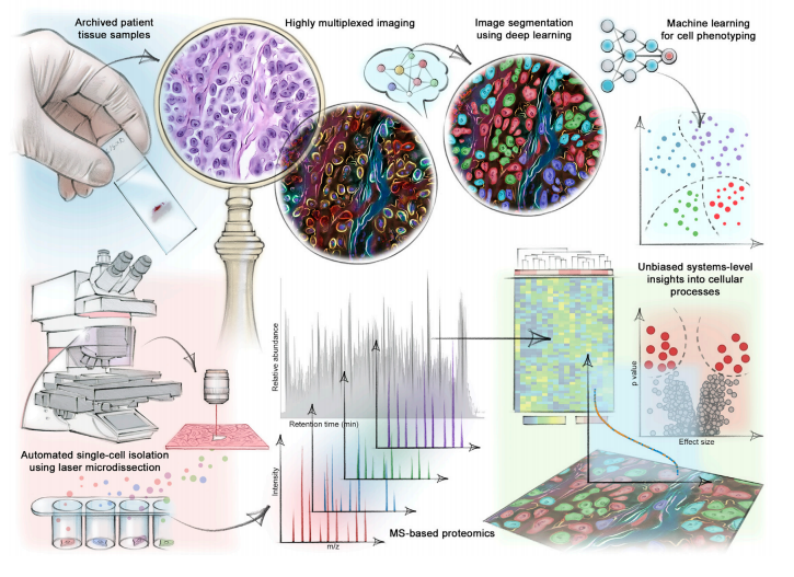
来自哈佛大学的Marinka Zitnik教授团队开发了一种考虑生物背景信息的单细胞蛋白质计算模型——PINNACLE,为每个蛋白质生成细胞类型特异的低维表示,进而完成诸如发现靶点、分析特定细胞类型的药物反应等下游任务。
关键词:单细胞蛋白质, 生物背景信息, 几何深度学习, 表示学习
![]()
论文题目:Contextual AI models for single-cell protein biology
论文链接:https://doi.org/10.1038/s41592-024-02341-3
蛋白质是生命过程的执行者。在漫长的研究过程中,人们对蛋白质从结构到功能都有了全方位的了解。近年来,随着AlphaFold等工具的兴起,科学家们开始使用人工智能模型对蛋白质进行研究。具体而言,计算生物学者广泛使用表征学习(Representation Learning)的手段对蛋白质进行建模,并完成诸如结构预测、靶点发现、亲和力预测等下游任务。然而,已有的人工智能模型通常为每个蛋白质都生成统一的表示。随着精准医学的发展,越来越多的研究开始关注生物组织细胞之间的异质性,挖掘蛋白质在不同的生物环境和细胞状态下所发挥的多样作用。
表征学习是一种机器学习技术,指从原始的输入数据(这里为蛋白质)中提取显著特征,并使用提取出来的特征,一般为一串向量,对蛋白质进行表示,进而输入后续人工智能模型中完成下游任务(如分类、预测、回归等)。
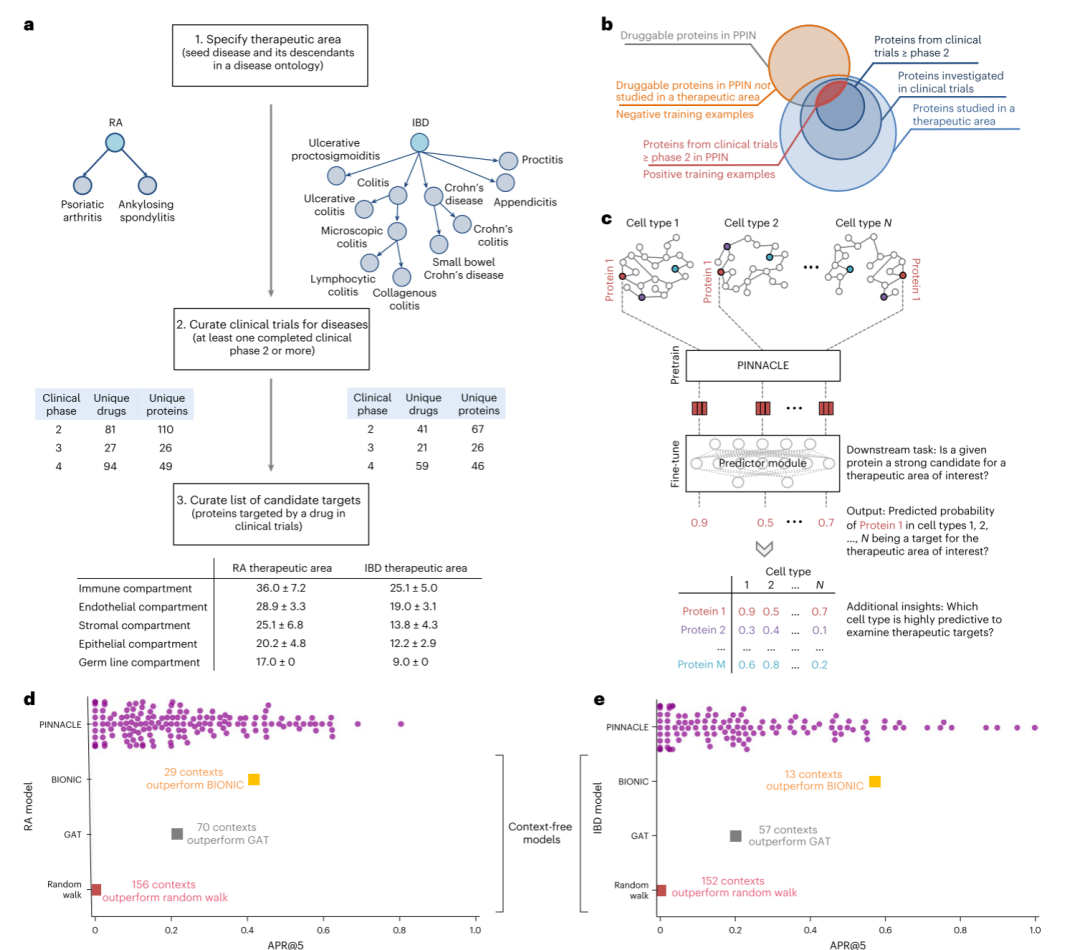
鉴于此,来自哈佛大学的Marinka Zitnik教授团队开发了一种考虑生物背景信息的单细胞蛋白质计算模型—— PINNACLE,通过结合单细胞转录组数据、蛋白质-蛋白质相互作用(PPI)网络、细胞相互作用和组织层次数据,为每个蛋白质生成细胞类型特异的低维表示,该模型生成的结果能够显著增强之前仅通过蛋白三维结构得到的通用表示,进而完成诸如发现靶点、分析特定细胞类型的药物反应等下游任务。
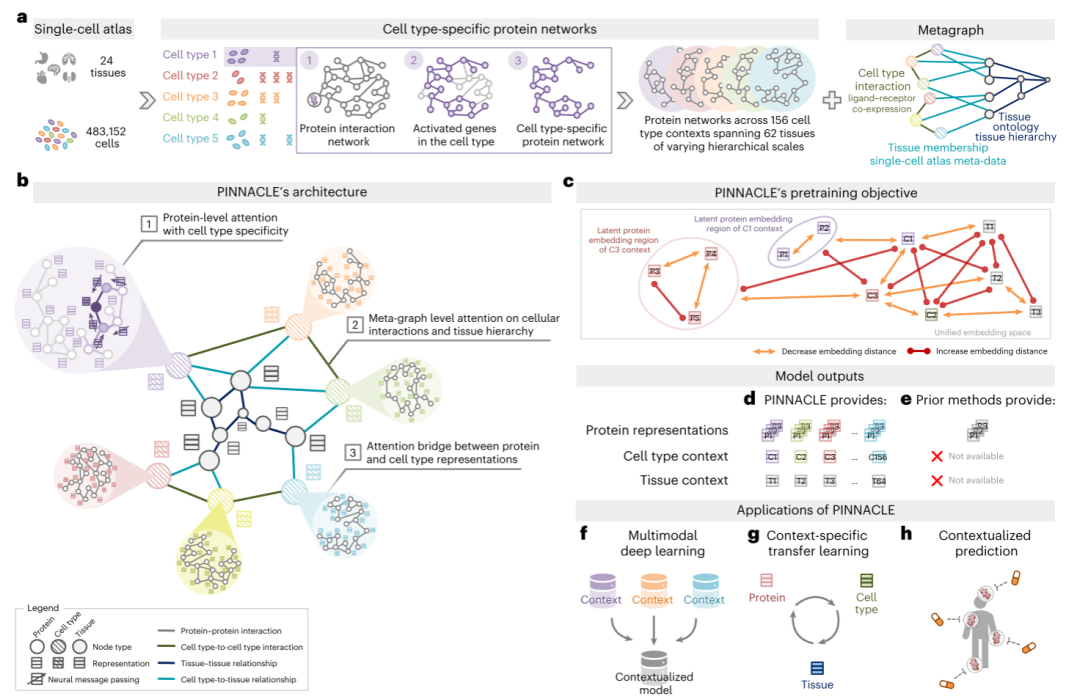
通过使用转录组学图谱数据与参考基因组进行比较,鉴定每个细胞类型特异高表达基因,寻找其对应的蛋白质,产生细胞类型特异的蛋白互作网络;通过对配受体关系和组织层次进行挖掘,得到细胞-组织关系图(MetaGraph)。将上述两图结合,可得到一个层次异质性网络,节点为蛋白质、细胞类型、组织类型,边为不同类型节点之间的关系(如蛋白互作关系,细胞配受体关系,组织层次等)。
采用对比学习的思路,对图进行自监督预训练,采用层次消息传递的方式对节点进行消息聚合,有边的节点之间增加特征表示相似性,无边的节点之间减少特征表示相似性,最终得到细胞类型特异的蛋白表示,细胞类型表示,组织表示。
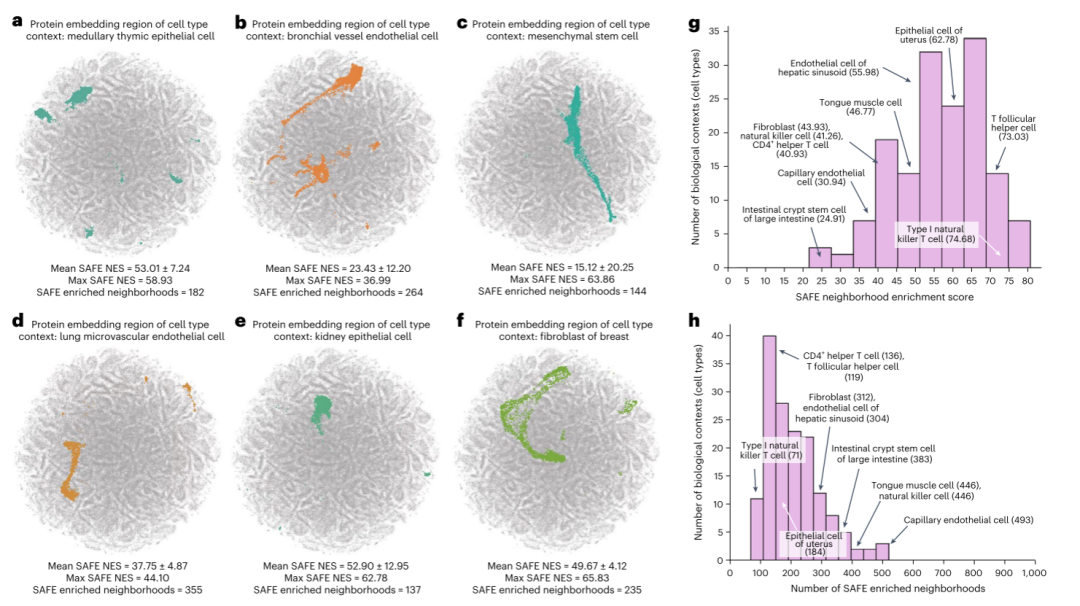
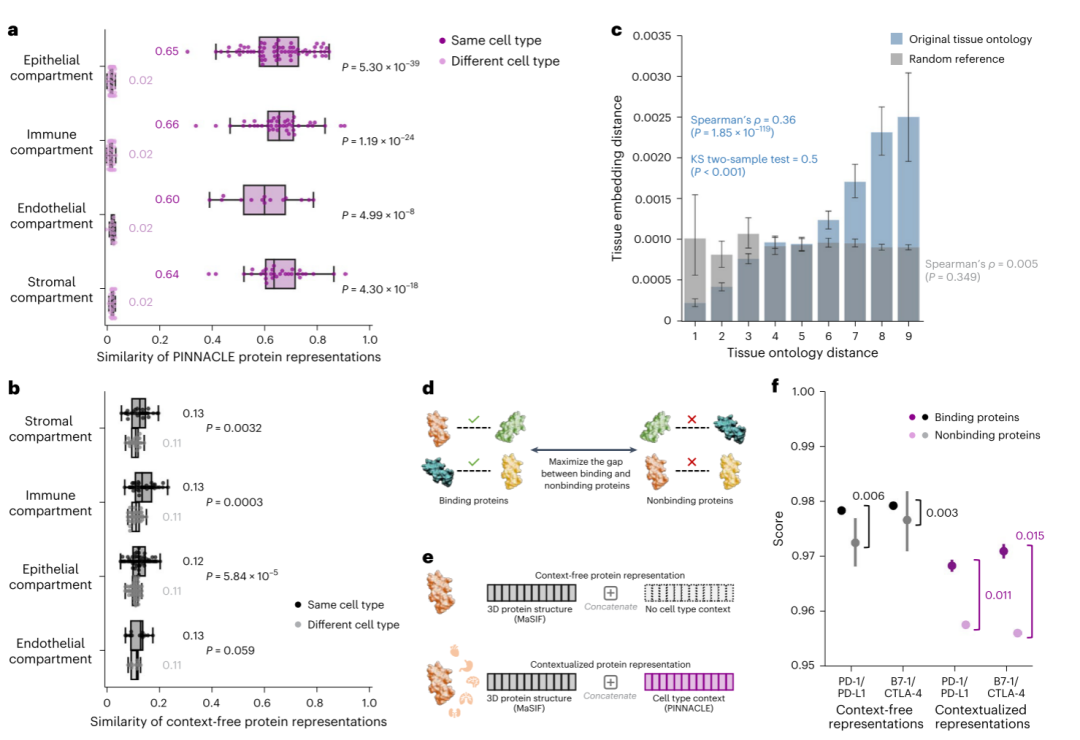
首先,研究者们对模型得到的表示空间进行了详细而又深入的探究。从蛋白层面,将所有的蛋白表示(394760个)降维投影到二维UMAP图上进行定性分析(图2a-f),发现来自相同细胞类型的蛋白在空间中也呈现聚集分布趋势。此外,文章采用定量统计学计算方法表明,模型考虑细胞类型信息后,的确会让来自相同细胞类型的蛋白表示相似度更高,反之亦然(图3a-b)。从组织层面,文章发现模型生成的组织层次表示也是合理的(图3c)。
其次,研究者们选取了典型可结合蛋白对:PD-1/ PD-L1和B7-1/ CTLA-4,通过消融实验证实加入生物背景信息(细胞类型特异性信息),能够更好地区分两个蛋白是否能够结合,从而得出结论:PINNACLE能够有效增强蛋白-蛋白互作网络的3D结构表示(图3 d-f)。
图2 对PINNACLE得到的表示进行定性展示和富集分析
然后,研究者们主要针对两种疾病:类风湿关节炎 (RA) 和炎症性肠病 (IBD) 进行了探究,开展了一系列下游任务。
将预训练过后的模型进行微调,并检查其是否能识别现在已有的治疗靶点。分类结果(图4)表明PINNACLE模型效果远超其他未考虑生物背景的模型(如随机游走、GAT等)。
图4 对PINNACLE进行微调,检验靶点识别性能
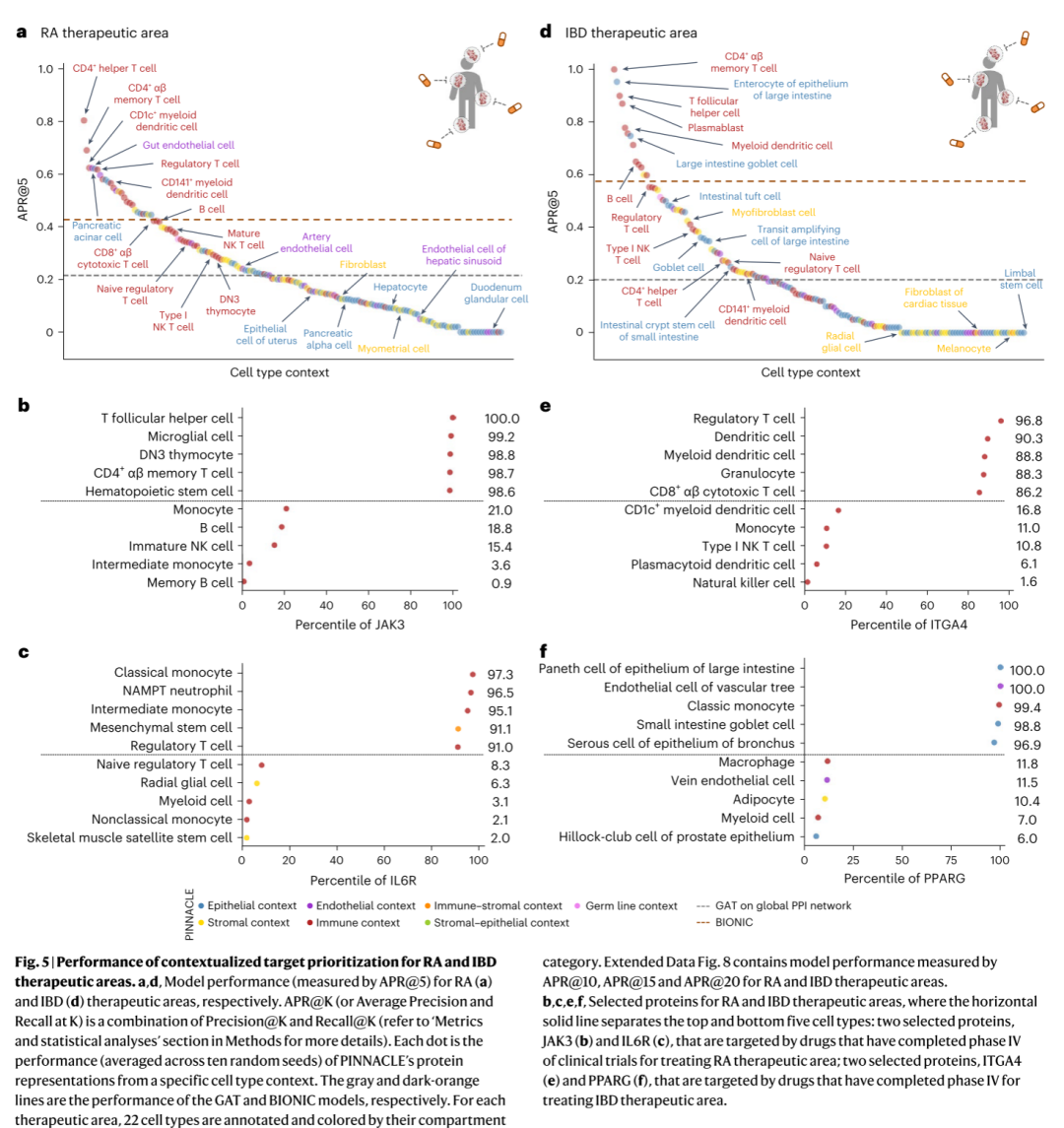
现有研究表明,不同类型的细胞对同一药物的响应不尽相同。因此,研究者们探究不同细胞类型的靶点识别性能是否有显著差异。结果如图5a、图5d所示,研究者们发现了某些特定细胞类型靶点识别性能较好,提示这类细胞对药物响应可能较强,存在发现新靶点的可能。图5 bc、ef分别以具体实例形式展示了相应情况,为临床靶向治疗、精准治疗提供了指导。
总之,在这项工作中,研究者们采用几何深度学习的策略,设计了一个考虑生物背景信息的单细胞蛋白质计算模型——PINNACLE,通过丰富的定性定量实验,不仅验证了模型的合理性,更揭示了模型的生物学意义和临床意义。
众所周知,蛋白质可以很方便地转化为一个计算模型,通过图神经网络等手段进行一系列的下游任务,如蛋白质结构预测,蛋白互作等。随着大模型的爆火,涌现出了很多优秀的工作将蛋白模型做大,采用大数据、大算力,期望能够“涌现”出生物学的底层规律,如AlphaFold3、ROSETTA – All Atom等。这篇文章发现了一个核心的问题,蛋白质表征模型都产生一个统一的表示,并未考虑到很多生物学背景信息,因此,围绕着这个问题,研究人员进行了探索,通过详细的分析和实验证实了融合生物学背景信息,能够很好的解决困扰已久的难题,正如一名审稿人所说,The paper is very timely, is technically interesting and addresses an important and challenging problem. 这篇文章对做算法开发的研究人员来说是一个很好的指引,引导大家将注意力放在挖掘好的科学问题,而非过多执着于算法的高深和艰难。
其次,将细胞类型作为有意义的生物背景信息从而注入模型是一个很好的想法,并且这不是第一次在顶刊中体现。如今年1月在Nature Methods中刊登的CytoCommunity[1],使用细胞表型作为特征学习组织细胞邻域 (TCN) 的划分,能够在可变空间尺度上发现条件特异性的细胞邻域协作模式,为解析肿瘤-免疫互作机制提供分析工具。因此,如何将生物学背景信息高效融入到计算模型,是未来值得探究的问题。
总体而言,这篇文章是一个非常漂亮的工作。从精准医学的角度出发,以细胞类型特异性蛋白表示(Cell type-specific protein representation)为线索,给读者展现了单细胞和蛋白互作网络是如何结合的,从而能够解决生物问题,提供临床指导。
1. Hu, Y., Rong, J., Xu, Y. et al. Unsupervised and supervised discovery of tissue cellular neighborhoods from cell phenotypes. Nat Methods 21, 267–278 (2024). https://doi.org/10.1038/s41592-023-02124-2
在生物学中心法则的起点,基因作为生命复杂系统的遗传信息载体,在生命周期内稳定存在;而位于中心法则末端的蛋白质,其组织构成和时空变化的复杂性呈指数式增长。随着分子生物学数十年来的突飞猛进,尤其是生命组学(基因组学、转录组学、蛋白质组学和代谢组学等的集合)等领域的日新月异,当代生命科学临近爆发的边缘。如此海量的数据如何帮助我们揭示宇宙中最复杂的物质系统——“人体”的构成原理和设计原理?阐释人类发育、衰老和重大疾病的发生机制?
集智俱乐部联合西湖大学理学院及交叉科学中心讲席教授汤雷翰,国家蛋白质科学中心(北京)副研究员常乘、李杨,香港浸会大学助理教授唐乾元,北京大学前沿交叉学科研究院研究员林一瀚,中国科学院分子细胞科学卓越创新中心博士后唐诗婕,共同发起「生命复杂性:生命复杂系统的构成原理」读书会,从微观细胞尺度、介观组织器官尺度到宏观人体尺度,梳理生命科学领域中的重要问题及重要数据,由生物学家提问,希望促进统计物理、机器学习方法研究者和生命科学研究者之间的深度交流,建立跨学科合作关系,激发新的研究思路和合作项目。读书会从2024年8月6日开始,每周二晚19:00-21:00进行,持续时间预计10-12周。欢迎对这个生命科学、物理学、计算机科学、复杂系统科学深度交叉的前沿领域感兴趣的朋友加入!
6. 加入集智,一起复杂!