NIS(神经信息压缩器,英文为:Neural Information Squeezer,简称NIS)是一个以解决因果涌现辨识问题为目的的神经网络框架[1]。它由编码器、解码器、动力学学习器三部分组成,其中编码器、解码器共享同一个可逆神经网络。NIS可以通过微观状态时间序列的输入、训练后输出粗粒化策略、宏观动力学、最优建模尺度,并判断是否存在因果涌现。NIS框架可以被视为一个压缩信道,通过投影操作在中间进行信息压缩。这种压缩信息通道通过约束粗粒化策略,将复杂的微观状态映射到简单的宏观状态,从而定义了有效的粗粒化策略和宏观态。通过理论推导可以证明一系列数学结论,例如:通过神经网络的训练过程,宏观动力学的互信息可以逐渐逼近真实数据中微观态在一个时间步内的互信息I(Xt+1; Xt),并且这种逼近程度会随着宏观态维度的增加而减少。验证其性质的实验包括带测量噪声的弹簧振子模型、简单布尔网络等。NIS整体目标在于最大化有效信息,但NIS只通过维度参数寻优的方式部分实现了这一优化目标,关于这一问题更彻底的解决衍生出了NIS+框架。NIS展示了在时间序列数据中发现宏观动力学、粗粒化策略和因果涌现的理论性质和应用潜力。
研究领域:复杂系统,涌现,有效信息,因果涌现,机器学习
刘佳睿 | 作者
张江、王志鹏、刘凯威 | 整理&审校
1.1因果涌现的识别
1.2标准化流技术
1.3可逆神经网络技术
1.4最大化EI
2.1数学定义
2.2神经网络框架
3.1基本概念
3.1.1微观动力学
3.1.2微观态
3.1.3 维粗粒化策略
3.1.4宏观动力学
3.1.5有效粗粒化策略
3.1.6有效宏观动力学
3.2最大化有效信息
4.1编码器
4.1.1ψ
4.1.2投影操作
4.1.3合成
4.2动力学学习器
4.3解码器
4.4使用可逆神经网络的原因
4.5两步优化
4.5.1训练一个预测器
4.5.2选择一个最优的尺度
5.1压缩信道理论
5.1.1信息压缩的信息瓶颈
5.2训练过程的变化
5.2.1模型的互信息与数据的互信息接近
5.2.2信息瓶颈是编码器的下界
5.3有效信息主要由粗粒化函数决定
5.3.1宏观动力学有效信息的数学表达式
5.4互信息随尺度的变化
5.4.1如果模型训练良好,宏观动力学的互信息不会发生变化
5.4.2信道越窄互信息越小
6.1带测量噪声的弹簧振荡器
6.2简单马尔可夫链
6.3简单布尔网络
8.1NIS的优点
8.2NIS的缺点
8.3未来展望:NIS+框架
1.1 因果涌现的识别
尽管已经存在许多跨时间和空间尺度的因果涌现的具体例子[2],但是传统方法需要预先指定粗粒化方案和微观动力学的马尔科夫转移矩阵。因此,我们仍然需要一种仅从数据中识别因果涌现的方法,同时找到最优的粗粒化策略和宏观动力学。解决这一问题的困难主要在于,需要一种方法来系统地、自动地搜索所有可能的粗粒化策略(函数、映射),从而得到宏观动力学,以及判断因果涌现。但搜索空间是微观和宏观之间所有可能的映射函数,体量非常巨大。为了解决这个问题,Klein 等人重点研究了具有网络结构的复杂系统,将粗粒化问题转化为节点聚类,即找到一种方法将节点分组,使得簇级别的连接比原始网络具有更大的有效信息。虽然该方法假设底层节点动态是扩散(随机游走)的,它还是被广泛应用于各个领域之中。同时,现实世界中的的复杂系统具有更丰富的节点动力学。对于一般的动态系统,即使我们给定节点分组,粗粒化策略仍然需要考虑如何将簇中所有节点的微观状态映射到簇的宏观状态,也需要在巨大的粗粒化策略函数空间上进行繁琐的搜索。详细方法请参看:复杂网络中的因果涌现
当我们考虑所有可能的粗粒化策略时,另一个难点是如何避免平凡粗粒化策略的出现,即粗粒化策略过于压缩,导致无效的宏观动力学。例如一种可能的粗粒化策略是将所有微观状态的值映射到一个常数值的宏观状态。这样,系统的宏观动力学就只是一个恒等映射,它将具有较大的有效信息 (EI) 度量。但这种方法不能称为因果涌现,因为所有信息都被粗粒化方法本身抹去了。因此,我们必须找到一种方法来排除这种平凡解。这些困难阻碍了基于有效信息的因果涌现理论的发展和应用。
另一种因果涌现是基于信息分解的因果涌现理论,该理论也提供了一种从数据中识别因果涌现的方法[3]。虽然这种方法可以避免对粗粒化策略的讨论,但是如果我们想获得精确的结果,也需要在系统状态空间的各种可能的子集上进行搜索,这将会在大规模的系统上遭遇指数爆炸难题。此外,Rosas提出的数值近似方法只能提供因果涌现的充分条件,而不是必要条件。同时,该方法依赖于研究者给出明确的粗粒化策略和相应的宏观动力学,这在实际中往往是非常困难的。上述两种方法的另一个共同缺点是需要一个明确的宏观和微观动力学的马尔可夫转移矩阵才可以从数据中估计转移概率。因此,上述方法对罕见事件概率的预测将产生几乎无法避免的、较大的偏差,尤其对于连续数据。
近年来,基于神经网络的机器学习方法取得了进展,并催生了许多跨学科应用[4][5][6][7]。借助此方法,以数据驱动的方式自主发现复杂系统的因果关系甚至动力学成为可能。机器学习和神经网络还可以帮助我们找到更好的粗粒化策略。如果将粗粒化映射视为从微观状态到宏观状态的函数,那么人们显然可以用参数化的神经网络来近似这个函数。这些技术也能帮助我们从数据中发现宏观层面的因果机制。
1.2 标准化流技术
标准化流(Normalizing Flows,NF)是一类通用的方法,它通过构造一种可逆的变换,将任意的数据分布px(x)变换到一个简单的基础分布pz(z),因为变换是可逆的,所以x和z是可以任意等价变换的。之所以叫Normalizing Flows,是因为它包含两个概念:
• 标准化(normalize):它可以将任意的复杂数据分布标准化为一个特定的分布(例如正态分布),类似于数据预处理中常用的对数据进行0均值1方差的标准化,但是更一般的标准化要精细很多;
• 流(Flows):数据的分布可以非常的复杂,需要多个同样的操作组合来达到标准化的效果,这个组合的过程称为流。
需要说明的是,因为分布间是可以相互变换的,因此对基础分布没有特定的限制,不失一般性,可以使用标准分布(单高斯)分布作为基础分布。另外,在本文中,我们回避使用先验分布(prior distribution)来称呼这个基础分布,是因为这里的变量z和其他场合下的隐变量不同,在标准化流模型中,一旦x确定了,z也随之确定下来,不存在随机性,也没有后验概率这一说法,所以不能称其为隐变量。
王磊、尤亦庄等由标准化流技术提出了使用神经网络来对数据进行重整化的技术,并提出了神经重整化群的技术方案,并将其应用到图像生成、量子场论和宇宙学之中。给定一组图像,或一个场论的模拟数据,训练一个基于流的分层深度生成神经网络模型,这样,神经网络就能开发出最优的重整化群变换。标准化流模型和NIS在某些方面具有相似性。它们都致力于使用可逆神经网络(INN)将复杂的微观状态s映射到更简单的宏观状态S,即粗粒化过程。在这种粗粒化之后,二者都试图通过优化某损失函数L(s,S),从而提取出系统中重要的宏观状态特征。这种方法可以帮助理解复杂系统中的涌现现象,在数据建模和分析中有较大应用潜力。
但是与标准化流不同的是,NIS还需要在宏观拟合宏观动力学,因此NIS考虑的是一种动力学过程,而标准化流是一种不包含动力学的生成式模型。
1.3 可逆神经网络技术
可逆神经网络(INNs)是一种特殊的神经网络,它的设计允许网络从输出精确地重建输入。这种可逆性使其在一些任务中非常有用,例如无损数据压缩、生成模型和概率密度估计。INNs 的关键特性是网络的每个转换都可以精确反向,因此,可以通过输出推导出对应的输入。
可逆神经网络与传统的神经网络不同,传统神经网络通常是不可逆的,即输入经过一系列复杂的非线性变换后,无法通过简单的反向操作恢复初始输入。而可逆神经网络通过特殊的结构设计,保证了每个变换都是双向的。例如,Real NVP(非线性卷积层叠网络)和基于耦合层的可逆模型是目前应用较为广泛的可逆神经网络结构。Real NVP 通过将输入分为两部分,使用一部分输入来调整另一部分,从而保证网络整体的可逆性。
在实际应用中,可逆神经网络被广泛用于生成对抗网络(GANs)、图像生成以及强化学习等领域。它们的可逆性不仅降低了计算复杂度,还提高了模型的可解释性,因为它可以精确地追踪输入如何影响输出。
尽管可逆神经网络有许多优势,它们的设计和训练过程仍然面临挑战,如网络结构的复杂性和训练稳定性等问题。然而,随着研究的深入,可逆神经网络正逐步成为解决高维数据处理和概率密度估计问题的强大工具。
1.4 最大化EI
2013年,Erik Hoel和他的团队首次提出了因果涌现理论[8],使用有效信息(Effective Information, EI)来量化离散马尔科夫动力学系统的因果涌现。在文献[8]中,作者在布尔网络实例上,通过对其进行空间、时间以及时空粗粒化都验证了因果涌现的发生,即“宏观打败微观”。
这里需要强调的是论文中指出找到的宏观动力学都是对应有效信息最大的粗粒化方案。然而该论文没有给出如何找到有效信息最大化的粗粒化方法。NIS框架的提出就是为了尝试解决如何最大化有效信息这一过程,从而识别出系统中能否发生因果涌现的。
NIS是一种将复杂系统数据驱动建模和因果涌现两种任务集于一体的数学优化框架以及神经网络框架[9]。NIS面对的问题是,给定一组复杂系统运行表现的时间序列数据xt,例如一组fMRI的时间序列数据,或者一组鸟群的飞行轨迹,或者一组由生命游戏元胞自动机生成的图片序列,我们需要找到它的微观动力学、宏观动力学,以及如何从微观动力学映射为宏观动力学的粗粒化策略,并最终判断出该组数据所反映的真实复杂系统是否发生了因果涌现。
2.1 数学定义
NIS定义了一个泛函优化问题,即通过寻找一组函数,使得宏观动力学的有效信息能够被最大化,从而实现上述问题的解决。这一问题可以表述为:
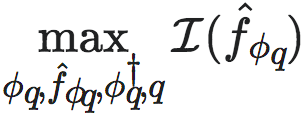
其中 是维度平均有效信息的度量(参考有效信息);ϕq是一种有效的粗粒化策略,它可以把任意的微观态xt映射到宏观态yt;
是维度平均有效信息的度量(参考有效信息);ϕq是一种有效的粗粒化策略,它可以把任意的微观态xt映射到宏观态yt; 是一种有效的宏观动力学,其中q是宏观态的维度,是一个超参;
是一种有效的宏观动力学,其中q是宏观态的维度,是一个超参; 是反粗粒化函数,它的作用和ϕ相反,可以把宏观态yt映射到微观态xt。
这里所谓的有效的粗粒化策略、宏观动力学的含义是指能够满足如下约束条件:
是反粗粒化函数,它的作用和ϕ相反,可以把宏观态yt映射到微观态xt。
这里所谓的有效的粗粒化策略、宏观动力学的含义是指能够满足如下约束条件:

其中,ϵ为一个很小的数作为超参。这样,NIS的数学框架需要在所有可能的有效粗粒化策略和宏观动力学中优化有效信息。
该定义与近似因果模型的抽象[8]存在许多相似之处。
2.2 神经网络框架
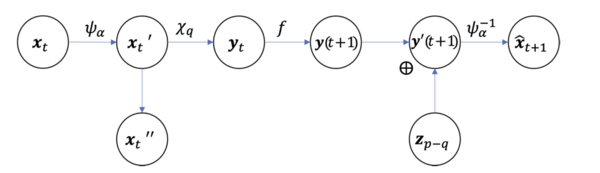
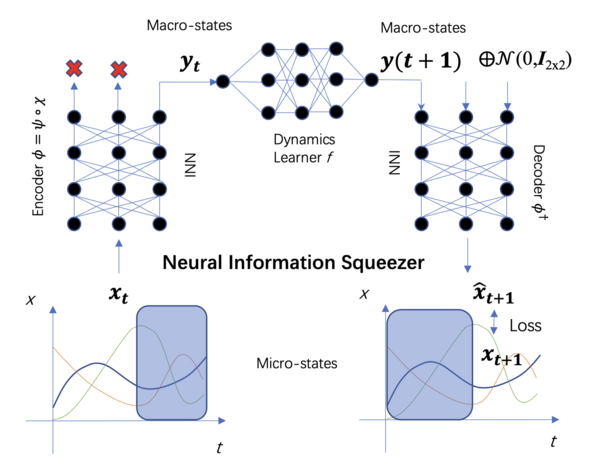
为了解决上述优化问题,NIS提出了一种神经网络架构,从而可以进行数值求解,该网络架构的示意图如下所示:
作为神经网络框架,NIS本质上是一个隐空间动力学学习框架。其中包括编码器、动力学学习器与解码器,可以由微观状态的时间序列输入、经训练后输出如下四个部分:
• 尺度M下的粗粒化策略(由可逆神经网络INN表示);
• 尺度M下的宏观动力学(由动力学学习器得出);
• 最优建模尺度q(由遍历得出最优维数);
• 判断:是否存在因果涌现(当最优尺度下的有效信息EIM∗大于最微观尺度下的有效信息EIm时判断存在因果涌现)。
在NIS中,解码器和编码器都使用了可逆神经网络,这样做的好处是,其解码器可由编码器逆转得到,且可以自上而下地从解码器配合随机采样的数据生成微观态细节,属于生成模型的一种。
接下来,我们将通过数学定义,详细描述NIS框架的基本概念和优化问题。
3.1 基本概念
3.1.1 微观动力学
 (1)
其中
(1)
其中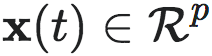 是系统的微观状态,
是系统的微观状态, 是一正整数,表示微观态的维度,ξ 是一随机噪声,通常满足高斯分布。
不失一般性,微观动力学 g 总是马尔可夫的,可以等效地建模为条件概率 Pr(x(t+dt)|x(t)) 。
是一正整数,表示微观态的维度,ξ 是一随机噪声,通常满足高斯分布。
不失一般性,微观动力学 g 总是马尔可夫的,可以等效地建模为条件概率 Pr(x(t+dt)|x(t)) 。
3.1.2 微观态
动力系统状态(式1)xt 的每一个样本称为时间步 t 的一个微观状态。以相等间隔和有限时间步长 T 采样的多变量时间序列x1,x2,···,xT 可形成微观状态时间序列。
如果我们需要以数据驱动的方式重构微观动力学g,则需要大量可观测的微观状态时间序列xt,但在噪声较强时,我们很难从微观状态中重建具有强因果特性的信息丰富的动力学。因果涌现的基本思想是,若忽略微观状态数据中的部分信息并将其转换为宏观状态时间序列,则可以重建一个具有更强因果效应的能描述系统演化的宏观动力学。
3.1.3 q 维粗粒化策略
从微观态到宏观态的信息转化过程即为粗粒化策略(或映射方法)。在宏观状态的维数为 0<q<p∈Z+ 的情况下,q 维粗粒化策略是一个连续可微函数,用于将微观状态 映射到宏观状态 。该粗粒化可以表示为 ϕq。
复杂系统经过粗粒化得到一个新的宏观状态时间序列数据,表示为 y1=ϕq(x1),y2=ϕq(x2),···,yT=ϕq(xT) 。
。该粗粒化可以表示为 ϕq。
复杂系统经过粗粒化得到一个新的宏观状态时间序列数据,表示为 y1=ϕq(x1),y2=ϕq(x2),···,yT=ϕq(xT) 。
3.1.4 宏观动力学
接着,我们需要寻找另一个动力学模型(或马尔可夫链)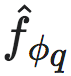 来描述宏观状态 yt 的演变,即宏观动力学。对于给定的宏观状态时间序列 ,y1,y2,···,yT ,宏观状态动力学是一组微分方程:
来描述宏观状态 yt 的演变,即宏观动力学。对于给定的宏观状态时间序列 ,y1,y2,···,yT ,宏观状态动力学是一组微分方程:
 (2)
(2)
其中y∈Rq为宏观态, ξ′∈Rq 是宏观状态动力学中的噪声,是连续可微函数,可通过最小化方程2在任何给定的时间步长 t∈[1,T] 和给定的向量范数‖⋅‖ 下的解来得到:
 (3)
此框架不能排除一些平凡解。例如,假设对于 ∀yt∈Rp , q=1 维的 ϕq 定义为 ϕq(xt)=1 。因此,相应的宏观动力学只是 dy/dt=0 和 y(0)=1。由于宏观状态动力学是平凡的,粗粒化映射过于随意,此方程无意义。因此,必须对粗粒化策略和宏观动力学设置限制以避免平凡解和动力学。
(3)
此框架不能排除一些平凡解。例如,假设对于 ∀yt∈Rp , q=1 维的 ϕq 定义为 ϕq(xt)=1 。因此,相应的宏观动力学只是 dy/dt=0 和 y(0)=1。由于宏观状态动力学是平凡的,粗粒化映射过于随意,此方程无意义。因此,必须对粗粒化策略和宏观动力学设置限制以避免平凡解和动力学。
3.1.5 有效粗粒化策略
为了规避上述平凡解的问题,NIS提出了有效粗粒化策略和有效宏观动力学的概念。
其中,所谓的有效粗粒化策略应是一个从微观态到宏观态可以尽量多地保存微观态信息的压缩映射。
如果存在一个函数 ,使得对于给定的小实数ε和给定的向量范数‖⋅‖,以下不等式成立,则 q 维粗粒化策略ϕq:Rp→Rq是ϵ有效的:
,使得对于给定的小实数ε和给定的向量范数‖⋅‖,以下不等式成立,则 q 维粗粒化策略ϕq:Rp→Rq是ϵ有效的:
 (4)
这里的
(4)
这里的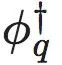 即为与ϕq相应的反粗粒化策略,如果使用可逆神经网络技术建模ϕq,且如果p=q,则
即为与ϕq相应的反粗粒化策略,如果使用可逆神经网络技术建模ϕq,且如果p=q,则 。
。
3.1.6 有效宏观动力学
同时,由上面导出的宏观动力学也是ϵ有效的(其中y(t) 是式2的解)。即对于所有t=1,2,···,T:
 (5)
(5)
可以通过重构微观状态时间序列,使得宏观状态变量尽可能多地包含微观状态的信息。
3.2 最大化有效信息
为了找到上述各个函数,即有效粗粒化和有效的宏观动力学,NIS提出通过最大化有效信息(EI)来进行求解。
因此,最优的粗粒化策略和宏观动力学可以表述为:在约束方程4和5下,最大化宏观动力学的有效信息,即:
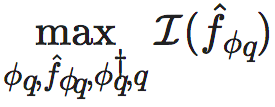 (6)
其中是有效信息的度量(这里,因为所有变量都是连续型实数变量,故而NIS使用的是维度平均的有效信息,即dEI,详情请参考有效信息,以及文献[1])。ϕq 是一种有效的粗粒化策略,是一种有效的宏观动力学。
(6)
其中是有效信息的度量(这里,因为所有变量都是连续型实数变量,故而NIS使用的是维度平均的有效信息,即dEI,详情请参考有效信息,以及文献[1])。ϕq 是一种有效的粗粒化策略,是一种有效的宏观动力学。
NIS是一种新的机器学习框架,基于可逆神经网络来解决式6中提出的问题。该框架由三个组件组成:编码器、动力学学习器和解码器。它们分别用神经网络 ψα,fβ, 和 来实现,其中这些神经网络的参数分别为α,β 和α 。整个框架如下图所示。接下来将分别描述每个模块。
来实现,其中这些神经网络的参数分别为α,β 和α 。整个框架如下图所示。接下来将分别描述每个模块。
4.1 编码器
首先,编码器又是由可逆函数ψ与投影操作χ两部分构成。
4.1.1 ψ
这里ψ是一个从Rp 到 Rp的可逆函数,它建模了粗粒化过程中,信息转换的操作。由于函数是可逆的,因此,这一步仅仅做信息转换,而不损失任何信息。
4.1.2 投影操作
投影算子χp,q 是一个从Rp 到 Rq的函数,表达为
其中⨁是向量拼接(concatenate)算符,χq∈Rq,χp−q∈Rp−q。 χp,q可简写为χq。
4.1.3 合成
这样,编码器(ϕ)将微观状态xt映射到宏观状态yt,分为两个步骤:
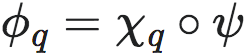 (8)
(8)
其中 表示函数复合运算。
第一步是从 到
表示函数复合运算。
第一步是从 到 的双射(可逆)映射ψ:Rp→Rp,等价于向量在高维空间中的旋转,只改变向量与坐标轴的角度,不改变模长,无信息丢失,该过程可以由可逆神经网络实现;第二步是通过将 映射到
的双射(可逆)映射ψ:Rp→Rp,等价于向量在高维空间中的旋转,只改变向量与坐标轴的角度,不改变模长,无信息丢失,该过程可以由可逆神经网络实现;第二步是通过将 映射到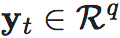 ,丢弃p−q维上的信息,将得到的向量投影到q维。
,丢弃p−q维上的信息,将得到的向量投影到q维。
4.2 动力学学习器
动力学学习器 fβ 是一个带有参数的常见前馈神经网络,它在宏观层面上学习有效的马尔可夫动力学。用 fβ 替换方程2中的,并使用 dt=1 的欧拉方法求解方程 (2)。假设噪声是高斯分布(或拉普拉斯分布),则可以将方程5简化为:
 (9)
(9)
其中,ξ′∼N(0,Σ) 或 Laplacian(0,Σ),  是协方差矩阵,σi 是第 i 维度的标准差(可以学习或固定)。因此,该动力学的转移概率可被写作:
是协方差矩阵,σi 是第 i 维度的标准差(可以学习或固定)。因此,该动力学的转移概率可被写作:
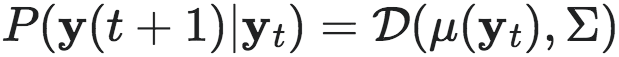 (10)
(10)
其中,D 指表示高斯分布或拉普拉斯分布的概率密度函数,μ(yt)≡yt+fβ(yt) 是分布的均值向量。
通过端到端的方式训练动力学学习器,可以避免从数据中估计马尔可夫转移概率以减少偏差。
4.3 解码器
解码器将宏观状态 y(t+1) 的预测转换为微观状态 的预测。在这个框架中,粗粒化策略 ϕq 可以分解为可逆函数 ψ 和投影器 χq,因此解码器可以直接通过反转 ψ 得到。然而,由于宏观状态的维度是 q,而 ψ 的输入维度是 p>q,因此需要用 p−q 维高斯随机向量填充剩余的 p−q 维。对于任何 ϕq,解码映射可以定义为:
的预测。在这个框架中,粗粒化策略 ϕq 可以分解为可逆函数 ψ 和投影器 χq,因此解码器可以直接通过反转 ψ 得到。然而,由于宏观状态的维度是 q,而 ψ 的输入维度是 p>q,因此需要用 p−q 维高斯随机向量填充剩余的 p−q 维。对于任何 ϕq,解码映射可以定义为:
 (11)
(11)
 (12)
其中,
(12)
其中, 是 p−q 维的高斯随机噪声
是 p−q 维的高斯随机噪声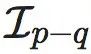 是同维度的单位矩阵。这样可以结合 xq 和一个来自 p−q 维标准正态分布的随机样本 zp−q 生成微观状态。
解码器可以被视为条件概率
是同维度的单位矩阵。这样可以结合 xq 和一个来自 p−q 维标准正态分布的随机样本 zp−q 生成微观状态。
解码器可以被视为条件概率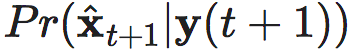 的生成模型[10][11],而编码器执行粗粒化过程(也可以称为重整化Renormalization)。
的生成模型[10][11],而编码器执行粗粒化过程(也可以称为重整化Renormalization)。
4.4 使用可逆神经网络的原因
有多种方法可以实现可逆神经网络[12][13]。这里选择如上图所示的RealNVP模块[14]来具体实现可逆计算。
在该模块中,输入向量x被拆分成两部分并缩放、平移、再次合并,缩放和平移操作的幅度由相应的前馈神经网络调整。s1,s2是用来缩放的共享参数的神经网络,⨂ 表示元素乘积。t1,t2是用来平移的共享参数的神经网络。这样,我们就可以实现从x到y的可逆计算。同一模块可以重复多次以实现复杂的可逆计算。
4.5 两步优化
尽管函数已被神经网络参数化,但由于必须综合考虑目标函数和约束条件,并且超参数 q 会影响神经网络的结构,因此直接优化式6仍然具有挑战性。因此,论文[1]提出了一种两阶段优化方法。在第一阶段,论文固定超参数 q,并优化预测的微观状态和观测数据的差异 (即式4),以确保粗粒化策略 ϕq 和宏观动力学
(即式4),以确保粗粒化策略 ϕq 和宏观动力学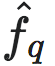 的有效性。此外,NIS通过搜索所有可能的 q 值,以找到有效信息的最大值,也就是最大化。
的有效性。此外,NIS通过搜索所有可能的 q 值,以找到有效信息的最大值,也就是最大化。
4.5.1 训练一个预测器
在第一阶段,NIS使用似然最大化和随机梯度下降技术来获得有效的 q 粗粒化策略和宏观状态动力学的有效预测器。目标函数由微观状态预测的概率定义。
前馈神经网络可以理解为一种用高斯或拉普拉斯分布建模条件概率[15]的机器。因此,整个 NIS 框架可以理解为一个对条件概率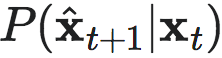 建模的模型,神经网络的输出
建模的模型,神经网络的输出 为此分布的平均值。此外,目标函数方程 14 只是给定分布形式下观测数据的对数似然或交叉熵。
为此分布的平均值。此外,目标函数方程 14 只是给定分布形式下观测数据的对数似然或交叉熵。
 (13)
其中当 l=2 时,
(13)
其中当 l=2 时, ,而当 l=1 时概率分布为
,而当 l=1 时概率分布为 。Σ 是协方差矩阵。Σ 始终是对角矩阵,其幅度为 l=2 时的均方误差或 l=1 时的绝对值平均值。
如果将高斯或拉普拉斯分布的具体形式带入条件概率,将看到最大化对数似然等同于最小化 l 范数目标函数:
。Σ 是协方差矩阵。Σ 始终是对角矩阵,其幅度为 l=2 时的均方误差或 l=1 时的绝对值平均值。
如果将高斯或拉普拉斯分布的具体形式带入条件概率,将看到最大化对数似然等同于最小化 l 范数目标函数:
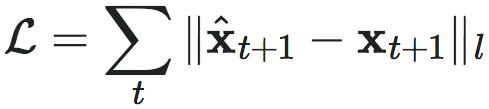 (14)
(14)
其中 l=1 或 2。接下来使用随机梯度下降技术来优化方程14。
4.5.2 选择一个最优的尺度
在上一步中,经过大量的训练周期可以得到有效的 q 粗粒化策略和宏观状态动力学,但训练结果依赖于 q。
为了选择最优的 q,可以比较不同 q 维粗粒化的有效信息度量化。由于参数 q 是一维的,其值范围也有限 (0<q<p),可以简单地迭代所有 q 以找出最优的 q 和最优的有效策略。
使用了可逆神经网络作为编码器的基础以后,NIS框架具备很好地数学分析性质。接下来,这里将展示论文[1]的若干重要定理。
5.1 压缩信道理论
NIS框架可以看作上图所示的信道,由于投影操作的存在,通道在中间被压缩。此为压缩信息通道。这里,xt为输入数据, 为丢弃的数据,yt为宏观态,zp−q为p-q维的正态分布随机数,
为丢弃的数据,yt为宏观态,zp−q为p-q维的正态分布随机数,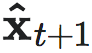 为模型对t+1时刻微观态的预测输出。
为模型对t+1时刻微观态的预测输出。
5.1.1 信息压缩的信息瓶颈
对于上图所示的压缩信道以及任意可逆函数ψ、投影函数 χq、宏观动力学 f 和随机噪声 ,有:
,有:
 (21)
(21)
其中是NIS的预测值,y(t+1)符合式2。
对于任何实现压缩信道示意图中一般框架的神经网络,宏观动力学 fϕq 的互信息与整个动力学模型相同,即对于任意时间从 (xt) 到 () 的映射。此定理是 NIS 中最重要的定理。从这个定理可以看出,实际上,宏观动力学 f 是整个通道的信息瓶颈[16]。
5.2 训练过程的变化
通过信息瓶颈理论,可以直观地理解当神经压缩器框架通过数据进行训练时会发生什么。首先,在神经网络训练过程中,整个框架的输出对任意给定xt都接近于真实数据xt+1,对互信息同理。即如下定理:
5.2.1 模型的互信息与数据的互信息接近
如果 NIS 框架中的神经网络是训练充分的(即对于任何t∈[1,T]训练周期结束时有 和 Prτ(xt+1|xt) 之间的 Kullback- Leibler 散度趋近于 0),那么对于任何t∈[1,T]:
和 Prτ(xt+1|xt) 之间的 Kullback- Leibler 散度趋近于 0),那么对于任何t∈[1,T]:
 (22)
由于微观状态xt的时间序列包含信息,假设互信息I(xt,xt+1) 较大,否则不关注xt。因此,随着神经网络的训练,I(
(22)
由于微观状态xt的时间序列包含信息,假设互信息I(xt,xt+1) 较大,否则不关注xt。因此,随着神经网络的训练,I( ; xt)将增加,直到接近I(xt+1; xt)。根据信息瓶颈理论,I(yt;yt+1)=I(xt; )也将增加,直到接近I(xt+1; xt)。
因为宏观动力学是整个通道的信息瓶颈,其信息必然随着训练而增加。同时,ψ的雅可比矩阵的行列式和yt的熵一般也会增加。
; xt)将增加,直到接近I(xt+1; xt)。根据信息瓶颈理论,I(yt;yt+1)=I(xt; )也将增加,直到接近I(xt+1; xt)。
因为宏观动力学是整个通道的信息瓶颈,其信息必然随着训练而增加。同时,ψ的雅可比矩阵的行列式和yt的熵一般也会增加。
5.2.2 信息瓶颈是编码器的下界
对于上图中的压缩信息信道,ψα的雅可比矩阵的行列式和yt的香农熵的下界是整个信道的信息:
 (23)
(23)
其中H为香农熵测度,Jψα(xt)为双射ψα输入xt 时的雅可比矩阵,Jψα,yt(xt) 为Jψα(xt)在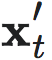 投影yt上的子矩阵。
由于xt的熵是由数据而定的,NIS的互信息性质定理指出 |det(Jψα(xt))|的对数的期望以及yt必然大于整个信道的互信息。
因此,若
投影yt上的子矩阵。
由于xt的熵是由数据而定的,NIS的互信息性质定理指出 |det(Jψα(xt))|的对数的期望以及yt必然大于整个信道的互信息。
因此,若 |det(Jψα(xt))|的初始值和yt很小,随着模型的训练,整个信道的互信息会增加,此时雅可比矩阵的行列式必然增大,宏观态yt也必然更分散。但若信息I(xt, )已逼近I(xt; xt+1),或|det(Jψα(xt))|和H(yt)已足够大,则这些现象可能不会发生。
|det(Jψα(xt))|的初始值和yt很小,随着模型的训练,整个信道的互信息会增加,此时雅可比矩阵的行列式必然增大,宏观态yt也必然更分散。但若信息I(xt, )已逼近I(xt; xt+1),或|det(Jψα(xt))|和H(yt)已足够大,则这些现象可能不会发生。
5.3 有效信息主要由粗粒化函数决定
此前分析的是互信息而非宏观动力学的有效信息(因果涌现的关键要素)。实际上可以借助压缩信道的良好属性写出EI的宏观动力学表达式,但这一表达式没有解析的形式。由此,作者得出确定因果涌现的主要成分是依赖于可逆函数ψα的。
5.3.1 宏观动力学有效信息的数学表达式
假设给定xt下xt+1的概率密度可以通过函数Pr(xt+1|xt)≡G(xt+1,xt)描述,且神经信息挤压框架训练充分,即可通过以下方式计算fβ的宏观动力学信息:
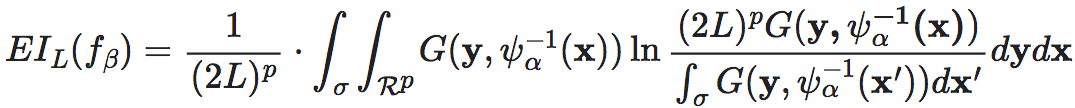 (24)
(24)
其中 σ≡[−L,L]p 是x与x′的积分区间;L是do成均匀分布时,宏观态区间的线性尺度大小,它是一个充分大的给定常数。
5.4 互信息随尺度的变化
由信息瓶颈理论与互信息理论,论文[1]可以推出如下推论:
5.4.1 如果模型训练良好,宏观动力学的互信息不会发生变化
对于训练充分的NIS模型,宏观动力学fβ的互信息将与所有参数(包括刻度q)无关。如果神经网络训练充分,则有关宏观动力学的互信息将接近数据{xt}中的互信息。因此,无论q有多小(或尺度有多大),宏观动力学fβ的互信息都会保持恒定。
由此可得,q是因果涌现的无关参数。但根据EI的定义,较小的q意味着编码器将携带更多有效信息。
5.4.2 信道越窄互信息越小
 (25)
(25)
其中 表示 yt 的q 维向量。
互信息描述了编码器(即在不同维度q中的微型状态xt和宏观状态yt)。该定理指出,随着q减小,编码器部分的互信息必然减小,且对信息限制I(xt; )≃I(xt; xt+1)更接近。因此,整个信道将更加狭窄,编码器必须携带更有用和有效的信息才能转移到宏观动力学,预测变得更加困难。
表示 yt 的q 维向量。
互信息描述了编码器(即在不同维度q中的微型状态xt和宏观状态yt)。该定理指出,随着q减小,编码器部分的互信息必然减小,且对信息限制I(xt; )≃I(xt; xt+1)更接近。因此,整个信道将更加狭窄,编码器必须携带更有用和有效的信息才能转移到宏观动力学,预测变得更加困难。
在几个数据集上测试NIS(所有数据均由模拟动力学模型生成)。此测试还包括连续动力学和离散马尔可夫动力学。
6.1 带测量噪声的弹簧振荡器
 (26)
其中z和v分别是振荡器的一维位置与速度。定义系统状态x=(z,v)。
实验数据仅由两个带误差的传感器获得。假设观测模型为
(26)
其中z和v分别是振荡器的一维位置与速度。定义系统状态x=(z,v)。
实验数据仅由两个带误差的传感器获得。假设观测模型为
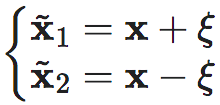 (27)
(27)
其中 是符合二维高斯分布的随机数值,σ 是位置与速度标准差的向量。将状态x理解为潜在宏观状态,测量微观状态
是符合二维高斯分布的随机数值,σ 是位置与速度标准差的向量。将状态x理解为潜在宏观状态,测量微观状态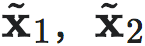 。NIS从测量值中恢复潜在的宏观态xt。
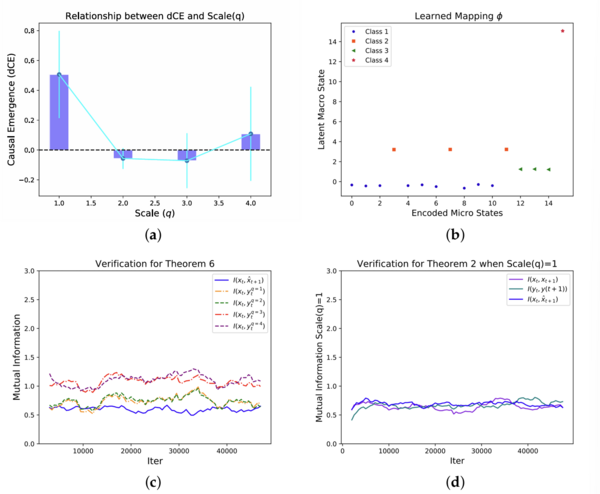
根据式27,影响状态测量的噪音可以通过叠加两通道的数据消除。因此,如果在NIS中输入两个测量值的宏观状态,则可简单地获得正确的动力学。使用Euler方法(dt=1)采样10,000批批次的数据,并在每个批次中生成100个随机初始状态并执行一个步骤动力学,求得下一个时间步长中的状态。使用这些数据来训练神经网络,同时使用相同的数据集来训练具有相同数量参数的普通前馈神经网络以作比较。结果如下图所示。
下一组实验结果验证NIS基本性质的定理和信息瓶颈理论。当 q 取不同值时,I(xt, xt+1)、I(yt, yt+1)和I(
。NIS从测量值中恢复潜在的宏观态xt。
根据式27,影响状态测量的噪音可以通过叠加两通道的数据消除。因此,如果在NIS中输入两个测量值的宏观状态,则可简单地获得正确的动力学。使用Euler方法(dt=1)采样10,000批批次的数据,并在每个批次中生成100个随机初始状态并执行一个步骤动力学,求得下一个时间步长中的状态。使用这些数据来训练神经网络,同时使用相同的数据集来训练具有相同数量参数的普通前馈神经网络以作比较。结果如下图所示。
下一组实验结果验证NIS基本性质的定理和信息瓶颈理论。当 q 取不同值时,I(xt, xt+1)、I(yt, yt+1)和I( 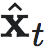 , )的互信息随迭代次数的变化情况,如上图(c)(d)所示,其中所有的互信息的收敛均符合NIS训练过程中有效信息的变化定理。同时绘制不同 q 下的 xt 和 yt 之间的互信息来检验信道与互信息的关系。如上图a部分所示,当 q 增加时,互信息增加。
根据信息瓶颈理论[17],在训练初期宏观变量和输出之间的互信息可能会增加,且输入和宏观变量之间的信息必然在增加后随着训练过程的进行而减少。NIS 模型证实了这一结论(上图b部分),其中宏观状态 yt 和预测 yt+1 都是宏观变量。由于 yt 和 y(t+1) 是瓶颈,而所有其他无关信息都被变量
, )的互信息随迭代次数的变化情况,如上图(c)(d)所示,其中所有的互信息的收敛均符合NIS训练过程中有效信息的变化定理。同时绘制不同 q 下的 xt 和 yt 之间的互信息来检验信道与互信息的关系。如上图a部分所示,当 q 增加时,互信息增加。
根据信息瓶颈理论[17],在训练初期宏观变量和输出之间的互信息可能会增加,且输入和宏观变量之间的信息必然在增加后随着训练过程的进行而减少。NIS 模型证实了这一结论(上图b部分),其中宏观状态 yt 和预测 yt+1 都是宏观变量。由于 yt 和 y(t+1) 是瓶颈,而所有其他无关信息都被变量  弃用,在得到相同结论的情况下,NIS模型的架构可以比一般的神经网络更清楚地反映信息瓶颈。
弃用,在得到相同结论的情况下,NIS模型的架构可以比一般的神经网络更清楚地反映信息瓶颈。
6.2 简单马尔可夫链
本案例展示NIS作用于离散马尔可夫链、粗粒化策略可以作用于状态空间的过程。生成数据的马尔可夫链是以下概率转移矩阵:
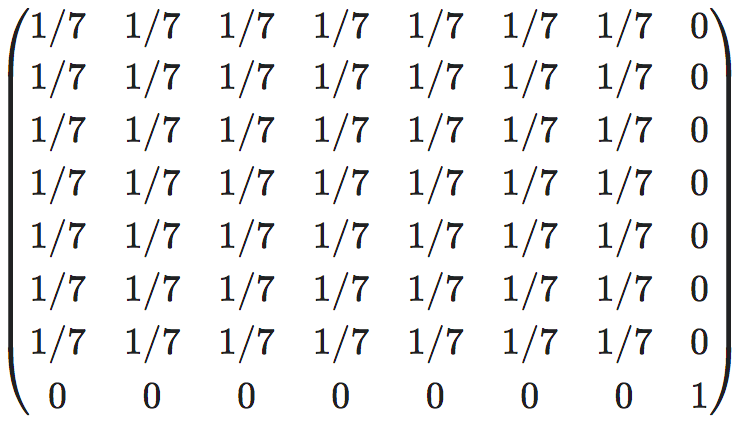 (28)
(28)
该系统有 8 个状态,其中前7个状态之间可以相互转移,最后一个状态是独立的。NIS模型使用一个 one-hot 向量编码状态(例如状态2将表示为 (0,1,0,0,0,0,0,0))。对初始状态进行50,000个批次的采样以生成数据,然后将 one-hot 向量输入 NIS 框架,经过50,000个迭代轮次的训练后可以得到一个有效的模型。结果如上图所示。
通过系统地搜索不同的 q 可以发现维度平均因果涌现(dCE)在 q=1 处达到峰值(上图a部分)。可以通过上图b部分可视化在最佳尺度上的粗粒化策略,其中 x 坐标是不同状态的十进制编码,y 坐标表示宏观状态的编码。粗粒化映射成功地将前七个状态分类为一个宏观状态,同时保持最后一个状态不变。这种学习到的粗粒化策略与文献[14]中的示例相同。
将学习到的宏观动力学可视化(上图c部分)。 yt<0 时宏观动力学是一个线性映射,yt>0 时它可被视为一个常数。因此,该动力学可以保证所有前七个微观状态都可以与最后一个状态分离。上图d部分验证了信息压缩的信息瓶颈定理,即宏观动力学 fϕq 的互信息与整个动力学模型相同。
6.3 简单布尔网络
布尔网络是离散动力系统的典型例子,其中每个节点有两种可能的状态(0 或 1),且节点状态受其相邻节点状态的影响。该网络的微观机制如下:上图是一个包含四个节点的布尔网络的示例,每个节点的状态受到其相邻节点状态组合的概率影响,具体概率见上图中的表格。将所有节点的机制结合后,可以得到一个具有 24=16 个状态的马尔可夫转移矩阵。
通过对整个网络进行 50,000 次状态转换的采样,将这些数据输入 NIS 模型。通过系统搜索不同的 q 值,发现维度平均因果涌现峰值出现在 q = 1 处(上图a部分)。可视化结果显示出粗粒化策略(上图b部分),其中 x 坐标是微观状态的十进制编码,y 坐标表示宏观状态的编码。数据点根据其 y 值可以清晰地分为四个簇,这表明 NIS 网络发现了四个离散的宏观状态。16 个微观状态与四个宏观状态之间存在一一对应关系。然而,NIS 算法在处理此问题时并不知道任何先验信息,包括节点分组方法、粗粒化策略和动力学信息。这个示例验证了信息瓶颈理论(NIS中宏观动力学 fϕq 的互信息与整个动力学模型相同)与信道互信息之间的关系(上图c, d部分)。
本部分在有效信息词条中有详细描述,为NIS框架解决的问题之一。
对于前馈神经网络, 其EI的计算有一些不合理之处:首先EI的计算结果将会受到L的严重影响;其次,如果计算归一化的EI,即Eff,那么会遇到一个问题:对于连续变量来说,其状态空间的元素个数为无穷多个,如果直接使用,势必会引入无穷大量。
此问题的解决方案是,用状态空间维数来归一化EI,从而解决连续状态变量上的EI比较问题,这一指标被称为维度平均的有效信息(Dimension Averaged Effective Information,简称dEI)。在离散的状态空间中,维度平均的EI和有效性指标(Eff)实际上是等价的。在这一定义中L并未消失,但在计算维度平均的因果涌现时,尽管在期望中仍然隐含地包含L,但所有显含L的项就都被消失了。这就展示出来引入维度平均EI的一定的合理性。
8.1 NIS的优点
NIS(神经信息压缩器)是一种新的神经网络框架,可被用于发现时间序列数据中的粗粒化策略、宏观动力学和涌现的因果关系。NIS中可逆神经网络的使用通过在编码器和解码器之间共享参数来减少参数数量,且使得分析 NIS 架构的数学特性更加方便。通过约束粗粒化策略来预测未来微观状态从而让误差小于一定精度阈值,从而定义有效的粗粒化策略和宏观动力学,并推出因果涌现识别问题可以理解为在约束条件下最大化有效信息的问题。
8.2 NIS的缺点
NIS框架的弱点如下。
8.3 未来展望:NIS+框架
为解决这些问题,从NIS框架出发提出NIS+框架。在NIS的基础上,NIS+框架运用了重加权技术,添加了反向动力学、由此产生一个新的损失函数,并对两个损失函数进行加权。其中,新的损失函数产生于神经网框架中添加的部分:通过对t+1时刻再次编码,在宏观上来训练一个反向动力学来去预测t时刻的一个 。将新的损失函数与NIS框架中原有的损失函数加权,可以最大化有效信息的变分下界,解决了NIS框架无法直接最大化EI的问题。
1. Zhang, J.; Liu, K. Neural Information Squeezer for Causal Emergence. Entropy 2023, 25, 26.
2. Hoel, E.P.; Albantakis, L.; Tononi, G. Quantifying causal emergence shows that macro can beat micro. Proc. Natl. Acad. Sci. USA 2013, 110, 19790–19795.
3. Rosas, F.E.; Mediano, P.A.M.; Jensen, H.J.; Seth, A.K.; Barrett, A.B.; Carhart-Harris, R.L.; Bor, D. Reconciling emergences: An information-theoretic approach to identify causal emergence in multivariate data. PLoS Comput. Biol. 2020, 16, e1008289.
4. Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A.; et al. Mastering the game of Go without human knowledge. Nature 2017, 550, 354–359.
5. LeCun,Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444.
6. Reichstein, M.; Camps-Valls, G.; Stevens, B.; Jung, M.; Denzler, J.; Carvalhais, N. Deep learning and process understanding for data-driven Earth system science. Nature 2019, 566, 195–204.
7. Senior, A.W.; Evans, R.; Jumper, J.; Kirkpatrick, J.; Sifre, L.; Green, T.; Qin, C.; Žídek, A.; Nelson, A.W.R.; Bridgland, A.; et al. Improved protein structure prediction using potentials from deep learning. Nature 2020, 577, 706–710.
8. Beckers, S.; Eberhardt, F.; Halpern, J.Y. Approximate Causal Abstraction. arXiv 2019, arXiv:1906.11583v2.
9. Zhang, Jiang. “Neural Information Squeezer for Causal Emergence.” ArXiv (Cornell University), 1 Jan. 2022, https://doi.org/10.48550/arxiv.2201.10154.
10. Li, S.H.; Wang, L. Neural Network Renormalization Group. Phys. Rev. Lett. 2018, 121, 260601.
11. Hu,H.; Wu,D.; You, Y.Z.; Olshausen, B.; Chen, Y. RG-Flow: A hierarchical and explainable flow model based on renormalization group and sparse prior. Mach. Learn. Sci. Technol. 2022, 3, 035009.
12. Teshima, T.; Ishikawa, I.; Tojo, K.; Oono, K.; Ikeda, M.; Sugiyama, M. Coupling-based invertible neural networks are universal diffeomorphism approximators. Adv. Neural Inf. Process. Syst. 2020, 33, 3362–3373.
13. Teshima, T.; Tojo, K.; Ikeda, M.; Ishikawa, I.; Oono, K. Universal approximation property of neural ordinary differential equations. arXiv 2017, arXiv:2012.02414.
14. Dinh, L.; Sohl-Dickstein, J.; Bengio, S. Density estimation using real nvp. arXiv 2016, arXiv:1605.08803.
15. Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114.
16. Shwartz-Ziv, R.; Tishby, N. Opening the black box of deep neural networks via information. arXiv 2017, arXiv:1703.00810.
17. Shwartz-Ziv, R.; Tishby, N. Opening the black box of deep neural networks via information. arXiv 2017, arXiv:1703.00810.
18. Williams, P.L.; Beer., R.D. Nonnegative decomposition of multivariate information. arXiv 2017, arXiv:1004.2515.
。将新的损失函数与NIS框架中原有的损失函数加权,可以最大化有效信息的变分下界,解决了NIS框架无法直接最大化EI的问题。
1. Zhang, J.; Liu, K. Neural Information Squeezer for Causal Emergence. Entropy 2023, 25, 26.
2. Hoel, E.P.; Albantakis, L.; Tononi, G. Quantifying causal emergence shows that macro can beat micro. Proc. Natl. Acad. Sci. USA 2013, 110, 19790–19795.
3. Rosas, F.E.; Mediano, P.A.M.; Jensen, H.J.; Seth, A.K.; Barrett, A.B.; Carhart-Harris, R.L.; Bor, D. Reconciling emergences: An information-theoretic approach to identify causal emergence in multivariate data. PLoS Comput. Biol. 2020, 16, e1008289.
4. Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A.; et al. Mastering the game of Go without human knowledge. Nature 2017, 550, 354–359.
5. LeCun,Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444.
6. Reichstein, M.; Camps-Valls, G.; Stevens, B.; Jung, M.; Denzler, J.; Carvalhais, N. Deep learning and process understanding for data-driven Earth system science. Nature 2019, 566, 195–204.
7. Senior, A.W.; Evans, R.; Jumper, J.; Kirkpatrick, J.; Sifre, L.; Green, T.; Qin, C.; Žídek, A.; Nelson, A.W.R.; Bridgland, A.; et al. Improved protein structure prediction using potentials from deep learning. Nature 2020, 577, 706–710.
8. Beckers, S.; Eberhardt, F.; Halpern, J.Y. Approximate Causal Abstraction. arXiv 2019, arXiv:1906.11583v2.
9. Zhang, Jiang. “Neural Information Squeezer for Causal Emergence.” ArXiv (Cornell University), 1 Jan. 2022, https://doi.org/10.48550/arxiv.2201.10154.
10. Li, S.H.; Wang, L. Neural Network Renormalization Group. Phys. Rev. Lett. 2018, 121, 260601.
11. Hu,H.; Wu,D.; You, Y.Z.; Olshausen, B.; Chen, Y. RG-Flow: A hierarchical and explainable flow model based on renormalization group and sparse prior. Mach. Learn. Sci. Technol. 2022, 3, 035009.
12. Teshima, T.; Ishikawa, I.; Tojo, K.; Oono, K.; Ikeda, M.; Sugiyama, M. Coupling-based invertible neural networks are universal diffeomorphism approximators. Adv. Neural Inf. Process. Syst. 2020, 33, 3362–3373.
13. Teshima, T.; Tojo, K.; Ikeda, M.; Ishikawa, I.; Oono, K. Universal approximation property of neural ordinary differential equations. arXiv 2017, arXiv:2012.02414.
14. Dinh, L.; Sohl-Dickstein, J.; Bengio, S. Density estimation using real nvp. arXiv 2016, arXiv:1605.08803.
15. Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114.
16. Shwartz-Ziv, R.; Tishby, N. Opening the black box of deep neural networks via information. arXiv 2017, arXiv:1703.00810.
17. Shwartz-Ziv, R.; Tishby, N. Opening the black box of deep neural networks via information. arXiv 2017, arXiv:1703.00810.
18. Williams, P.L.; Beer., R.D. Nonnegative decomposition of multivariate information. arXiv 2017, arXiv:1004.2515.
今年三月,无意中发现餐桌上父亲正在阅读的一本名为《复杂》的书,一下就被书名中“chaos”一词吸引。
作为一名对物理有极大兴趣的学生,热力学和粒子物理中的复杂与随机性一直令我着迷:处于布朗运动中的分子组成的理想气体,可以被PV=nRT简单地描述;宏观物体的运动可以在一定程度上被牛顿定律精准预测,但组成这些物体的基本粒子,却被量子物理的不确定性主宰。
深入阅读后,我了解到Santa Fe研究所、复杂科学的创立过程,越发觉得复杂科学是一门很神奇的前沿学科;又发现我很敬佩的物理学家Gell-Mann居然是Santa Fe研究所的核心创始人之一,也倍感惊喜,颇有爱屋及乌的感觉。
而封面右下角译者一栏的署名引起了我的注意:集智俱乐部。创始人张江老师的推荐序,也让我感受到集智和传统研究机构的不同:热爱、纯粹、开放。
在更深入搜索集智的信息后,我发现了其志愿者项目,被集智“不看学历,只看实力”的理念所吸引。恰好此时因果涌现第五季读书会开放,遂抱着了解与体验的想法,决定先报名参加,感受集智共创社区的氛围。听了几次读书会分享之后,我不仅震撼于讨论内容的深度,也萌生了更加深入探索复杂科学的想法。
由此产生的、对复杂科学极大的兴趣,促使我认领了翻译与整理NIS词条的共创任务。对NIS本身的选择则更为简单:翻译一篇完整的论文并整理成词条的形式,看起来颇具挑战性,也是我入门复杂科学(更精确地说是因果涌现)的极佳形式。
经过三天高强度的工作,一万多字的翻译稿已经形成,而此时真正的工作刚刚开始。仅仅将论文按顺序翻译、粘贴到词条上并不足以完成创作:翻译是第一步,将其整理成“百科”的逻辑才是最重要的。
这样的视角转换让我对词条创作的理解更加清晰——作为一位复杂科学的“门外汉”,以论文的顺序阅读NIS的介绍,需要耗费大量的精力理解;但如果将内容换个顺序,从定性的历史和研究方法出发,阅读起来便轻松许多。
在学习了集智百科中已经成熟的“因果涌现”词条结构之后,我开始了对NIS词条框架的修改:在词条最上方添加简介、从历史和概念铺垫讲起,再切换到NIS的技术基础;最后逐步引入NIS框架本身的结构与性质,完整介绍后再讨论数值实验、优缺点分析与展望。转换思路与框架之后,我开始对翻译稿进行不断的修改:省略过于复杂的一部分定量推导;更加着重背景和技术简介;把理论性质模块化……在不断的修改过程中,张江老师和王志鹏学长一次次的打磨与悉心指导,使我开始对NIS的论文和其框架本身有更加清晰、深入的了解。
最终,NIS词条完成了从一篇简单翻译稿到百科页面的蜕变,而我在这一过程中,从一开始对论文的简单逐句翻译,到整理和写作标准化流、可逆神经网络等论文中并未提及的技术介绍,不断扩充了对复杂科学的基本概念的认知,进而对因果涌现、NIS的数学定义、神经网络框架与性质等有了越发清晰的理解。
完成词条的基本写作后,我对NIS框架本身的兴趣也在与日俱增。暑假里去北京集智公寓实习的过程中,有幸在袁冰老师和杨明哲学长的面对面教学下,成功复现了NIS的实验。今后,我也计划继续深入对因果涌现和NIS框架的学习和研究,尝试构造一个量化因果涌现的测量标准;并与其他志愿者合作,继续参与词条的共创任务。
在创作NIS词条的过程中,我的视角从纯粹的翻译者,转变为读者角度,不断分析什么样的结构对理解NIS最有帮助。张老师有一个非常形象的比喻:词条写作如同做菜,翻译是“切菜”的过程,而准备好材料后的“烹饪”方式,才是最终形成词条的关键步骤。
对复杂系统的研究亦是如此:将复杂的个体行为与细节简化,从整体、宏观的视角,分析一个复杂系统的走向与趋势。正如我的偶像乔布斯所言,“将一个产品做到无与伦比的复杂其实不难,但将它化到最简,则需要设计者对产品有着最本质、最深刻的理解。”

作为北师大系统科学学院的教授,以及集智俱乐部、集智学园的创始人,集智科学研究中心院长,张江从2003年开始,就长期从事有关复杂系统建模的工作。近年来,张江带领着北师大的研究组开始聚焦在基于新兴AI技术进行基于数据驱动的自动建模研究,并立志破解复杂系统的涌现之谜。我们希望可以有对复杂系统自动建模领域有热情,且认可这个领域发展前景的朋友一起来合作,促进这一领域的快速发展。我们希望这个叫做“ Complexity AI ”,中文叫做“复杂AI次方”的开放实验室,能够真正实现思想共享、资源共享、跨学科交叉,共同为复杂系统自动建模而奋进。
详情请见:“复杂 AI 次方”开放实验室招募,挑战“涌现”难题
6. 加入集智,一起复杂!
点击“阅读原文”,报名读书会

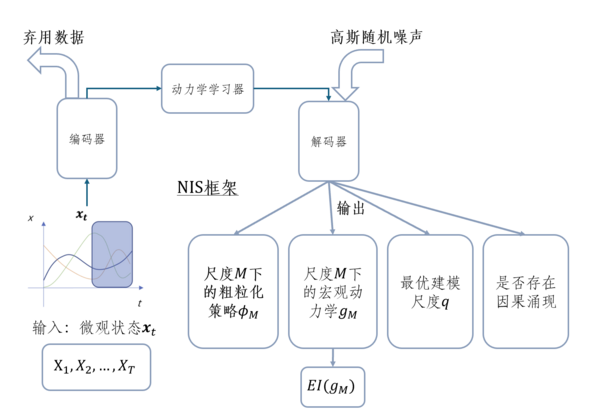
 定义为:对于任意
定义为:对于任意