Sci. Adv. 综述:机器学习方法在社会和健康科学中的应用

摘要
社会和健康科学中使用的机器学习(Machine Learning, ML)方法需满足描述、预测、因果推断等预期研究目的。本文通过将统计分析引入这些学科,对社会和健康科学中的研究问题与ML方法进行了全面、系统的总结。我们将其分类为描述、预测、反事实预测和因果结构学习,例如,估算不良社会或健康结果的发生率、预测事件的风险、识别风险因素或不良结果的原因、解释常见的ML性能指标等。这一归纳有助于在考虑与社会和健康科学相关领域问题时,充分利用ML的优势并加快ML应用的普及,以推进基础和应用的社会和健康科学研究。
关键词:机器学习

Anja K. Leist, et al. | 作者
赵雨睿 | 译者
郭瑞东 | 审校
邓一雪 | 编辑

论文题目:Mapping of machine learning approaches for description, prediction, and causal inference in the social and health sciences 论文链接:https://www.science.org/doi/10.1126/sciadv.abk1942
1. 引言
2. 将社会和健康科学问题转化为机器学习服务
3. 机器学习的基础
4. 描述中的机器学习
5. 预测中的机器学习
6. 因果推断中的机器学习
7. 机器学习表现性能评估
8. 未来展望
1. 引言
1. 引言
2. 将社会和健康科学问题
转化为机器学习任务
2. 将社会和健康科学问题
转化为机器学习任务
3. 机器学习的基础
3. 机器学习的基础
3.1 传统机器学习方法的分类
3.2 数据准备
3.2.1 数据需求
3.2.2 特征选择
3.2.3 特征工程
3.3 模型建立
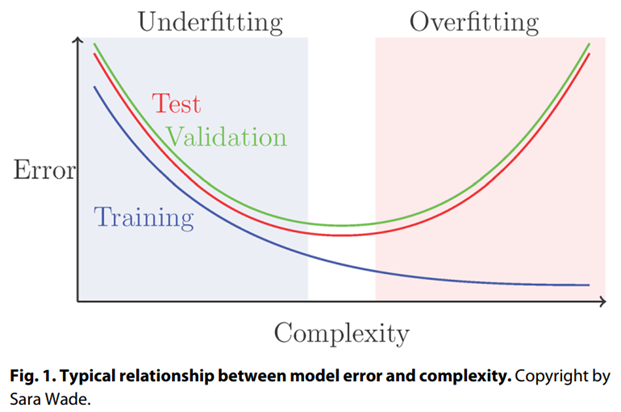
3.4 真实世界应用机器学习的考虑
3.4.1 可解释性与可视化
3.4.2 公平性
3.4.3 泛化性或者外部有效性
3.4.4 提升人类能力和技能
4. 描述中的机器学习
4. 描述中的机器学习
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4.1 筛选和识别高危人群或更高层次的模式
4.2 识别风险状况
4.3 估算和预测社会或健康结果的普遍性
4.4 诊断
4.4.1 获取可能的诊断
4.4.2 解决报告不足或诊断不足的问题
4.5 识别和传播社会或文化的影响
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
5. 预测中的机器学习
5. 预测中的机器学习
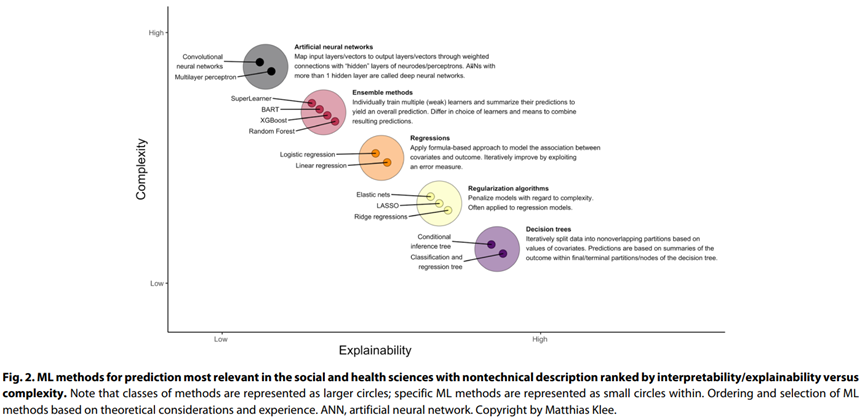
5.1 常见的预测性机器学习方法
5.1.1 惩罚性的方法
5.1.2 集成学习
5.1.3 人工神经网络
5.2 预测社会或健康的输出
5.2.1 预测不良结果的准确性
5.2.2 社会或健康结果的最小和最佳预测器组
5.2.3 罕见结果预测
5.3 新的或已知风险因素识别和评估
5.4 识别正常过程及其波动
6. 因果推断中的机器学习
6. 因果推断中的机器学习
|
|
|
|
|
|
|
|
|
|
6.1 应用1:反事实的推测
6.1.1 常见的机器学习方法
6.1.2 对社会和健康的潜在因素评估
6.1.3 评估比较治疗的有效性
6.1.4 识别异质性治疗效果
6.1.5 评估和消除偏差
6.2 应用2:因果发现或因果结构学习
6.2.1 结构学习
6.2.2 因果结构学习
7. 机器学习表现性能评估
7. 机器学习表现性能评估
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
8. 未来展望
8. 未来展望
参考文献
(参考文献可上下滑动查看)
因果表征学习读书会启动

推荐阅读
-
Sci. Adv.速递:机器学习预测细菌代谢系统的演化 -
Nat. Comput. Sci.:预测极端罕见事件的机器学习算法 -
无量纲学习:机器学习识别无量纲数与标度律 -
《张江·复杂科学前沿27讲》完整上线! -
成为集智VIP,解锁全站课程/读书会 -
加入集智,一起复杂!
微信扫一扫,分享到朋友圈











