思考生命复杂性的新视角:从组装理论到梯径理论
导语
复杂的生命如何从化学中产生?生命和非生命的界线如何确定?如果遇到具有不同化学组成的外星生命,我们能识别出来吗?英国格拉斯哥大学的 Lee Cronin 和美国亚利桑那州立大学的 Sara Walker 领导的研究小组,提出一种称为组装理论(assembly theory)的方法,通过计算从构造模块组成物体需要的最少步骤,来客观地衡量物体的复杂性。组装理论可以在生物与非生物分子之间划出一条明确的分界线,并可能为复杂性的产生和演化带来全新视角。
现任北京师范大学珠海校区-复杂系统国际科学中心特聘副研究员的刘宇博士长期专注生命起源和信息理论的研究,他对组装理论进行了评论,梳理了历史上的多种复杂度理论,指出组装理论可能存在的疑难之处,并介绍了另一种刻画复杂度的理论——梯径(Ladderpath)理论。

Philip Ball | 作者
郭瑞东 | 译者
梁金 | 审校
1. 思考复杂性的新视角
1. 思考复杂性的新视角
论文题目: Identifying molecules as biosignatures with assembly theory and mass spectrometry 论文地址: https://www.nature.com/articles/s41467-021-23258-x
论文题目: Exploring the sequence space of unknown oligomers and polymers 论文地址: https://www.sciencedirect.com/science/article/pii/S2666386421004100 论文题目: Exploring and mapping chemical space with molecular assembly trees 论文地址: https://www.science.org/doi/10.1126/sciadv.abj2465

图1. 组装理论试图捕捉 Lee Cronin 的直觉,即复杂分子不可能凭空产生,因为组合空间太大了。Lee Cronin 的学者主页:https://www.chem.gla.ac.uk/cronin/
2. 事物的顺序
2. 事物的顺序

图2. 美国亚利桑那州立大学的 Sara Walker 一直在探索地球生命的起源,以及如何识别遥远星球的其他生命形式。Sara Walker 的学者主页:https://search.asu.edu/profile/1731899
3. 量化复杂性
3. 量化复杂性
4. 衡量生命复杂性的指标
4. 衡量生命复杂性的指标
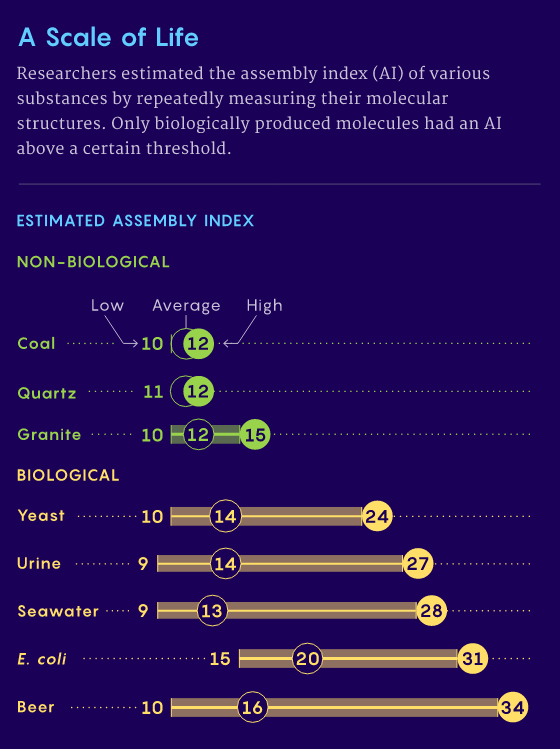
图3. 研究人员通过反复测量分子结构来估计不同物质的组装指数,非生物与生物分子之间存在明确的分界。| 来源:https://www.nature.com/articles/s41467-021-23258-x
论文题目: Multimodal Techniques for Detecting Alien Life using Assembly Theory and Spectroscopy 论文地址: https://arxiv.org/abs/2302.13753

图4. Hector Zenil,剑桥大学计算机科学家和生物技术学家,算法信息动力学提出者。学者主页:https://hectorzenil.net/
5. 挣脱决定论的枷锁
5. 挣脱决定论的枷锁
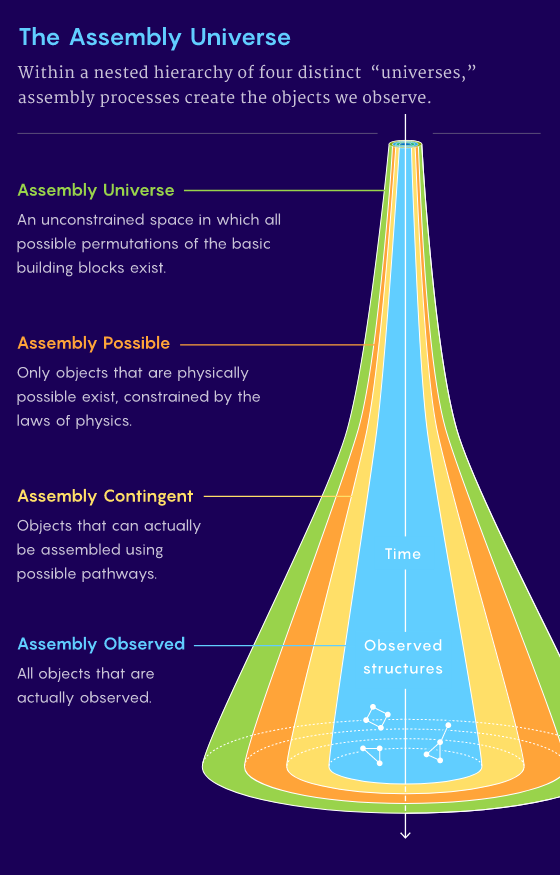
图5. 组装宇宙四个层级的示意图。组装理论确定了包含四个不同“宇宙”的嵌套层级结构,组装过程创造了我们观察到的物体。
论文题目: Assembly Theory Explains and Quantifies the Emergence of Selection and Evolution 论文地址: https://arxiv.org/abs/2206.02279
论文题目: Formalising the Pathways to Life Using Assembly Spaces 论文地址: https://www.mdpi.com/1099-4300/24/7/884
6. 超越所有度量方法?
6. 超越所有度量方法?
评论
刘宇 | 作者
1. 组装理论:评论
1. 组装理论:评论
组装理论(Assembly Theory)的出发点是:如果一个体系中有大量相同的复杂分子,那么可以判断,这个体系一定是生命或类生命、或是由它们产生的。
1. “大量”这个观点是新颖的。只有单个复杂分子是不足以做出上述判断的,因为这个复杂分子完全可能是随机过程产生的。
这里有必要把与柯式复杂度有同样精神(in the same sprit)的描述客体复杂度的理论列举一下(这类理论非常多,所以以下并不能包含所有):
1.霍夫曼编码(Huffman coding, 1952)David A. Huffman:无损数据压缩算法,根据预测到的符号重复出现的频率来编码(构造 Huffman Tree 使得任一符号都可以高效地唯一解码),频率越高,编码该符号的长度越短。
2.Lempel-Ziv 压缩算法(1976):无损数据压缩算法,是基于字典的编码器(而不是基于如霍夫曼编码所采用的频率);在构造字典的时候,是基于“前面出现过的亚序列可以直接重复利用”的思想。
3.“自然是修修补补的(Nature is Tinkering)”思想(1977)François Jacob(1965年诺贝尔医学奖得主):在进化中,通常是以加入新单元或增加新功能的方式将原构件作出修改,从而产生更复杂的系统。
4. Addition Chain:历史悠久不易追溯,最著名的介绍是由 Donald Knuth(高德纳,Tex发明者)1997年在他的书中作出的;对于任意整数n,有一个最短的从1开始的整数序列,其后一项等于该序列前面的某两项之和(可用于简化幂计算,也是基于“前面出现过的就不用再计算”的思想),比如31的 addition chain 是1, 2, 3, 6, 12, 24, 30, 31。
5. 逻辑深度(1988)Charles Bennett:跟柯式复杂度很相关,但它指的是,描述该客体的最短程序运行完毕所需要的时间步数,更强调计算复杂度。
柯式复杂度中,对于一个毫无规律(即某种意义上来说随机的)的序列,其柯式复杂度是最高的,因为对随机序列的最短描述也只能是原封不动地将原序列描述出来;组装理论将 Assembly Index 作为“复杂度”的指标,而完全随机序列的Assembly Index 是最高的,所以组装理论也会认为随机序列的复杂度最高。
但直觉上,我们并不会认为最随机的序列是最复杂的,或者说,从演化的意义上来讲,我们不会认为毫无规律的遗传序列是最复杂的,含有最多的“演化信息”。所以,组装理论和柯式复杂度面临着同样的问题(可能不能说是问题,而是特性),即最随机的、最无规律的序列是“复杂度”最高的。
我想这就是为什么牛津大学的 Hector Zenil 教授说组装理论是在重复发明轮子(Reinventing the Wheel)、跟霍夫曼编码(Huffman coding)等工作很像,并不是毫无道理;在跟生命相关的研究中,结构模块化和从基本构件开始的迭代重构这种观念有着悠久传统[1]。但我认为把这种复杂度推广到化学分子、然后在实验上把它与串联质谱法(Tandem Mass Spectrometry)的测量对应起来、用于探测“外星”未知生命,确实是新颖和大胆之处。不过,虽然做法是新颖和大胆的,但其合理性也是值得探讨的(后文会具体谈到),Zenil 教授也专门撰文说 Cronin 教授团队的实验和论断(claim)是不正确和被夸大了的[1]。
[1] Zenil et al. On the Salient Limitations of the Methods of Assembly Theory and their Classification of Molecular Biosignatures, arXiv, https://arxiv.org/abs/2210.00901 , 有4个版本,最新版是2023.4.3
Cronin教授团队将组装理论用于探测未知生命的逻辑和具体做法是:(1)对于已知的分子,首先在理论上计算 Assembly Index,然后用串联质谱法测量该分子,数出质谱上有多少个峰,将 Assembly Index 和峰的个数对应起来;(2)对大量已知分子如此操作之后,就能拟合出一条曲线,即通过串联质谱的峰的个数推测未知分子的 Assembly Index;(3)对含有生命的样品(比如海水、酵母、多肽)和非生命的样品(比如石英、石灰岩、Miller-Urey实验产物)测量后,发现含有生命的样品的串联质谱所推测出的 Assembly Index 一般都高于一个阈值,非生命的样品其 Assembly Index 较低;(4)所以,如果一个未知样本用串联质谱法测量然后所推测出的 Assembly Index 高于某个阈值,则可以判断其是生命或与生命过程有关。
2. 串联质谱中峰的个数是否真的与“生成分子的最少步骤数”存在确定的、鲁棒的关系,并没有给出严格说明;用split-branch给出的结果与串联质谱的拟合,来推测“生成分子的最少步骤数”就显得更加缺乏坚实基础。
Zenil 教授也通过实验指出:用传统的一维 Run Length Encoding(RLE)、霍夫曼编码等方法得出的相关性比 Assembly Index 高[1],所以组装理论用 Assembly Index 来作出判断生命和非生命的论断是很有误导性的。
说完组装理论中“复杂”这一点,再说说“大量”这个观点:偶然出现一个复杂分子并不神奇,神奇的是同时出现很多相同的复杂分子。我认为“大量”这个观点是新颖的(但事实上,只有在2023.3.12最新一版的组装理论的arXiv文章里[2],才提到一个称为“copy number”的量,用于描述某分子的数量,以前的版本对于“大量”都只是定性描述)。通过串联质谱的实测数据来推测是否“大量”复杂分子存在,巧妙地解决了“大量”这个问题(尽管上面所说的那两个疑难点仍然存在),因为质谱仪本来就只能检测到大量分子的信号,少量分子的信号也一般会被噪声淹没。
[2] Sharma et al. Assembly Theory Explains and Quantifies the Emergence of Selection and Evolution, arXiv, https://arxiv.org/abs/2206.02279 , 有3个版本,最新版是2023.3.12,最老版是2022.6.5
2. 梯径理论 vs. 组装理论
2. 梯径理论 vs. 组装理论
在与柯氏复杂度同样的精神(spirit)下(也是组装理论所遵循的spirit),我们提出了梯径(Ladderpath)理论。梯径理论中我们提出一个指标梯径度(Ladderpath-index)来刻画重构客体所用的最少步骤数(这跟柯氏复杂度、组装理论中的Assembly Index、Addition Chain、François Jacob的”Nature is Tinkering”等的精神是类似的)。
但我们认为梯径度并不能够刻画一个客体的“复杂度”,而必须和另一个指标有序度(Order-index)一并来刻画复杂度(有序度是梯径理论中定义的另一个量,定义为客体的规模减去客体的梯径度,具体请参见论文[3]、亦有中文版[4]、和简介[5])。也就是说,我们直觉中的复杂度其实包含了两个方面,一个是梯径度,描述复现目标客体的难度,另一个是有序度,描述客体有多有序,只有当两者同时很大的时候才算复杂度高,这是我们跟组装理论的本质区别之一。
[3] Liu et al. Ladderpath Approach: How Tinkering and Reuse Increase Complexity and Information, Entropy, 2022 https://www.mdpi.com/1099-4300/24/8/1082(最初公开版本是2022.1.19 http://www.chinaxiv.org/abs/202201.00057)
[4] 文献[3]的中文版《梯径:“修修补补”和“重复利用”如何增加复杂度与信息》 https://zh.wuyichen.org/chinese-version-ladderpath
[5] “三刀研学室”关于《梯径理论简介》的公众号文章
虽然上述的诸多关于复杂度的理论都提及最短路径、最少构造等(包括梯径理论、组装理论和Box 1中所提及的),梯径理论的关键点在于重复利用前面已经构造出的组件。所以在梯径理论中,只有重复出现过的组件才会被赋予特殊意义(我们称之为梯元Ladderon,梯元所构成的层级嵌套结构称为“梯图Laddergraph”);而在组装理论中,所有出现过的都是重要部件,所有这些部件共同组成一个“组装空间”。
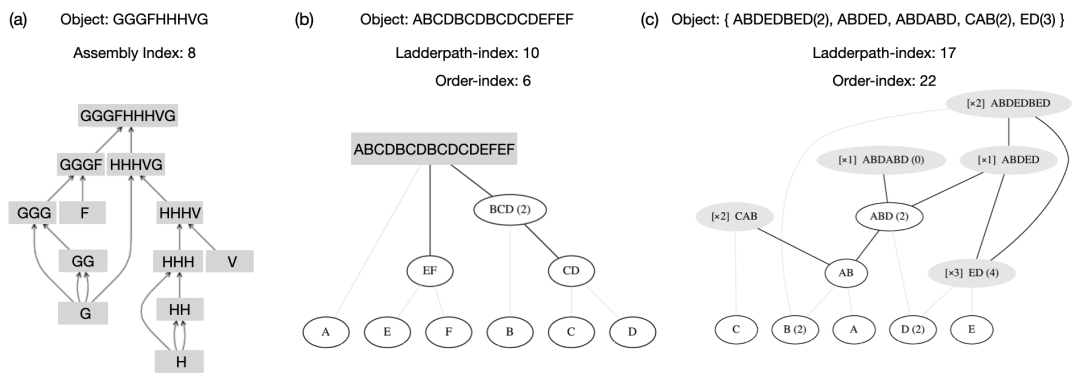
虽然梯径理论中的梯径度和组装理论中的 Assembly Index 在大的spirit上都是在描述生成目标所需的最少步骤,但它们给出的结果并不一样,见图1(更多例子请参见[6])。此外,组装理论只强调一个客体的复杂度,而不讨论一个体系,所以一个体系的 Assembly Index 是没有定义、无法被计算的;梯径理论的着眼点是一个体系的复杂度(单个客体是在体系之下的特例),所以体系的梯径是定义良好的(well-defined)。根据所考虑的问题不同,我们还需要区分孤立体系和联合体系(比如在考虑一个中文句子的意义的时候,我们需要把它放在整个中文语境这个联合体系下考虑),详见文献[3,4]。
[6] “三刀研学室”公众号文章《Ladderpath vs. Assembly》
梯径理论和组装理论的另一个本质的区别是:组装理论认为“选择”(或自然选择)是复杂性增加的原因;而梯径理论认为“复制”是复杂性增加的动力和根本原因,“选择”可以从“复制”中自动涌现出来。事实上,梯径理论的另一直觉和灵感来源就是生命起源研究中的自我复制理论(这也是我们长期以来的一个研究方向),包括提出“The Adjacent Possible”的Kauffman的自催化集合理论、Chemical Organization Theory、Chemoton、超循环理论等。
3. 组装理论的“野心和雄心”(Ambitions)
3. 组装理论的“野心和雄心”(Ambitions)
Cronin 教授团队原文[2]中说:组装理论“提供了一个跨越物理学和生物学的统一框架来描述自然选择”。但 Zenil 教授说:对于组装理论能够很好地刻画生命、甚至地外生命的能力(包括区分生命和非生命的能力),非常具有误导性、或者被严重地夸大了,使得它吸引了很多的不应得(undeserved)的媒体注意,而这对于以前或将来的研究都是不利的[1]。我们也认为声称组装理论是一种统一框架有点夸大其词了,听起来像是完全从0到1的工作,但正如 Zenil 教授所说的,这种“最短路径”逻辑有着相当长的历史,声称“框架至此统一了”并不利于这类理论的后续进一步发展。
事实上,这一大类理论一般可被称为算法信息论(Algorithmic Information Theory),其中一些分支着眼于生命系统和演化,一些着眼于计算理论等等,但大多分支都是一脉相承的,我们可以从以往诸多文献(如[1,3]等)中找到发展脉络。这些理论之间都有相互借鉴,并不完全排他。这类理论的发展似乎正好印证了François Jacob 所说的“自然界(当然也包括人类社会和科技)是修修补补的(Nature is Tinkering)”,就像这些理论描述了它们自身的演化。

刘宇:现任北京师范大学珠海校区-复杂系统国际科学中心特聘副研究员,独立PI。小组目前研究神经网络和基因序列的模块演化、新药分子的设计、以及关于生命起源和信息的理论研究,详见微信公众号“三刀研学室”。
自生成结构读书会
生命是有心(意识)的,但当你一层层剥开生命的组织,却只有心脏而没有一颗“心灵”;打开大脑皮层看到一个个神经元,却看不到“意识”。然而,生命与意识都具有“自我生成“的能力,生命自发从非生命中生成,意识自发从生命中生成。更惊人的是,生命与意识的自我生成结构似乎很相似。如果这个假设成立,那么最可能的备选结构会是什么呢?
为了更深入地认识复杂活系统的自生成结构,集智科学家小木球(仇玮祎)联合周理乾、王东、董达、刘宇、苑明理、傅渥成、章彦博等科学哲学、计算机科学、物理学和生物化学等学科的一线研究者共同发起组织《自生成结构系列读书会》。其中第一季《共识——自生成结构与自复制自动机的研究背景》已经完结,读书会所形成的自生成结构社群集结了相关领域的教授、硕博及产业界人士。现在报名读书会即可解锁第一季读书会所有录播视频并入群,欢迎从事相关研究、对相关领域有浓厚兴趣的探索者报名参与交流。

阅读原文链接:https://pattern.swarma.org/study_group/13?from=wechat
推荐阅读
微信扫一扫,分享到朋友圈











