PRX 速递:时滞任务中的权重扰动学习 VS 节点扰动学习: 权重扰动学习表现更优

关键词:机器学习,神经网络,权重扰动学习,节点扰动学习

论文题目:Weight versus Node Perturbation Learning in Temporally Extended Tasks: Weight Perturbation Often Performs Similarly or Better 论文来源:Physics Review X 论文链接:https://journals.aps.org/prx/abstract/10.1103/PhysRevX.13.021006
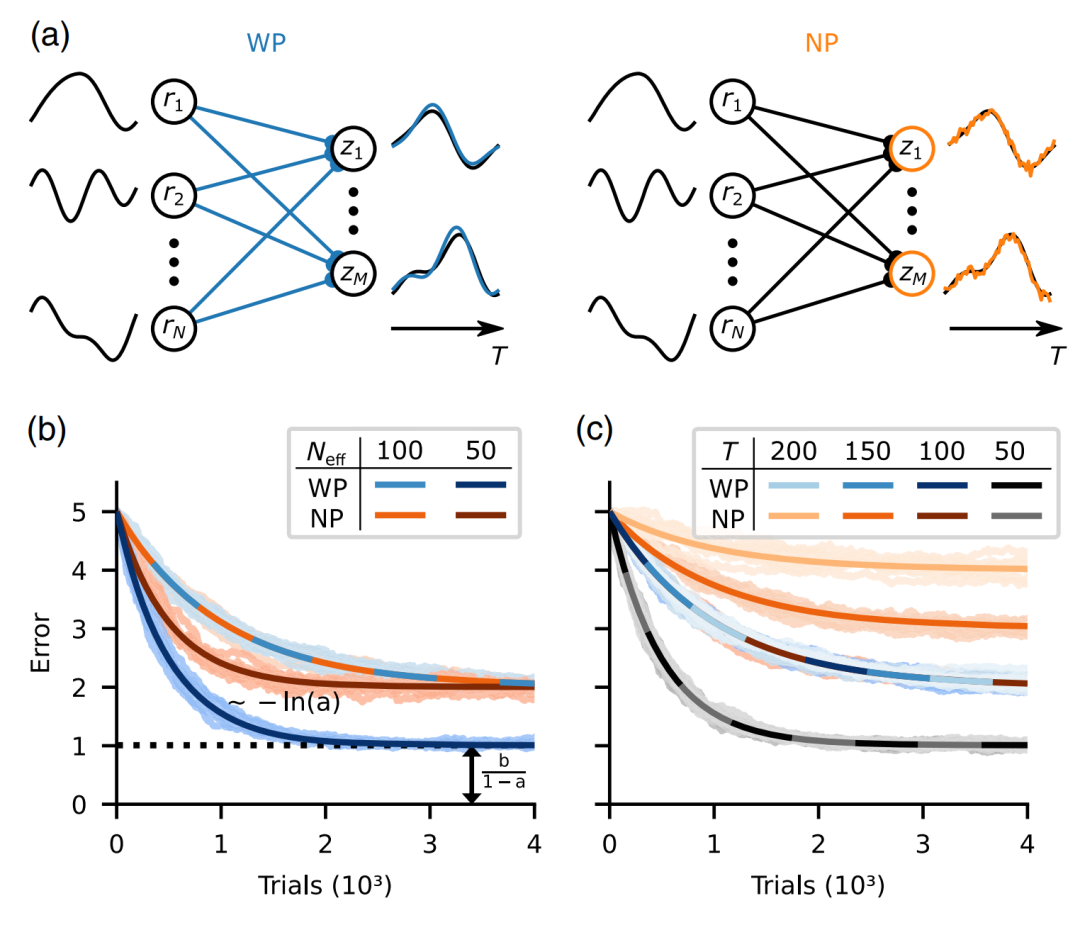
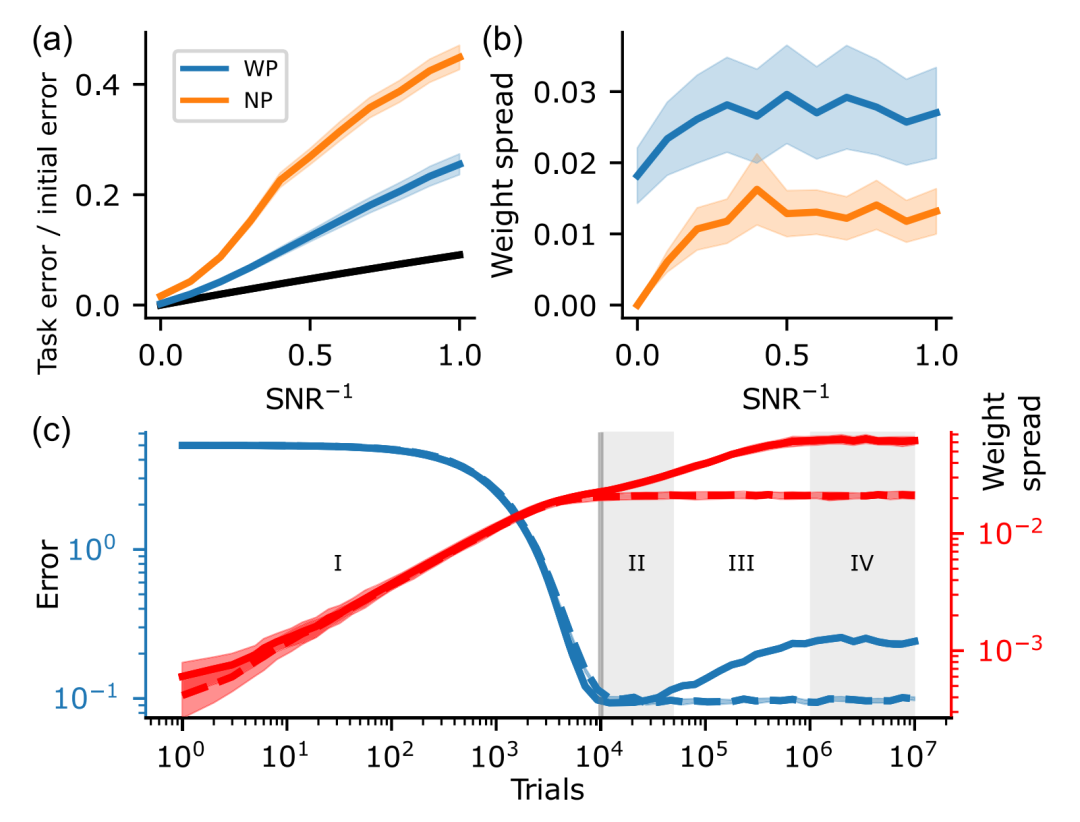
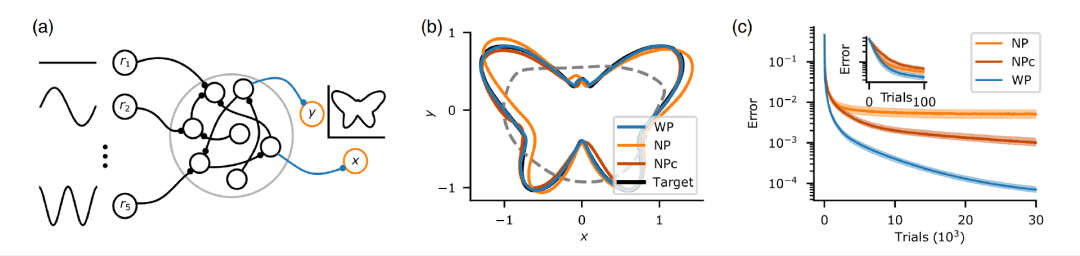
复杂科学最新论文

推荐阅读
微信扫一扫,分享到朋友圈











