随着ChatGPT等大语言模型的崛起,AI技术正在深刻改变我们的生活。然而,现有的大语言模型主要依赖统计相关性进行预测,容易产生偏见、刻板印象和“幻觉”等问题。如何让AI具备真正的因果推理能力,实现从“统计相关”到“因果关系”的跨越?如何将因果性嵌入到大语言模型(LLM)的训练过程中,构建更通用、更智能的模型?
在「因果科学与大语言模型读书会」的第十期,来自浙江大学的况琨老师和吴安鹏同学将与大家介绍最新的因果科学大模型的最新综述《Causality for Large Language Models》。读书会将回顾现有相关文献如何在大模型生态训练的各个阶段,包括嵌入学习、模型预训练、模型微调、输出对齐、结果推理和性能评估等方面,有机地融入因果性,以构建性能更强的大语言模型。最后总结一些未来可行的因果与大语言模型相结合的进一步发展方向。
集智俱乐部联合北京大学大数据科学研究中心博士研究生李昊轩、伦敦大学学院计算机博士研究生杨梦月,卡耐基梅隆大学和穆罕默德·本·扎耶德人工智能大学博士后研究员陈广义共同发起「因果科学+大模型」读书会。这是我们因果科学系列读书会的第五季,旨在探讨在大模型之后为何仍需“因果科学”?大模型如何推动因果科学的研究进展?因果科学能否在推理能力、可解释性和可信性等方面启发更优大模型的设计?以及因果科学的最新进展如何在实际领域中应用和落地?希望汇聚相关领域的学者,共同探讨因果科学的发展和挑战,推动学科发展。
因果大语言模型背景介绍
-
大语言模型的核心要素与局限性
-
虚假相关性的三大来源
-
融合因果机制的关键挑战
全周期优化方案
-
基于因果的词嵌入与预训练
-
因果导向的监督微调策略
-
基于因果推理的模型对齐
-
因果增强的推理机制
-
因果视角下的评估方法
技术创新与最新进展
-
因果Transformer基础模型
-
因果发现与注意力机制
-
反事实数据增强
-
基于LLM的因果效应估计
未来研究方向
直播时间:
11月3日20:00-22:00(周日),直播报名入口见后文。
参与方式:
集智俱乐部 B站和视频号免费直播,扫码可预约:
若需要观看视频回放,文末扫码付费参加可加入腾讯会议,可提问交流、加入群聊、获取视频回放及更多学习资料,成为因果科学社区种子用户,与一线科研工作者沟通交流,共同推动因果科学社区的发展。
[1] Wu A, Kuang K, Zhu M, et al. Causality for Large Language Models[J]. arXiv preprint arXiv:2410.15319, 2024.
[2] Liu X, Xu P, Wu J, et al. Large language models and causal inference in collaboration: A comprehensive survey[J]. arXiv preprint arXiv:2403.09606, 2024.
[3] Ma J. Causal Inference with Large Language Model: A Survey[J]. arXiv preprint arXiv:2409.09822, 2024.
大语言模型的因果性

最近,人工智能领域的突破推动了范式的转变,其中具有数十亿或万亿参数的大型语言模型(LLM),如ChatGPT、LLaMA、PaLM、Claude和Qwen,经过在海量数据集上的训练,在一系列语言任务中取得了前所未有的成功。然而,尽管取得了这些成功,LLM仍然依赖于概率建模,这种建模通常捕捉到的是植根于语言模式和社会刻板印象的虚假相关性,而不是实体与事件之间的真正因果关系。这个局限性使得LLM容易受到诸如人口偏见、社会刻板印象和LLM幻觉等问题的影响。这些挑战凸显了将因果性整合到LLM中的紧迫性,以超越依赖相关性驱动的范式,构建更可靠且符合伦理的人工智能系统。
尽管许多现有的调查和研究主要集中在利用提示工程激活LLM的因果知识或开发基准来评估它们的因果推理能力,但大多数这些努力依赖于人为干预来激活预训练模型。如何将因果性嵌入到LLM的训练过程中,并构建更通用、更智能的模型,仍然是一个未被充分探索的领域。最新的研究表明,LLM的功能类似于“因果鹦鹉”,它们能够复述因果知识,但并未真正理解或应用这些知识。这些基于提示的方法仍然局限于人类干预改进。
本次调研旨在填补这一空白,探索如何在LLM生命周期的每个阶段——从词嵌入学习、基础模型训练到微调、对齐、推理和评估——通过整合因果性来增强模型的解释性、可靠性和因果信息。此外,我们进一步提出了六个有前景的未来发展方向,以推进LLM的开发,增强它们的因果推理能力,并解决当前这些模型面临的局限性。GitHub链接: https://github.com/causal-machine-learning-lab/Awesome-Causal-LLM.
大型语言模型(LLM)是一类旨在通过利用海量数据和计算能力来处理和生成类人文本的人工智能模型[1, 2, 3, 4, 5, 6]。这些模型是基于深度学习架构,尤其是Transformer网络[7]构建的,通常在由书籍、网站、社交媒体和其他数字文本等多样化来源组成的大型数据集上进行训练[1, 2, 3, 8, 9, 10, 11]。大型语言模型的关键特征包括:
1. 规模和大小:LLM包含数十亿到数万亿的参数,这些参数是在训练过程中模型学习的内部配置。这些模型的例子包括OpenAI的GPT-3[11]、GPT-4[12],Meta的LLaMA[2, 3],谷歌的PaLM[13],Anthropic的Claude和阿里巴巴的Qwen[14]。模型越大,其对语言的理解和生成越细致。
2. 在海量数据集上的训练:LLM是在广泛的文本数据集上训练的,涵盖了多种数据来源。这些包括公开的互联网内容,如网站、博客和社交媒体平台,以及更结构化和正式的来源,如书籍、学术论文和新闻文章。通过利用这种海量的文本,LLM可以学习复杂的统计模式,包括语法、语义、上下文以及实体之间的关系。
3. 能力:LLM可以直接应用于广泛的与人类语言相关的任务,包括:
尽管LLM具备显著的能力,但其快速进展也引发了关于其伦理使用、内在偏见和更广泛社会影响的重大担忧[4, 15, 16, 17]。这些模型通常依赖从训练数据中学到的统计相关性来生成响应,而非真正理解所提出的问题。这种局限性常常导致一些问题,如幻觉——模型生成虚假或无意义的信息,以及训练数据中存在的偏见得到加强。这些缺陷极大地削弱了LLM在现实世界应用中的可靠性、准确性和安全性,特别是在医疗和法律等关键领域。在这些场景中,生成错误的诊断或治疗建议可能危害患者的健康和安全[18, 19],而错误的法律信息可能会损害司法决定的公平性和合法性[20, 21]。这些风险进一步强调了持续研究的重要性,以改进这些模型的可解释性、可靠性和伦理对齐[4, 15, 16, 17, 22]。
因果性 指的是因果关系,即一个事件直接影响另一个事件,从而解释了为什么以及如何发生某事。与只显示两个变量一起变化的相关性不同,因果性建立了一个有方向的和可操作的联系,使我们能够理解变化背后的机制。因果性是人类智能的一个重要标志,对于科学理解和理性决策至关重要[23, 24, 25, 26]。然而,当前的LLM主要是通过捕捉统计相关性而不是因果关系进行训练的,这限制了它们推理支配世界的潜在机制的能力。
虽然LLM在语言理解、生成和模式识别任务上表现出色,但它们在需要更深层因果推理的任务上往往表现不佳。在缺乏因果理解的情况下,LLM可能生成上下文相关但逻辑上不连贯的输出,导致潜在问题,如幻觉、偏见输出,以及在依赖因果关系的决策任务中表现不佳。将因果性整合到LLM中至关重要,原因有三:首先,它帮助模型超越表面相关性,使其生成更可靠且可解释的输出。其次,因果性通过使模型能够考虑数据中存在的混杂因素和系统性偏见,从而提高公平性,最终产生更符合伦理的预测。第三,它增强了模型处理复杂任务的能力,例如医疗诊断、政策规划和经济预测,在这些任务中理解因果关系至关重要。此外,因果性使LLM能够进行反事实推理,这对于探索“假设”场景并做出明智决策至关重要[26]。总体而言,将因果推理整合到LLM中代表了朝着开发不仅能理解语言,还能以更类人和科学上更严谨的方式推理世界的人工智能系统迈出的重要一步。
虽然许多现有的调查和研究[25, 26, 75]集中于利用提示工程激活LLM以提取因果实体、恢复事件之间的因果关系以及回答反事实问题,但大多数这些努力仍然严重依赖人为干预以有效利用预训练模型。将因果性直接嵌入训练过程以创建更智能和更具泛化能力的模型仍然是一个未充分探索的领域。除了依赖人类设计的提示外,在将因果推理整合到LLM中还出现了几个关键挑战:
1. 对非结构化文本数据的依赖(需要因果嵌入):LLM主要是在非结构化文本数据上进行训练的,这些数据主要传达相关性而不是明确的因果知识。在没有结构化因果数据或因果注释的情况下,LLM很难推断出实体、事件和行为之间的因果动态。在大规模语料库上训练LLM往往导致学习的是统计相关模式,而不是因果关联,限制了它们执行因果推理任务的能力。
2. 理解反事实的挑战(需要反事实语料库):因果推理通常涉及评估反事实场景——探索“如果……会怎样”的情境,这需要模型对假设的替代方案进行推理。LLM在根据统计模式预测下一个词时,难以推理这些反事实场景,因为它们缺乏保持某些变量不变的机制,同时改变其他变量。这限制了它们在决策或政策相关任务中进行深层因果推理的能力。
3. 基于Transformer模型的局限性(需要因果基础模型):Transformer的注意力机制是许多LLM的基础,旨在通过关注输入文本的不同部分来捕捉词语之间的交互。虽然它在建模上下文和语言结构上表现出色,但在捕捉实体和事件之间的深层因果关系方面往往表现不佳。注意力机制倾向于学习虚假相关性,使其易受人口偏见和社会刻板印象的影响,并缺乏推断因果关系的能力。
4. 预训练模型中的因果盲区(需要因果微调):预训练的LLM在初始训练过程中并未设计为优先考虑或检测因果关系。这些模型被优化用于文本生成和补全等任务,而不需要明确的因果推理。这种“因果盲区”限制了它们在没有微调或提示工程的情况下进行有意义的因果推理的能力,从而限制了它们在需要因果理解的实际任务中的实用性。
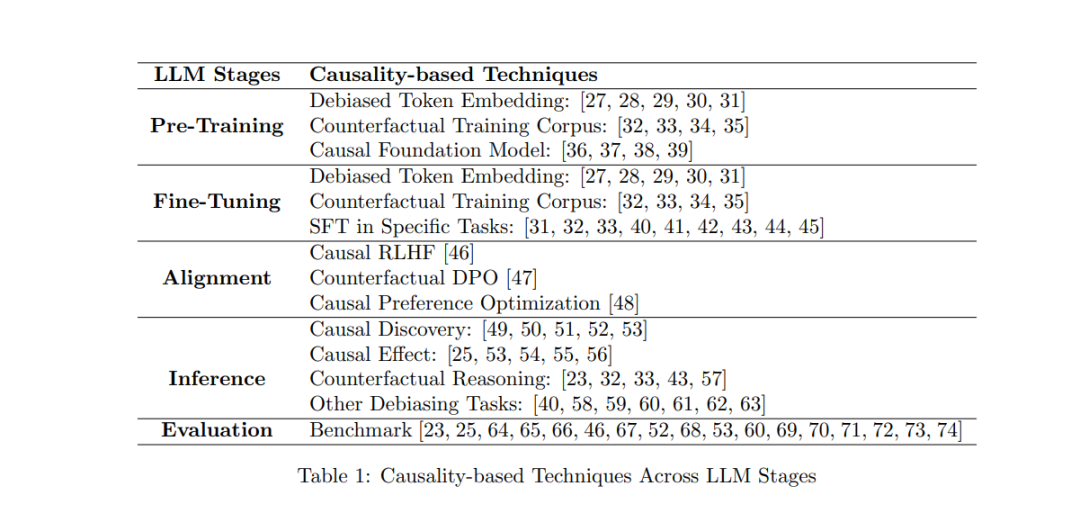
这表明,虽然LLM在语言处理方面取得了重大进展,但因果推理的整合仍然是一个充满挑战且尚未解决的前沿问题。最新的研究指出,LLM是“因果鹦鹉”,能够复述训练语料库中的因果知识,但并未真正理解或推理这些知识[64]。LLM可能是已有因果知识的优秀解释者,但不是优秀的因果推理者。当前对训练语料中统计相关性的依赖,虽然对许多自然语言任务有效,但在需要更深层次理解因果动态的任务中,LLM表现不佳。将因果性嵌入LLM的核心训练过程,而不是依赖人工设计的提示或事后干预,代表了推动该领域发展的关键下一步。为解决这一差距并整合因果性到LLM中,如表1和图1所述:
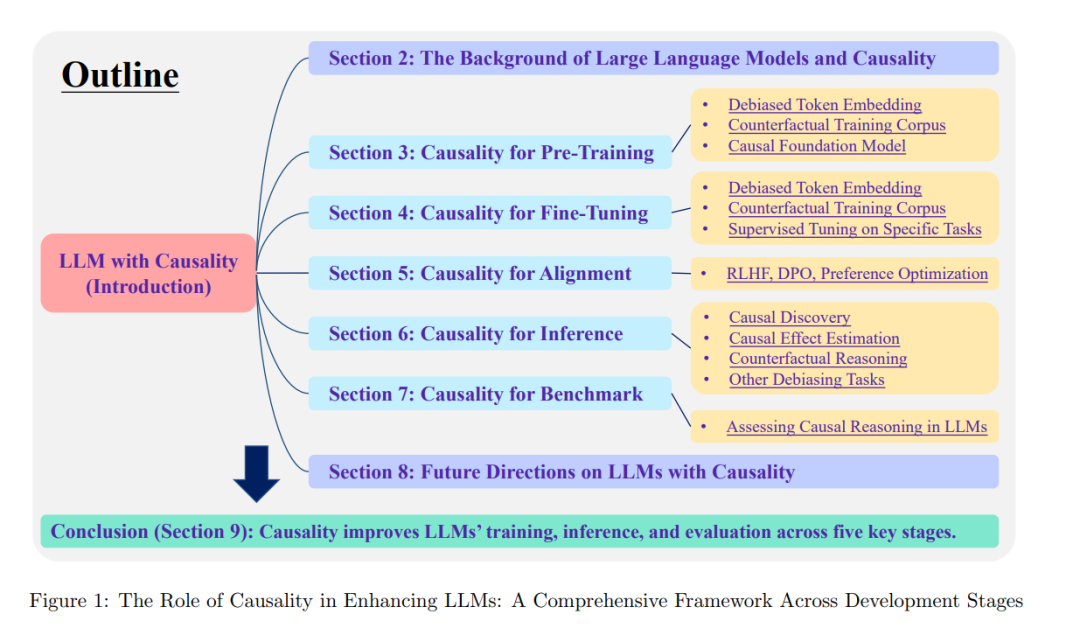
我们回顾了因果推理如何在LLM生命周期的各个阶段——从词嵌入学习、基础模型训练到微调、对齐、推理和评估——增强其能力。基于这些阶段,我们将因果性技术在LLM中的应用分为五个不同的类别(见表1)。最后,我们概述了六个有前景的未来方向,旨在推动LLM的发展,增强其因果推理能力,并克服当前模型面临的局限性。实现这一目标将带来超越传统架构的新方法,重点是捕捉语言和推理背后的基本因果关系。
本文的结构如图1所示。其余部分的安排如下:在第2节中,我们概述了LLM的最新进展,并探讨了因果性与语言模型之间的潜在关系。基于在LLM开发各阶段应用的因果驱动技术(见表1),我们回顾并提出了通过因果性改进LLM能力和解决相关问题的潜在方法,涵盖了模型生命周期的五个阶段:预训练(第3节)、微调(第4节)、对齐(第5节)、推理(第6节)和评估(第7节)。最后,在第8节中,我们重点介绍了几个有前景的未来发展方向,并在第9节对本文进行了总结。
大型语言模型(LLM)凭借其在广泛的自然语言处理任务中的卓越表现,迅速获得了广泛关注,尤其是在2022年11月ChatGPT发布之后[1, 2, 3, 8, 9, 10, 11]。这些模型令人印象深刻的语言理解和生成能力主要归功于其在庞大且多样化的人类生成文本数据集上的自回归训练。尽管LLM研究领域相对较新,但其已经经历了快速而重大的进展,并在各个领域催生了创新[4, 22, 15, 16, 17]。然而,关于LLM如何整合或从因果推理中获益的问题仍然大多未被探索。虽然LLM擅长识别文本中的模式和相关性,但整合因果推理可以为更健壮的决策和预测建模开辟新途径。将因果性引入LLM不仅有潜力提升语言任务,还可以在需要因果推理的领域(如医疗、经济学和政策分析)中应用[18, 19, 20, 21]。
2.1 什么是大型语言模型?
大型语言模型(LLM)是一类先进的机器学习架构,旨在通过在海量、多样化的人类生成文本语料库上进行训练来处理和生成自然语言[4, 15]。这些模型主要利用深度学习框架,其中Transformer架构是最为突出的[7]。通过这种架构,LLM能够建模单词、短语和句子之间的复杂依赖关系,从而捕捉人类语言中固有的丰富语言结构[76]。LLM的变革性力量在于其能够进行自回归训练,即根据所有前面的单词预测序列中的下一个单词。这个过程使得模型不仅生成语法正确的文本,还能在上下文上连贯一致,从而模仿人类的文本生成[4, 15, 16, 67, 2, 3]。关键的是,LLM在学习这些表示时不需要人为干预进行特征设计,使其在广泛的自然语言处理(NLP)任务中具有很高的通用性。这个自监督学习范式重塑了整个领域,大大减少了任务特定模型的需求,并开启了普遍语言理解和生成的新时代[4, 15]。
与传统机器学习任务不同,LLM的开发流程要复杂得多,涵盖了几个关键阶段,包括词嵌入、基础模型预训练、监督微调、通过人类反馈的强化学习(RLHF)进行对齐、基于提示的推理以及评估。以下是这些阶段的概述:
1. 词嵌入:原始文本被转换为模型可以处理的数值表示(嵌入)。这些嵌入捕捉了语义和句法信息,为模型的语言理解提供了基础[8, 77]。
2. 基础模型预训练:模型在大规模、多样化的语料库上进行广泛的预训练,使用自监督学习技术。在这一阶段,模型学习语言模式、结构和上下文的通用理解,获取适用于多种任务的表示,而不需要任务特定的标注[2, 12, 60, 67]。
3. 监督微调:在预训练阶段之后,模型通过监督微调进一步在特定的标注数据集上进行训练,以适应下游任务,如机器翻译、文本摘要或问答。这一过程提高了模型生成特定任务输出的精度和可靠性[78, 79, 80]。
4. 对齐:这一关键阶段旨在使模型的输出与人类价值观、伦理考虑和期望的行为保持一致。通常使用人类反馈强化学习(RLHF),通过人类判断优化模型的响应,从而确保生成的内容更符合社会和伦理标准[81, 82, 83]。
5. 推理:在训练完成后,模型被部署到实际应用中,其核心操作在于提示工程。通过精心设计的输入提示,模型利用其所学表示生成连贯的文本、检索信息或参与各种NLP任务中的对话。提示工程在引导模型响应以更有效地满足用户意图中起着至关重要的作用,确保在多种应用中获得最佳性能[84, 85]。
6. 评估:模型的性能在多个维度上进行严格评估,包括任务特定的准确性、对未知数据的泛化能力、伦理对齐和鲁棒性。这些评估确保模型不仅在目标任务中表现出色,还能遵循伦理准则,并在多样且具有挑战性的真实世界场景中表现出韧性[86, 87]。
在过去的几年中,LLM的发展标志着一系列里程碑模型的诞生,它们从根本上推进了我们对语言表示和生成的理解。这些模型包括但不限于OpenAI的GPT-3[11]、GPT-4[12]、Meta的LLaMA[2, 3]、谷歌的PaLM[13]、Anthropic的Claude和阿里巴巴的Qwen[14]。除了传统的NLP任务外,LLM现在还被集成到广泛的前沿研究和实际应用中,从科学发现和医疗保健到政策分析。它们无与伦比的处理和生成大规模语言的能力正在推动多个领域的变革性进展,凸显了它们在塑造AI驱动创新未来中的关键作用[88]。
预训练是大型语言模型(LLM)训练流程中的基础阶段,为模型提供了可以应用于广泛下游任务的基本语言理解能力。在这一阶段,LLM接触到大量通常未标注的文本数据,通常是在自监督学习环境下进行的。其目标是使模型能够学习可泛化的语言模式和表示。预训练方法有多种,包括下一词预测(自回归语言建模)、下一句预测、掩蔽语言建模以及专家混合(Mixture of Experts, MoE)等广泛使用的技术。
在本节中,我们首先回顾几种传统的预训练模型,包括BERT[8]、T5[9]、BLOOM[1]、GPT[10, 11]和LLAMA[2, 3],以介绍LLM的模型架构。然后,我们将深入探讨基础模型预训练中因果性的三个关键方面:(1) 去偏的词嵌入,(2) 反事实训练语料库,(3) 因果基础模型框架。
为了使预训练的基础模型在特定和通用任务中发挥作用,微调是必不可少的。在监督微调(SFT)中,模型通过使用标注数据进行优化,以适应特定任务。尽管现代大型语言模型(LLM)通常可以在无需微调的情况下处理任务,但在优化任务特定或数据特定需求时,微调仍然是有益的。微调和预训练共享一些共同的元素[33, 32, 31],例如特征提取,并且可以结合因果特征提取和反事实数据增强等高级方法。然而,两者的主要区别在于训练语料库的规模和对特定任务的关注点。在本节中,我们将回顾几种在微调阶段有效应用的因果技术。这些方法旨在通过关注数据中潜在的因果关系来增强模型的泛化能力,确保微调不仅限于相关性,还能捕捉更深层次的、与任务相关的洞察[41, 42, 43, 44, 45]。
AI对齐(Alignment)是引导AI系统行为与人类目标、偏好和伦理标准保持一致的过程。这一点尤为重要,因为尽管大型语言模型(LLM)在预训练阶段主要用于完成诸如预测句子中下一个单词的任务,但它们可能无意中生成有害、毒性、误导或带有偏见的内容。通过将AI系统与人类价值观对齐,我们可以减少这些风险,确保模型生成更安全、可靠且符合伦理的输出。为实现对齐,已经开发了多种技术,包括近端策略优化(Proximal Policy Optimization, PPO)[113],这是一种强化学习方法,旨在提高策略更新的稳定性和效率,通常用于在对齐过程中优化模型。通过人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF)[114],模型根据人类对其输出的评估进行调整,引导其生成更符合人类偏好的响应。最近,直接偏好优化(Direct Preference Optimization, DPO)[115]被引入,用以直接调整模型以更好地匹配人类的偏好,而无需使用强化学习的复杂性。
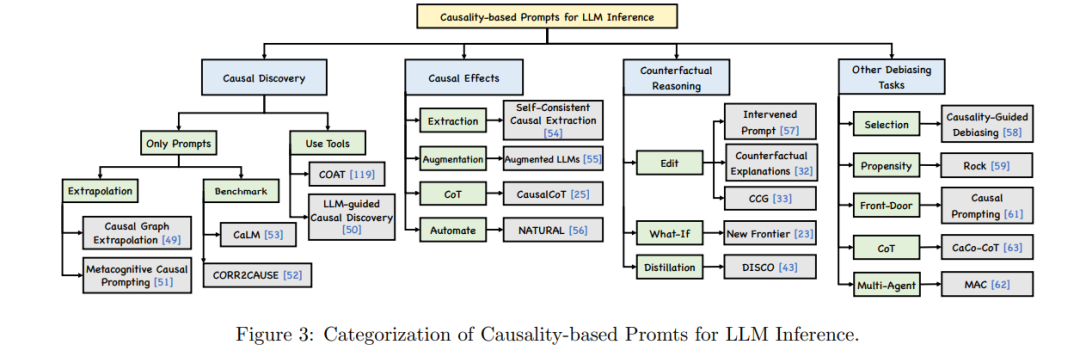
自然语言是知识和信息的存储库,主要用作交流工具,而不是思维的媒介[116]。大型语言模型(LLM)经过大规模的人类语言网络训练后,可以复述知识以应对各种语言任务,但它们仍然不知道如何应用这些知识或独立思考。因此,需通过人为干预提供“深思熟虑”的提示,来引导LLM,从而塑造它们的响应,确保整合相关知识和推理。这些过程被称为“提示工程”(Prompt Engineering)[84, 85]。为了提高LLM响应的可靠性和深度,最近的研究提出设计因果提示或因果链式推理,这些提示能够激活LLM,召回因果知识并将其整合到响应中,从而提供更准确和有洞察力的答案[32, 49, 50, 51, 54, 57, 65, 66]。在图3中,我们将这些研究分为四个不同的类别,分别关注因果性提示在不同任务中的LLM推理应用。这些包括用于因果发现、因果效应估计、反事实推理和去偏提示的精心设计的提示。在表4.1-4.4中提供了这些提示的详细示例。
在本文中,我们全面回顾了如何在大型语言模型(LLM)生命周期的各个阶段——从词嵌入、基础模型训练到微调、对齐、推理和评估——整合因果推理以提升其能力。我们重点探讨了几个关键领域:在预训练阶段使用去偏的词嵌入和反事实训练语料库以减轻偏差并改进因果特征学习;在微调阶段采用因果效应调优(Causal Effect Tuning, CET)和反事实蒸馏(Distilling Counterfactuals, DISCO)等技术,既保留基础知识,又使模型适应需要更深层次因果推理的领域特定任务;在对齐策略中,采用因果偏好优化(Causal Preference Optimization, CPO),利用因果推理将伦理考虑与用户偏好对齐。此外,我们还讨论了因果发现方法的应用,以通过区分相关性与因果关系来增强推理能力,以及整合反事实推理以促进更具反思性和适应性的决策过程。
最后,我们提出了六个有前景的未来方向,以进一步提升LLM的因果推理能力。将因果推理整合到LLM中代表了一种范式转变,使模型能够超越纯粹的统计相关性,参与结构化的因果推理。尽管像ChatGPT、LLaMA、PaLM、Claude和Qwen这样的传统模型在通过识别大型数据集中的词级模式来理解和生成语言方面表现卓越,但它们在需要深刻因果理解的任务中往往表现不佳。这些模型在区分政策分析、科学研究和医疗等领域中至关重要的潜在因果关系方面存在困难。通过嵌入因果推理,LLM能够提供更可靠且具有上下文意义的输出,尤其是在准确的因果理解至关重要的高风险领域中。
因此,将因果性整合到LLM中标志着人工智能研究中的一个重要前沿,使这些模型能够推理因果关系,并生成不仅更加准确,而且在上下文中更为适当且健全的输出。将因果知识贯穿于模型的整个生命周期——从预训练、微调到推理和对齐——使LLM能够超越模式识别,解决现实世界问题的复杂性,从而实现更深层次的推理。该因果驱动的方法解锁了LLM在医疗、科学发现和政策制定等关键领域做出重大贡献的新潜力,在这些领域,辨别因果关系对于做出明智决策至关重要。
“因果”并不是一个新概念,而是一个已经在多个学科中使用了数十年的分析技术。集智俱乐部在过去4年期间围绕研究人员的不同角度的需求,举办了4季相关主题的读书会,形成了数千人规模的社区。
【第一季:因果科学与Causal AI】基于《Elements of Causal Inference》,探讨因果科学在机器学习方面的应用,如强化学习和迁移学习等,并分享工业应用。
【第二季:因果科学与基础实战】聚焦实操和基础,深入学习《Causal inference in statistics: A primer》和《Elements of causal inference: foundations and learning algorithms》。
【第三季:因果科学与Causal +X】回顾社会学、经济学、医学,计算机等领域的因果模型和范式,尝试用现代模型提供新思路。
【第四季:因果表征学习】探讨因果表征学习的理论、技术和最新应用,涉及因果生成模型、可解释性、公平性及工业落地。
第五季读书会主要围绕因果科学的最新进展,包括因果科学与大模型的结合等方面进行深度的探讨和梳理,希望给在这个领域的研究者提供一个全面的研究图景。共同探讨因果科学的未来发展以及面临的挑战。

详情请见:速来!因果与大模型的双向赋能丨因果科学第五季强势回归