COVID-19数据分析的可复现性:悖论、陷阱和未来挑战

导语
新冠疫情教给我们的一个重要科学教训:医学知识的获取和信息的质量,更多取决于“数据质量”,而不是“数据数量”。在短时间内涌现的大量新冠肺炎报告表明:即使是最先进的统计和计算工具,也无法很好地克服获得的数据质量差的问题。由于数据问题,大量针对新冠病毒机制、传播、防控等研究难以复现,甚至出现自相矛盾的结论。我们很难找到简明的方法,以可解释的方式,从有限数据中描述传播机制的复杂性。
在最近发表于PNAS Nexus的文章中,作者认为需要复杂的综合方法,来结合不同的数据和信源,同时需要从统计学的角度来平衡建模的困难,产生有效的推论和可靠的预测。作者结合案例讨论了数据质量怎样影响新冠研究和决策,并认为需要新的范式和新的设计方案,以便在处理新冠肺炎等紧急情况下收集的数据时得出有意义且信息丰富的可信结论。
研究领域:数据分析,统计学

Clelia Di Serio, Antonio Malgaroli, Paolo Ferrari, Ron S Kenett | 作者
刘志航、刘培源 | 译者
邓一雪 | 编辑

论文题目:
The reproducibility of COVID-19 data analysis: paradoxes, pitfalls, and future challenges
论文链接:
https://academic.oup.com/pnasnexus/article/1/3/pgac125/6673789
1. 背景
1. 背景
我们对新冠数据分析的回顾性检查,因其前所未有的数量被命名为“新冠-洪流”(“COVID-torrent”)[1],加入了统计学家、流行病学家和临床医生的多方面经验和观点。目标是在公共医疗保健和临床决策的背景下平衡数据采集和数据分析的挑战和陷阱,包含三个阶段。具体而言,我们分析的是,大量的新冠肺炎相关数据是否转化为关于这种病毒感染、疾病及其治疗的扎实知识。答案是否定的,新冠-洪流因其糟糕的结果而脱颖而出[2]。这在一定程度上可以归因于新冠病毒病理学的复杂性。我们也需要承认,与新冠病毒相关的数据采集和分析并不是量身定制的,因此无法为汇总非常不同的数据集提供共同的途径。可以说,我们一直在“淹没在数据中,饿死在信息中”[3]。新冠大流行为在世界各地实施更有效的数据收集、分析、建模和解释工具提供了一个基本的试验场。在应对这一挑战时,我们援引了信息质量(InfoQ)框架,该框架提供了一种在特定目标[4]背景下评估可用数据及其分析的方法。评估新冠数据及其分析所产生的信息质量有助于将数字转化为有用信息。
2. COVID-19出版物的泛滥
2. COVID-19出版物的泛滥
自2020年2月新冠肺炎疫情爆发以来,我们目睹了前所未有的努力,以找到关于如何遏制病毒传播、如何应对其后果以及如何找到突破性治疗方法的答案。我们在相关的出版物洪流中确定了三个阶段。在第一阶段,重点主要放在新冠肺炎的流行率、发病率和传播率上。病毒载量与疾病严重程度、治疗组合和不同治疗方案的有效性有关。在第二阶段,重点转移到分析患病群体免疫力、抗体水平和无症状的特征。在第三阶段,大部分注意力都集中到不同的可用疫苗、疫苗接种方案及其治疗效果,以及对新感染浪潮和新变种起源的预测。最近的文献已经讨论了这种整体观点[5]。
对不同的分组和国家对不同的疫苗进行比较测试,可以有效地选择最有效的疫苗和那些不太容易产生副作用的疫苗。确定疫苗的最佳剂量及其保护持续时间,对不同病毒变体的疗效,确定接种疫苗的人是否仍被感染或传播病毒,确定疫苗接种的最佳间隔,同时了解为已经感染该的人接种疫苗是否有用,这些都被证明是复杂的问题。主要出版商(http://acdc2007.free.fr/drowningcovidpapers.pdf)卷入了一场争议,一方面为了让人们免费获取新冠病毒的相关论文,没有设置相应的限制性条款,另一方面是需要通过传统的审查程序来保护论文质量。仅在 2020 年,COVID-19 开放研究数据集[6]就收集了40多万份与新冠病毒相关的出版物。COVID-19 开放研究数据集(CORD-19)是最大的出版物数据库之一,囊括了 50 多万篇学术文章。该数据库为了应对如洪水般的大量出版物,实施了一些举措,以选择稳健和可推广的论文。但是,由于缺乏共同的标准和标准化数据的质量要求,使得这一目标变得困难。一些自发和独立的项目,旨在找到一份共同的新冠肺炎记录清单。例如,COVID-19 真实世界数据(RWD)数据元素协调项目[7],以及国际组织和机构(例如欧统局、世卫组织、经合组织和疾控中心)。然而,这些似乎没有为公共卫生地方机构和与新冠病毒相关的健康指标的统一提供有效支持。
在疫情爆发时,所收集的数据被期望在很短的时间内提供有用的信息[8]。这种紧迫性推动了以数据驱动的人工智能算法的应用,但这与期刊确保科学严谨性的需要明显冲突[9]。这种现象与基于批判性推理和统计思维的科学基本方法不同。一般来说,科学寻求区分噪音来源和可重复的真实效果。这种方法需要时间,不一定满足紧迫性的要求。事实上,很难找到直截了当的方法,以可解释的方式,从观察到的临床可用信息中描述传播机制的复杂性。需要复杂的综合方法,以结合不同的信息来源。同时,需要从统计学的角度来平衡建模的困难,产生有效的推论和可靠的预测。另一方面,人工智能算法已被用于选择预测模型,能够整合新冠患者的临床症状和特征[10]。此外,流行病学模型(SEIR)[11]和基于布朗运动的物理学方法[12]被用来调查不同的情况和公共卫生干预措施,旨在最大限度地减少疫情的影响。影响。这些方法使决策者能够测试不同控制策略的影响。然而,这些建模方法往往被证明与显示非线性行为、稀疏模式和部分收集的数据不一致。
为了增进知识,所有这些考虑都需要配合对数据和分析方法的深入讨论。一方面,公共卫生系统存在重要的缺陷,例如(i)公共卫生组织在提供统一的流行病参数定义和数据共享的指导方针方面反应缓慢;(ii)在早期爆发或新的突变毒株等关键十字路口对数据监测不足;(iii)数据收集的标准不同且混乱;以及(iv)缺乏一个开放的科学数据系统。另一方面,人们过度依赖数据驱动的方法,将其作为揭示大流行病的工具,有时却损害了统计思维。例如,为了监测一段时间内的感染和免疫力,建议采用基于样本的监测计划,该计划建立在人口代表性的统计原则之上。这与在世界各地广泛实施的便利的非概率抽样形成了鲜明对比。
新冠疫情爆发让现代世界震惊,并提供了一个机会来回顾过去感染和大流行病的教训。在下一节中,我们将举例说明。
3. 历史总是惊人相似
3. 历史总是惊人相似
生物医学发现的历史告诉我们,将信息转化为知识一直是临床研究的一个主要挑战。阿尔伯特·萨宾(Albert Sabin)用减毒脊髓灰质炎病毒制成的口服小儿麻痹症疫苗,几乎没有任何副作用[13],而且比 1955 年推出的 Jonas Salk 的疫苗有效得多。萨宾几乎花了七年时间才弄明白其中的机制。萨宾对他的发现持怀疑态度,因为这意味着放弃了一种已经有效的预防性治疗。这与无法将现有的临床数据转化为信息和预测有关。这迫使萨宾在俄罗斯测试他的疫苗,然后才被全世界接受。直到2006年,世界卫生大会成员国才宣布致力于使用适当的单价口服脊髓灰质炎疫苗阻止三种野生型脊髓灰质炎病毒中的两种的传播。事实上,我们对疾病的消除和疾病的根除进行了区分。就脊髓灰质炎和麻疹而言,我们指的是“消除”感染。当某一特定病原体引起的感染的发生率由于刻意的和共同的努力而缩小到零时,就发生了消除。然而,需要继续采取措施以避免传播的重新发生。当我们在世界范围内达到永久的零感染率,不再需要干预措施时,就可以使用“根除”这个术语。天花接种环形疫苗似乎就是这种情况。随着新冠病毒变种的迅速出现,这些变种可以逃避自然或疫苗诱导的免疫,根除或消除新冠病毒是不可能的。
如果新冠肺炎得到控制,意味着需要努力将疾病的发生率、流行率、发病率或死亡率降低到地方性水平,从而实现 “群体免疫”。事实上,通过自然感染或接种疫苗的群体免疫力在人口层面上实现了阈值免疫力,削减了疾病的净传播。这种阈值免疫可以在一定时间内保护特定地理区域内最大比例的居民。效果是否持久取决于个人层面的自然或疫苗诱导的免疫力的持续时间。有几个原因导致患新冠群体免疫力不太可能达到。这些原因包括疫苗接受度低,出现了传染性更强的新变种,以及规避了全球疫苗接种计划。
因此,对一种传染病的控制不能仅仅通过疫苗覆盖率来实现,而是需要从整体上进行处理。这包括识别爆发模式的“数据驱动”政策、易感人群的风险剖析、构建监测的统计抽样、计划数据整合技术,以整合流动性和健康数据与临床信息。所有这些方法的共同点是数据质量、信息质量和统计思维。下一节将对信息质量框架进行阐述。
4. 信息质量
4. 信息质量
新冠疫情带来的一些重要挑战反映在三个问题中:(i)我们能否改进和规范数据获取和数据库建设,以囊括所有相关数据,并排除无意义、不准确或不可靠的数据?(ii)我们能否使数据获取更加灵活和动态,以便我们能够快速解决随着时间的推移可能出现的以目标为导向的问题,并加快实现对潜在现象的洞察?(iii)统计学能否提供一种新的分析架构,以改善“大数据”和 “大量知识”或“信息质量”之间的差距?
产生新的知识需要由结构化的信息质量(information quality,InfoQ)支持的。信息质量被定义为 “一个数据集使用特定的经验分析方法实现特定(科学或实践)目标的潜力”[4]。InfoQ 框架由四个部分组成。(i)目标,(ii)实用性,(iii)数据,以及(iv)分析方法和八个维度:(1)数据分辨率,(2)数据结构,(3)数据整合,(4)时间相关性,(5)数据和目标的时间顺序,(6) 通用性,(7) 操作性,和(8) 交流。这些组成部分和维度决定了一项具体研究所提供的信息质量。从新冠数据中产生的数据质量受到许多限制的影响,如研究设计不完善、数据不完整、数据分辨率差、数据整合无效和可推广性不强。这些障碍阻碍了有意义的分析。糟糕的信息质量可能是由于数据收集和数据分析的条件造成的。在紧急情况下,调查结果的操作化和概括化推动了数据收集需求,这些需求解释了广泛的误差来源。
5. 数据质量、偏见来源和COVID-19悖论
5. 数据质量、偏见来源和COVID-19悖论
在处理未经适当研究设计而收集的大数据时,一个主要问题是几种类型的偏差可能产生的影响,包括选择性偏差和无回应偏差(None Response bias)。这些可能会以一种矛盾的方式影响结果,导致混杂偏差(confounding bias)。影响新冠疫情数据的一个主要偏差来源,与“非概率”抽样程序有关。这样的数据收集削弱了由此产生的统计推断。事实上,概率抽样是基于事先已知的设计变量,用于定义人口框架的所有单位。在非概率抽样中,纳入概率是未知的。糟糕的抽样方法,不能通过增加样本的大小来解决。人口规模扮演着“放大镜”的角色,它放大了非概率抽样的偏差,并可能导致错漏百出的推断。可以证明[14],在非概率抽样下,衡量统计模型误差量的 MSE(均方误差)会随着样本大小而增加。在这种情况下,人们需要实施替代的统计分析方法,如各种加权方法。一种选择是使用倾向得分来构建权重,以考虑非概率样本的偏差。最近在分析非概率抽样的大数据时提出了新的统计视角[15]。这种方法利用标准的逻辑回归克服了可能的偏差,这种回归依赖于观察变量之间函数关系的先验假设。另一种新方法是使用贝叶斯网络来估计倾向得分[15]。
然而,即使是非概率抽样,大多数已发表的论文仍然采用标准统计技术,因此忽略了可能的偏差来源。除了选择性偏差和无回应偏差外,混杂偏差会导致对协变量作用的错误解释,以及矛盾的结论。这在新冠病毒数据中风险因素的解释中已经广泛出现。事实上,对协变量的标准调整方法,如使用优势比,导致了一些误导性的悖论,包括“肥胖悖论”、“ACE 抑制剂悖论”和“吸烟悖论”。大多数这些悖论可归因于产生混淆效应的未解释的可变性来源。这包括对缺失值的错误估算,数据库中缺乏统一的变量定义,以及忽略疾病严重程度与年龄的交互效应。此外,来自不同 COVID-19 感染浪潮的数据不容易合并和比较,这不仅是因为病毒变体在感染和致病机制上可能有生物学上的差异,而且还因为接触治疗剂的时间,以及新疗法的引入可能影响临床结果。
例如,许多新冠肺炎研究论文[16]评估了肥胖的作用,因为肥胖是心血管疾病中主要的风险因素。在第一波新冠肺炎期间,肥胖被证明是一个风险因素,但也有研究声称肥胖具有“保护性”或没有影响[17]。这些相互矛盾的结果来自许多潜在的警告,例如:(1)评估肥胖的不同选择标准。体重指数(BMI)是一个基本工具,但其本身不足以在没有临床评估的情况下诊断肥胖症。(2) 肥胖临床诊断的标准和临界值因国家而异并取决于种族,(3) BMI 的缺失值也可能会影响结论。在疫情突然爆发的情况下,重症患者的体重和身高变量往往很难获得。这代表了一种审查效应,而不是“随机缺失”的情况,因此不能通过简单的数据插补来纠正。另一个悖论指的是广泛讨论的习惯性吸烟者感染新冠肺炎的低风险。许多论文报告称,活跃吸烟者与新冠肺炎的严重程度[18]之间没有显著相关性,驳斥了吸烟对呼吸功能的影响。然而,可以证明,吸烟变量通常测量得不好(0/1变量)。这些数据主要由不再吸烟的年龄组住院的重症患者组成。这个悖论导致选择性偏差。ACE 抑制剂悖论也存在类似的现象,ACE 抑制剂悖论是新冠肺炎第一阶段的一个重要讨论话题[19]。起初,据报道接受 ACE 抑制剂治疗的患者感染新冠肺炎的风险增加。后来,情况正好相反,即 ACE 抑制剂药物的保护作用[20]。在我们审查的大多数文献中,没有适当考虑年龄对所有协变量的混淆影响。
这些现象被归类为“假保护性(false protectivity)”[21, 22]。它们由于有偏的测量,忽略了基础数据结构和数据整合,而这些是信息质量框架中需要考虑的第二和第三个维度。缺乏设计的研究可能会对治疗方案产生严重影响。
另一个问题是,数据不是按照对照试验设计收集的,通常使用“控制”定义,因此这些新冠数据不能在观察回顾设计中构建。与许多发表的论文一样,人们需要知道在这种流行病中,什么是适当的“控制”。
对照试验的一般性质取决于所考虑的研究类型和研究假设,应该仔细选择。根据历史文献[23],应该根据可比性原则选择对照,特别是:(i)所有比较都应在“研究基础”内考虑,这意味着住院新冠肺炎患者的对照应该是非住院的新冠肺炎患者;(ii)剔除混淆因素:在影响疾病风险时,应考虑不同暴露水平的依赖性,以避免扭曲;以及(iii)可比的准确性。
不幸的是,由于尚未系统地对无症状或轻症患者进行通用的鼻咽 rt-PCR 筛查,因此无法获得非住院患者的信息。所以,大多数论文使用从初级保健数据库中随机抽样的对照组,而对对照组的疾病状态没有任何了解。
大多数关于新冠病毒的研究都是针对病例的分析。适当的分析应该在一个复杂的依赖性网络结构中调查病人的情况,以评估风险因素的“净”影响,从而采取因果推断的方法。事实上,数据驱动的视角需要整合先验临床知识,不能完全依赖算法。机器学习方法可能无法描述新冠病毒风险因素之间的关系,因为它们本质上只是在调查相关性而非因果性[24]。任何因果性的结论都应该立足于验证和敏感性分析的角度,以确保结论的可复现性[25]。
因此,对于这些类型的数据,需要开发新的分析范式。这些方法应该能够控制混杂偏差、不同的数据整合协议、数据分辨率和数据结构,即重点关注信息质量的产生。
现有文献中已经广泛讨论了数据质量差对医学的影响(26)。然而,如今医疗数据的可用性不断提高,数据采集方法也发生了变化,这给数据质量范式带来了新的挑战,与之相对应的是更多的技术和伦理特征,如(i)数据共享,(ii)数据整合,以及(iii)隐私保护。
6. 数据质量、数据共享和可复现性
6. 数据质量、数据共享和可复现性
一个突出数据共享带来巨大好处的著名例子是抗炎药物 Rofecoxib。这种药物在1999年被美国食品和药物管理局(FDA)批准用于治疗类风湿性关节炎、急性疼痛和痛经。该药物公司提供的临床数据(有8076名入选患者的 VIGOR 试验)表明,该药物优于其他止痛药。在数据采集过程中,发现严重心脏问题的风险增加,但制造商决定保留该信息,并将 VIGOR 的结果与另一项Rofecoxib 试验的结果相结合,淡化了这种副作用[30]。在接下来的几年里,许多报告呼吁注意心血管问题的风险增加[31, 32],这迫使制造商在 2004 年撤回该药并承认它隐瞒了信息[33, 34]。2007年,制造商宣布支付 48.5 亿美元以结束数千起诉讼,这是有史以来最大的药物和解案。这种经验有助于改变生物医学研究。近十年来,生物医学研究中的数据共享变得更加普遍,而气象学和经济学等其他研究领域的数据共享一直是常见的做法。
新冠疫情的经验表明,对数据共享的强烈抵制会极大地减缓对一种全球疾病知识的快速获取。有几篇文章强调,缺乏激励措施限制了数据共享[35]。共享数据的倾向与学者的心理和实际动机有关,这些动机是研究人员厌恶分享数据的诱因。在最近对 321 名研究人员进行的一项研究[36]中,比较了个人对数据共享的“态度”和“意向”,主要障碍是对技术支持的不信任和对其科学发现被抢先一步的恐惧。大多数受访者对数据共享持积极态度,并表示他们愿意与其他研究人员共享数据,支持开放的科学研究。然而,当测试研究人员如何信任有足够的系统来分享数据时,只有不到三分之一的人表示他们愿意将他们发表的文章的数据存入这样的数据存储库。这些结果表明,研究人员对通过目前的数据储存库和交流工具共享数据的信心比他们所宣称的要低。在对3416 篇已发表的论文[37]进行研究人员对其数据可用性声明(DAS)的遵守情况的测量时,也证实了类似的结论,显示只有 17 %的文章从发表开始就真正公开了数据。不难看出,“已发布”数据和“公开”数据之间的区别,即宣布数据是“可用的”,具有许多不同的含义,阻碍了读者对数据的直接访问,见图1。
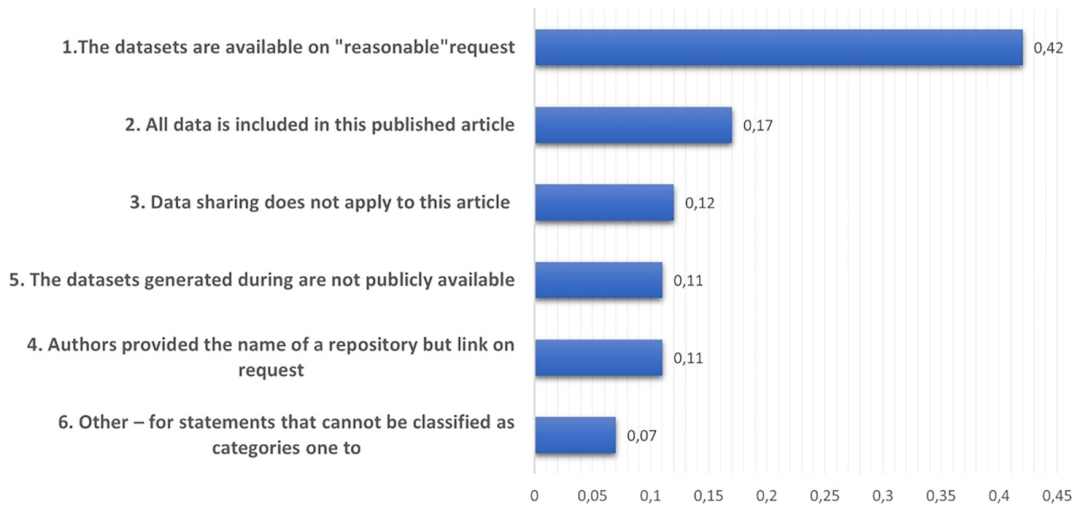
除了上述的心理原因,对共享数据的抵触情绪可能与“数据质量”问题和法律问题有关,如知情同意或伦理批准。事实上,简单地分享数据并不能改善科学,除非科学界可以利用这些数据来建立共享平台,实现数据整合。此外,结合多个数据源是一个复杂的过程,需要技术来解决时间结构、编码和处理缺失值、定义共同变量的不一致、不同的数据分辨率以及病例定义的非标准化等方面的不一致。
定义共同的准则,确定应如何分析数据,以便对不同来源产生的结果进行有意义的比较,这将加强确保数据完整性的最佳做法,并成为一种普遍做法。
7. 数据质量、数据整合和统计视角
7. 数据质量、数据整合和统计视角
新冠疫情的经验告诉我们,通过交叉检验和整合在异质临床环境中收集的数据,如医院、重症监护室、私营和公共部门的普通和专业卫生部门,提高推断的质量和获得更多的知识,已经成为一种基本的需要。有效的数据整合产生的统计推断,与基于单一数据源相比,更加稳健和高效。这方面的第一个障碍是数据提取。实施生物库往往意味着将电子医疗记录与基于文本的报告(如临床日记)的数据合并。这需要专家对背景的理解和解释。例如,在整个疫情期间,数据格式不仅在不同的国家而异,而且在同一报告来源中也有所不同。
在过去的 20 年里,人们对加强不同学科的数据整合的潜在好处有广泛的共识。数据整合主要通过两种方法实现:统计匹配和记录链接。这些程序的主要特点在像大流行病这样的紧急条件下可能会遇到重要的限制。这两种方法之间的一个基本区别来自于要整合的数据源的类型。统计匹配更接近于“合并”不同数据集。基于模型,它提供了通过多种来源收集的变量和指标的联合信息。统计匹配的主要特征涉及感兴趣的人群:尽管数据集中的单位可能不同,但这些单位应该来自同一人群,而且通常不重叠。一个不同的观点是将相同单位的信息联系起来。这是通过记录链接来实现的,只要数据集中的单位有重叠,就可以整合数据。记录链接处理相同的单位,而统计匹配则处理来自同一人口的“类似”单位。
在疫情的背景下,这一过程出现了许多限制,主要是由于电子健康记录和疾病定义标准缺乏协调性。首先,由于新冠肺炎患者特征缺乏代表性,不符合共同的标准,不能参考同一人群,因此统计匹配受到了阻碍。此外,当存在缺失值时,或当数据库在唯一识别病人方面含糊不清时,记录链接不能正确用于整合新冠数据。当患者信息中存在大量的噪音时,这种情况会更加突出。
上述考虑解释了为什么即使是最基本的流行病学新冠肺炎问题仍然没有答案。罪魁祸首是不良的感染报告和未知的抽样设计。考虑一下这些问题:该病在一般人群和亚人群中的流行率是多少?是否存在需要区别对待的特定临床表型?真正的病死率是多少?无症状的病例是否真的具有传染性?免疫力能持续多长时间?一般来说,如上所述,非概率抽样会影响目标人群的代表性,而推断则需要扩大可概况性的程度。数据整合的方法根据样本的类型和要整合的信息的类型而不同。在疫情期间,由于不同数据集的代表性不足或过高或不同,数据整合常常失败。对这种综合数据进行训练的工具对特定的亚群存在偏见[38-40]。不同的数据集缺乏同质的代表性,增加了寻找有效的方法来改善统计工具的数据分析过程的难度。此外,缺乏代表性阻碍了独立数据源结果的复现现,也就是一个糟糕的“可推广性”问题。一般来说,数据集成和整合,可以帮助克服两个重要的限制:(1)整合来自同一个体的不同数据来源(即临床和生物)的结果。这在处理全基因研究中的大数据分析时是至关重要的,在这种情况下,基因组学、表观基因组学、转录组学、蛋白质组学和代谢组学数据需要被整合;(ii)当来自不相干的样本时,需要整合基本协变量的信息以了解疾病的过程。不同层次的信息可以结合起来,从而形成不同的概率数据整合方法:通过汇总统计来描述多项调查的宏观方法,以及加强合成归因的微观方法。最近,人们考虑将随机临床试验和观察性数据结合起来的可能性。在这种情况下,可以考虑两种类型的数据整合:横向和纵向。横向整合的目的是整合具有大量变量和小样本的不同数据来源。这经常发生在基础研究和基因组元分析中。此外,我们在同一组样本上可能有多种数据类型和变量,我们可以将其视为“垂直整合”。这可以用无监督或有监督的方法实现。整合具有大量变量的数据需要采用变量选择方法来进行结果的预测建模,但在数据整合的变量选择文献中仍有空白需要填补,以控制偏差的来源,并保留为有限人口推断从而捕获的所有信息。
在未来,这个方向的努力可能会应用于基于风险特征分层的的疫苗监测方案上,以及针对一般免疫持续时间和并发症的免疫参数纵向监测方案上,如年龄、BMI和其他协变量。
8. 数据质量、隐私和数据保护
8. 数据质量、隐私和数据保护
大数据分析需要处理有关患者特征、人口统计、患者资料数据、生物标志物和疗法的临床信息。除了上述技术障碍外,另一个障碍是遵守患者隐私和数据保护的基本权利,例如 2018 年欧盟通用数据保护条例(GDPR),该条例被认为是世界上最严格的隐私和安全法(https://gdpr.eu/tag/gdpr/)。 未指明的大数据分析破坏了“同意或匿名”机制,根据该机制,出于研究目的医疗数据处理需要个人特定的知情同意或为研究处理的个人数据的匿名化。要使处理健康数据的知情同意书有效,该同意书必须是自愿的、明确的、具体的和明确的。获得这种同意在人力成本是巨大的,因为通常需要从大量可能不容易获得(甚至不知是否活着)的人那里获得同意。匿名个人信息可用于避免知情同意的需要,因为一旦个人数据不可逆转地匿名化,数据主体将不再可识别。然而,完全匿名的数据在保护患者隐私的同时,可能会降低数据的用处,甚至对大数据分析毫无用处。例如,对仅包含临床数据的不可逆匿名数据库进行分析将极大地保护患者的隐私,但会降低与生物库或其他有价值的数据集相关联的效用。另一方面,在线潜在互补数据的日益普及增加了从匿名数据集中重新识别特定个人的机会。在未经个人同意的情况下,获得各种形式研究批准的能力是访问不同的存储库。这是许多国家/地区法律规定的选项。然而,这条路线进一步受到适用的道德法规的阻碍,这些法规在不同国家、不同地区、甚至在不同类型的机构之间可能存在很大差异。
对于大量数据密集型医学研究而言,获得有意义的同意或不可逆转地匿名化数据不太可能或可行。如何在数据密集型医学研究的背景下,在数据保护的 GDPR 框架内应对知情同意或匿名化方法的挑战正变得越来越困难,并代表了未来的一个关键挑战。
9. 对共同语言的需求
9. 对共同语言的需求
最后,日常交流的复杂数据量与普通公众的统计知识水平之间的鸿沟已经非常大,这可能成为为一种数据恐怖主义,而非真正的信息交流。
除了专业管理的项目外,新冠肺炎疫情强化了消极态度,使普通人和脆弱的患者暴露在不受控制和不完整的信息洪流中。世界卫生组织声称,围绕新冠肺炎的“信息流行病”的传播“与病毒本身一样快,阴谋论、谣言和文化耻辱都导致了死亡和伤害。”在全球通信时代,错误信息的破坏力突出表明,需要将错误信息与教育进行对比,以区分可靠的来源,这不应该与审查信息的尝试相混淆[41]。最近的文献一直强调错误信息[42]的危险,这些错误信息无助于提高对新冠肺炎的健康素养,而是对医学和公共卫生系统的不信任。
关于新冠肺炎疫情,出现了前所未有的持续的错误信息,这些错误信息可能抵消了公共组织给予患者的好处。事实上,这导致许多患者被误导,消极参与和健康相关的活动,并做出了与自身利益无关的糟糕选择。与拒绝接种疫苗相关的大量新冠肺炎死亡就是一个戏剧性的例子。同样,文献中经常看到,识字率低和疾病的不良后果之间存在着密切的联系。例如,对于像高血压这样的常见疾病,在成人中的发病率估计在26%到31%之间(根据ECDC的估计,2020年世界上有13.9亿人),而治疗的比例很低(15.5%到17.4%的病人),低文化水平和错误信息与45%的高血压病人的血压得不到控制有关。因此,人们还应该考虑沟通,这是信息质量的第八个维度。为了支持这一层面,统计人员[44, 45]推动了教育方案,旨在培训记者和传播者应对新挑战,不仅与搜索准确信息和来源有关,而且深化数据新闻业的总体统计“计算”水平。为了更好地了解新冠肺炎数据中的信息内容,可以支持媒体对基于政策的限制进行适当的沟通,使人们积极配合预防措施[46]。提高整体科学素养的普遍需求正成为所有生物医学学科的关键所在[47]。
图2将信息质量框架、数据整合和调查结果沟通的组件、尺度和功能合并到示意图流程图中,以实现公共卫生系统更好地准备任何类型的传染病或慢性疾病。
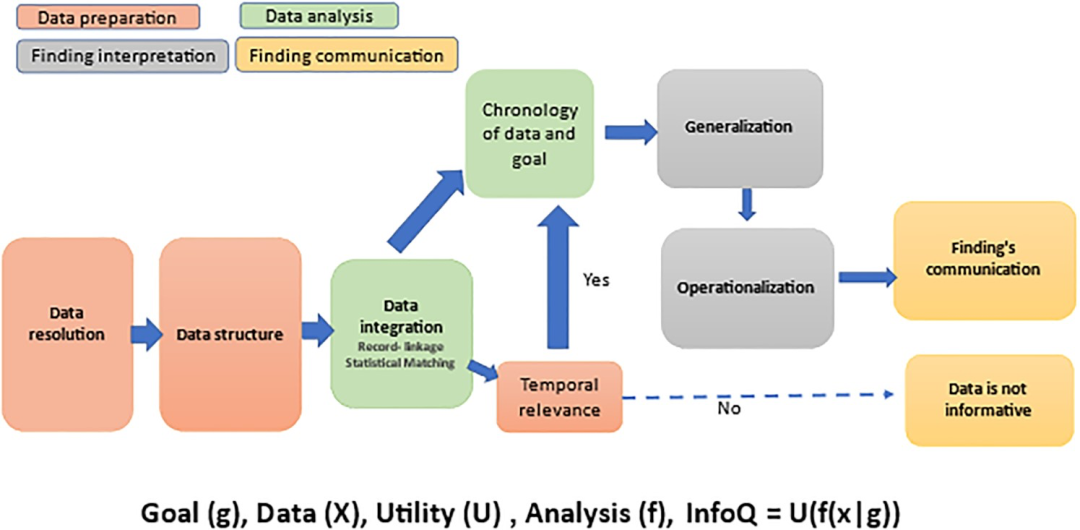
图2. InfoQ、数据整合和沟通问题的综合方案。
10. 结论
10. 结论
新冠肺炎疫情凸显了一系列与数据质量和分析相关的悖论和陷阱。这限制了统计分析在帮助更好地管理未来全球威胁挑战方面的范围和作用。因此,我们呼吁提高对未来挑战的准备水平。这些可能是与决策者或医疗保健组织相关的主题,如抗生素功效损失、交通拥堵、智慧城市的交通管理以及全球变暖等环境问题。
在初始阶段,新冠数据是在公众和政治家的强大压力下获得的,是出于前所未有的高死亡率疾病制定政策和治疗方案的紧迫目标。这导致了非针对性的和不一致的数据收集,以及许多未经证实的结果,导致不错误的公共卫生决策。今天,我们已经积累了大量数据,可以回顾并找到在全球范围内恢复这些信息的方法,并开发更合理、更严格的分析协议和综合分析模型[5]。这篇文章对现有文献的审查是为了帮助推进这一方向,并根据新冠疫情的经验,帮助卫生专家就如何解决未来的大流行病数据获取、分类、整合和分析问题达成普遍共识。
参考文献
(参考文献可上下滑动查看)
复杂科学最新论文

推荐阅读
-
口罩与疫情的博弈:为什么传染率低反而感染更多人? -
复杂性,互联性与韧性:为什么需要经济学范式转移来应对新冠流行和未来冲击 -
聪明的封控:权衡疫情防控与经济的智能封锁模型 -
《张江·复杂科学前沿27讲》完整上线! -
成为集智VIP,解锁全站课程/读书会 -
加入集智,一起复杂!
微信扫一扫,分享到朋友圈











