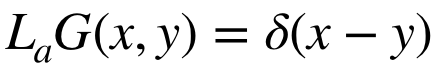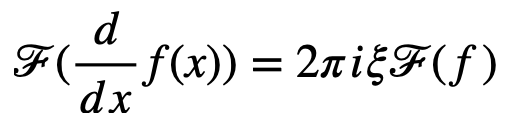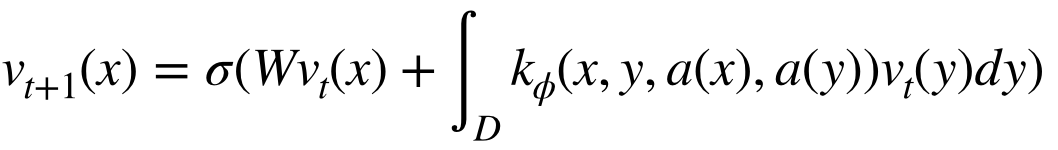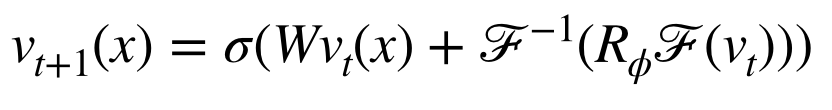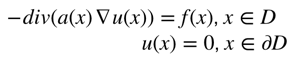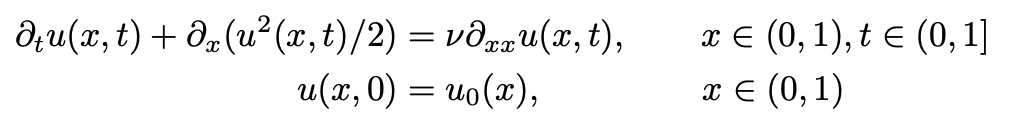从物理学中的热扩散方程、描述流体运动的纳维耶-斯托克斯方程、刻画量子波函数的薛定谔方程,到生物学中描述斑图形成的反应扩散方程,偏微分方程(PDE)的应用非常广泛。但求解 PDE 却是非常困难的问题。机器学习方法为此提供了便利。
加州理工学院博士生李宗宜等人提出了傅立叶神经算子(Fourier neural operator, FNO)方法,将傅立叶变换应用于深度学习中,是一种能够学习无限维函数空间之间映射的深度学习架构。傅立叶神经算子非常适合学习偏微分方程的数值解,比一般的深度学习方法更快速和准确,且误差不随分辨率的变化而变化。
在集智俱乐部「AI+Science」读书会本周日(5月28日)的分享中,李宗宜博士将分享自己在神经算子学习方面的最新工作,同时斯坦福大学的赵青青博士将介绍基于图神经网络(Graph Neural Network)进行物理仿真的系列工作,欢迎感兴趣的朋友参与~
仇竞纬(NCC lab) | 作者
刘泉影 | 校对
神经计算和控制实验室 | 来源
最近NCC lab 讨论了一篇加州理工学院的Li Zongyi同学于2020年8月发表在ICLR上的文章 《Fourier neural operator for parametric partial differential equation》。
太长不看版:在这篇文章中,作者把传统的神经网络推广到神经算子,即一种能够学习无限维函数空间之间映射的架构。通过在傅立叶空间上对积分核进行参数化,构造了这种神经算子。这种神经算子非常适合学习偏微分方程的数值解,并且比一般的深度学习方法更快速和准确。最后,作者在伯格斯方程、达⻄流方程、纳维–斯托克斯方程上进行了实验,证明了 神经算子 的相对误差比其他方法几乎低了一个数量级,而且误差值不会随着训练数据的分辨率的变化而变化。
这篇文章的主要作者是加州理工学院的Li Zongyi, Nikola Kovachki和Anima Anandkumar。Li Zongyi 是加州理工学院的博士学生,Zongyi的导师Anima Anandkumar是加州理工学院的教授,同时也是英伟达机器学习部⻔的负责人。
神经网络 (neural network) 是一种由大量节点构成的运算模型。每个节点代表一种特定的输出函数,称为激励函数 (activation function)。各个节点 (或称神经元) 之间相互连接,形成神经网络的层 (layer)。神经网络的输入和输出一般都是有限维的向量。
神经算子 (neural operator) 是对神经网络的一种扩展,其输入和输出都是一个函数。
偏微分方程 (PDE) 是包含了未知函数的偏导数的方程。偏微分方程在数学,物理及工程技术上应用广泛,薛定谔方程,伯格斯方程,爱因斯坦场方程等都属于偏微分方程。
傅立叶空间 (Fourier space),即频率空间。现代人听的Fm电台就是用电台波段的频率来命名,如中央人⺠广播电台频率就是89.3兆赫。
PDE作为一种建模工具,从19世纪开始就被广泛应用于物理,数学上。热方程、薛定谔方程、纳维–斯托克斯方程等都是物理上非常有名的例子。近来PDE也被逐渐应用于生物学,反应扩散方程 (reaction-diffusion equation) 就被应用于模式形成 (pattern formation) 的研究,斑⻢、老⻁身上斑纹的形成就可以用反应扩散方程来解释。
但PDE的求解也是一个十分艰难的问题,传统的PDE求解方法包括有限差分法 (finite difference)、有限元法 (finite element) 等 ,这些方法速度较慢,有时效率低下。例如,当设计机翼等材料时,我们需要对前向模型进行数千次评估。因此,我们亟需一种更有效率的方法。
机器学习方法为PDE和许多数学问题的求解提供了便利的途径,成为了革新许多科学与工程学科的关键所在。但是经典的神经网络是有限维欧氏空间之间的映射,如果我们想用神经网络来对PDE进行求解,则需要对PDE的函数定义域进行离散化,并且每次只能学习到特定离散区间下的PDE的解。这在实际应用中往往是不够的,因此我们需要一种能够对不同离散区间都适用的神经网络 (mesh-invariant neural network)。在研究人员发明神经算子之前,主流的基于神经网络求解PDE的方法包括了有限维算子 (finite- dimensional operator) 和神经FEM (neural-FEM)。
由Guo Xiaoxiao等人提出的有限维算子 通过把PDE的解算子参数化为有限维欧氏空间之间的深度卷积神经网络,实现了对PDE的求解。这些方法并不是mesh-invariant的,即对不同的离散区间我们往往需要对有限维算子进行修改和调整。除此之外,这种方法也受到训练数据的几何形状与离散区间的局限:对于PDE的定义域上存在但数值网格不能覆盖到的点,我们无法用有限维算子求得对应的解。
与有限维算子不同,神经FEM直接把PDE的解参数化为一个神经网络。因此,当PDE的系数发生变化时,我们都需要训练一个新的神经FEM来对PDE求解。这种方法与经典的有限元方法非常相似,不同的地方就在于神经FEM把有限元方法中的基函数换成了神经网络。同时,神经FEM与经典数值方法的局限性相似:需要针对每一个新的实例解决优化问题并且必须知道PDE的具体表达式。
由于神经算子是对神经网络的一个推广,我们在这里先介绍神经网络的基本架构。顾名思义,神经网络模仿的是人类大脑神经元的结构,但同时又与生物神经元有着显著的差别。在数学上,我们可把神经网络定义为一个连续的复合函数
F = σ ∘ WK−1 ∘ . . . ∘ σ ∘ W1 ∘ σ ∘ W0
其中K为神经网络的深度,{W0, . . . , WK−1}为可训练的权重,激活函数σ应用到向量的每一个元素中。可⻅,神经网络可被看作有限维欧氏空间之间的一个映射。但PDE处理的是无穷维的函数,因此我们需要一个新型的能处理函数的神经网络。
对于一个PDE Lau = f (很多PDE可被表达成这个形式,比如达⻄流方程 −div(a(x)∇u(x)) = f(x)),我们可以用格林函数写出它的解。格林函数是一种用来解有初始条件或边界条件的非⻬次微分方程的函数。对一个微分算子La,它的格林函数满足
PDE Lau = f 的解 可以用这个格林函数表达出来:
由格林函数法我们知道,一个PDE的解可以表示成以上积分的形式。通过这个启示,作者们在神经算子中引入了一个积分算子,使得神经算子能够处理关于函数的数据。
数学家们在求解PDE的经验中发现,对一个PDE做傅立叶变换往往能够使问题变得简单。这一个秘诀藏在这个傅立叶变换公式中,即物理空间 (即以x为变量的空间)上的微分等效于傅立叶空间中的乘法:
通过傅立叶变换,PDE上的一部分偏微分被消除,而PDE也被转化成一个ODE,问题由此得到简化。类似地,傅立叶变换也被尝试用在深度学习中,神经算子的工作就借助了傅立叶变换的帮助。
傅里叶变换在深度学习的发展中发挥了重要作用。理论上,它们出现在通用逼近定理的证明中 [Hornik et al., 1989],同时也被用于加速卷积神经网络 [Mathieu et al., 2013]。Bengio et al.,2007, Mingo et al.,2004,Sitzmann et al.,2020等还提出并研究了涉及傅立叶变换或使用正弦激活函数的神经网络架构。最近,一些偏微分方程的谱方法已扩展到神经网络 [Fan et al., 2019a, Fan et al., 2019b]。本文作者Li Zongyi在这些前人工作的基础上,提出了一种直接在傅立叶空间中定义的神经算子架构。
神经算子拥有一个迭代结构 a → v0 → . . . → vT → u,其中的迭代关系可以用
来表示,其中{W0, . . . , WT−1}为训练的权重,vj是一系列函数,每一个函数取值于Rdv。其中由a到 v0的转换可以由局部变换P : Rda → Rdv来完成,即v0 = P(a)。这一局部变换P一般通过浅层全连接网络进行参数化。类似地,输出u = Q(vT )是vT通过局部变换Q : Rdv → Rdu后的投影。在每次迭代中更新vt+1由前一时刻vt通过非局部积分算子K和局部非线性激活函数σ的连续变换得到。kφ是从数据中学得的核函数。通过引入积分算子,我们成功地完成了神经网络向无限维空间的推广。
在卷积神经网络 (CNN) 中,每个卷积层学的是局部的信息,比如对一张图片来说,卷积层抽取的是3 × 3或5 × 5的一块。但对于连续函数来讲,我们更关注它全局的信息,傅立叶变换在处理全局信息时更有优势。
对此,研究人员提出了用傅立叶变换定义神经算子中的积分算子。令F表示对函数的傅立叶变换, F−1表示傅立叶反变换,则对函数f : D → Rdv的傅立叶变换和反变换可以定义为
其中i为虚数单位,j = 1,…,dv为函数的指标。若我们令积分算子(2)中的核
kφ(x, y, a(x), a(y)) = kφ(x − y),则积分算子(2)变成一个卷积(kφ * vt)(x)。运用卷积定理F(kφ * vt) = F(kφ)F(vt) 我们可以得到积分算子的新定义
把这个卷积的傅立叶表达式 代入到 神经算子的迭代公式中,即可得到
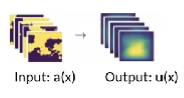
神经算子所需要的训练数据是{aj, uj}, 其中aj是方程中的系数(coefficient function),uj则是所对应的方程的解。神经算子将会学习aj和uj之间的对应关系,当输入一个新的系数aj时神经算子将会预测相对应的PDE 解uj。这种思路可以类比图像到图像的回归学习,如图 1 所示
文章介绍了傅立叶神经算子,这是一种能够学习无限维函数空间之间映射的深度学习架构。
• 算法优越性:傅立叶神经算子是mesh-invariant的,可以学习不同离散区间条件下PDE的解而不需要针对每个离散区间进行调整。
• 性能优越性:在文章展示的实验中,傅立叶神经算子的学习效果优于所有现有的PDE 深度学习方法。相比其它方法,傅立叶神经算子的错误率在伯格斯方程上降低了 30%,在达⻄流方程上降低了 60%,在纳维–斯托克斯方程 (雷诺数为 10000 的湍流状态) 上降低了 30%。在学习整个时间序列的映射时,该方法在雷诺数为1000 时的误差小于 1%,在雷诺数为10000 时的误差为 8%。
• 计算高效性:在 256 × 256 网格上,傅立叶神经算子的计算时间仅为 0.005 秒,而用于求解纳维–斯托克斯的伪谱方法的计算时间为 2.2 秒。
伯格斯方程是一种非线性偏微分方程,具有多种应用,包括模拟粘性流体的流动。一维的伯格斯方程可以写成以下形式
其中 u0 ∈ L2((0,1); R) 是初始条件,ν 是粘度系数。我们的目标是训练一个神经算子,使它尽可能地逼近解算子G : L2((0,1); R) → Hr((0,1); R),解算子G : u0 → u(⋅,1)从初始条件u0映射到时间t = 1时的解u(⋅,1)。初始条件 u0(x) 符合一个高斯分布,即 u0 ∼ N(0,625(−Δ + 25I )−2),粘度ν设置为0.1。
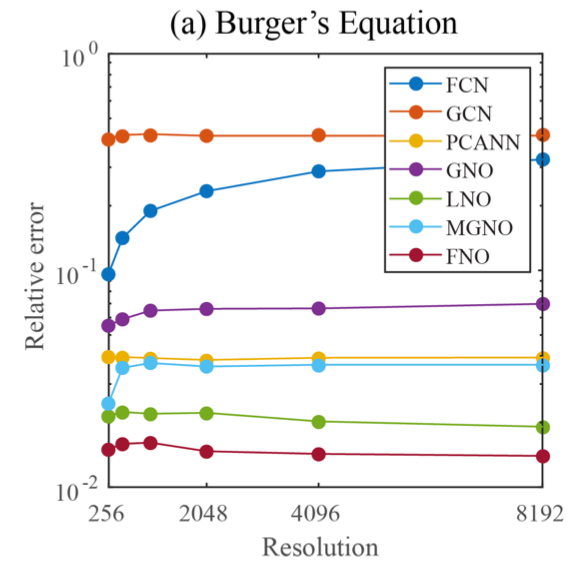
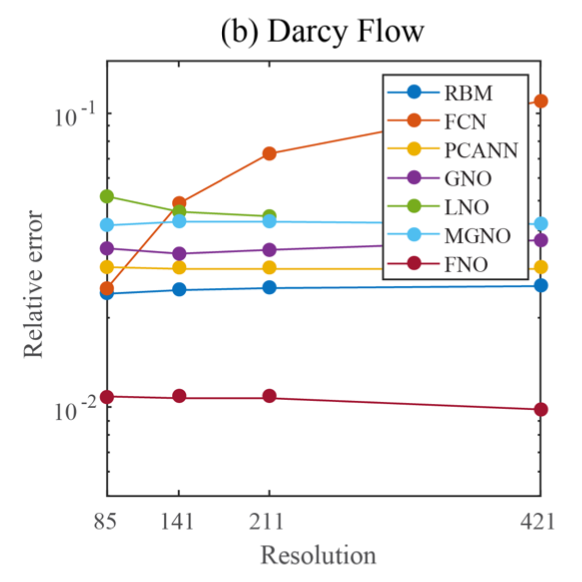
实验的结果如图 2 所示。与任何深度学习方法相比,傅立叶神经算子 (FNO) 获得了最低的相对误差。基于卷积神经网络的方法 (FCN) 的误差随着训练数据的分辨率的增加而增⻓,除此之外其它 方法的误差基本独立于训练数据的分辨率。与在物理空间中使用 Nyström 采样的 GNO 和 MGNO 等其他神经算子方法相比,傅立叶神经算子更准确且计算效率更高。
PCANN:一种使用 PCA 作为输入和输出数据的自动编码器
GNO:一种图神经算子
LNO:基于核k (x , y)的低秩分解的神经算子方法
MGNO:一种多极图神经算子
FNO:傅立叶神经算子
其中 a ∈ L∞((0,1)2; R+)是扩散系数,f ∈ L2((0,1)2; R) 是强制函数。该 PDE 有许多应用,包括模拟地下流体的压力、线弹性材料的变形以及导电材料的电势。作者通过神经算子学习了达⻄流方程的解,并与其它的深度学习方法进行了比较。它们的计算结果与PDE的真实解之间的误差可参⻅图(3)
其中RBM指的是一种经典的简化基方法 (使用 POD 基),其余的缩写可参考上文。
纳维–斯托克斯方程是流体力学上的著名方程,可以用于描述各种流体的运动,如高空气流、洋流、管道中的水流、机翼附近空气的流动、星系中天体的运动等。下面这个纳维–斯托克斯方程可以用于描述二维的粘稠不可压缩流体
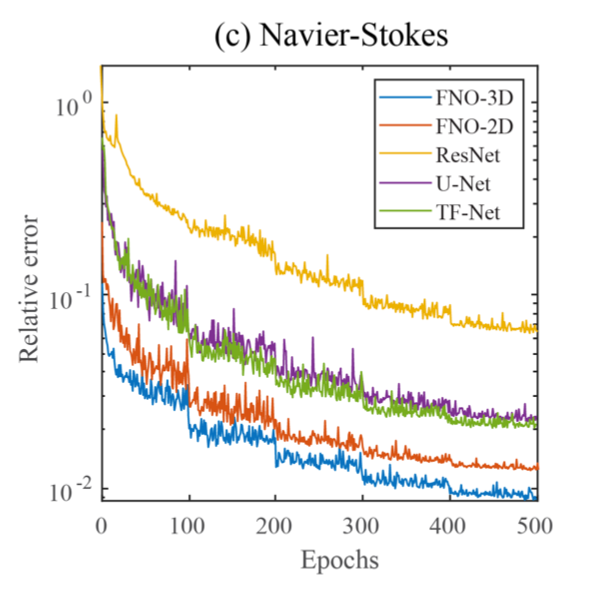
其中 u ∈ C([0,T ]; Hr((0,1)2; R2)) 为速度场,w = ∇ × u是涡度,w0 ∈ L2((0,1)2; R) 是初始涡量, ν ∈ R+ 是粘性系数,f ∈ L2((0,1)2; R)是强迫函数。我们的目标是训练一个神经算子来学习映射G : C([0,10]; Hr((0,1)2; R)) → C([10,T ]; Hr((0,1)2; R)),即一个从[0,10]的涡度 映射到 [10,T]的涡度的算子。训练的效果如下图所示
图4. 各种深度学习方法在纳维-斯托克斯方程上的学习效果
其中
ResNet:具有残差连接的 18 层二维卷积网络。
U-Net:一种用于处理图像到图像回归任务的流行方法。
TF-Net:一种用于学习湍流的网络。
FNO-2d:具有 RNN 结构的二维傅立叶神经算子。
FNO-3d:直接在时空中进行卷积的三维傅立叶神经算子。
Bengio, Y., LeCun, Y., et al. (2007). Scaling learning algorithms towards ai. Large-scale kernel machines, 34(5):1–41.
Fan, Y., Bohorquez, C. O., and Ying, L. (2019a). Bcr-net: A neural network based on the nonstandard wavelet form. Journal of Computational Physics, 384:1–15.
Fan, Y., Lin, L., Ying, L., and Zepeda-Nu ́nez, L. (2019b). A multiscale neural networkbased on hierarchical matrices. Multiscale Modeling & Simulation, 17(4):1189–1213.
Hornik, K., Stinchcombe, M., White, H., et al. (1989). Multilayer feedforward networks are universal approximators. Neural networks, 2(5):359–366.
Li, Z., Kovachki, N., Azizzadenesheli, K., Liu, B., Bhattacharya, K., Stuart, A., and Anandkumar, A. (2020a). Fourier neural operator for parametric partial differential equations.
Mingo, L., Aslanyan, L., Castellanos, J., Diaz, M., and Riazanov, V. (2004). Fourier neural networks: An approach with sinusoidal activation functions.
Mathieu, M., Henaff, M., and LeCun, Y. (2013). Fast training of convolutional net- works through ffts.
AI+Science 是近年兴起的将人工智能和科学相结合的一种趋势。一方面是 AI for Science,机器学习和其他 AI 技术可以用来解决科学研究中的问题,从预测天气和蛋白质结构,到模拟星系碰撞、设计优化核聚变反应堆,甚至像科学家一样进行科学发现,被称为科学发现的“第五范式”。另一方面是 Science for AI,科学尤其是物理学中的规律和思想启发机器学习理论,为人工智能的发展提供全新的视角和方法。
集智俱乐部联合斯坦福大学计算机科学系博士后研究员吴泰霖(Jure Leskovec 教授指导)、哈佛量子计划研究员扈鸿业、麻省理工学院物理系博士生刘子鸣(Max Tegmark 教授指导),共同发起以“AI+Science”为主题的读书会,探讨该领域的重要问题,共学共研相关文献。读书会从2023年3月26日开始,每周日早上 9:00-11:00 线上举行,持续时间预计10周。欢迎对探索这个激动人心的前沿领域有兴趣的朋友报名参与。
报名链接:https://pattern.swarma.org/study_group/24?from=wechat
现实世界中大量问题的解决依赖于算法的设计与求解。传统算法由人类专家设计,而随着人工智能技术不断发展,算法自动学习算法的案例日益增多,如以神经网络为代表的的人工智能算法,这是算法神经化求解的缘由。在算法神经化求解方向上,图神经网络是一个强有力的工具,能够充分利用图结构的特性,实现对高复杂度算法的高效近似求解。基于图神经网络的复杂系统优化与控制将会是大模型热潮之后新的未来方向。
为了探讨图神经网络在算法神经化求解的发展与现实应用,集智俱乐部联合国防科技大学系统工程学院副教授范长俊、中国人民大学高瓴人工智能学院助理教授黄文炳,共同发起「图神经网络与组合优化」读书会。读书会将聚焦于图神经网络与算法神经化求解的相关领域,包括神经算法推理、组合优化问题求解、几何图神经网络,以及算法神经化求解在 AI for Science 中的应用等方面,希望为参与者提供一个学术交流平台,激发参与者的学术兴趣,进一步推动相关领域的研究和应用发展。读书会从2023年6月14日开始,每周三晚 19:00-21:00 举行,持续时间预计8周。欢迎感兴趣的朋友报名参与!
推荐阅读
点击“阅读原文”,报名读书会