重磅圆桌:因果推理、科学发现与大模型 | 周日直播·因果表征 x AI+Science 读书会联动

导语
科学发现作为人类知识进步的核心驱动力,与科学研究的基础因果关系密切相关。通过关注因果发现,研究者能够挖掘数据中潜在的因果关系,获得新的研究思路和方向,从而促进科学发展。此外,现代科学研究越来越注重模型的可解释性,因果发现有助于揭示数据背后的真实机制,为科学家提供更具解释力的模型,进而深化对相关领域的理解。
为了促进因果科学社区、AI+Science社区以及后ChatGPT社区的跨学科交流和碰撞,扩展科研思维,我们组织了此次圆桌活动,希望通过分享+圆桌讨论的形式,帮助大家更好地交流。其中分享环节组主要是由CMU的张坤老师团队介绍因果表征读书会的相关内容。在圆桌讨论环节,来自斯坦福、MIT、CMU等国内外的老师和同学围绕「因果表征学习」「科学发现」以及「大模型」等话题进行探讨和交流。
本次圆桌活动是集智俱乐部三个读书会的联动,欢迎感兴趣的朋友参与!


分享简介
分享简介
因果发现是指从观测数据中推断变量之间的因果关系,而不进行随机实验。这是一个既有挑战又有重要意义的问题,对于人工智能和科学发现都有很大的价值,因为它可以帮助我们理解复杂现象背后的机制,测试因果假设,和设计有效的干预措施。在这次活动中,我们将邀请CMU的张坤教授和他的团队来介绍他们在因果表征学习方面的最新进展,这是一种利用深度神经网络和图模型进行因果发现的新范式。我们还将与来自不同学科的专家进行圆桌讨论,探讨如何将因果发现应用到不同领域的科学发现中。
分享大纲
分享大纲
• 什么是因果表征学习,它为什么重要?
• 如何使用深度神经网络和图模型从数据中学习因果表征?
• 因果表征学习面临哪些挑战和机遇?
• 如何使用因果表征进行不同领域的科学发现?
讲者介绍
讲者介绍

张坤:卡内基梅隆大学副教授和MBZUAI大学副教授,研究兴趣是机器学习和人工智能,尤其是因果发现、基于因果关系的学习和通用人工智能。曾担任大型机器学习或人工智能会议的区域主席或高级程序委员会成员,包括NeurIPS、UAI、ICML、AISTATS、AAAI和IJCAI。
个人主页:https://www.cmu.edu/dietrich/philosophy/people/faculty/zhang.html

谢少安:卡内基梅隆大学张坤教授的博士研究生,研究兴趣是基于因果推论的机器学习与计算机视觉。在机器学习以及视觉领域顶会如ICML, NeurIPS, ICLR, CVPR等以第一作者发表过多篇论文。
个人主页: shaoan.net

黄碧薇:加州大学圣地亚哥分校助理教授,主要研究方向为causal discovery & causality-related machine learning, 以及在生物和神经科学等领域的应用。她的研究贡献已发表在 JMLR、ICML、NeurIPS、KDD、AAAI、IJCAI 、UAI等ML/AI主要期刊和会议。她是 CMU 校长奖学金和Apple AI/ML博士奖学金的获得者。主办了NeurIPS 2020 workshop on causal discovery and causality-inspired machine learning 以及1st conference on Causal Learning and Reasoning (CLeaR)。
个人主页:https://biweihuang.com/
圆桌嘉宾介绍
圆桌嘉宾介绍




直播信息
直播信息
直播时间:
2023年5月7日(周日)上午9:00-11:00

拟讨论的问题列表
拟讨论的问题列表
如何打造一个通用的「AI科学家」平台,赋能科研工作?
1.在AI科学发现的领域中,存在哪些普遍和基础的机器学习问题?这一领域的研究方法有哪些共同的步骤和流程?
2.因果推断在大型语言模型(LLM)中扮演什么样的角色?它们之间有什么联系和区别?
3.LLM如何与科学数据和知识进行交互和融合?LLM与科学领域之间有什么样的接口和桥梁?
4.针对不同领域的科学问题,如何设计和构建一个AI科学家,能够有效地利用新的数据集和数据类型,从而做出有意义的科学发现?这样一个AI科学家系统需要具备哪些关键的组件和功能?
5.在AI科学发现的研究中,有哪些子领域之间的组合是较少被关注但具有重要价值的?
6.LLM在处理科学数据和知识时,如何解决不确定性问题?不确定性对LLM的性能和效果有什么影响?
因果关系和大型语言模型
-
因果推理:大型语言模型是否能够学习进行因果推理?它们是否能够区分因果关系,并利用这种理解来预测未来事件? -
因果推断:如何利用大型语言模型进行因果推断任务,例如识别干预对系统的因果效应或预测政策变化的影响? -
因果发现:大型语言模型是否可以用于因果发现任务,例如在复杂系统中识别变量之间的因果关系? -
反事实推理:大型语言模型是否能够推理出反事实情景,例如“如果……会怎样”,并生成可信的反事实结果? -
干预推理:大型语言模型是否能够推理出干预的影响,例如改变变量值对系统结果的影响? -
偏见和公正:大型语言模型是否能够设计出对数据和决策过程中的偏见和公正进行因果推理的方法,并生成干预措施来解决这些问题? -
可解释性:如何使大型语言模型在其因果推理能力方面更具可解释性,以便更好地理解和分析其决策过程? -
时间序列预测:大型语言模型能否通过学习因果关系来进行时间序列预测,例如预测未来的气温、股票价格或流行病趋势? -
因果语言生成:大型语言模型能否生成包含因果关系的自然语言文本,例如解释某个事件的原因和结果? -
对抗干扰:大型语言模型能否应对对抗性攻击和干扰,例如识别对抗性样本并保持其因果推理能力? -
因果图神经网络:可以将因果图和神经网络结合起来,以实现更准确和高效的因果推理和预测?
AI for科学发现与大模型
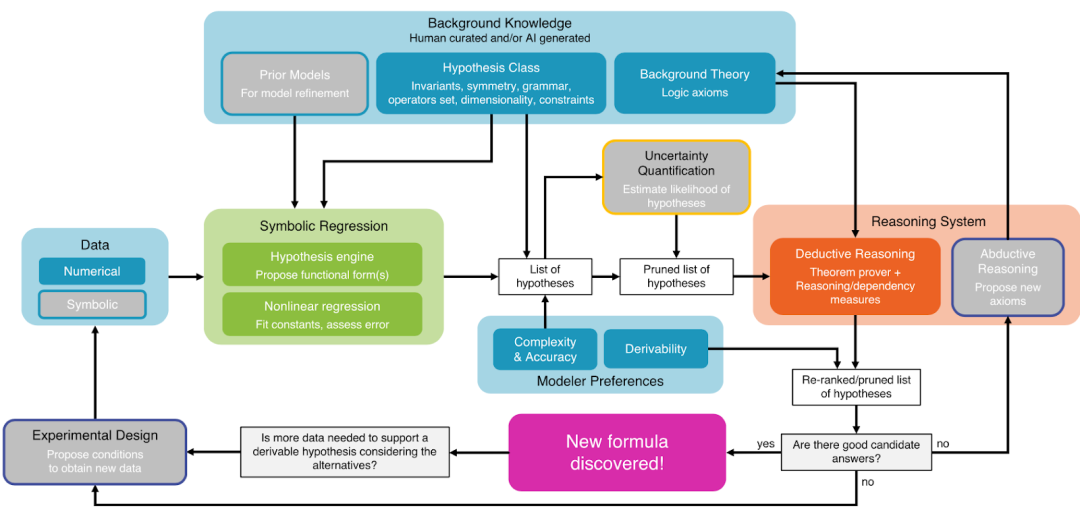
-
符号回归(symbolic regression):根据输入和输出的数据,发现符号表示的方程能尽可能准确简明地把输入映射到输出。
-
概念学习(concept learning):从数据中自动学习和提取出抽象概念。比如从数据中提取出“准粒子”、“对称性”、“熵”等抽象的概念。
-
词典学习(dictionary learning):从数据中学习一组基本元素(称为字典),使得数据可以通过这些基本元素的稀疏线性组合来表示。比如从数据中学出一系列的数学公理,又比如从数据中学习出一系列的物理理论。
-
关系学习(relation learning):自动学习和识别系统中不同子系统的潜在关系。
-
因果学习(causal learning):自动学习和识别数据中的因果关系。
-
AI用于推理(AI for reasoning):AI可以帮助演绎推理(deductive reasoning)和诱导推理(abductive reasoning)。演绎推理是指一般原则或前提出发,通过逻辑推导得出特定结论,比如定理证明(theorem proving)。诱导推理是指根据观察到的现象或结果,尝试找到最可能的解释或原因。
-
AI用于实验设计(AI for experimental design):AI帮助科学家和研究人员更高效地设计实验,找到最优实验条件,提高数据收集的质量,并加速知识发现过程。包含搜索最优实验条件、自动优化、多目标优化、高效筛选、无监督学习、以及预测和推理等方面。
-
AI用于离群点检测(Outlier Detection):用于识别数据集中与大多数数据点显著不同的数据点。在粒子物理、宇宙学、材料科学等方面有重要应用
-
AI科学家:把以上各部分有机组合起来, 形成一个闭环的AI科学家从事科学研究。有名的工作有Adam [2], AI Physicist [3],AI-Descartes [1], LLM for scientific experiments [4]等。
大模型 for 因果发现与机器学习
[1] MLCopilot: 释放大型语言模型解决机器学习任务的能力
• 动机:机器学习在各个领域得到了广泛的应用,但针对特定场景自适应的机器学习仍然是昂贵且不容易的。而现有的自动化机器学习方法通常耗时且难以理解,本研究旨在通过引入新的框架MLCopilot,利用LLM来开发新型机器学习任务的机器学习解决方案,以弥合机器智能和人类知识之间的差距。
• 方法:提出一种新框架MLCopilot,利用最先进的语言模型(即LLM)为新机器学习任务开发机器学习解决方案。该研究将问题分解成两个组件,包括离线和在线阶段。离线阶段,MLCopilot将历史数据规范化,并创建经验池。LLM用于从历史经验中提取有价值的知识。在线阶段,MLCopilot根据目标任务的描述从经验池中检索最相关的任务经验,然后与LLM交互以一次性获得多个建议的机器学习解决方案。
• 优势:展示了LLM扩展到理解结构化输入和执行彻底推理的可能性,并发现经过一些专门设计后,LLM可以从现有的机器学习任务中获得经验,并有效地推理出有前途的结果。生成的解决方案可以直接用于实现高水平的竞争力。还提出了一种新的检索和提示框架,用于几乎即时地解决机器学习任务,而无需任何耗时的搜索或优化。
• 动机:大型语言模型的因果推理能力一直是一个争议性的问题,对其在医学、科学、法律和政策等领域的应用具有重要意义。本文旨在深入了解大型语言模型的因果能力,并考虑不同类型因果推理任务之间的区别以及构造和测量效度的威胁。
• 方法:采用多个因果基准测试数据集,发现基于大型语言模型的方法在多个因果推理任务中取得了新的最高准确率,并能使用自然语言输入系统地处理因果关系。同时提供了一些技巧来解释大型语言模型的失效模式。
• 优势:大型语言模型可以作为人类领域知识的代理,以减少人类在因果分析中的工作量,同时帮助实现协变与逻辑因果分析的统一。
[3]复杂推理:大语言模型的北极星能力
我们研究复杂推理的原因有两个:
• 正如上文提到的,复杂推理是标志着小模型与大模型差异的关键因素,这一点在 GPT-4 发布文章中已经讨论过。
• 复杂推理是使模型成为下一代操作系统的核心能力。
将语言模型视为下一代操作系统的愿景尤为有趣,因为它为构建新应用程序和创建基于语言模型的计算生态系统(可能比超级应用程序如 ChatGPT 提供更大的机会)开辟了无数可能性。复杂推理能力是基础,因为如果我们希望模型成为新的操作系统,它需要能够通过与工具、用户和外部环境的所有元素互动来完成复杂的指令。
本文研究了如何训练具有强大复杂推理能力的模型,如何进行提示工程以充分发挥模型的推理能力,以及如何评估模型的推理性能。本文的内容分为以下几部分:
• 在第 2 部分,我们讨论了构建具有强大复杂推理能力的语言模型的现有方法。复杂推理的方案与通用大型语言模型(LLM)开发的方案相似,包括三个阶段:持续训练 (continue training)、指令微调 (instruction finetuning) 和强化学习 (reinforcement learning)。我们还会进一步讨论代码与推理之间令人惊讶的耦合关系。
• 在第 3 部分,我们讨论了复杂推理的提示工程 (prompt engineering) 技术。当语言模型成为新一代操作系统内核时,提示工程 / 场景学习将成为新一代脚本编程 (shell script)。
因果表征学习读书会启动
随着“因果革命”在人工智能与大数据领域徐徐展开,作为连接因果科学与深度学习桥梁的因果表征学习,成为备受关注的前沿方向。以往的深度表征学习在数据降维中保留信息并过滤噪音,新兴的因果科学则形成了因果推理与发现的一系列方法。随着二者结合,因果表征学习有望催生更强大的新一代AI。
集智俱乐部组织以“因果表征学习”为主题、为期十周的读书会,聚焦因果科学相关问题,共学共研相关文献。欢迎从事因果科学、人工智能与复杂系统等相关研究领域,或对因果表征学习的理论与应用感兴趣的各界朋友报名参与。集智俱乐部已经组织三季“因果科学”读书会,形成了超过千人的因果科学社区,因果表征学习读书会是其第四季,现在加入读书会即可参与因果社区各类线上线下交流合作。

AI+Science 读书会启动

点击“阅读原文”,报名读书会
微信扫一扫,分享到朋友圈











