最近KAN突然爆火,让人们开始意识到大模型的计算效率至关重要,而提高大型模型生成tokens的速度同样至关重要。相对于不断加码GPU,改善Transformer模型架构的计算效率是一种更为长远有效的方法。近期,彩云科技的研究团队对Transformer计算最耗时的核心组件——多头注意力模块(MHA)进行了改进,推出动态组合多头注意力改进Transformer(DCFormer),将Transformer的计算性能提升有2倍之高。该论文已被ICML 2024接收为oral(今年oral的接收率仅为1.5%)。
集智俱乐部邀请论文一作、彩云科技首席科学家肖达老师在「后ChatGPT时代」读书会中深入解读了DCFormer的主要工作,介绍这项工作背后的动机和研究历程,并探讨模型结构研究的未来发展方向,本文是对此次读书会的整理。DCFomer的论文作者均来自彩云科技NLP算法组,核心成员出自集智俱乐部。彩云科技旗下产品包括彩云天气、彩云小梦、彩云小译等,致力于通过人工智能产品让生活更美好。团队目前正在招聘多个算法岗位,期待志同道合的朋友加入!详情见文末。
研究领域:大模型,Transformer架构,动态组合多头注意力
![]()
论文标题:Improving Transformers with Dynamically Composable Multi-Head Attention
论文链接:https://arxiv.org/abs/2405.08553
开源项目地址:https://github.com/Caiyun-AI/DCFormer
在大模型时代,无论是处理文本、图像、语音还是视频任务,大多以Transformer作为基础模型。前段时间一篇非常受欢迎的论文,名为KAN,它之所以受到广泛关注,是因为人们认为KAN可能会对Transformer进行改进,提升模型的效率。我们的工作同样旨在改进Transformer。(参看《KAN一作刘子鸣直播总结:KAN的能力边界和待解决的问题》)
我把Transformer引领的新一代模型范式比作搭积木的游戏,并将其分为三个派别:大力飞砖派、系统交互派和结构创新派。
首先是“大力飞砖派”,也就是我们常说的“大力出奇迹”的 Scaling Law。如果我们把Transformer block看作积木块,那么使用更多的积木块和数据就能得到更好的效果。这种方法的最大优势在于确定性强,因此我们称之为“靠谱青年”。
另一派——“系统交互派”认为,不应将模型视为孤立的点,而应将其置于系统中,让其进行更丰富的交互,例如通过强化学习训练,或提供思维链提示等。这种思路更接近人类的学习方式,因此我们称之为“文艺青年”。
第三个派别——“结构创新派”则更为直接,他们认为,既然前两派都把Transformer的积木块当作黑盒来使用,为什么不拆开看看里面究竟是什么呢?他们主张深入研究Transformer的工作原理,探讨如何改进甚至替换它。这一派的做法确实引发了一些质疑。
许多人会问:“真的有必要改进Transformer吗?这个结构不是已经足够好了吗?”这些疑问并非无的放矢,因为Transformer已经诞生七年了,无数实践似乎已经证明它的强大和通用性。并且有论文显示对Transformer的改进大多并不像原始Transformer那样普适有效和可扩展。
正是在这样的背景下,我们决定进行这项看似有些中二的工作——改进Transformer的结构。我们设计了一种名为动态组合多头注意力(DCMHA)的新架构,用以替换Transformer中的多头注意力(MHA)机制,从而得到一个具有更高计算效率的模型。这意味着在达到相同效果的情况下,我们可以节省1.7到2倍的算力,或者在使用相同算力的情况下获得更好的效果。简而言之,这个新模型让我们能够以更少的算力训练出更优秀的模型。
本次分享围绕三个方面展开:第一部分是改进的动机,即我们是如何产生这个改进想法的;第二部分是DCFormer本身的设计和实现细节;第三部分是对DCFormer研究历程的回顾,包括我们的经验教训和对未来的展望,探讨结构改进和创新的可能方向。
Transformer 组件:MHA 和 MLP
-
多头注意力(MHA):核心组件,跨token信息流动
我们都知道Transformer由两大模块组成,一块叫做多头注意力(MHA),另一块叫做全连接层(MLP)。前一段比较很火的KAN架构本质上是一项关于MLP的工作,而DCFormer则更加关注多头注意力模块(MHA)。我们认为,多头注意力的重要性在于:Transformers中跨token的信息流动都是在注意力模块中完成的,而MLP模块中则没有这种信息流动。因此,很显然,所有关于上下文的信息的整合处理以及算法的实现都要依靠Attention注意力。
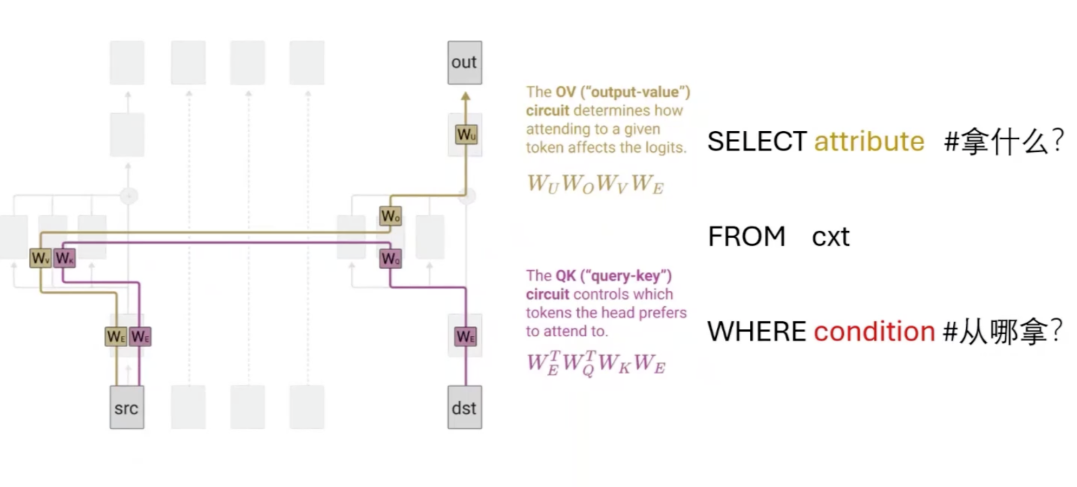
我们的第一步工作是研究注意力模块里每个注意力头是如何工作的。在这里,我们需要引入一个回路(Transformer circuits)的概念。每个注意力头有四个权重矩阵:Wq、Wk、Wo、Wv,当它们两两进行配对时,便会形成了两个信息回路——QK和OV。QK回路决定了从当前位置关注上下文中的哪些位置(如下图紫色部分所示)。OV回路决定了从关注到的位置取回什么信息/属性写入当前位置的残差流,进而预测下一个token(如下图黄色部分所示)。
Transformer circuits [by Anthropic]
Nelson Elhage, et al. A Mathematical Framework for Transformer Circuits. https://transformer-circuits.pub/2021/framework/index.html
• QK/查找回路:决定从当前位置关注上下文中的哪些位置
• OV/变换回路:决定从关注到的位置取回什么信息/属性写入当前位置的残差流,进而预测下一个token
图中展示了一个经典案例——我们可以称之为“归纳头”(induction head)。对于致力于模型可解释性的研究者来说,理解这种模型通过内部回路完成任务的概念至关重要。
现在,让我们通过一些具体的例子来探讨这种组合方式是如何工作的,以及它可能面临的问题。以中文句子“小明有个钢笔 … 小明有个 -> 钢笔”为例,模型会使用一个类似induction head的机制来确定如何从前面的内容中提取信息。模型会识别到“小明”作为主语,并与宾语“钢笔”有关联。通过识别前文相同的主语,模型用一个QK回路能够找到相关的信息——这里是“钢笔”,并用一个OV回路直接复制了“钢笔”这个信息到残差流用于输出预测。
接下来,我们再看两个例子:“苹果是一种 -> 水果。模型使用QK来关注前面的词汇“苹果”,并通过OV回路,来提取“苹果”的类别信息,即“水果”。
另一个例子是:“钢笔用来 -> 写字。”这里,模型使用QK来识别“钢笔”,并通过OV来提取关于“钢笔”的用途信息,即它是用来写字的。这样,模型就能够利用这些信息来进行更准确的预测。
我们注意到,QK回路的查找(从哪拿)和OV回路取属性(拿什么)本来是独立的两件事,理应可以分别指定并按需自由组合,MHA硬把它们放到一个注意力头的QKOV里“捆绑销售”,限制了灵活性和表达能力。假设有个模型存在注意力头A、B、C其QK和OV回路能够完成上面的例子,那换成“小明有一支钢笔…小明有一种 -> 文具”(head A 关注相同主语的宾语的QK + head B 取类别属性的OV)或“小红有一支钢笔…小红能用它 -> 写字”(head A 关注相同主语的宾语的 QK + head C 取用途属性的OV),需要交叉组合现有注意力头的QK和OV回路,模型就可能“转不过弯儿”了。这就像是在肯德基点餐,如果只有固定的套餐组合,而顾客想要的组合并不在菜单上,那就无法满足需求。
实际上,即使是这样简单的例子,模型的表现也并不总是令人满意,尤其是对于较小的模型,比如6B以下的模型,它们的表现会出乎意料地差。这促使我们去深入分析原因,并寻求改进的方法。
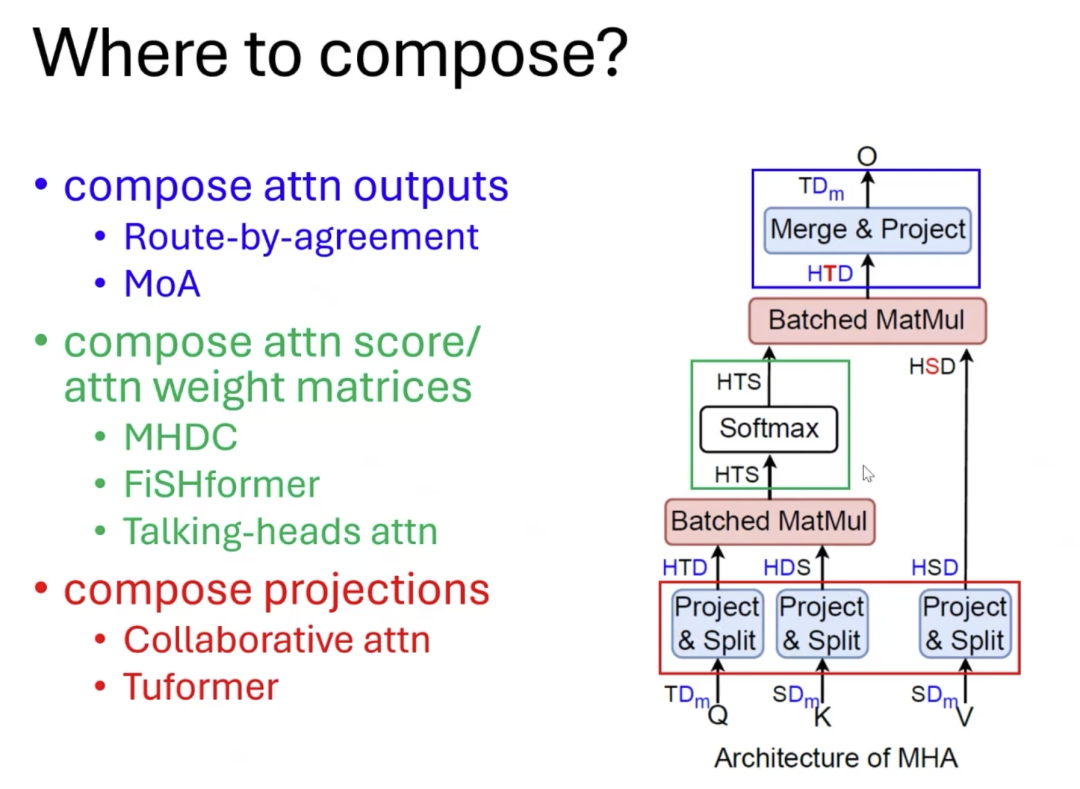
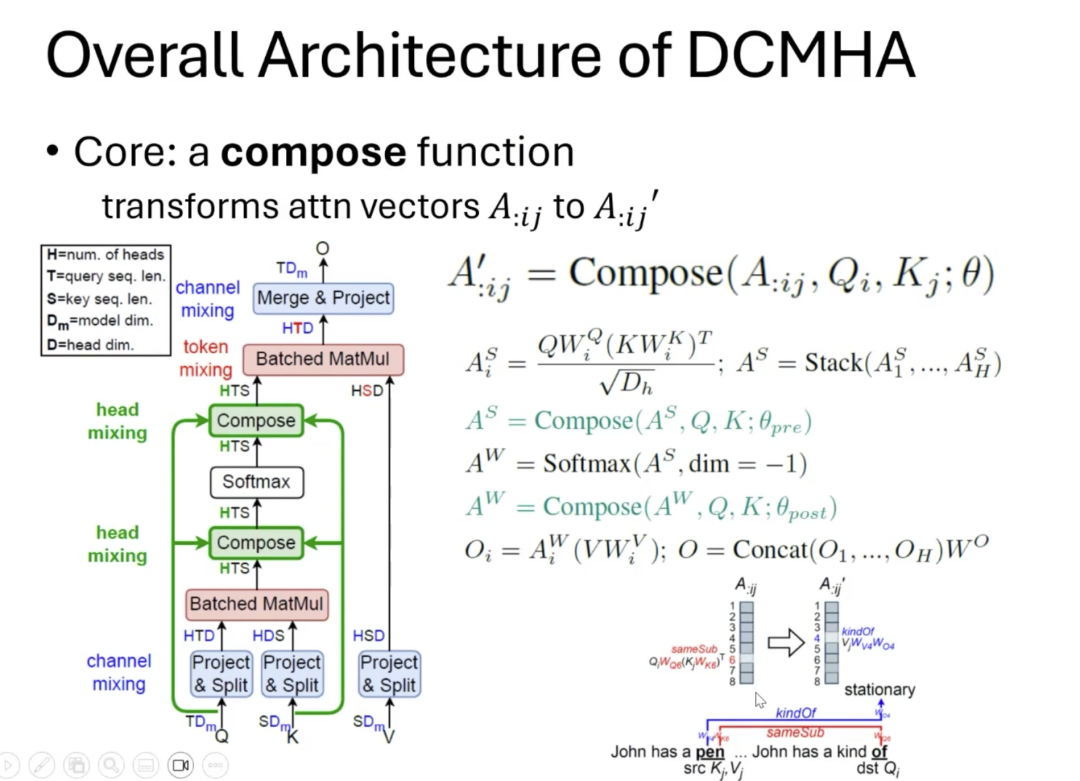
那么,我们应该如何将QK和OV进行动态组合呢?我们可以在多头注意力的几个计算步骤中进行组合。比如,将Wq、Wk、Wo、Wv等权重组合,或对输出进行组合。而我们在DCFomer中采用的其实是将它生成的注意力分数和注意力权重矩阵做组合。
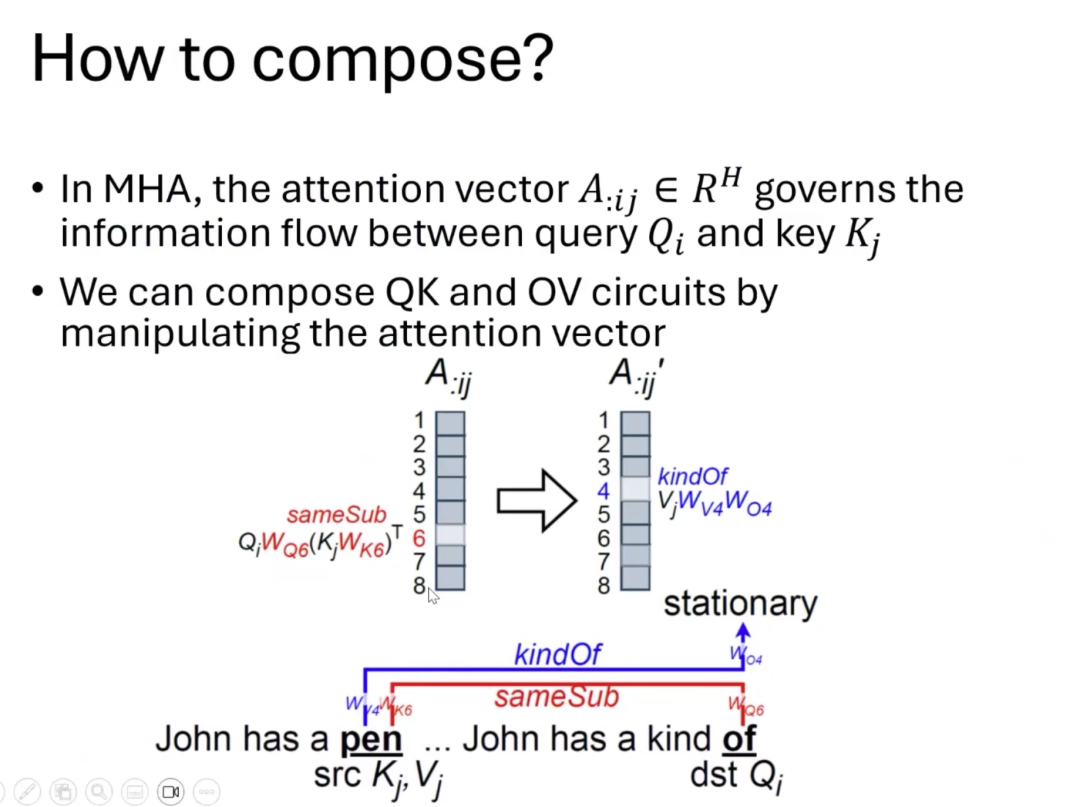
接下来,我们通过之前的例子来说明在注意力机制的层面上,组合不同头(Head)的信息优势。假设我们有一句话,其中每一对注意力的起始词和终点词(例如“pen”和“of”)都可以计算出一组注意力分数,它们是通过权重矩阵Wq和Wk相乘得到的。假设有八个头(H=8),那么就有八组Wq和Wk的组合。这些组合计算出的8个注意力分数被称为注意力向量,它们决定了从“pen”到“of”应该传递哪些信息。例如,假设第六个头(Head 6)的QK回路特别关注了“pen”,在正常情况下,第六个头的数值会较大,模型就会倾向于使用第六个头的OV回路来传递信息。
但如果第六个头的OV并不获取我们需要的属性信息,比如“kindOf”(类别),那么我们就不能简单地使用它。为了解决这个问题,我们可以调整这些注意力分数,假设第四个头(Head 4)的OV包含所需的“kindOf”信息。我们可以通过将Head 6的注意力分数增加给Head 4,让它在计算中起到更大的作用,从而实现在Head 6的QK搭起的通路上传递Head 4的OV获取的属性信息。
通过这样“偷梁换柱”,我们就实现了不同头之间的信息组合,让模型能够更灵活地处理信息。通过这种方式,我们可以操作注意力向量,使模型能够更准确地捕捉和传递关键信息。
那么,如何将一个注意力向量A:ij转换成我们想要的另一个向量A:ij‘呢?一种简单的方法是通过矩阵乘法。当我们将一个向量与一个特定的矩阵相乘时,它就可以转换成另一个向量。这个矩阵的性质决定了转换的具体方式。
例如,如果矩阵设计成特定的形式,它就可以实现特定的变换,比如将原本属于第四个头的信息移动到第六个头,或者反之。此外,矩阵还可以调整各个头的权重,比如增强或减弱某个头的影响力。比如,如果我们想要减弱第46个位置的权重,我们可以在矩阵的对角线上相应位置设置较小的值,这样在乘法操作后,该位置的权重就会降低。
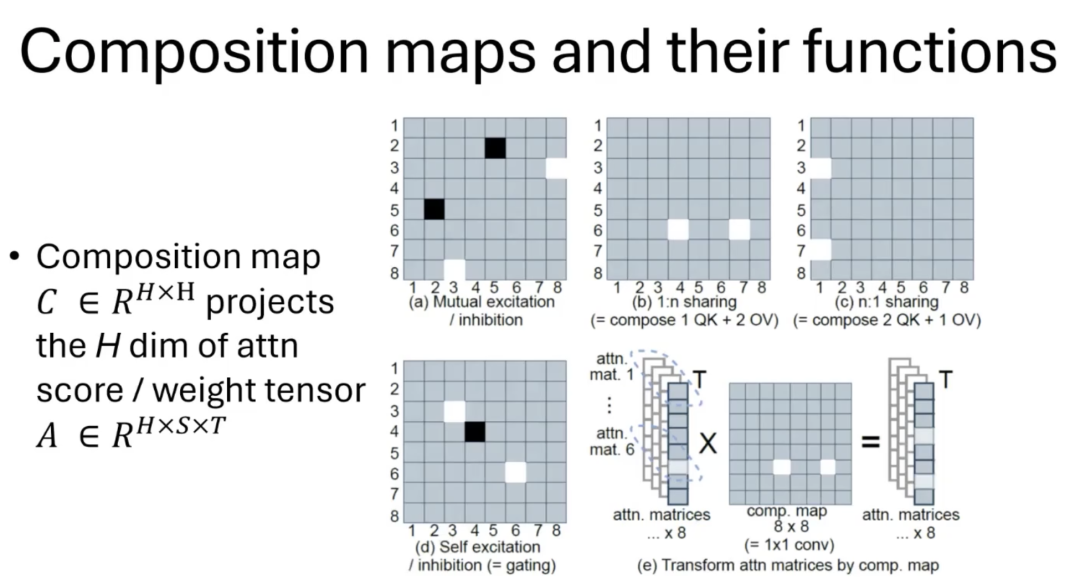
我们将这些用于调整和组合的矩阵称为“Composition Map”(组合映射)。这些映射不是针对单个注意力起点-终点对,而是全局性的。
如果这些组合映射对于所有起点-终点对都是相同的,我们称之为“静态”的组合映射,其效果等同于扩展了头的QK(Query-Key)和OV(Output Value)的维度,比如如果有8个头,就可以将每个头的维度扩展到原来的8倍,从而增强模型的表达能力。
在DCMHA中,我们引入了一个“compose”的关键操作,是将一个注意力向量转换成另一个不同的注意力向量,从而实现更灵活的注意力分配。
具体来说,compose操作会接收一个原始的注意力向量,并输出一个新的、经过转换的注意力向量。在多头注意力机制中,我们会在两个关键的位置插入compose操作:一个在softmax归一化步骤之前,另一个在softmax之后。通过这种方式,DCMHA能够动态地调整每个头的贡献,创造出更加精确和有效的注意力模式。提高了模型的表达能力,而且增强了其对复杂数据关系的捕捉能力,从而在各种任务中都能取得更好的性能。
Noam Shazeer等人的Talking-heads attention工作提出过类似的注意力头组合思想(其本质是上文的静态组合映射),与他们的工作不同,我们的工作则更加关注动态组合的概念。所谓动态,意味着根据不同的输入,在每个位置生成不同的composition map,使模型能够动态调整不同头之间的组合方式。例如,给定前文“小明有只钢笔”,对“小明有一种 -> 文具”,模型需要将找相同主语的QK与取属性的OV组合,而对“小明拿它 -> 写字”,则需要与取用途的OV组合。
Shazeer, Noam, et al. Talking-heads attention. arXiv preprint arXiv:2003.02436 (2020).
动态组合的优势在于它能够更灵活地适应不同的语言模式,但这也带来了计算上的挑战。因为模型需要为每个token生成一个动态的组合映射,这在计算上可能会非常昂贵。特别是当模型规模较大时,需要处理的参数和计算量会显著增加。
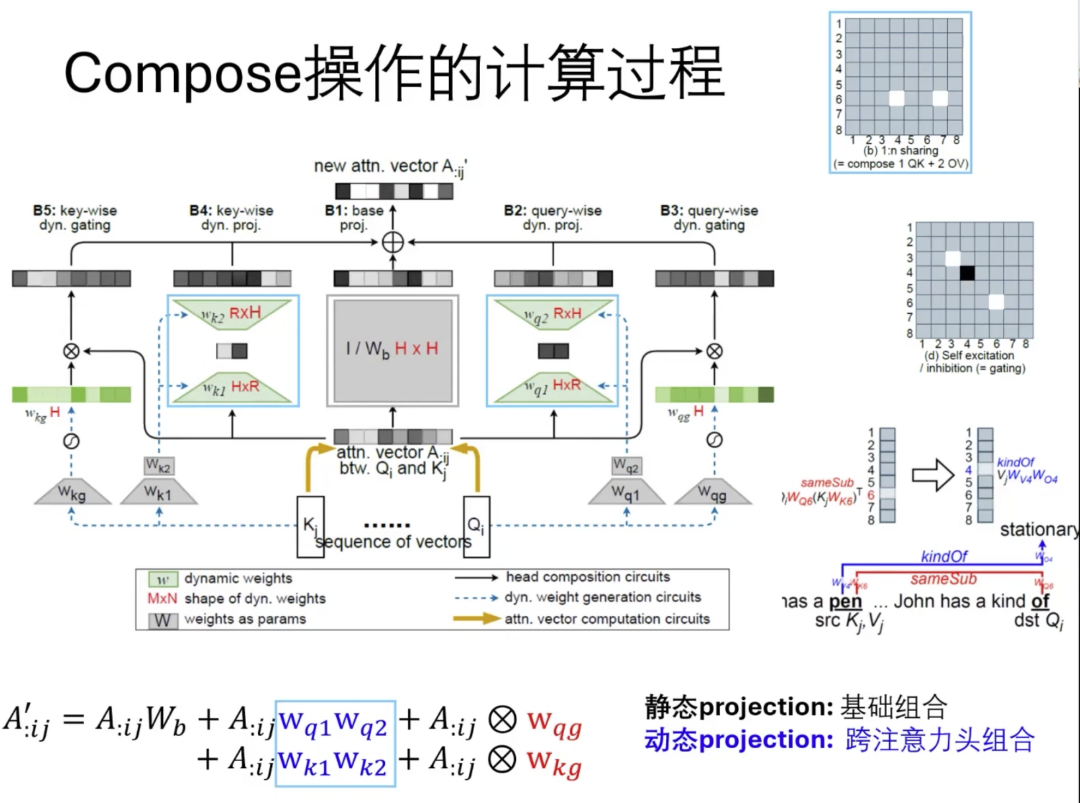
为了解决这个问题,我们在DCMHA中采用composition map分解的方法。这种方法将compose操作分解为几个步骤,每个步骤都有其特定的作用。例如,我们可以通过低秩分解来限制组合的复杂性,从而减少计算开销。低秩意味着每个特定位置需要的组合数量是有限的,这样可以有效地控制计算资源的使用。此外,我们还引入了门控机制,它通过调整composition map对角线上的值来增强或减弱特定头的影响。这种方法允许模型在不同情况下灵活调整每个头的贡献。
最终,通过将这些不同步骤的结果结合起来,我们可以得到一个综合的输出。如果我们从整体张量的角度来理解这个过程,实际上是对组合张量进行了行列分解和低秩对角分解,这些技术在其他领域也有应用,但我们将其创新性地应用于组合映射上。
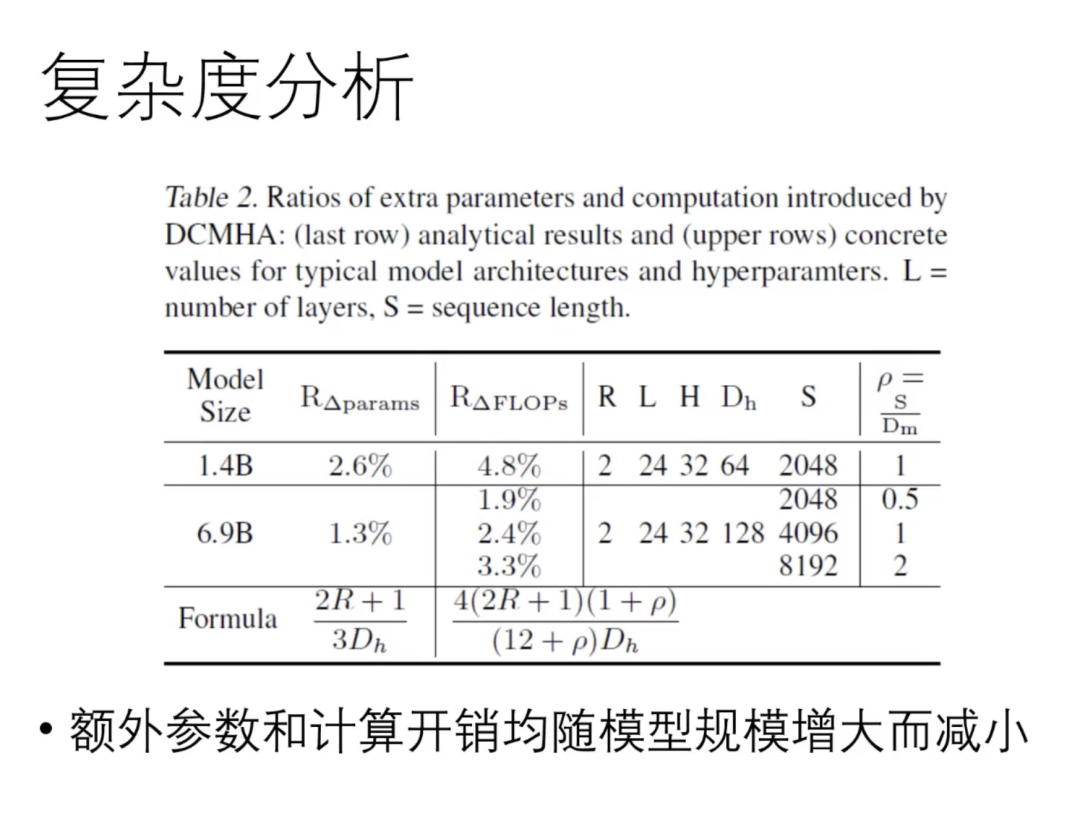
这种方法引入了一些额外的参数,但其计算复杂度相对较小。增加的计算量(flops)也不多,并且随着模型规模的增大,这种复杂度相对减少,即模型越大,增加的计算复杂度越少。
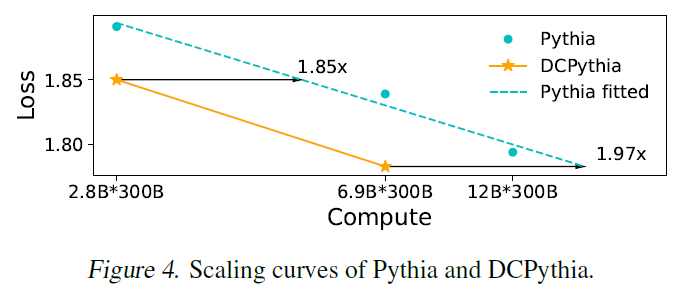
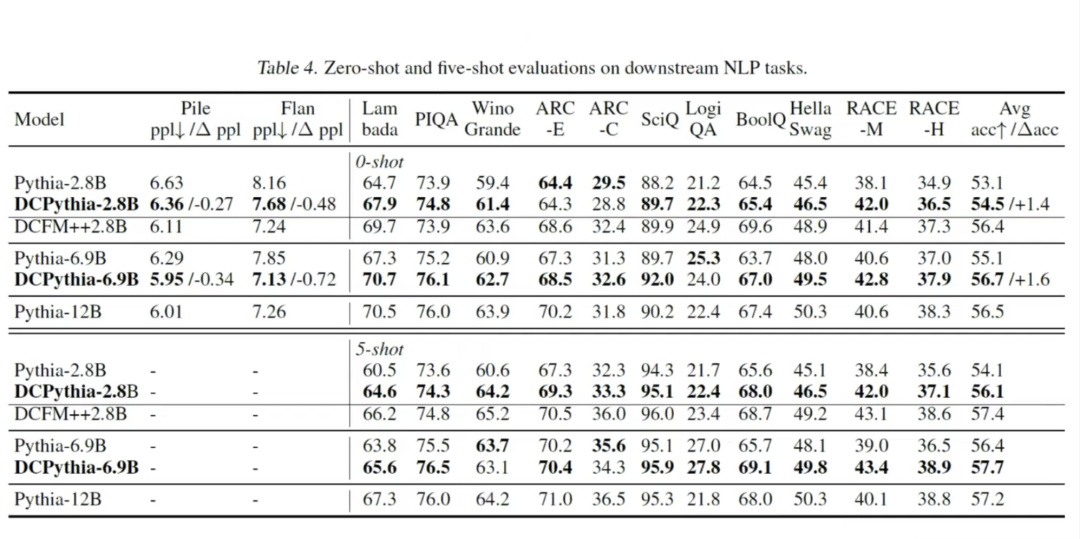
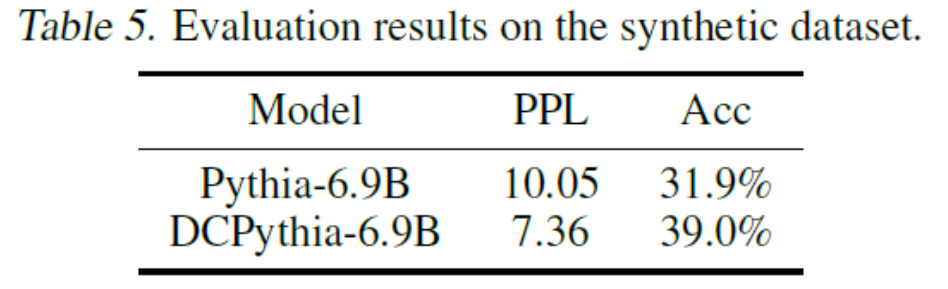
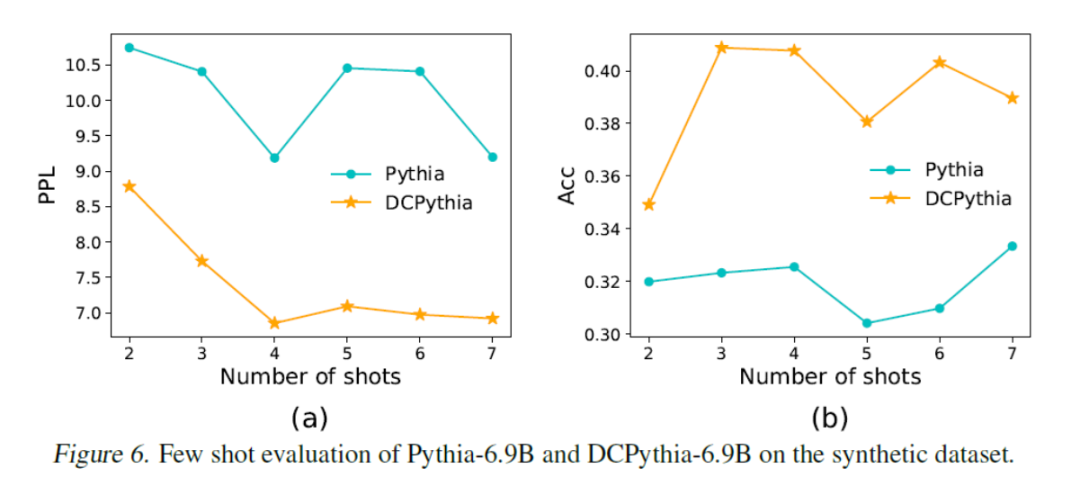
接下来,让我们看看主要的测试结果——性能算力比。性能算力比衡量的是单位算力投入能带来多少性能提升。实验结果显示,在相同的训练数据(300B tokens)下,一个改进后的69亿参数模型,其效果甚至超过了120亿参数的模型。例如,如果GPT-4o能够应用这项技术,推理一次128k上文的成本就可能从4元降低到2元。此外,在下游任务的评估中,随着模型规模的增大,我们的改进效果更加显著,如6.9B参数模型与2.8B参数模型的比较。在保持超参数和训练数据一致的情况下,无论是损失值(Loss)还是语言模型的困惑度(PPL),DCPythia-6.9B的表现都优于Pythia-6.5B和Pythia-12B。
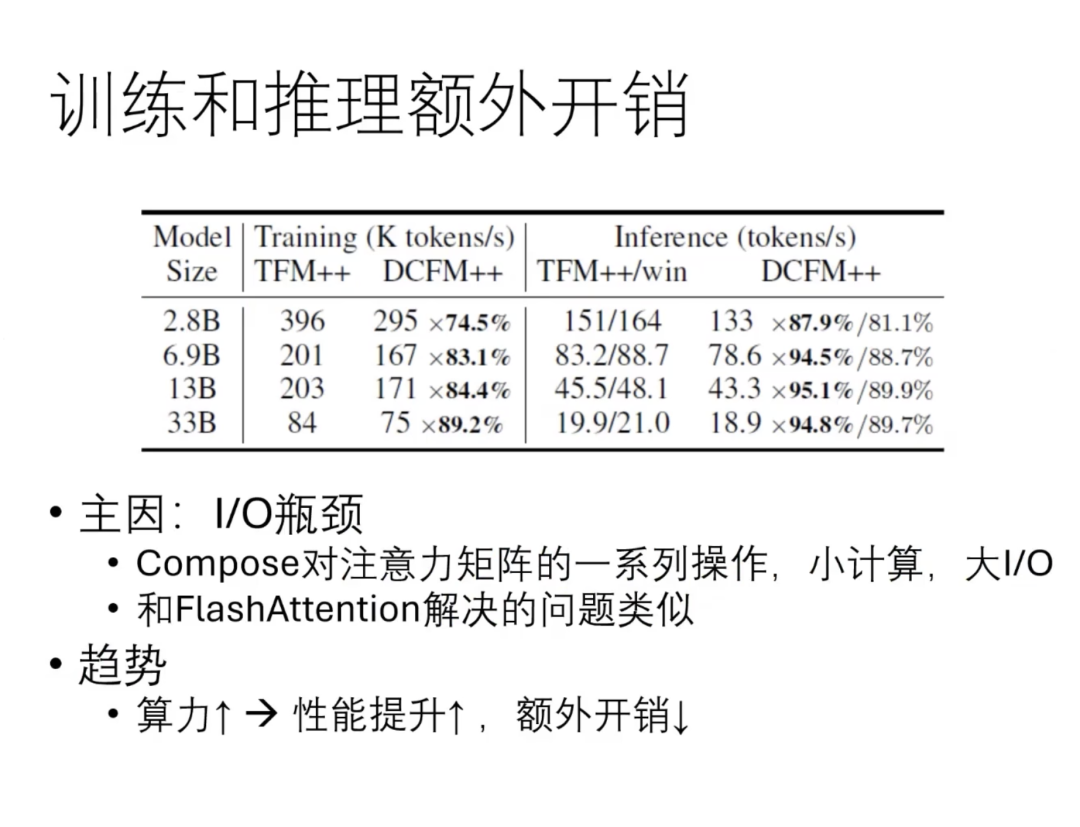
尽管理论上的复杂度很小,但实际训练中我们确实发现了一些额外开销。这主要是因为compose操作对注意力矩阵进行了一系列的变换,虽然每个变换的计算量不大,但由于Attention矩阵本身很大,导致了较大的I/O需求。针对这个问题,我们在实践层面进行了一些优化。优化结果显示,无论是在训练还是推理中,相比于Transformer模型,这种额外开销是可以接受的。例如,在13B或6.9B模型上,尽管推理速度慢了5.5%,但性能却超过了13B模型。如果与13B模型相比,实际上速度是变快的。
从这个角度来看,随着算力的提升,模型规模的增大带来了更大的收益,额外开销实际上随着算力的增加而降低。
此外,我们还进行了消融实验,以评估DCMHA中五个分支的重要性。实验结果表明,动态组合比静态组合更重要,尤其是跨头的组合,比单个头的自增强或自抑制(即门控)更为关键,这符合我们的直觉;关注侧的信息(query-wise)比被关注侧的信息(key-wise)更重要。即使只使用一侧的信息,也能达到很好的效果。基于这些观察,我们可以进一步采用一些方法,比如使用更多的局部注意力层,只用关注侧的信息(QW),这不仅能保持类似的效果,还能进一步提高速度。
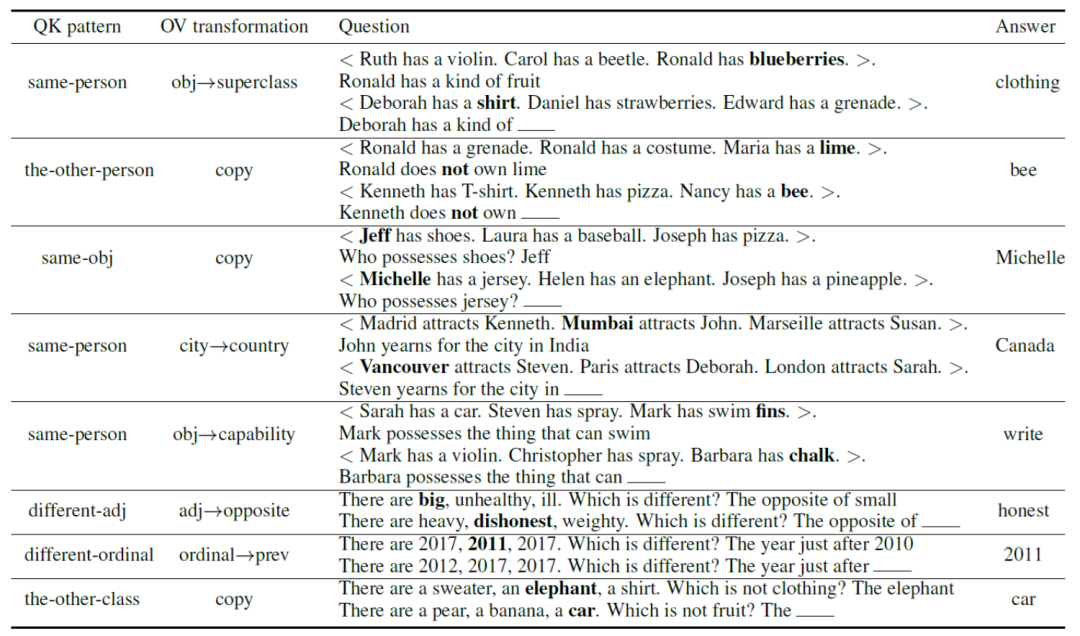
我们还进行了另一项实验,测试了DCFormer是否能够解决需要注意力头组合的任务。我们构建了一个测试集,包含了各种类似于“小明有支钢笔”这样的测试用例,并进行了不同的QK和OV变换。结果表明,在6.9B参数的模型上,DCFormer在这种需要头组合的任务上的表现确实显著优于普通模型。
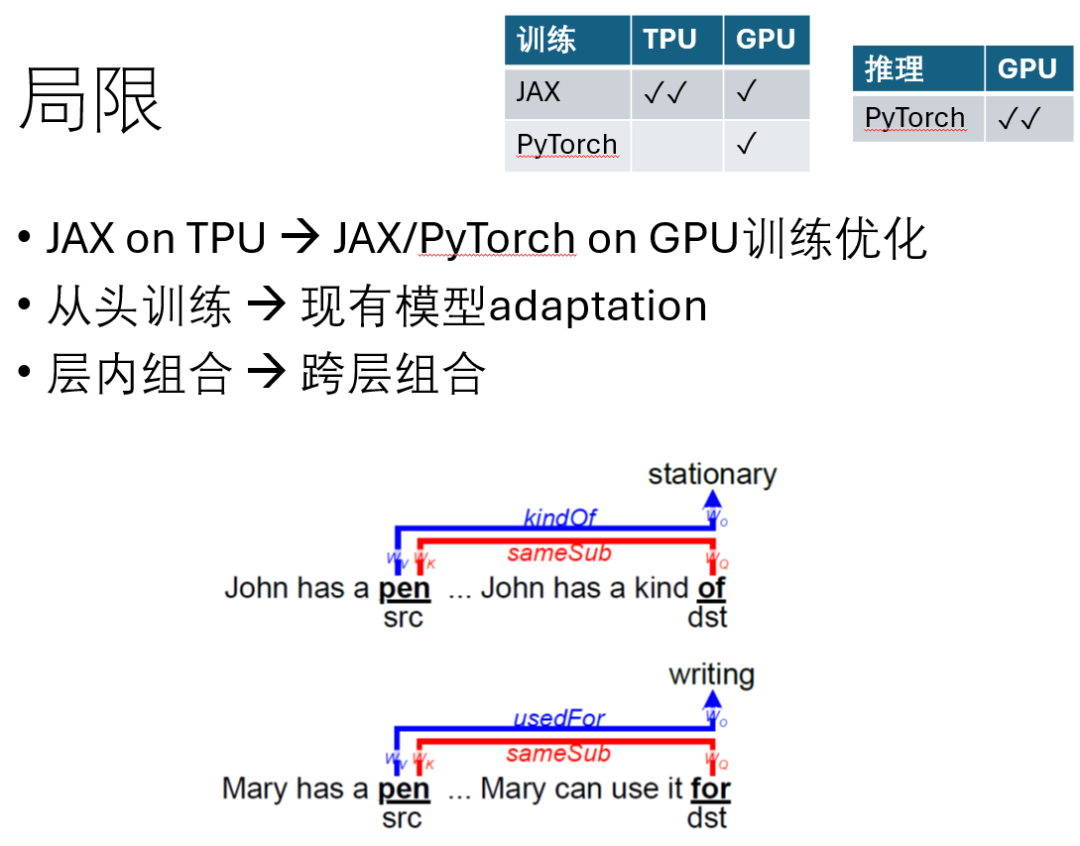
接下来,我想谈谈我们工作中存在的一些局限性。首先,关于实现方面,我们的模型主要是使用JAX在TPU上进行训练的。虽然我们也提供了在GPU上使用JAX和PyTorch进行训练的代码,但我们必须承认,这部分代码并没有经过深入优化,因此在GPU上的性能可能会差于TPU上的性能,而推理部分是在GPU上使用PyTorch来执行。
其次,关于现有模型的适配问题。我们希望能够将DCFormer技术应用到现有的模型上,而不是从头开始训练一个新模型,因为从头训练的开销是相当大的。我们尝试过将现有的模型,比如Llama2或Llama3,直接应用DCFomer技术,并通过一些微调来提升性能。但实验结果表明,这种简单的直接应用是不够的。原因在于,我们的DCFormer依赖于不同头之间的组合,而现有的模型在训练时并没有考虑到这种组合关系。例如,一个头的QK(Query-Key)需要与另一个头的OV(Output Value)进行组合,这种组合的前提是它们必须在同一层中。但是,在现有的Llama模型中,需要组合的QK和OV不一定位于同一层,这就导致了无法有效实现组合。这不仅是一个技术挑战,而且在分布式训练环境中,跨层组合的实现难度和开销都是相当大的。因此,目前我们的一个局限性在于,虽然跨层组合在技术上是可行的,但要实现它并达到良好的性能,还存在一定的难度和成本。
研究历程回顾
关于这篇论文的工作,以上介绍的就是我们研究的主要内容。现在,我想简单地回顾一下我们进行这项研究的初衷。我们最初的出发点是提高模型的可解释性。具体来说,我们设计了一系列任务,并开发了自己的分析方法和工具来探究模型的工作机制:模型是如何执行任务的,以及它为何能或不能完成这些任务。我们的尝试相当于将模型逆向工程从“黑盒”变为“灰盒”,使我们能够对其进行调试并寻找改进方案。
费曼说:“如果你不能创造一样东西,你就不能真正理解它”;我觉得反过来:如果你不能理解一样东西,你也无法改进或创新它。然而,这并非唯一的途径。许多杰出的研究人员,比如之前提到的Noam Shazeer,他们的论文往往不会详细解释设计结构的动机,我们也无法确切知道他们的灵感来源。可能在更高层次的逻辑中,存在着其他的思路和方法,比如直觉的引导。当实践经验和视野积累到一定程度时,直觉可能会自然而然地引领你走向正确的道路。
然而,在实际研究过程中,我们最深的体会是迭代速度的重要性。即使你的想法在理论上是可行的,但在实践中往往需要不断地调整和实验,快速地完成闭环。我们总共进行了500多次大大小小的实验,才验证了我们方法的有效性。这意味着,如果你能加快迭代速度,将原本一年内完成的实验压缩到半年,那么你就有可能在半年内取得显著的成果。
此外,面向底层硬件的优化也是至关重要的。在模型优化的后期,我们发现性能提升的瓶颈往往不在于PyTorch或JAX等框架层面,而在于TPU、GPU等底层硬件。最终,我们可能需要编写CUDA Kernel等底层代码,这似乎是不可避免的。最近许多架构创新的工作,如Flash Attention、Mamba、GLA等,它们的实现都依赖于定制化的Kernel,否则模型效率将受到影响。因此,我曾跟团队半开玩笑说,当前架构创新的尽头是CUDA编程。如果你的想法仅限于PyTorch、JAX层面,那么你的发挥空间可能受到限制。而如果你掌握了CUDA、Pallas等底层技术,你将有更多的空间去做出更出色的工作。
2B青年的未来方向
接下来,让我们探讨一下底层结构创新的可能性和未来方向,我将分享一些个人看法。
我坚信底层结构的创新不仅可行,而且是一个充满潜力的领域。自从Mamba模型出现后,它激发了一系列令人兴奋的研究工作,这一领域也逐渐受到更广泛的关注。在过去,许多人认为Transformer架构已经达到了底层结构的极限,无需进一步改进。然而,Mamba、DCFormer等工作的出现打破了这一刻板印象,为我们打开了新的探索空间。
特别值得一提的是,我们对混合架构非常感兴趣,尤其是将Attention机制与RNN或状态空间模型(SSM)结合起来。这两种架构具有不同的内在偏好(Inductive Bias),它们的结合能够形成强大的混合模型。例如,简单地将一层Attention与一层RNN结合,就能显著提升模型的性能。无论是已发表的研究还是我们的实验,都证实了这种混合方法的有效性。此外,这种方法与人脑的工作方式更为贴近。人脑在维持当前状态的同时,能够通过远程Attention机制进行记忆检索,而混合架构正是这种能力的体现。
此外,信息流动性也是我们关注的焦点。无论是Mamba还是DCFormer,它们都通过输入相关的方式增强了模型内部的信息流动。尽管Transformer模型本身也能动态形成信息流通路径,但我们认为这些路径的动态性还有待提高。因此,探索如何以更高效的方式促进信息流动通路的动态形成,是一个充满希望的研究方向。
肖达,北京邮电大学讲师,彩云科技首席科学家,集智俱乐部核心成员。长期从事深度学习、大模型的算法研究及其在天气预报、机器翻译、机器辅助创作、系统和代码安全等领域的应用研究,相关工作发表在 ICLR、ICML、TDSC等顶级会议和期刊。目前研究兴趣包括大模型机制可解释性、高效模型架构设计。
DCFomer的论文作者均来自彩云NLP算法组,核心成员出自集智俱乐部。团队继承了集智俱乐部自由讨论和乐于奉献的精神,鼓励开放、真诚、平等的沟通,秉承着精益求精的精神,致力于“让田间地头的农民大哥”和“字宙里的航天员”一样,都能通过人工智能产品让生活更美好。
我们正在招聘多个算法岗位,期待优秀的你加入我们团队!
-
参与⼤模型对齐方向的研发,涉及数据构造,SFT及RL训练等。持续提升自研基座模型在业务场景下的能力
-
持续跟进业界最新的大模型对齐算法,参与大模型对齐算法的设计、训练、调优工作
-
构造测评集,设计实现测评方法和测评系统,对自研模型和竞品模型的能力进行系统性测评
-
探索可扩展监督、对抗性测试、自动化红队测试、机制可解释性等相关前沿对齐技术
-
985/211高校硕士及以上学历或优秀本科生,计算机、自动化、人工智能、机器学习、数学或统计学等相关专业,两年及以上NLP相关经验
-
对Transformers模型、LLM预训练/微调、RLHF/RLAIF等基本原理有深入理解和通过实践掌握的实现细节
-
熟练使用PyTorch、Huggingface transformers等深度学习和大模型框架
-
-
-
面向NLP文本生成等任务的LLM推理性能和显存优化
-
-
基于CUDA或Triton的神经网络定制算子开发和算子融合,支持对新模型结构的优化
-
-
具备LLM模型的推理加速和优化的一年以上经验,熟悉算子融合、量化、剪枝等常见优化技术
-
熟悉Transformer及各种变种,熟悉PyTorch、Deepspeed、JAX等常见深度学习框架及其内部的优化机制
-
熟悉常见的LLM推理加速框架和方法,如FasterTransformer、FlashAttention等并能够根据业务需求进行定制优化
-
熟悉CUDA或Triton编程,熟悉各种性能诊断和profiling工具和方法
-
具备较强的团队合作和沟通能力,能够与团队成员、业务部门紧密协作
-
深入调研、追踪或复现高效模型结构、机制可解释性等领域的前沿进展
-
对现有模型结构进行基础性改进和创新,设计更高效的模型结构,结合优化算法、数据混合策略等维度的改进、大幅度提高基础模型预训练的效率
-
研发机制可解释性的benchmark和分析工具,进行Transformer circuits(逆向工程/白盒化)的研究
-
-
-
985/211高校硕士及以上学历或优秀本科生,计算机、自动化、人工智能、机器学习、数学或统计学等相关专业,两年及以上大模型相关经验
-
对Transformers模型的基本原理和工作机制有深入理解
-
熟练使用PyTorch、Huggingface transformers等深度学习和大模型框架
-
-
具体招聘岗位详情请见链接:http://colorfulclouds.com/jobs/
请通过集智俱乐部投递简历(可以直接推荐跟负责人面试):wangting@swarma.org
2022年11月30日,一个现象级应用程序诞生于互联网,这就是OpenAI开发的ChatGPT。从问答到写程序,从提取摘要到论文写作,ChatGPT展现出了多样化的通用智能。于是,微软、谷歌、百度、阿里、讯飞,互联网大佬们纷纷摩拳擦掌准备入场……但是,请先冷静一下…… 现在 all in 大语言模型是否真的合适?要知道,ChatGPT的背后其实就是深度学习+大数据+大模型,而这些要素早在5年前的AlphaGo时期就已经开始火热了。5年前没有抓住机遇,现在又凭什么可以搭上大语言模型这趟列车呢?
集智俱乐部特别组织“后 ChatGPT”读书会,由北师大教授、集智俱乐部创始人张江老师联合肖达、李嫣然、崔鹏、侯月源、钟翰廷、卢燚等多位老师共同发起,旨在系统性地梳理ChatGPT技术,并发现其弱点与短板。读书会已完结,现在报名可加入社群并解锁回放视频权限。
![]()
点击“阅读原文”,报名读书会