Nat.Commun.速递:使用大语言模型从科学文本提取结构化信息

关键词:大语言模型,结构信息提取,科学文本


论文题目:Structured information extraction from scientific text with large language models 论文期刊:Nature Communications 论文链接:https://www.nature.com/articles/s41467-024-45563-x
科学知识的海量累积使得研究者难以全面掌握过往的研究成果,尤其是在材料科学领域,相关信息散布在无数的学术论文中,包括文本、表格和图形等形式。此外,尽管机器学习模型在材料发现和设计流程中被越来越多地用作筛选步骤,但这种方法的有效性受到可用训练数据量的限制。近年来,自然语言处理(NLP)算法在材料科学文本结构化方面取得了显著进展,但如何准确提取命名实体之间的复杂关系仍是一个关键挑战。
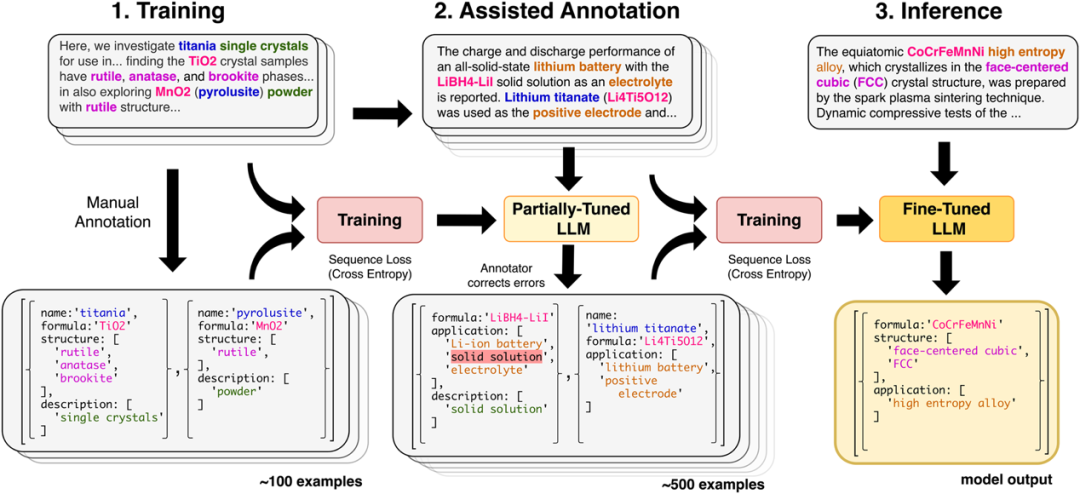
最近美国劳伦斯·伯克利国家实验的团队在Nature Communications发表研究论文,通过精细调整GPT-3和Llama-2等大语言模型(LLMs),开发了一种新方法,用于同时提取科学文本中的命名实体及其关系。这种方法能够灵活处理包括列表多项信息在内的复杂相互关系,无需枚举所有可能的n元组关系或进行初步的命名实体识别。研究团队在三个联合命名实体识别和关系提取(NERRE)的材料信息提取任务上验证了该方法的有效性,展示了其在从科学文本中提取结构化知识方面的强大性能。该研究针对的是材料科学及相关交叉领域。
该研究提供了一种简单的方法来处理科学信息提取的复杂性,使得研究者可以利用大语言模型的强大能力,而无需深入了解其内部工作原理。研究发现,使用人机交互流程可以帮助减少收集完整训练集所需的时间。考虑到当前可用的 API 和接口(例如 GPT-3),该论文的方法是简单且可广泛访问的。随着大模型微调方法的进步和大模型代码库变得更加成熟,我们预计与 LLM-NERRE 兼容的可微调模型将同时变得强大、易于自我托管、可复现,并且处于研究人员的完全控制之下。
复杂系统视角下的科学学读书会

点击“阅读原文”,报名读书会
微信扫一扫,分享到朋友圈











