机器学习的核心任务,是从数据中自动发现相关性信息以便预测未来,但数据的真相并非来自相关性,而是来自因果性。因此,我们需要进一步对数据追因溯源,考虑数据背后更本质的因果结构。剑桥大学机器学习组陆超超博士的研究,就是在传统机器学习的基础上引入因果机制,这一新兴领域被称为“因果机器学习”。因果机器学习是什么?拥有因果推断能力的机器学习算法为什么更强大?探索一个全新的机器学习领域是怎样的体验?今年九月初,在2022年集智-凯风研读营期间,集智俱乐部采访了陆超超博士,以下是基于此次采访整理的文字稿。
研究领域:因果机器学习,因果表征学习,因果强化学习
陆超超 | 受访
梁金 | 采访
邓一雪 | 编辑
陆超超,剑桥大学机器学习组博士,他的研究兴趣是机器学习,特别是涉及到如何结合因果推理、贝叶斯推理、强化学习和深度学习各自的优势,并将它们应用在现实领域中解决实际问题,如计算机视觉和医疗等领域。
个人主页:https://causallu.com/
陆超超:我的主要研究兴趣是因果机器学习。通常所说的机器学习,目的是从数据中发现模式,然后根据模式做出预测。预测之所以困难,是因为我们处在一个复杂变化的世界。一个极端的例子是混沌现象:即使所有的函数都是确定的,仍然会产生蝴蝶效应,微小的初始变化会导致迥然不同的结果。
因果机器学习是在传统机器学习的基础上引入因果机制,用结构因果模型来建模数据生成过程。它是一类用因果模型建模数据生成过程的机器学习方法的总称,目的是更好地处理现实生活中大量存在的数据分布变化的场景。
陆超超:传统的机器学习只能处理独立同分布的数据,即测试数据和训练数据遵循相同的统计分布;但是现实生活中,训练数据和实际应用场景的数据分布通常是不一样的,传统的机器学习一般会失效。因果机器学习可以提供一个非常通用的框架,来描述和处理数据分布是怎么变化的,从而更好地预测和应对外部环境的变化。
由于能够处理变化是智能最重要的特征之一,所以因果机器学习可以让机器更加智能。因果机器学习是处理数据变化的理想框架之一,正在成为新一代人工智能的重要基础。
陆超超:首先,在最理想的情况下,我们希望能通过数据直接学习到潜在的正确的因果模型。但是,这在大多数情况下不太现实,因为对于给定的数据可能会对应多个潜在的因果模型,而我们无法确定哪一个是正确的。因此,我们通常需要利用已有的先验知识对潜在的因果模型做一些假设,缩小可能的潜在因果模型的范围,然后再从数据中进一步学习并确定其中正确的因果模型。一旦得到因果模型,就知道了变量之间的因果关系,然后就可以做一系列预测、生成、决策等机器学习任务。
因果模型一方面可以描述数据分布的变化,比如遇到新的环境,通过干预变量产生数据变化,我们可以看到哪些干预对目标变量产生影响,哪些不产生影响;另一方面,因果模型会显式地告诉我们,哪些变化是有用的,哪些没用,这就能很好地解决传统机器学习中最重要的两个任务:泛化(generalization)和适应(adaptation)。由于因果模型能够描述分布中变化和不变的部分,所以就很容易做泛化和适应任务。
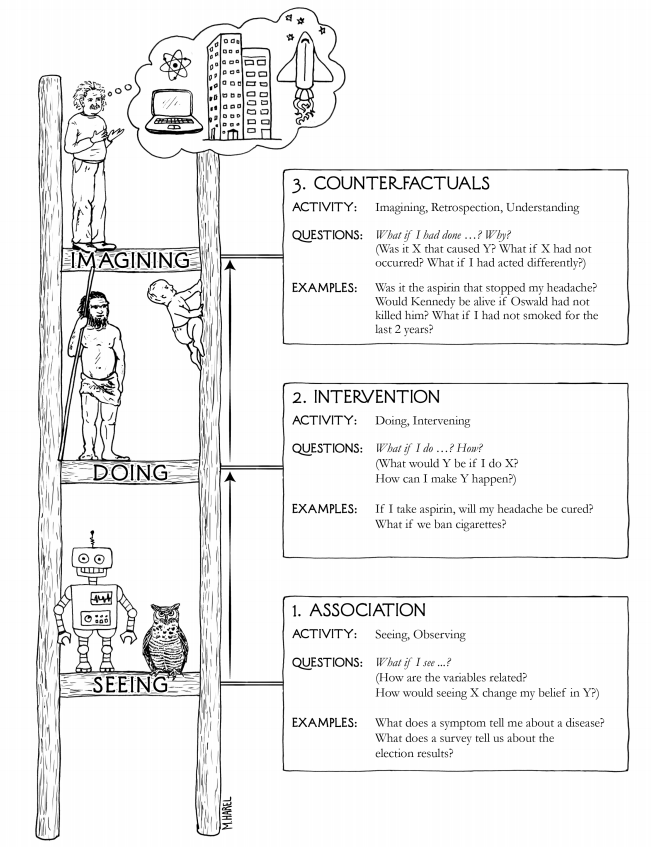
这里的因果是如何定义的呢?通常我们是通过干预来定义因果。对于两个变量A和B,要判断A是不是B的因,我们可以通过干预A,然后看B是否会产生变化。比如一个简单的例子,如何判断鸡叫和日出有没有因果关系?我们可以干预鸡,让它不叫,然后看太阳是否升起。如果控制鸡不叫,但太阳照常升起,说明它们没有因果关系。所以干预是定义于因果的一种方式,也就是说,通过分布的变化,我们能确定有没有因果关系。反过来,因果也是一种描述数据分布变化的方式。
陆超超:它有两个重要的子方向是因果表征学习和因果强化学习。因果表征学习的目标是,从低层次、高维度的数据中学习高层次、低维度的因果表征。通常的预测模型分为两部分:一部分是特征提取,一部分是预测器或分类器。这两部分的复杂度是相对的,如果提取到的特征很好,只需要很简单的分类器就可以完成预测任务;如果提取到的特征不好,就需要设计很复杂的分类器才行。所以学习好的表征是机器学习最核心的任务之一。一个好的因果表征不仅可以极大简化机器学习分类器或预测器的设计和学习,还可以有效地应对新场景中的数据分布变化。
对于分类任务,例如判别某张图片是否为猫,人们会根据形状是否像猫而做出判断,所以,在该任务中,形状是因果表征。而人们不会根据背景、颜色、姿态等判断图片是否为猫,所以这些特征不是因果表征。因此,一个好的猫的分类器应该只包含猫的因果表征。只有这样,在新的场景中,猫的背景等信息的变化才不会影响该分类器的性能,因为背景等信息不是猫的因果表征,它不会被分类器利用。
另一个方向是因果强化学习。我们知道,强化学习是让智能体(agent)在与环境交互的过程中学习的策略,因其在 AlphaGo 等击败人类顶尖玩家的游戏中的运用而广为人知。但是,传统的强化学习无法应对环境的变化,即在一个环境中学习到的策略很难迁移到另一个环境中。因果强化学习则是让智能体在和环境的交互过程中学习和发现其因果模型。因为因果模型是描述环境变化的理想工具之一,根据因果模型来优化自身策略,可以更好地应对环境变化,进而指导、优化下一步交互——这正是对人类行为的模仿,人类在探索自然的过程中总结经验规律,提高适应环境的能力。也因此,因果强化学习实质上是一种通用学习算法,有广泛的应用潜力,正在向计算机视觉、医药健康、推荐系统、自动驾驶等领域渗透。
因果强化学习和因果表征学习实际上互为表里。一方面,从观测数据中学习到的特征,我们需要干预才能判定它们是不是有因果关系,是不是因果表征;而因果强化学习是一个很自然的干预过程,智能体跟环境不断互动,这个互动的过程就是干预的过程,可以帮助学习因果表征。反过来,强化学习的一个重要任务是学到低维有效的状态表征,如果状态维度很高,探索空间就会指数级地增加,所以需要学习有效的状态空间,这就又回到因果表征学习的问题。所以因果强化学习和因果表征学习两个方向可以相互促进。
陆超超:因果机器学习的应用有很多,几乎所有传统机器学习的应用都可以通过引入因果模型变成因果机器学习的应用。例如无人驾驶,通过强化学习训练一个因果的世界模型,就可以在这个世界模型里做推理决策。再例如在医疗健康领域,如果可以学习到关于病人状态的因果模型,在真正治疗之前,我们就可以先通用因果推理来判断各种治疗手段有没有效果。
医疗中的很多问题都是因果问题。在治疗疾病时,只知道相关性没用,知道因果性才是最重要的。就像我们如果生病,会反思各种可能让自己生病的相关因素,但很难判断到底是什么导致生病。如果只知道相关性,给病人吃某种药是没用的,仍然在耽误他的治疗。因为对于A、B两个变量,如果它们之间只有相关性,调整A不一定会影响B;只有当它们之间存在因果性,调整A才会影响B。
不过,因果机器学习目前的应用主要是在一些容错能力比较强的任务,比如推荐系统、图像搜索、SIRI 的对话系统之类,都是出现错误不会产生严重后果的场景。像无人驾驶、医疗领域,跟人类的生命安全息息相关,还不能把所有决策都交给机器智能,机器只是在辅助驾驶、辅助医生诊断,最终的决策权还在人手里。从这个角度说,机器智能的发展还没有达到很高的高度。
陆超超:因果表征学习作为因果科学的前沿方法,可以用于研究复杂系统中的涌现现象。涌现是从微观到宏观的产生过程,这与因果表征学习恰好对应。因为表征学习也是一个从微观到宏观的学习过程,它从一些微观的信息(比如图像或者音频)中可以学到宏观的、可解释的因果变量。
例如对于文本,单看一篇文章中的字之间的关系很复杂,但如果把文章做抽象概括,每一段话都有一个中心意思,你可以只看每段话的中心意思,这样整篇文章的逻辑结构就变得清楚了。另一个例子是图像,图像中低层次、高维度的像素之间的关系很复杂,但如果我们能从图像中学习到视角、颜色、形状等高层次、低维度的宏观变量,就能更好地理解图像。因果表征学习,就是要从这些低层次、高维度的数据中,学习到高层次、低维度的变量。这些变量就是更宏观的概念,便于人类理解并发现复杂数据中更本质的规律。
陆超超:我是在博士阶段到 Bernhard Schölkopf 组做研究,自然受到他们的影响。我之前认为,机器学习主要是数据驱动的,它的目的就是从数据中发现模式,根据模式做预测。Bernhard 是做传统机器学习出身,他很清楚知道机器学习的优缺点是什么,能解决什么问题,不能解决什么问题,他对于因果机器学习的观点说服了我,我觉得很有道理,于是从2018年开始做这方面的研究。
学习机器学习之后你会发现,大部分模型输出的结果都是不可靠的。因为数据是人以各种方式生成的,而每个人都是有偏见的(bias),生成的数据也自然包含了人的偏见,这样学到的模型自然也是有偏见的,做预测或决策时自然也会有偏见。所以传统的机器学习有很多问题,这些最本质的问题通过现有的学习理论没有办法解决,必须借助新的工具。对我来说,我觉得到目前为止,因果模型是其中最有道理的一个工具,但我并不认为它是唯一的一个。
因果机器学习是一个非常新的领域,我读博士之前还没太多的人研究,可以参考的文献也不是很多。当时的情况是,有表征学习,有强化学习,有因果推理,但没有办法把它们拼起来,没有人知道怎么拼,大家都在做各种尝试。像因果强化学习,到目前为止,都没人知道要怎样有效地结合,还在尝试。那种感觉就像是在太平洋上,一个人划着一只船,或者几个人划一只船。
陆超超:我很难讲因果是不是个客观的东西,我觉得它是人类为了更好地理解世界建立的一个观点。从这个角度来说,在数据科学中引入因果,能更好地理解数据,通过数据来理解我们周围的世界。你可以认为因果是个本质的东西,它能处理三个层次的事情:相关性,干预和反事实。至少到目前为止,因果模型比其它大部分模型对数据的理解要更本质。但你不能认为它已经到底了,也许之后人类对数据的理解更深入,因果可能就不是那么本质。我不知道对于智能来讲,想象力(反事实)是不是已经到底了,我现在很难想象,有比想象力更加体现智能的东西。
陆超超:我觉得至少在博士期间,对我影响最大的是 Judea Pearl 和 Bernhard Schölkopf 两个人。Judea Pearl 的书我基本都读过,包括《Causality》、《The Book of Why》、《Causal Inference in Statistics: A Primer》。我最早看的是《Causality》,这本书基本囊括了他所有的观点,对我影响挺大。还有 Bernhard Schölkopf 的书 《Elements of Causal Inference》。
2022集智-凯风研读营线下场地:
十里芳菲
「十里芳菲」主题度假村落是以“新生活美学”理念打造的休闲度假的新场景新案例,提出「新农业+新服务+新家园」的乡村打造新模式,杭州西溪十里芳菲坐落于西湖区西溪国家湿地公园景区内,依托于西溪湿地自然环境、生态人文,倡导“即兴的智慧”的生活理念,以美物、美食、美宿、美力、美愿,构筑的静谧充满生机的村落式休闲目的地。
随着“因果革命”在人工智能与大数据领域徐徐展开,作为连接因果科学与深度学习桥梁的因果表征学习,成为备受关注的前沿方向。以往的深度表征学习在数据降维中保留信息并过滤噪音,新兴的因果科学则形成了因果推理与发现的一系列方法。随着二者结合,因果表征学习有望催生更强大的新一代AI。
集智俱乐部组织以“因果表征学习”为主题、为期十周的读书会,聚焦因果科学相关问题,共学共研相关文献。读书会自2022年12月27日开始,每周六晚20:00线上举行。欢迎从事因果科学、人工智能与复杂系统等相关研究领域,或对因果表征学习的理论与应用感兴趣的各界朋友报名参与。集智俱乐部已经组织三季“因果科学”读书会,形成了超过千人的因果科学社区,因果表征学习读书会是其第四季,现在加入读书会即可参与因果社区各类线上线下交流合作。