语言+知识:大语言模型与知识图谱的相互促进丨周五直播·后ChatGPT读书会

导语
大语言模型因其广泛的知识面而受到广泛的关注,并在许多应用场景中展现出了强大的性能。诸如ChatGPT这样的现代大语言模型已经被广泛应用于文本生成、机器翻译、关键词提取等领域。然而,在商业应用中更加广泛地使用大语言模型仍面临潜在的风险和挑战,因为其输出内容的真实性、一致性尚难以得到保证。为了弥补上述短板,是否可以将数据质量更高的知识图谱作为其知识来源呢?与此同时,大语言模型内部蕴含的丰富知识又能否帮助提高知识图谱的质量和广度?在本次读书会中,我们将讨论大语言模型和知识图谱相互促进的可能形式与现有实践。
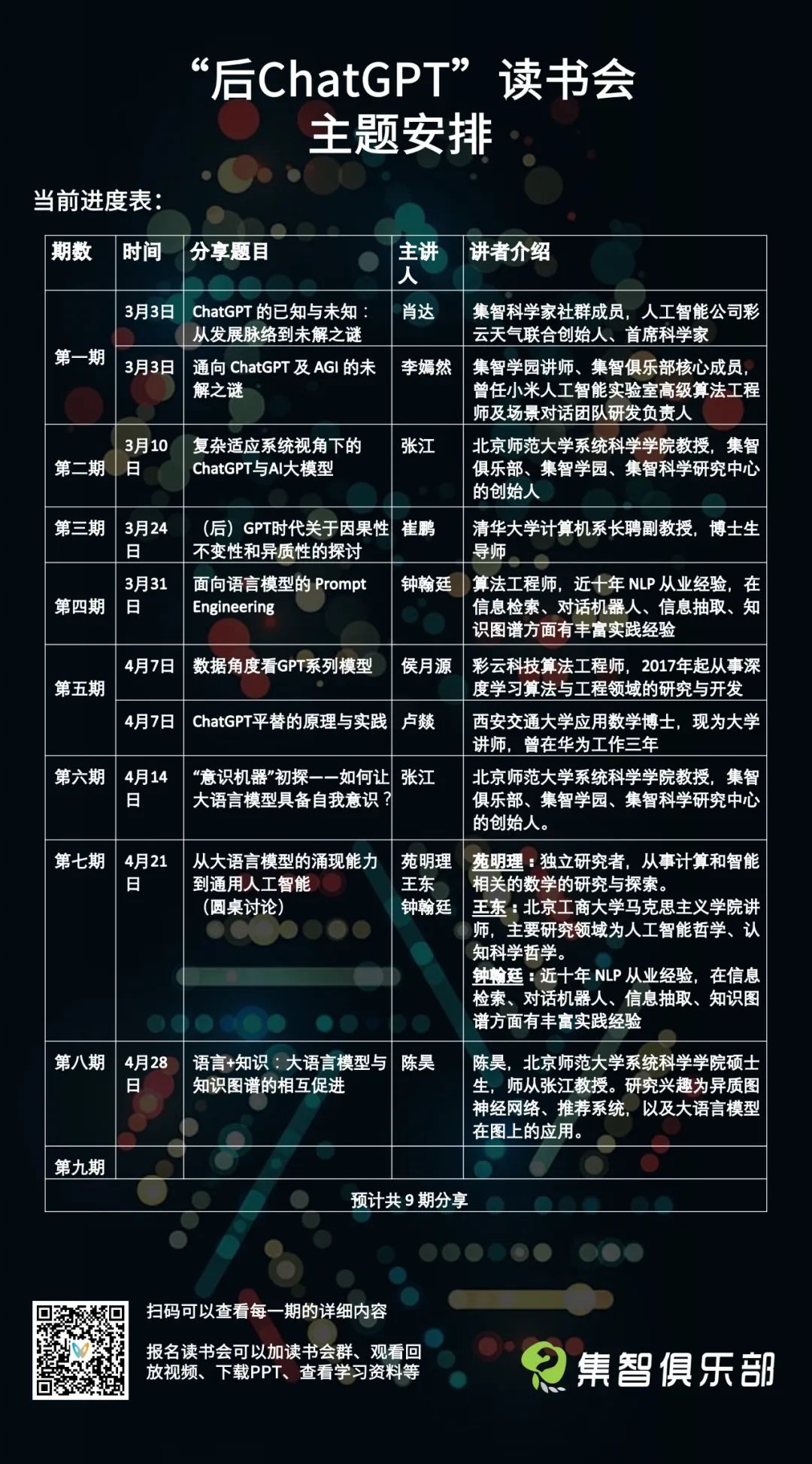
集智俱乐部的“后ChatGPT”读书会由北师大教授、集智俱乐部创始人张江老师联合肖达、李嫣然、崔鹏、侯月源、钟翰廷、卢燚等多位老师共同发起,旨在系统性地梳理ChatGPT技术,并发现其弱点与短板。同时,结合集智俱乐部常年来积累的各种人工智能技术讨论,展望后GPT时代的人工智能都有哪些可能性?读书会自2023年3月3日开始,每周五晚上19:00-21:00举办,欢迎对本话题感兴趣的朋友报名参加!


与读书会之间的关系
与读书会之间的关系
主要涉及到的知识概念
主要涉及到的知识概念
-
大语言模型(Large Language Model, LLM) -
知识图谱(Knowledge Graph) -
提示工程(Prompt Engineering) -
图数据库(Graph Database)
分享简介
分享简介
大语言模型在因其广泛的知识面而受到广泛关注的同时,也面临着在输出内容一致性、正确性和可解释性方面的挑战。反观使用结构化方式承载知识的知识图谱在这些方面有很大优势。在本期读书会中,我们将从原理角度分析大语言模型在这些方面存在的不足和挑战的根源,进而讨论两者相互促进的可能性。具体而言,一方面,我们能否使用质量更高的知识图谱作为大语言模型的知识来源来弥补其不足;另一方面,大语言模型能否用起蕴含的丰富知识来提高知识图谱的质量和广度。
分享大纲
分享大纲
1. 基本概念
2. 问题分析:为什么说大语言模型在原理上便无法保证一致性、正确性
3. 大语言模型与知识图谱如何相互促进
主讲人
主讲人

活动信息
活动信息
时间:2023年4月28日(周五) 晚上 19:00-21:00
参与方式:

扫码参与读书会,加入群聊获取本系列读书会的视频回放权限、资料权限,与社区的一线科研工作者和企业实践者沟通交流。
“后ChatGPT”读书会启动

推荐课程:

链接:https://campus.swarma.org/course/854?from=wechat
微信扫一扫,分享到朋友圈











