络方法及应用 -
图网络与深度学习 -
计算机建模与仿真 -
统计物理与复杂系统 -
量子计算与量子信息 -
生态系统、进化、生物物理等 -
系统生物学与合成生物学 -
计算神经科学与认知神经科学 -
计算社会科学与社会经济复杂系统 -
城市科学与人类行为 -
科学学 -
计算流行病学 -
以及一些领域小众,但有趣的工作
更多论文
点击“阅读原文”,追踪复杂科学顶刊论文
微信扫一扫,分享到朋友圈











