传统深度学习方法在处理非欧几何空间数据时显得力不从心。近年来,基于消息传递机制的图神经网络的出现,为处理社交网络和分子结构等具有复杂关系结构的数据提供了全新的方案。然而传统的图神经网络在设计之初也并非完美,几何深度学习是否能为非欧几何空间的数据提供更精确的表征?如何才能够克服传统图神经网络的局限?AI for Science的下一个颠覆性突破又在何处?
几何深度学习读书会第二期由发起人之一上海交通大学副教授王宇光,带领大家探索几何深度学习当前的研究进展及未来的技术趋势。本次分享依次介绍了图神经网络如何通过消息传递机制和图卷积模块处理图结构数据,并针对其缺陷提出了改进和优化方法。进一步,通过介绍消息传递单纯复形网络和双曲几何深度学习,详细阐述了几何深度学习在处理非欧几里得数据方面的最新进展及其优势。最后,从理论发展、学科交叉与应用前景等角度,对几何深度学习的发展趋势进行了全面展望。
研究领域:几何深度学习、消息传递机制、单纯复形、双曲几何、拓扑数据分析
王宇光 | 讲者
王若晨 | 整理
王宇光、余孟君、董弘禹 | 审校
1. 几何深度学习背景
2. 经典图神经网络
3. 经典图神经网络的模型改进及优化
4. 消息传递单纯复形神经网络
5. 几何深度学习的典型应用
6. 双曲几何深度学习
7. 几何深度学习的发展趋势
Al for Science and Structure Deep Learning

在科学领域,几何深度学习(Geometric Deep Learning, GDL)是人工智能研究的重要方向。自2022年AlphaFold 2开源以来,人们逐渐认识到AI在生物学,特别是结构生物学中的巨大贡献,包括蛋白质结构折叠和逆折叠等应用。这进一步证明了AI在科学研究中的潜力。在蛋白质结构预测方面,AI不仅速度快,而且其准确性能够与实验室测得结果相媲美甚至超越,这一成果令人振奋。
此外,在数学领域,DeepMind 的一篇 Nature 封面文章介绍了一种利用图神经网络进行快速优化的方法,用以证明某些数学猜想,例如拓扑学中的纽结定理以及图表示论中一些较大猜想的优化,包括界的优化。这表明几何深度学习,特别是当前的拓扑深度学习(Topological Deep Learning, TDL)具有重要应用价值。
感兴趣的朋友可以观看相关分享——AI+Science 第三季 :人工智能与数学:8.用机器学习寻找丝带结(https://pattern.swarma.org/study_group_issue/562)
几何深度学习 Geometric Deep Learning
几何深度学习是一种在提取特征时,具有保持对象特征不变特性的深度神经网络。这种变换在一些群上进行,如 2D 和 3D 欧氏空间中的平移群、旋转群、庞加莱群、洛伦兹群等。这些都会对应到所谓的“对称性(Symmetry)”,这种对称性在物理上和生物上有很多应用。能够把这些不变的性质和物理中的运动和对称性相结合是深度学习在各个科学领域得到成功的关键点。
在变换中,一个被关注的对象保持不变被定义为具有对称性。例如,对于空间中的两点,不管它们如何同时旋转或平移,它们间的距离仍保持不变。在数学上,一组变换的集合被称为群。
对于第一张照片这种 2D 图像,我们希望对象在图片中的位置不影响所设计的机器学习方法对它的识别,例如经典的卷积神经网络(Convolutional Neural Networks,CNNs)就可以不受它所在位置的影响,提取出歌剧院的总体特征。
对于分子结构数据,这种具有关系属性的数据,其特点在于这些节点之间有着一些特殊的几何关系或者是空间结构,这种空间结构在一定程度上能够反映出这个对象或者分子的一些特征,这十分重要。
在深度学习中,拓扑和几何关系至关重要。如何将这些特征整合进深度学习模型,或通过提取重要的几何不变特征,使其在预测过程中发挥关键作用是几何深度学习特别擅长或重点关注的机制。
等变性(Equivariance)指对一个对象施加一个广义的变换以后,预测结果是否在某些层面是一致的。例如对于这个小白兔 (Bunny),它经过一个旋转变换后是否还能判断出它是一个小白兔。这种空间上的等变性对药物设计,特别是大分子药物设计、抗体设计的预测复合体结构中(例如 AlphaFold 3)的准确性的提升十分重要。
感兴趣的朋友可以观看相关分享——图神经网络与组合优化:5.几何图神经网络及其科学应用(https://pattern.swarma.org/study_group_issue/485)。并且,社区成员整理成笔记,供大家学习几何深度学习:让物理世界拥有AI | 黄文炳分享整理
Graph and Image Data
深度学习在过去十几年发展比较成功的两个网络一个是图神经网络(Graph Neural Networks, GNNs),另一个是卷积神经网络(CNN)。现在几何深度学习能够同时关注这两种网络。
对于CNN来说,在图片特征提取时,会考虑一些局部特征,这些特征和位置无关。而图数据结构则会考虑节点之间的比如两原子之间的相互作用,这种作用来自物理属性或者生化属性,例如相互作用力和共价键连接。这些关系特点是自然界广泛存在的。此外在社交网络中也会考虑人和人之间的联系,用户和商品之间的联系,把这些联系抽象出来,就变成了一个结构数据或者关系数据。可以把这种关系看作图的一条边,甚至是拓扑中的某些几何特征。
这些数据和平面数据有着本质的不同,称为非欧结构数据(Non-Euclidean Structure data),平面数据或者图像数据称为欧式结构数据(Euclidean Structure data)。对这两种数据的特征学习和预测是两种截然不同的模式。
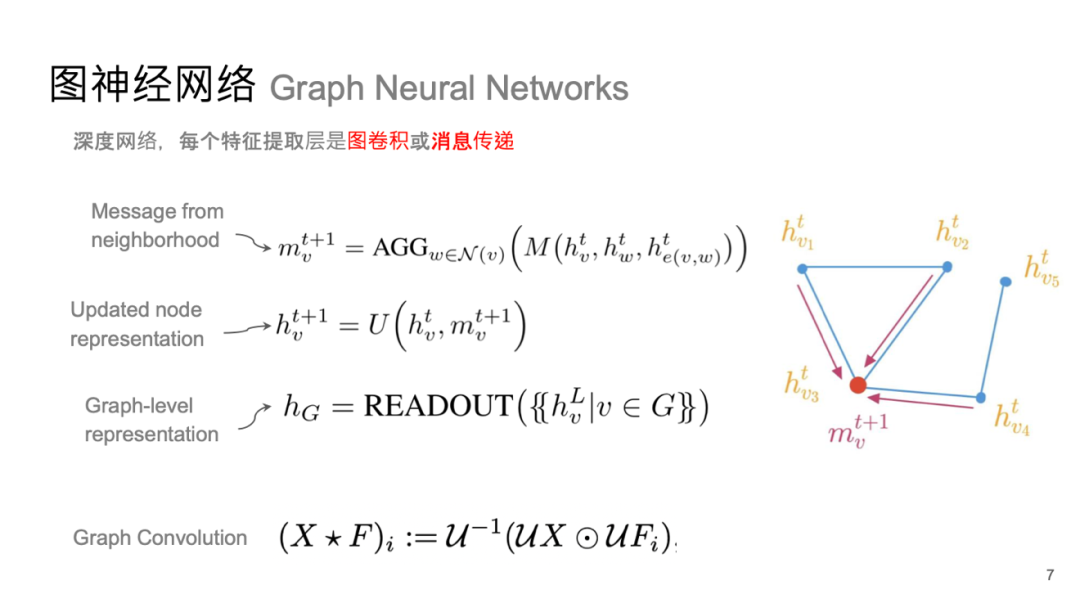
神经消息传递(Neural Message Passing)是神经网络中常用的一种模式,其概念源自理论计算机科学中的消息传递机制。在节点特征更新时,会考虑该节点与其周边节点之间的特征交互关系。例如,在分类任务中,物以类聚的原则使得我们在进行分类时会关注这些联系,这些联系反映了它们之间的共性。如何将这种共性纳入神经消息传递过程中至关重要。
实现这一点主要依赖于两个步骤:首先,周边节点可以是直接相连的邻居,也可以是更广泛范围内受共同特征影响的节点;其次,需要整合这些特点,例如通过全连接网络(Multilayer Perceptron, MLP)来提取数据特征。这一过程不仅涉及中心节点,还需考虑每个节点及其邻近节点间的关系,包括不同层级间点与点之间的关联。因此,可以将整个系统视为一个离散动力系统,但实际上由于图中可能有 n 个节点,因此形成了 n 个子系统,使之成为一个复杂的多体系统。
数学上也有相关研究,比如粒子系统可用于模拟多体系统,其中粒子间相互关系可视为图中的边,而多个图之间则可看作超边。这些研究成果对探索和改进神经消息传递方法具有重要意义,并且近期在此领域已有诸多进展。
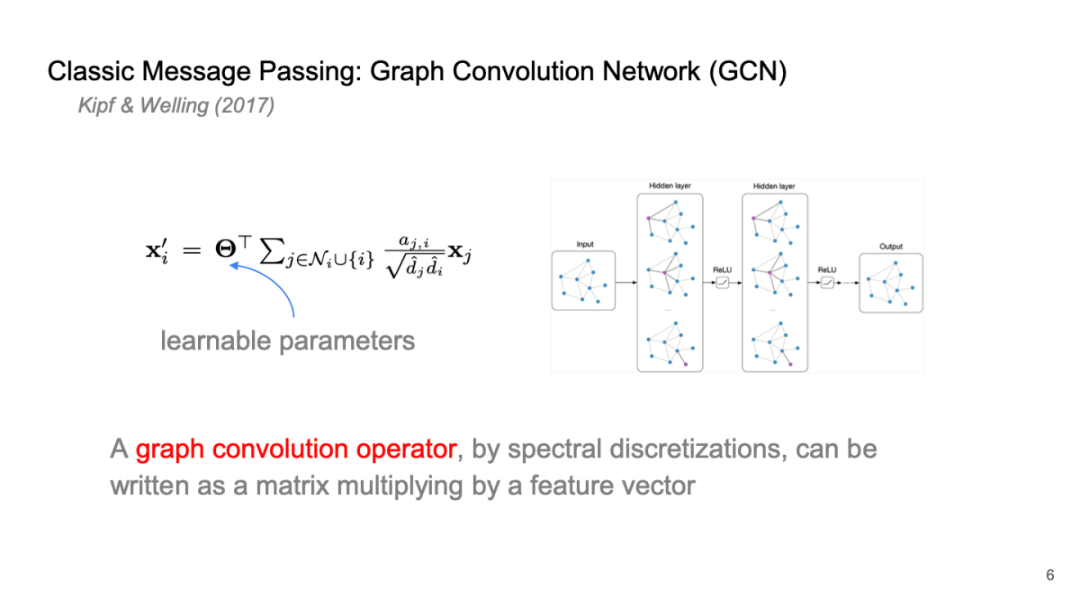
Classic Message Passing: Graph Convolution Network (GCN)
经典的图卷积网络是一个相对简单的系统,从微观角度看,它主要通过与相邻节点之间边连接的特征进行线性加和。这些权重来自于节点间自带的权重。由于这是一个深度神经网络,通常需要可学习参数来驱动关系和特征的迭代,因此会采用共享权重,即各个节点使用同一系数表示。
这个矩阵的维度与特征维度一致,其作用在于学习特征传递过程中的共性,同时也能体现每个节点上的结构信息及其特征。因此,这构成了经典的神经消息传递模型,并在许多深度学习任务中,如节点分类、回归以及图层面的分类等问题上表现出色。
该实现形式非常简洁,通过消息传递的方式进行表达,这在计算机实现中,尤其是在 GPU 运算和底层实现时,可以显著加快运算效率。因此,直接采用这种模式进行实现是高效的。
图神经网络 Graph Neural Networks
谱图卷积 Spectral Graph Convolution
我们进一步探索如何优化系统迭代。数学上,这种微观表示实际上对应于消息传递,而更宏观的表示可以用邻接矩阵 乘以特征矩阵 (每个节点的特征构成)来描述,再与外部的权重 相乘,并添加激活函数,从而得到一个系统。
如果将图视为离散流形或嵌入数据,这个系统实际上是在流形上的傅立叶卷积或图上的傅立叶卷积近似。这方面有许多研究探讨如何近似这一过程。早期经典的图卷积网络就是基于傅立叶卷积定义的。
在数学中,流形(manifold)是可以“局部欧几里得空间化”的一个拓扑空间,即在此拓扑空间中,每个点附近“局部类似于欧氏空间”。更精确地说,n维流形(n-manifold),简称n流形,是一个拓扑空间,其性质是每个点都有一个邻域,该邻域同胚于n维欧氏空间的一个开集。
这里提到的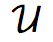 是拉普拉斯矩阵对应特征向量分解形成的矩阵。从另一个角度看,该矩阵与图信号(整个图上的特征)相乘,即对该信号进行傅立叶变换。如果执行逆变换,则为傅立叶逆变换。因此,我们可以通过邻接矩阵及其对应特征向量定义我们的傅立叶卷积,这实质上完全遵循了傅立叶卷积定义,是对每个数据特征和滤波器的傅立叶变换后再单点相乘并做逆变换所得到的一种卷积。
是拉普拉斯矩阵对应特征向量分解形成的矩阵。从另一个角度看,该矩阵与图信号(整个图上的特征)相乘,即对该信号进行傅立叶变换。如果执行逆变换,则为傅立叶逆变换。因此,我们可以通过邻接矩阵及其对应特征向量定义我们的傅立叶卷积,这实质上完全遵循了傅立叶卷积定义,是对每个数据特征和滤波器的傅立叶变换后再单点相乘并做逆变换所得到的一种卷积。
拉普拉斯矩阵是对图结构的一种描述,其中对角线上的元素表示相应节点的度。其他位置刻画节点之间是否有边相连:如果有边相连记为-1,没有边相连记为0。
2013年,Joan Bruna 和 Yann LeCun [1]提出了基于傅立叶变换的图卷积方法。早期,Lecun 对图神经网络的发展持支持态度,因为当时尚未明确如何定义非规则节点上的数据。在小规模图中,这种方法的准确性和效率较高,但在处理大型图(如社交网络中数百万或数亿个节点)时,由于需要进行复杂的特征分解,计算难度显著增加,因此不太现实。
为了解决这一问题,从 2013 年至 2017 年间,研究者们持续探讨优化方案。2016 年出现了一种名为ChebNet的网络[2],它通过切比雪夫多项式展开对傅立叶卷积进行了近似,使得在滤波器设计过程中无需直接计算特征分解,从而提高了效率。
Kipf 和 Welling 在 2017 年[3]对卷积网络进行了简化。他们通过提取切比雪夫展开的前两项,将复杂的卷积形式转变为更简单的格式,这种简化在实践中证明非常有效,因此被广泛传播。同时为了进一步发展卷积并避免计算复杂性的指数增长,需要对变换进行优化。
早期研究表明,谱图卷积与相应的优化方程有直接关系,它实际上是拉普拉斯正则化优化解的一种近似。在此过程中,优化目标除了原本的卷积,还引入了与拉普拉斯项相关的正则项,以刻画几何特征。
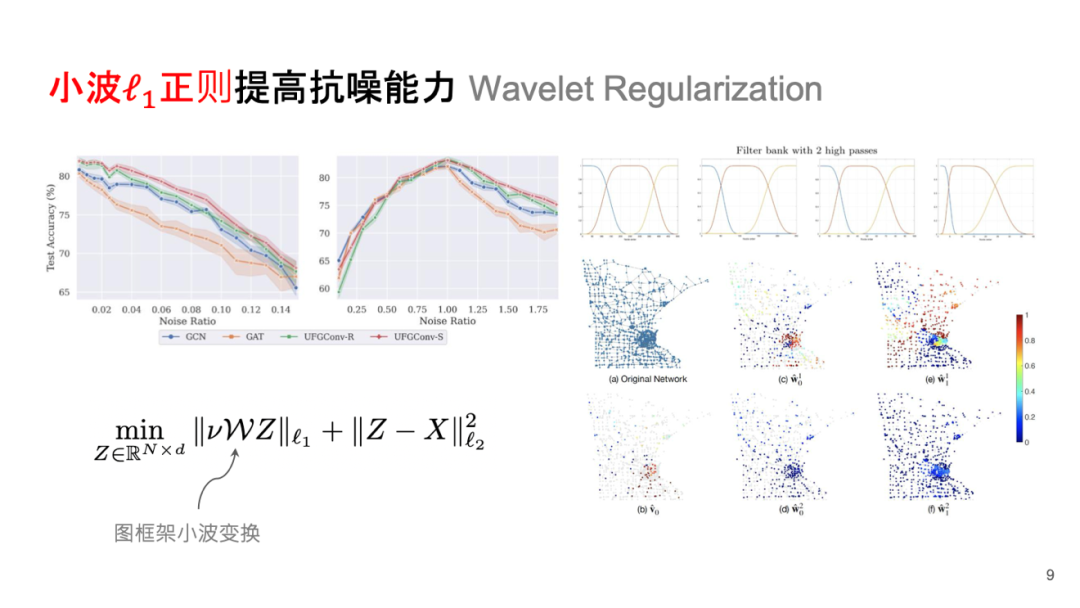
小波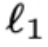 正则提高抗噪能力 Wavelet Regularization
正则提高抗噪能力 Wavelet Regularization
此外,可以采用小波变换替代傅立叶变换,通过非备降式的小波分解来避免细节处理,从而使用整体拉普拉斯多项式组合计算小波矩阵,这类似于切比雪夫多项式的一种近似。这种方法能够减少噪音信号的影响。
感兴趣的朋友可以观看相关分享——AI+Science 第三季 :人工智能与数学:7.利用小波分析增强深度学习模型的鲁棒性(https://pattern.swarma.org/study_group_issue/556)。
设计卷积提高鲁棒性 Enhance Robustness of GNNs
小波卷积可以定义为先进行小波分解再反变换。其在频域空间中的操作,可以看作是在频域空间中的学习过程。激活函数可以由小波分解中的 Shrinkage 模式定义。传统框架下的小波卷积在噪音去除和多尺度数据表示方面表现出色。
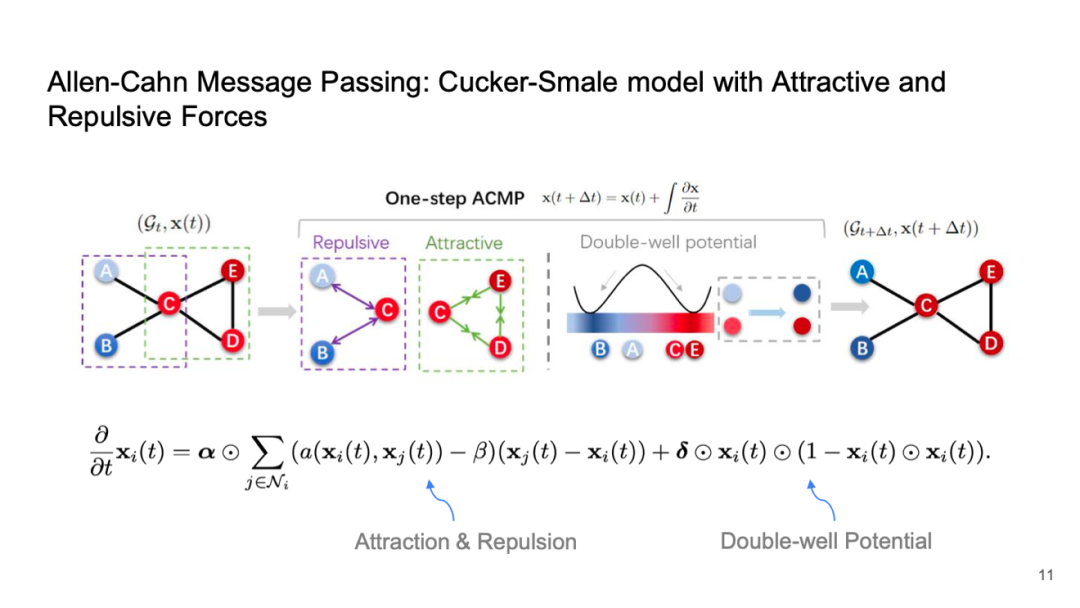
Allen-Cahn Message Passing: Cucker-Smale model with Attractive and Repulsive Forces
在图神经网络中,一个重要的问题是“过光滑现象”。随着网络层数的加深,特征趋同,使得节点分类变得困难,从而降低了学习和预测能力。这种现象是神经消息传递中的一个不可避免的结果。
理论上可以证明,如果遵循特定的消息传递模式构建神经网络,它必然会出现特征趋同问题。许多学者对此进行了研究,例如 Michael M. Bronstein 提出了Gradient Flows[4]来降低特征趋同造成的影响。
Cucker-Smale model to GNN: Allen-Cahn Energy
我们可以将消息传递视作一个动力系统,并用粒子方程描述其演化过程,这实际上对应于扩散方程。然而,传统扩散方程只考虑粒子之间的吸引力,而忽略了距离减小时可能产生的排斥作用。如果没有排斥效应,所有粒子最终会聚集到一点,这是不理想的。因此,可以通过加入排斥项来改善这一点。
然而,仅仅依靠排斥力可能导致极端情况,即特征无限增大或减小,从而在数据计算上带来问题。当网络加深时,也可能出现计算失控的问题。因此,我们尝试引入一种平衡项 Allen-Cahn 项,实现引力与斥力之间的平衡,达到双井势(double well potential),使得粒子能够稳定在多个平衡点上,实现有效分类。
这种方法基于多体系统的一些数学理论,如 Cucker-Smale 模型,该模型涉及引力与斥力系统。在这个框架下,可以证明即使当网络层数达到 50、100 或 500 时,仍然具有良好的可分性,不会出现过光滑问题。这表明,通过改进和优化多粒子系统及其方程,我们能够有效地解决神经消息传递中的相关挑战。
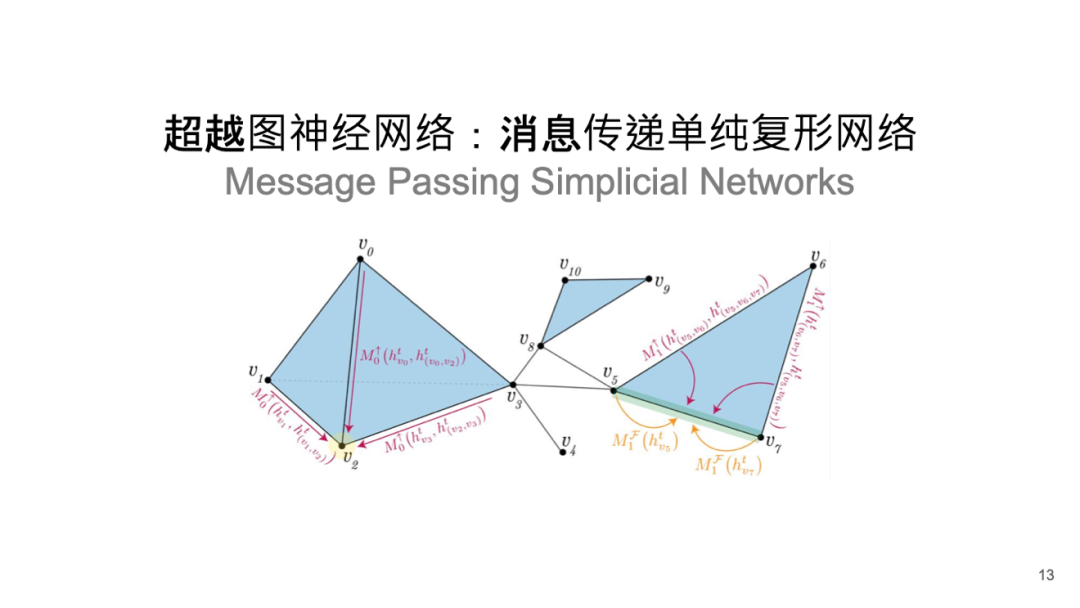
超越图神经网络:消息传递单纯复形网络 Message Passing Simplicial Networks
另一个有趣的发展方向是对复杂数据或几何的刻画,现称为拓扑深度学习,这是传统拓扑数据分析的延伸。该领域关注数学上严格定义的结构,如超图和单纯复形,而不仅限于计算机科学中常用的图。
单纯复形考虑的不仅是两个节点之间的边关系,还包括三个节点形成面的关系,以及四个节点构成立方锥等多阶拓扑特征。这些高阶拓扑关系被称为单纯复形网络。
我们与牛津大学 Michael M. Bronstein 教授团队合作开发了一种新的单纯复形网络(Message Passing Simplicial Networks, MPSN)[5]。除了研究几何体不同层次的拓扑特征外,我们还探讨如何通过低阶拓扑构造高阶拓扑,从而建立它们之间的联系,这一过程在我们的消息传递机制中得以体现。
感兴趣的朋友可以观看相关分享——几何深度学习:1.AI如何理解高阶结构?拓扑深度学习基础(https://pattern.swarma.org/study_group_issue/710)。
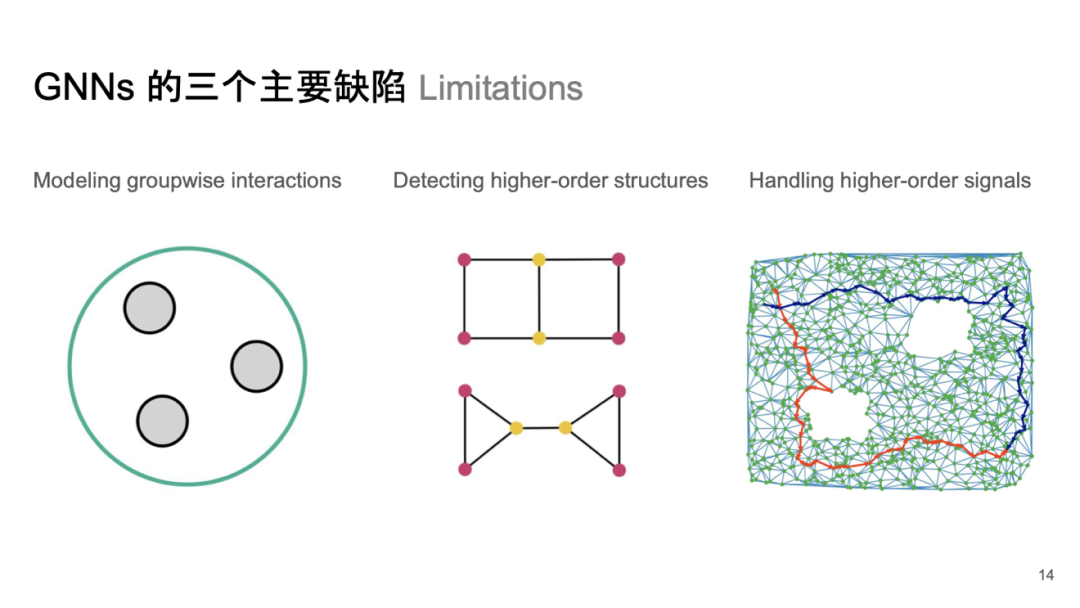
GNNs 的三个主要缺陷 Limitations
这种单纯复形网络旨在克服传统图神经网络存在的一些缺陷,包括无法有效描述多个节点间交互、难以检测高阶拓扑关系以及处理长路径信号时效果不佳等问题。因此,消息传递系统在这里表现出较好的性能。
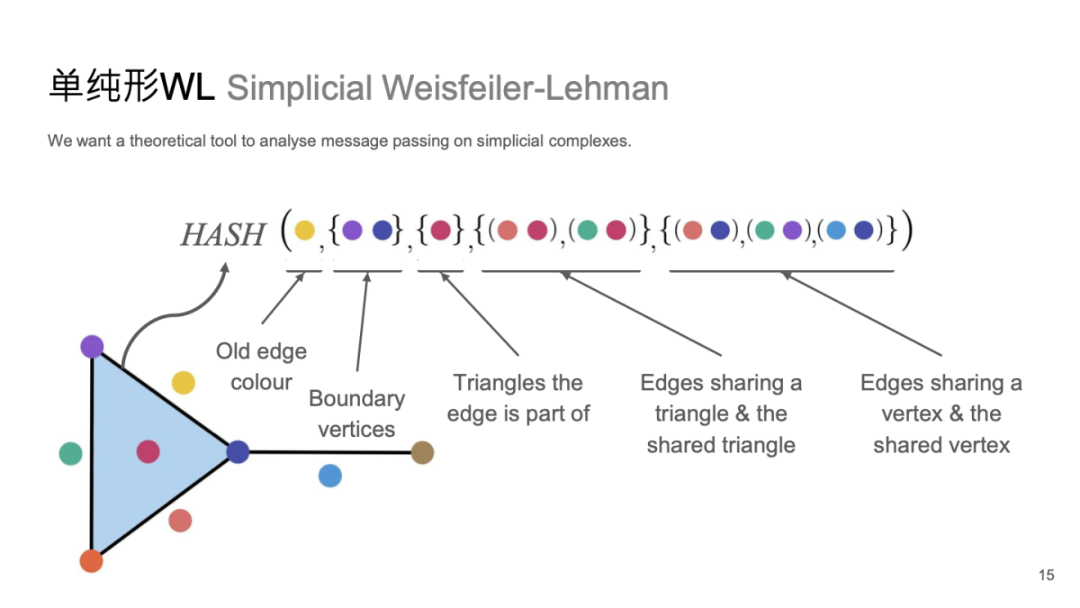
单纯形WL Simplicial Weisfeiler-Lehman
该系统源自 Weisfeiler-Lehman 测试,是一种图同构检测算法,用于确定两个图是否具有相同的结构。
具体而言,该测试可用于评估神经网络模型性能,以确定其是否满足特定的计算复杂度要求并能有效区分不同结构的数据。此外,单纯形上还存在相应的 WL 测试,称为单纯形 WL(Simplicial WL) 测试。
这种测试源自传统着色问题的考虑。简单来说,我们会分析单个节点、边以及面(如二阶或三阶拓扑)的特征,将它们整合后进行 HASH 操作,通过检查是否能够有效区分不同结构的数据,从而实现 WL 测试。我们的研究发现,单纯形 WL 测试可以在一定程度上定义消息传递,这使得它能够迁移到消息传递应用中。
SWL 对应的神经网络层:消息传递单纯复形网络 MPSNs
除了之前提到的节点特征外,还需考虑边、面及高阶拓扑特征的整合。这些整合基于消息传递模式,通过加和来形成新的信息,而这些模式遵循一定规则,例如连接方式和相关性(如同属于某一阶拓扑)。
相关性可能涉及多个方面,比如共面的关系,以及不同阶拓扑之间的交互。例如,一阶与二阶或三阶与四阶之间存在邻接矩阵关系。从低阶到高阶是一种方向,而从高阶到低阶则是另一种。因此,需要考虑上下邻接的问题。将所有这些信息,包括各个拓扑的信息及其相邻阶间的信息,通过类似于图神经网络的消息传递方式进行整合,就能构建出一种有效的单纯复形网络。
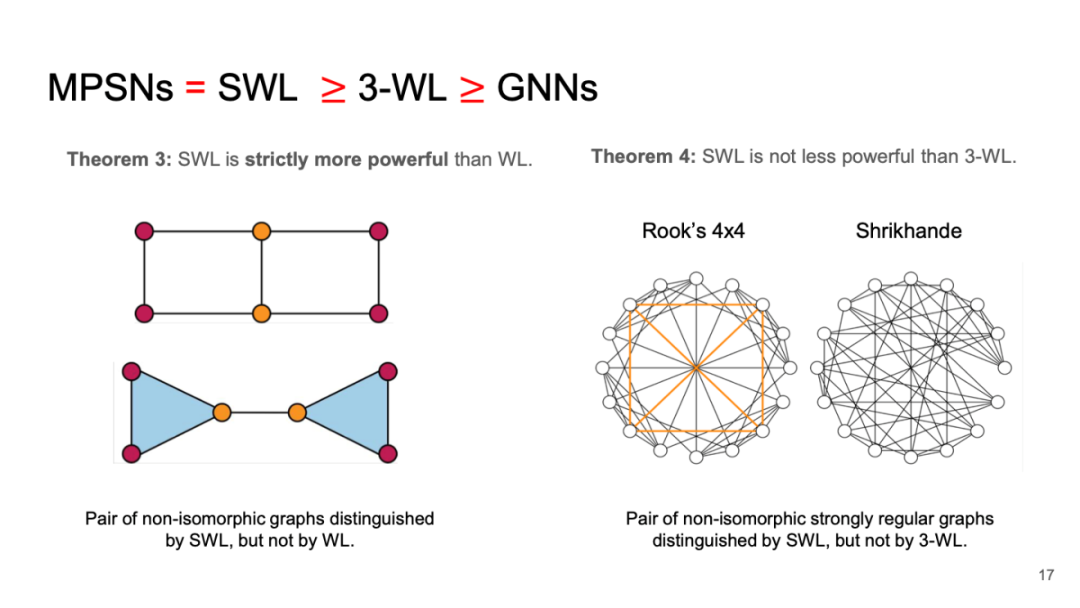
MPSNs = SWL 3-WL GNNs
通过对其复杂性的分析和线性域计算,可以有效地证明该消息传递神经网络能力远超传统图神经网络:文献表明后者无法超过 3 阶 WL Test 能力。而一般单纯形消息传递网络则能超过 3 阶 WL Test,因此可以证实这一新型网络在学习和预测能力上优于传统图神经网络。
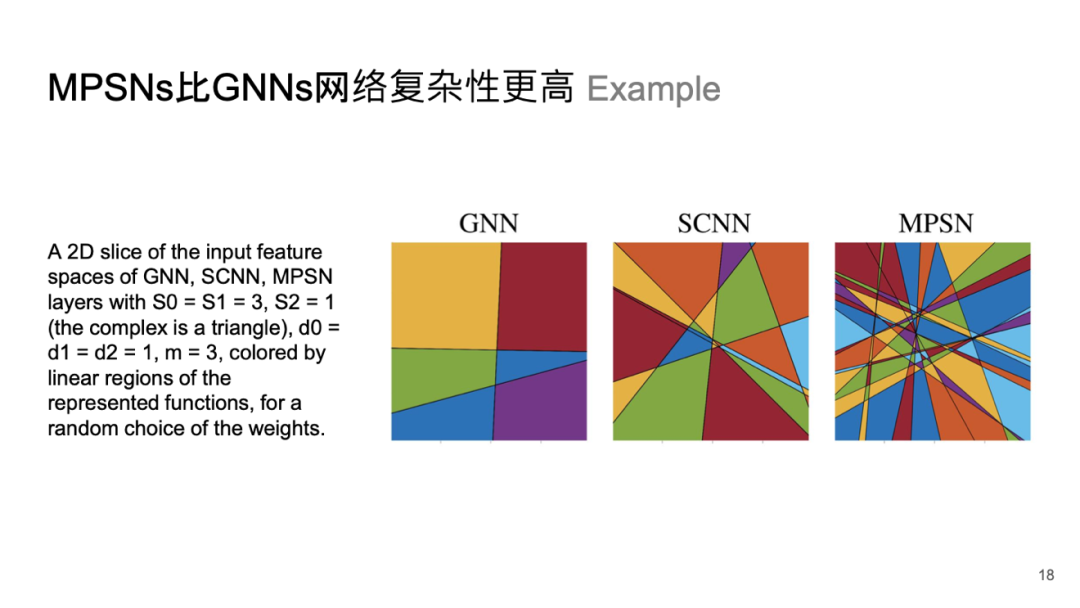
MPSNS 比 GNNs 网络复杂性更高
这个结果说明了更高阶的信息和拓扑信息对几何深度学习模型的重要性。通过计算某个案例中不同网络的线性域,我们可以直观地看到模型的复杂度。使用 ReLU 激活函数时,网络会进行线性的切分或使用超平面进行高维特征切分,超平面的数量越多,表明网络内部复杂性越强,从而提升其表示能力和学习能力。
在实际案例中,与消息传递单纯复形网络相比,图神经网络的复杂性明显较低。这意味着采用单纯复形或高阶拓扑能够显著增强网络的表示能力,这是一个积极信号。然而,这种多阶信号所带来的丰富几何信息也会导致计算复杂度上升,因此需要运用技巧来平衡表示能力与计算复杂度。
路径分类 Trajectory classification
我们希望能得到良好的预测结果,即使这种复杂度呈线性增加,也应被适当平衡。这是一个典型的案例。我们可以使用四层的图神经网络进行消息传递,并结合注意力机制和四层消息传递模式,与采用消息传递单纯复形神经网络的方法相比,结果差异显著。
以同一轨迹预测任务为例,MPSN能够达到接近 96%至 97%的预测准确度,而图神经网络的效果则相对较差。
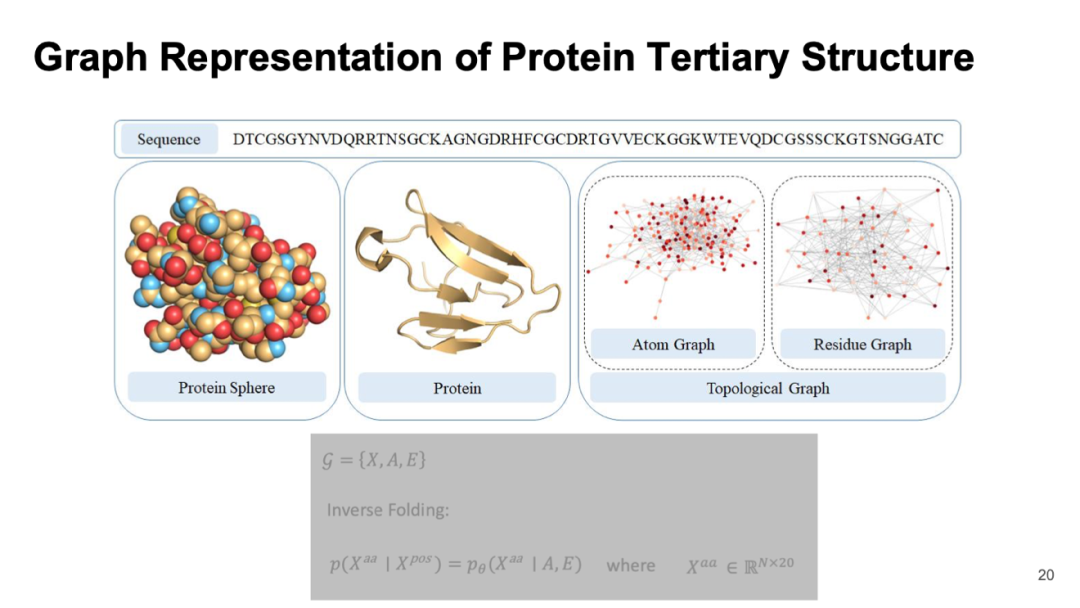
Graph Representation of Protein Tertiary Structure
一个有趣的发展方向是在生物领域的交叉,特别是在蛋白设计方面。我们目前的研究受到 DeepMind 的 AlphaFold 启发,该模型不仅使用了多层 Transformer,还引入了结构深度学习模块,这实际上是一种几何深度学习。
在蛋白质中,每个氨基酸包含序列信息,通过折叠形成三维结构。这一最终结构决定了蛋白质在体内外的功能,比如酶催化、药物作用和抗体反应等。因此,对蛋白质结构的捕捉至关重要。
我们可以将每个氨基酸视为图中的节点,而它们之间的相互作用则看作边,从而构建残差网络或原子图。如果按原子层面分析,每个氨基酸由多个原子组成,形成庞大的图结构。尽管训练效率较低,但随着计算能力提升,现在许多团队已能有效处理这些复杂数据。
通过将信息转化为图形并应用几何深度学习,我们能够从序列信息直接预测每个原子的三维坐标。例如,一个由 1000 个氨基酸组成的蛋白可能涉及上万个原子的坐标预测,这项任务难度不言而喻。此外,在逆折叠方面,如果知道某一功能和其对应结构,就可以设计新的蛋白,这是实际应用中常见且需求量大的任务。
感兴趣的朋友可以观看相关分享——几何深度学习:4.解读生命密码 | 几何深度学习在生物科学中的应用(https://pattern.swarma.org/study_group_issue/699)。
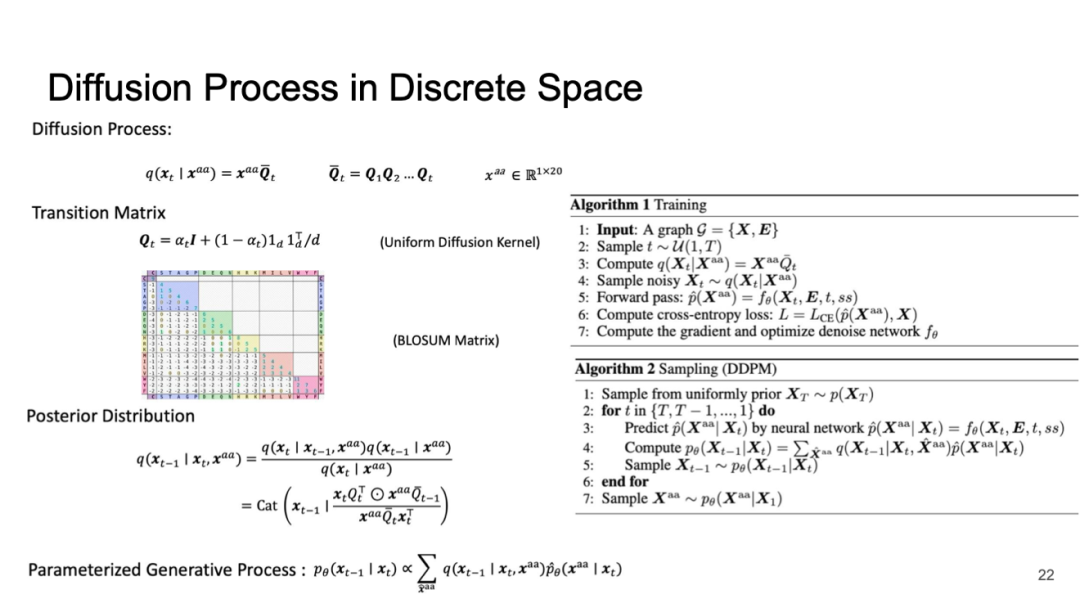
Diffusion Process in Discrete Space
将扩散模型与几何深度学习结合,可以实现生成式 AI 的效果。通过将蛋白质的氨基酸突变矩阵与扩散模型相结合,可以形成迁移模式,从而进行有效的统计推断。
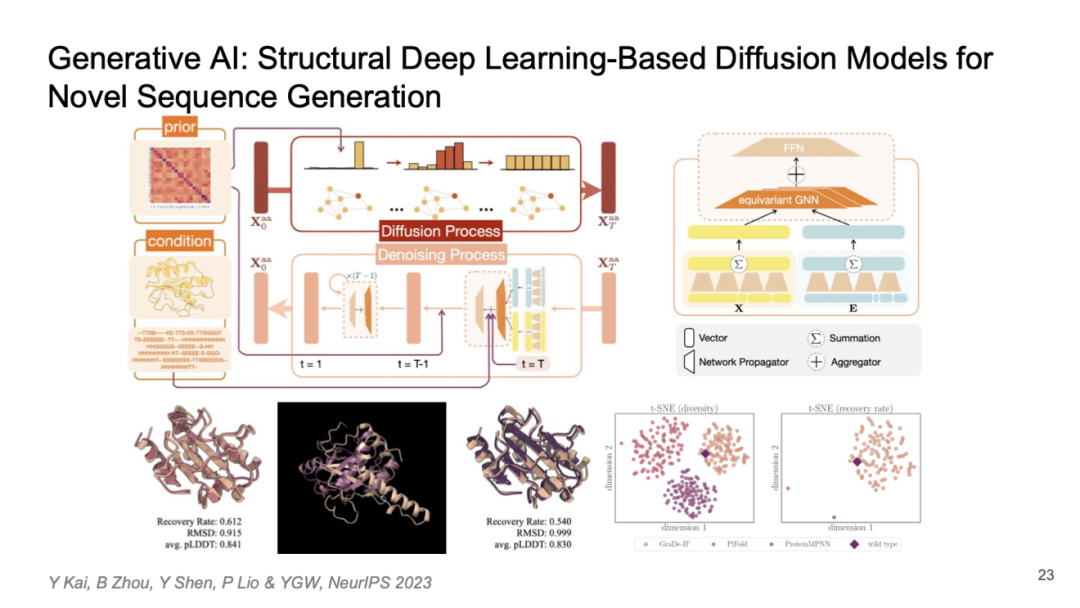
Generative Al: Structural Deep Learning-Based Diffusion Models for Novel Sequence Generation
下面是一个例子,我们可以利用几何深度学习构建一个扩散模型,进而开发出一种生成式 AI 的方法,用于预测新的黄色蛋白结构。这种黄色蛋白和紫色蛋白在结构和功能上非常相似,甚至可能在某些功能上有所提升,但它们之间的序列相似度却很低。因此,这样的方法能够帮助我们设计出一些新型蛋白质,并创造出新的产品。
双曲几何深度学习 Hyperbolic geometric deep learning
对于几何学的研究除了常见的球面几何和正曲率几何外,还会考虑双曲几何这些对象。
双曲几何主要研究的是负常数曲率的非欧几里得结构。在深度学习中,我们将双曲几何的一些特性应用于几何深度学习推断,例如在图卷积层或神经消息传递中,使数据中的一些几何性质能够在双曲空间中进行计算。
双曲几何深度学习特点 Hyperbolic geometric deep learning
这一过程可以分为三步:首先,将原始特征中的节点信息嵌入到双曲空间,以更好地表示图的数据层次结构;其次,通过消息传递或变换方式,在节点之间传播信息,同时保持双曲几何特性;最后,对信息进行聚合,有效更新特征。
双曲几何深度学习 Hyperbolic geometric deep learning
在处理时,双曲几何需要考虑层次表示,其特征使得它更适合有效表达数据分层。例如,在社交网络中,有影响力的中心节点与边缘节点之间存在明显区别,如 Elon Musk 在 Twitter 上的影响力远大于普通用户,这种层次区分对理解网络关键特征非常有帮助。
此外,双曲几何能一定程度上保持原始数据的结构关系,从而减少推断过程中丢失的重要几何信息。这一点对于从高维数据到低维拓扑表示至关重要,如何实现高效嵌入也是该领域关注的重点。相较于欧式空间,双曲空间能够以更低维度表示相同结构的信息,因此在捕捉各节点间相似度方面表现出色。例如,对于异构图(Heterogeneous Graph),相似类节点即便距离较远,通过双曲变换也能使其在空间上接近,这有利于后续神经网络推断。
异构图指图中存在不同类型的节点和边(节点和边至少有一个具有多种类型)的图结构。
双曲图卷积神经网络 Hyperbolic GCN
现有的双曲几何深度学习中,有两种经典的方法。首先是由斯坦福大学的 Leskovec 团队提出的基于双曲几何的图卷积网络,称为双曲图卷积网络[6]。他们使用庞加莱球模型进行节点嵌入和卷积操作。
此外,图神经网络也可以通过注意力机制来实现,因此还有一种叫做双曲注意力机制网络的方法。这种方法允许在双曲空间中引入一定程度的注意力机制,以提升网络表示能力。注意力机制使得在迭代或消息传递过程中,不同节点特征对结果产生显著影响,这一点至关重要。
关于双曲卷积神经网络,它需要将原始数据特征中的长特征嵌入到低维的双曲流形中,通常采用庞加莱球模型来实现点嵌入。在此过程中,需要考虑与传统欧式距离或球面距离不同的双曲距离,该距离由 arcosh 函数定义。
双曲图卷积神经网络 Hyperbolic GCN
完成这些准备后,可以对数据特征进行双曲嵌入。在处理时,双曲图神经网络会利用麦比乌斯线性变换来实现特征加和。具体来说,对于一个特征,其麦比乌斯线性层可定义为 W 和 x 之间的叉积,通过 x 在 W 上的投影以及 Wx 单位化相结合来完成这种变换。其中,W 是可学习参数矩阵,而 x 则是原始数据中特征向量构成的矩阵。此外,负曲率作为一种特殊属性,会被用来规范化计算,从而定义麦比乌斯线性变换层。
通过有效地组合这些线性变换层,就能实现数据嵌入和卷积操作,并将这些卷积层整合进传统神经网络结构中,从而形成完整的双曲卷积神经网络模型。
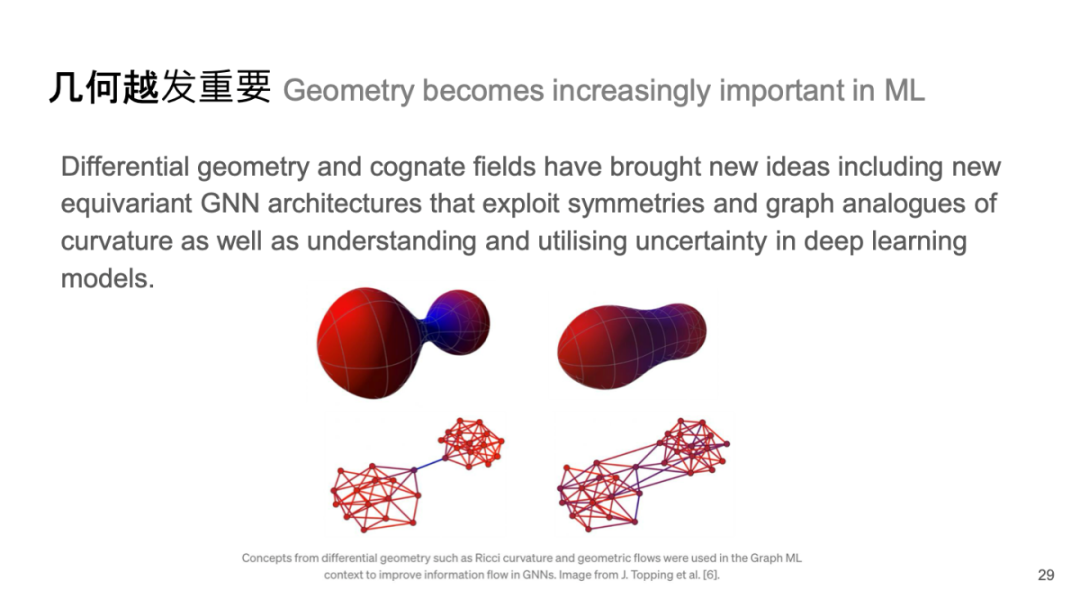
几何越发重要 Geometry becomes increasingly important in ML
未来在人工智能领域有几个可能的发展趋势。尽管大模型备受关注,但几何学仍然发挥着至关重要的作用,特别是微分几何的重要性日益凸显。微分几何及其相关领域将为几何深度学习带来新的思路,例如等变图神经网络(Equivariant Graph Neural Networks, EGNN)架构,这一重点在于考虑几何推断和神经消息传递过程中的不变特性。
等变图神经网络是一种特殊类型的图神经网络,旨在保持输入数据在某些对称性变换下的特征不变或一致。具体来说,这类网络通过设计使得节点和边的表示能够在进行旋转、平移或其他几何变换时保持相应的不变性,从而更好地捕捉图结构中的重要信息。
在数学上,“等变”指的是系统对于某些操作具有一致性的响应,即如果输入发生了变化,输出也会以可预测的方式变化。这一性质特别适用于处理物理系统、分子结构等领域,因为这些对象通常具有固有的对称性。
利用对称性和曲率等图形结构,可以更好地理解深度学习模型中的不确定性。例如,通过最优传输理论或表示学习中微分几何的曲率关系,我们可以发展出双曲卷积神经网络。离散微分几何相较于传统整体和连续微分几何更具挑战性,目前也受到数学大师如丘成桐的关注。
离散微分几何作为一种自然工具,将有效应用于图神经网络,因为数据本身是离散的。此外,前两年ICLR最佳提名奖颁发给了借助里奇流和里奇曲率理论,解决图神经网络中的过度挤压问题,并减轻负面效应的工作[7]。未来,离散曲率有望与其他结构和拓扑问题相结合,从而设计出全新的神经网络。
过度挤压问题指对于依赖于远程节点之间相互作用表示的消息传递网络,非相邻节点的信息需要被传播并压缩成固定大小的向量,并导致信息被过度挤压的现象。
消息传递仍是主要范例 Message passing is still the dominant paradigm
此外,消息传递机制在深度学习中依旧是一个重要趋势,自 2016 年谷歌团队提出以来,它已被广泛应用,并揭示了特征传递过程中的细节。这种机制未来可能与不同类型的几何结合,以克服现有瓶颈问题,如过光滑或过度挤压现象。我认为未来在与不同类型的几何结合时,将会有很大的帮助。刚才我们提到过图形或神经消息传递,甚至更广泛的概念。
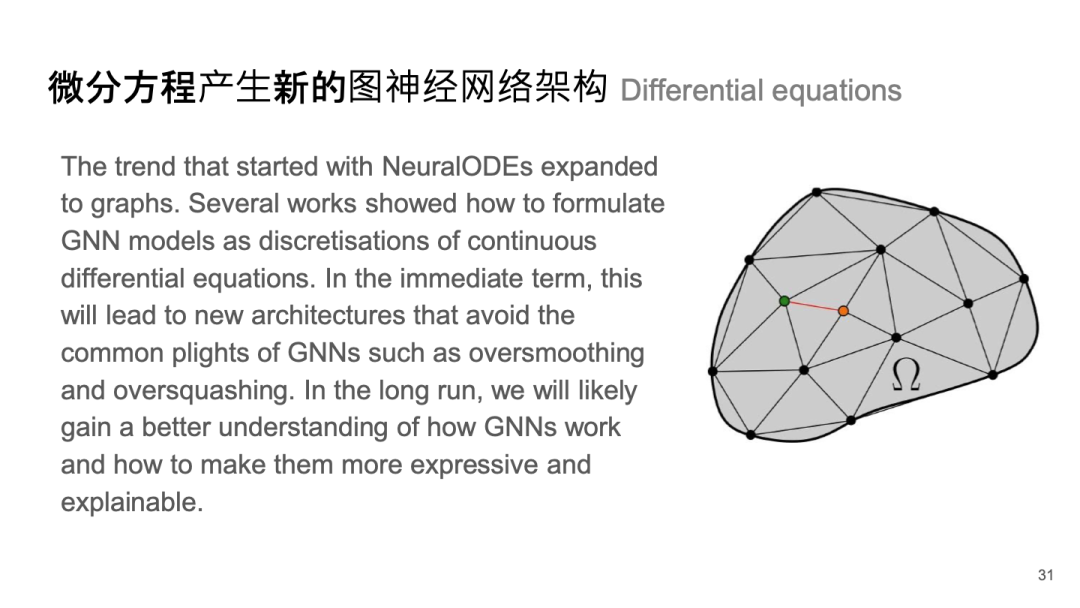
微分方程产生新的图神经网络架构 Differential equations
可以将单纯复形神经消息传递机制视为一个方程。当这个方程与其他元素结合时,会产生多种类型的消息传递,以克服原有消息传递中的一些瓶颈问题,例如过于光滑或过度挤压的问题。
相信未来这一领域还会进一步发展,特别是它可能与神经常微分方程(ODE)求解器相结合,从而实现快速和高效的图神经网络推断,并且能够使网络变得更加深层次。
信号处理、神经科学、物理学思想获新生 Signal Processing,Neuroscience, and Physics get a new life
信号处理方面,脑科学和神经科学的一些机制也可应用到图信号处理中,与傅里叶分析等经典方法结合,将推动新型图神经网络的发展。
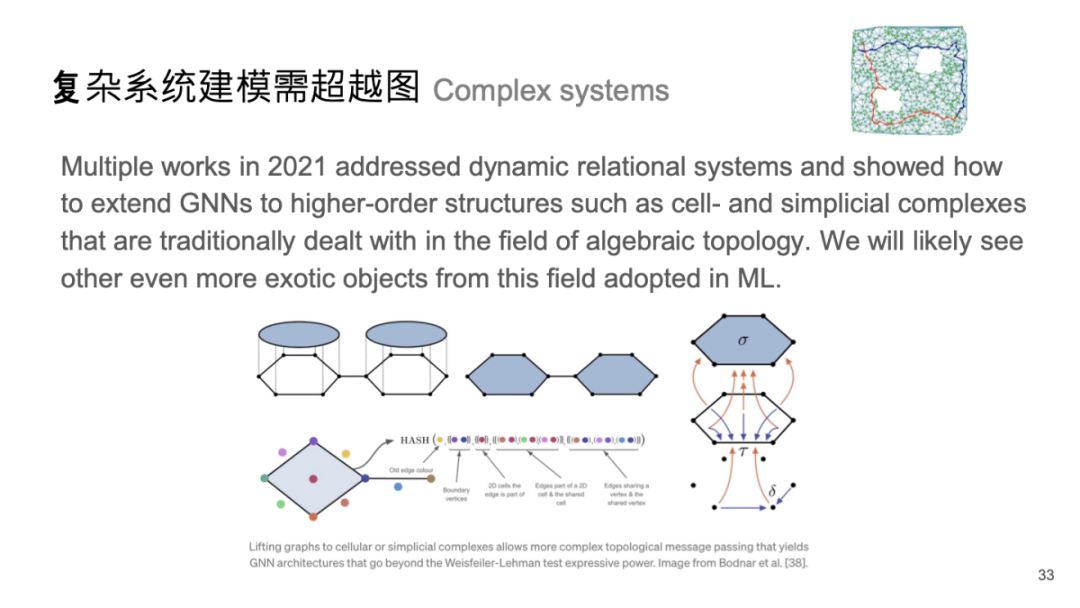
复杂系统建模需超越图 Complex systems
同时,高阶复杂的拓扑数据分析与离散微分几何相结合,有望产生创新性的结构设计。此外,利用更复杂的几何结构以及拓扑数据分析进行几何深度学习,也是当前及未来非常热门的方向。在图消息传递中实现高效拓扑,以及将离散微分几何、拓扑分析中的前沿工具(如范畴论、路径拓扑、单纯复形等)与主干网络结合,是一个值得关注的创新点,可能会出现更有效的结构设计。
例如,在传统材料设计中,通常只考虑材料内部分子的某些结构特征,而忽略了原子之间相互作用的力场效应。如何将这种力场信息纳入图生成网络的推断是一个复杂的问题,因为力场是一个连续且整体的量,需要在微观消息传递机制中加以考虑。
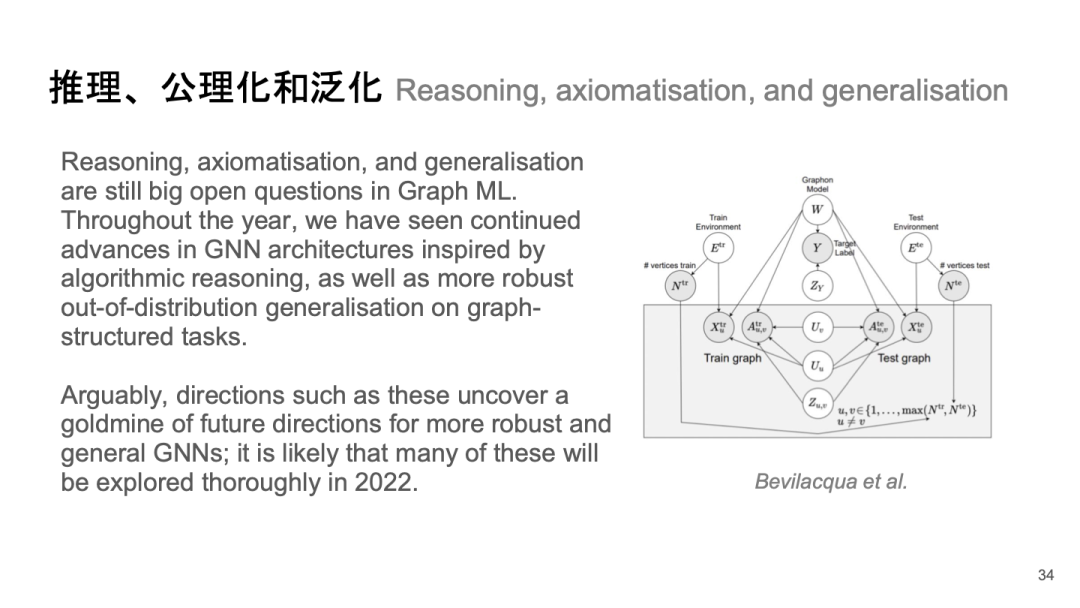
推理、公理化和泛化 Reasoning, axiomatisation, and generalisation
之前提到,可以利用范畴论或其他抽象代数和逻辑方法来实现公理化或泛化,这也是值得关注的一点。
强化学习与图结合 Graphs become popular in RL
此外,近两年也有一些与强化学习结合的新工具,例如如何将图与强化学习中的全局变化和局部变化机制相结合,这可以在一定程度上增强消息传递和深度学习的效果,从而促进几何在强化学习中的应用。
感兴趣的朋友可以观看相关分享——图神经网络与组合优化:1.组合优化问题的机器学习求解(https://pattern.swarma.org/study_group_issue/483)。并且,社区成员整理成笔记,供大家学习人工智能前沿:组合优化问题的机器学习求解 | 范长俊分享整理
几何与图机器学习助力药物发现和设计 Drug Discovery
自 2021 年以来,图神经网络与蛋白质工程之间的联系日益紧密,尤其是在 AlphaFold 2 问世后,引发了大家对这一领域的广泛关注,并认为其能够在药物设计领域做出重大贡献。通过图神经网络方法,可以有效地为大分子或小分子的设计提供支持。这种图神经网络能够将生化信息和特征整合进推断机制中。
在过去几年里,这一领域得到了广泛探索,不仅涉及人工智能,还包括生物医药等科学领域,相关文献层出不穷。例如,黄老师在这一方面也有突出贡献,他们利用图神经网络进行抗体设计[8],并获得了前几年的 ICLR 最佳论文奖。在国内,该领域已有不少优秀研究成果。
量子机器学习 Quantum ML
此外,还有一些前沿方向,如量子机器学习的整合,目前尚未完全实现。具体来说,就是如何将图机器学习的思想融入量子机器学习,以加速其推断过程,以及如何在量子计算机上实现这些网络。这些问题都值得深入探讨,目前相关研究仍较少,但未来几年可能会出现突破。
参考文献
1. BRUNA J, SZLAM A, LECUN Y. Learning stable group invariant representations with convolutional networks[M. arXiv, 2013. http://arxiv.org/abs/1301.3537. DOI:10.48550/arXiv.1301.3537.
2. DEFFERRARD M, BRESSON X, VANDERGHEYNST P. Convolutional neural networks on graphs with fast localized spectral filtering[C//Advances in Neural Information Processing Systems: 卷 29. Curran Associates, Inc., 2016. https://proceedings.neurips.cc/paper_files/paper/2016/hash/04df4d434d481c5bb723be1b6df1ee65-Abstract.html.
3. BERG R van den, KIPF T N, WELLING M. Graph convolutional matrix completion[M. arXiv, 2017. http://arxiv.org/abs/1706.02263. DOI:10.48550/arXiv.1706.02263.
4. GIOVANNI F D, ROWBOTTOM J, CHAMBERLAIN B P, et al. Graph neural networks as gradient flows[J. 2022. https://openreview.net/forum?id=0IywQ8uxJx.
5. BODNAR C, FRASCA F, WANG Y, et al. Weisfeiler and lehman go topological: Message passing simplicial networks[C//Proceedings of the 38th International Conference on Machine Learning. PMLR, 2021: 1026-1037. https://proceedings.mlr.press/v139/bodnar21a.html.
6. CHAMI I, YING R, RÉ C, et al. Hyperbolic graph convolutional neural networks[M. arXiv, 2019. http://arxiv.org/abs/1910.12933. DOI:10.48550/arXiv.1910.12933.
7. J, DI GIOVANNI F, CHAMBERLAIN B P, et al. Understanding over-squashing and bottlenecks on graphs via curvature[M. arXiv, 2022 http://arxiv.org/abs/2111.14522. DOI:10.48550/arXiv.2111.14522.
8. KONG X, HUANG W, LIU Y. Conditional antibody design as 3D equivariant graph translation[C//The Eleventh International Conference on Learning Representations. 2022. https://openreview.net/forum?id=LFHFQbjxIiP.
拓扑编织着复杂世界,机器学习孕育着技术奇点。一个维度,其中拓扑理论与深度学习模型交织共鸣;一个领域,它跨越了数学的严谨与本质以及人工智能的无限可能,开辟着通往科学新纪元的航道。让我们携手在几何深度学习的起点出发,一路探索如何走向AI for Science的无限未来。
集智俱乐部联合中国人民大学黄文炳副教授、上海交通大学王宇光副教授和南洋理工大学夏克林副教授发起「几何深度学习」读书会。从2024年7月11日开始,每周四19:00-21:00进行,持续时间预计 8-10 周,社区成员将一起系统性地学习几何深度学习相关知识、模型、算法,深入梳理相关文献、激发跨学科的学术火花、共同打造国内首个几何深度学习社区!欢迎加入社区与发起人老师一起探索!
![]()
6. 加入集智,一起复杂!