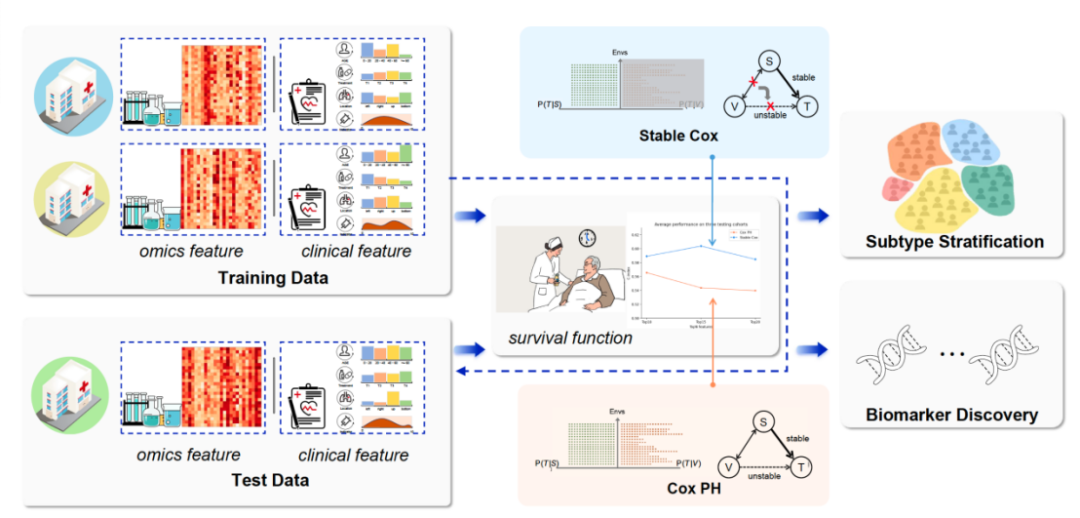
在医疗和生命科学领域,生存分析是一种关键的统计工具,用于预测患者的生存时间和事件发生的风险。然而,生存分析面临的一个主要挑战是数据的异质性,患者群体间的差异、不同医疗中心的实践差异都导致了生存数据在不同环境和人群中的分布可能截然不同,使得许多传统的生存分析模型在实际应用中变得不那么可靠。在这种背景下,稳定和可靠的生物标志物(Biomarker)的发现变得尤为重要。
近日,清华大学的崔鹏团队与国家蛋白质科学中心(北京)常乘团队联合在全球顶级期刊 Nature Machine Intelligence 上发表了“Stable Cox Regression for Survival Analysis under Distribution Shifts”研究长文。该论文提出了一种发现稳定标志物的 Stable Cox 模型,在多种癌症的组学以及临床预后数据上证明了 Stable Cox 可以发现在多个测试中心数据上稳定的预后标志物,该标志物可以用于对病人进行亚型分层以及生存曲线预测。 该工作是崔鹏团队所提出的稳定学习(Stable Learning)的理论和方法在生存分析领域的最新力作。受因果推断方法启发,稳定学习方法专注于学习协变量和输出之间的稳定因果关系,而非易变的相关性。受益于因果分析方法提供的理论保证,稳定学习方法在分布偏移场景下通常具有很强的泛化性、可解释性和公平性。
关键词:因果推断,稳定学习,生存分析,泛化能力,生物标志物
邓紫臻 | 作者
论文题目:Stable Cox Regression for Survival Analysis under Distribution Shifts
论文地址:https://www.nature.com/articles/s42256-024-00932-5
生存分析是一个重要的统计研究方向,它专注于分析预期时间直到某个特定事件发生的数据。这种分析方法在多个领域都有广泛的应用,尤其是在生命科学和医疗保健领域,它对于理解疾病的发展、评估治疗效果以及预测患者的生存时间至关重要。比如医生和医疗决策者可以利用生存分析的结果来制定治疗计划,根据患者的生存预后来选择最合适的治疗方案;研究人员通过生存分析评估新药物或治疗方法的有效性,通过比较不同治疗组的生存曲线来确定治疗效果的差异等。
生存分析处理的是时间到事件(time-to-event)数据,它涉及到测量从某一特定起点(如治疗开始、疾病诊断或其他重要事件)到某一关键事件发生的时间间隔,是生存分析中的核心概念。其中“事件”可以是患者的死亡、疾病的复发、治疗的成功或失败等。这种分析不仅关注事件发生的时间,还关注事件发生的风险,即在特定时间内事件发生的概率。
Cox风险比例模型(Cox Proportional Hazards Model)[1],又称Cox回归模型,由英国统计学家David Cox于1972年提出。该模型以生存结局和生存时间为因变量,可同时分析众多因素对生存期的影响,能分析带有截尾生存时间的数据,且不要求估计数据的生存分布类型。因上述优点,Cox回归模型迅速成为生存分析中最常用和最重要的工具之一,广泛应用于医学、公共卫生、流行病学、临床试验等多个领域。
以Cox模型为主流的大多数现有生存分析方法假设训练和测试数据具有相似的分布,而在现实中,由于不同中心或人群队列的异质性、不同仪器甚至不同分析方法等因素,这一假设常常并不成立。这对现有生存分析方法的泛化性和可靠性提出了严峻的挑战,尤其是在个性化医疗和药物研发等高风险应用中,这些模型的可靠性超越了简单的统计考量,成为生死攸关的重要问题。
应对多中心异质数据分布偏移的主要挑战是如何找到稳定的生物标志物,由于生存分析数据是复杂的“time-to-event”数据并且其本质是相关性驱动的学习机制,因此导致现有方法会盲目地学习到训练集中存在的虚假相关性(比如,病人某个基因的表达和他所在地点高度相关,然后该地点的医疗水平又会影响该病人的预后)。然而,这种虚假相关性是不稳定的,容易在测试中心数据上发生改变,导致我们训练好的生存模型在用到新的测试中心时有显著的风险。如何找到生存分析的稳定变量是困扰学界多年来的问题,也是将该类方法用到生命科学等关键领域的重要瓶颈。
稳定学习(Stable Learning)是一种机器学习方法 [2, 4],它旨在在保证预测性能的同时,减少模型在未知测试集上的方差,这种方法特别关注于模型在面对多个不同环境或分布时的泛化能力。稳定学习的核心思想是在模型训练过程中,识别和利用那些在不同环境下保持稳定性的特征,从而提高模型的鲁棒性和可靠性。
稳定学习很大程度上受到因果推断的启发,因果推断致力于识别变量之间的因果关系,即一个变量如何直接影响另一个变量,这种关系不因环境或条件的变化而改变。在机器学习领域,尤其是在稳定学习中,因果推断的原则被用来识别那些在不同环境或条件下都能保持一致影响的特征,这些特征与结果变量之间的关联更可能是因果关系而非简单的相关性。稳定学习的方法论也受到因果推断的影响。例如,因果推断中常用的协变量平衡技术,旨在消除混杂变量的影响,使得处理组和对照组在关键协变量上具有可比性。类似地,稳定学习通过样本重加权技术,尝试在不同环境或条件下平衡样本的分布,以减少模型对特定环境的依赖,增强模型的泛化能力。
Stable Cox模型是稳定学习在生存分析领域的一个应用实例,它继承了稳定学习的核心理念,即在生存数据分析中识别和利用稳定的协变量,以提高模型在不同患者群体或不同医疗环境中的泛化能力和稳定性。为了使得生存分析方法不受虚假相关影响识别稳定标志物,Stable Cox提出发现稳定的预后标志物的关键是在于消除不稳定协变量与生存结果之间的虚假相关性,从而使得学习到的相关性可以代表协变量对生存概率的因果影响,这个因果影响在不同测试中心是稳定的。
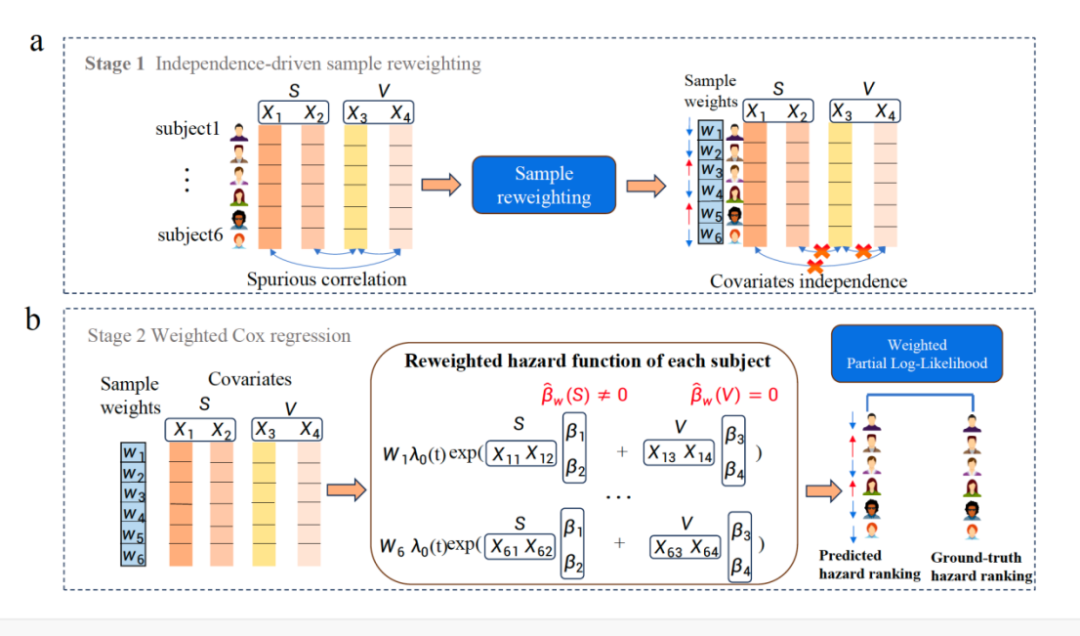
具体而言,Stable Cox 模型由两阶段组成:独立性驱动的样本加权和加权Cox回归。在独立性驱动的样本加权阶段,模型学习一套样本权重对样本进行重加权使得协变量之间相互独立(图2 a)。在加权的Cox回归阶段,Cox模型损失中的样本被之前学到的样本权重进行重加权。这个加权后的样本损失可以有效地分离每个变量对于生存输出的效应(图2 b)。从理论上,模型证明了即使在有模型错估的情况下,Stable Cox模型可以识别稳定变量进行预测,也就是模型在不稳定变量上的系数为0。
想象有一批数据,这些数据包含了很多可能影响事件的因素(比如病人的生活习惯、基因等)。在传统的方法中,所有这些因素都被认为同等重要。但Stable Cox模型认为,只有一部分因素是真正重要的,而其他的可能是噪音或者在不同情况下表现不一致的因素。样本重加权的步骤就像是给每个因素一个“信任度”评分。那些在不同情况下都能稳定预测事件的因素会得到更高的信任度,而那些表现不稳定的因素信任度会降低。这个评分过程通过样本加权的算法完成,目的是让所有因素在整体上相互独立,减少它们之间的干扰。在完成了样本重加权之后,模型进入加权Cox回归阶段,这一步是真正预测事件发生时间的阶段。在这里,每个因素都会根据之前得到的信任度来影响最终的预测结果,信任度高的因素对预测结果的影响更大,而信任度低的因素影响较小。
研究团队在模拟数据,三类癌症组学数据集(肝癌、乳腺癌、黑色素瘤)和两类癌症临床生存数据(肺癌、乳腺癌)上进行了广泛实验,采用多个独立测试群体和子群体,展示了此方法的强大泛化能力(平均提升6.5%-13.9%)。此外,Stable Cox学习得出的权重系数可用于发现潜在的组合标志物,并区分生存风险显著不同的亚型,这对于指导治疗决策和靶向药物研发具有重要意义。
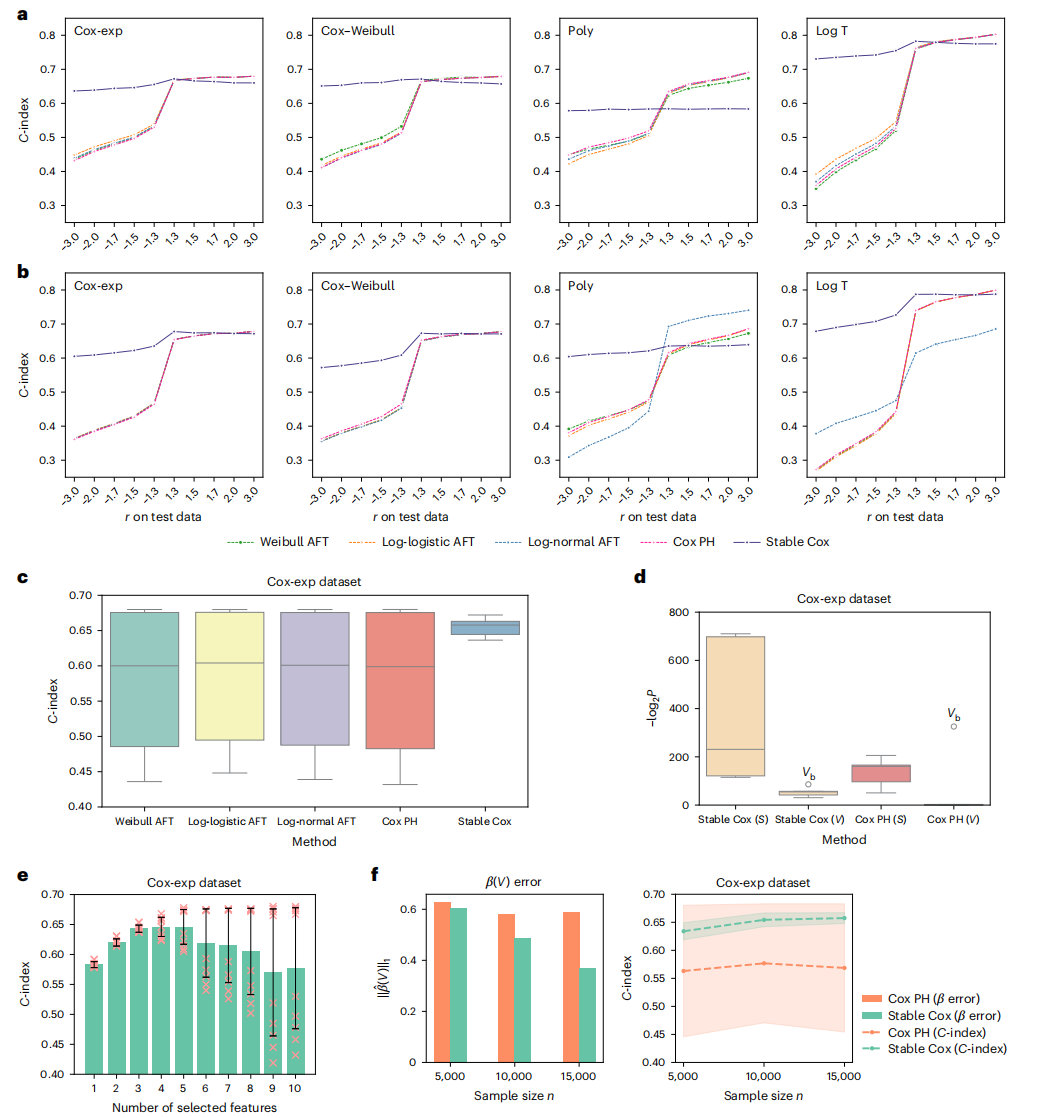
不同模型在多种模拟数据下的表现结果显示,与传统的Cox PH模型相比,Stable Cox模型在面对协变量偏移时,能够保持更低的预测误差和更高的稳定性。特别是在测试数据的分布与训练数据不一致时,Stable Cox模型的预测性能显著优于传统模型。此外,Stable Cox模型在特征选择方面也表现出色,能够识别出对生存预测最关键的生物标志物,减少不必要的特征使用,从而提高了模型的实用性和解释性。
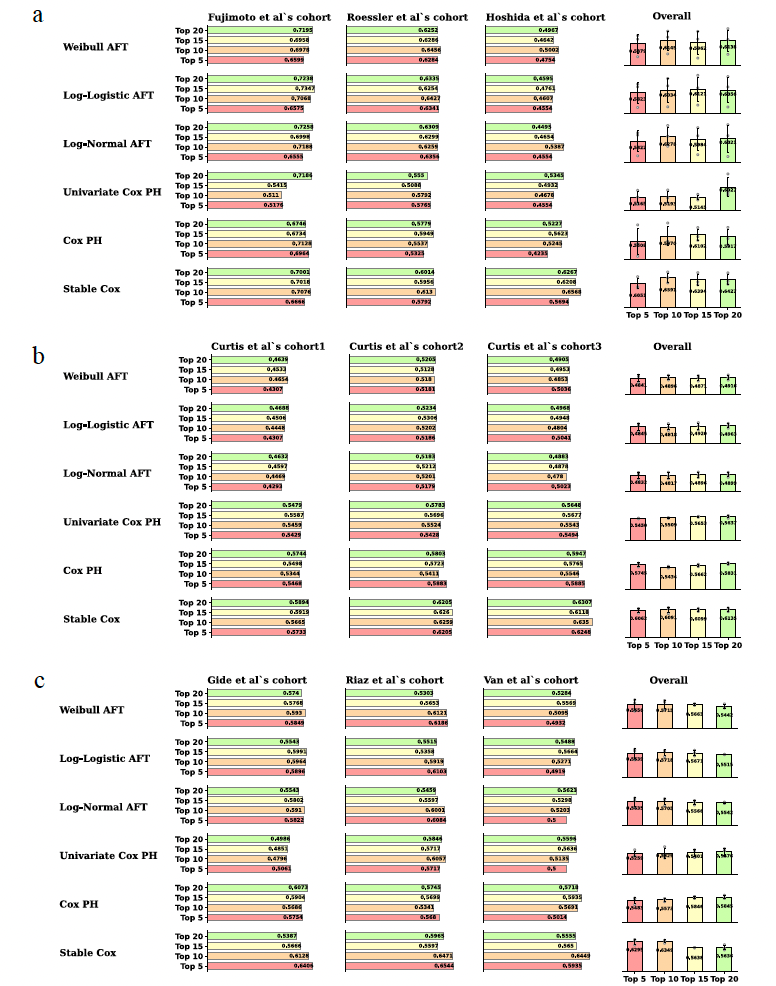
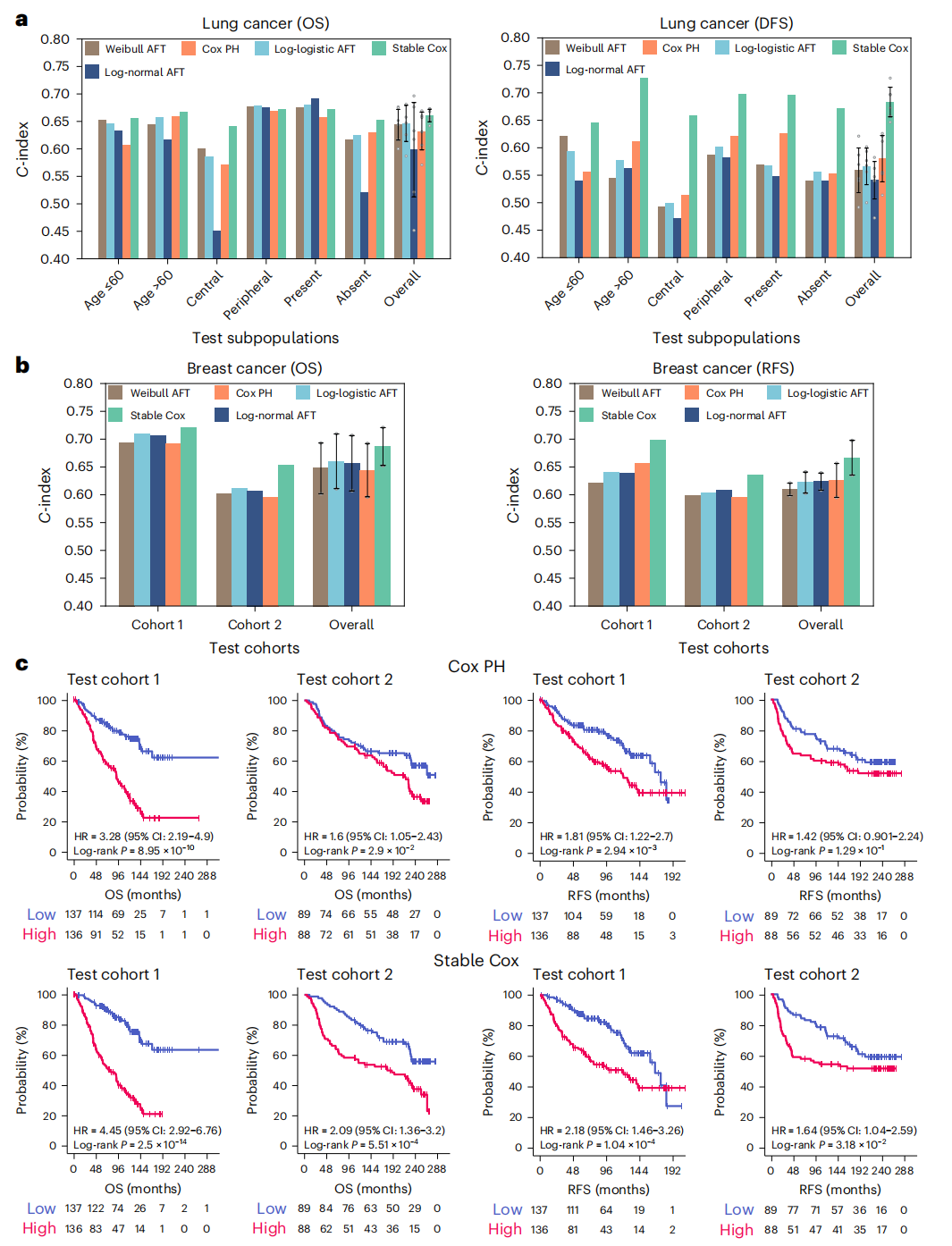
图4 在肝癌、乳腺癌、⿊⾊素瘤上Stable Cox与其他方法在多个独立测试集上的C-index比较
在肝癌数据集中,Stable Cox模型在三个独立的测试队列上均显示出比Cox PH模型更高的平均C-index,表明其在未见过的测试条件下具有更好的泛化能力和鲁棒性。同样,在乳腺癌和黑色素瘤数据集上,Stable Cox模型也展现出了优越的性能,尤其在选择较少数量的生物标志物时,其预测准确性和稳定性更为显著。这些结果证明了Stable Cox模型在识别跨不同患者群体一致有效的预后生物标志物方面的优势,这对于指导临床治疗决策和开发针对性疗法具有重要意义。
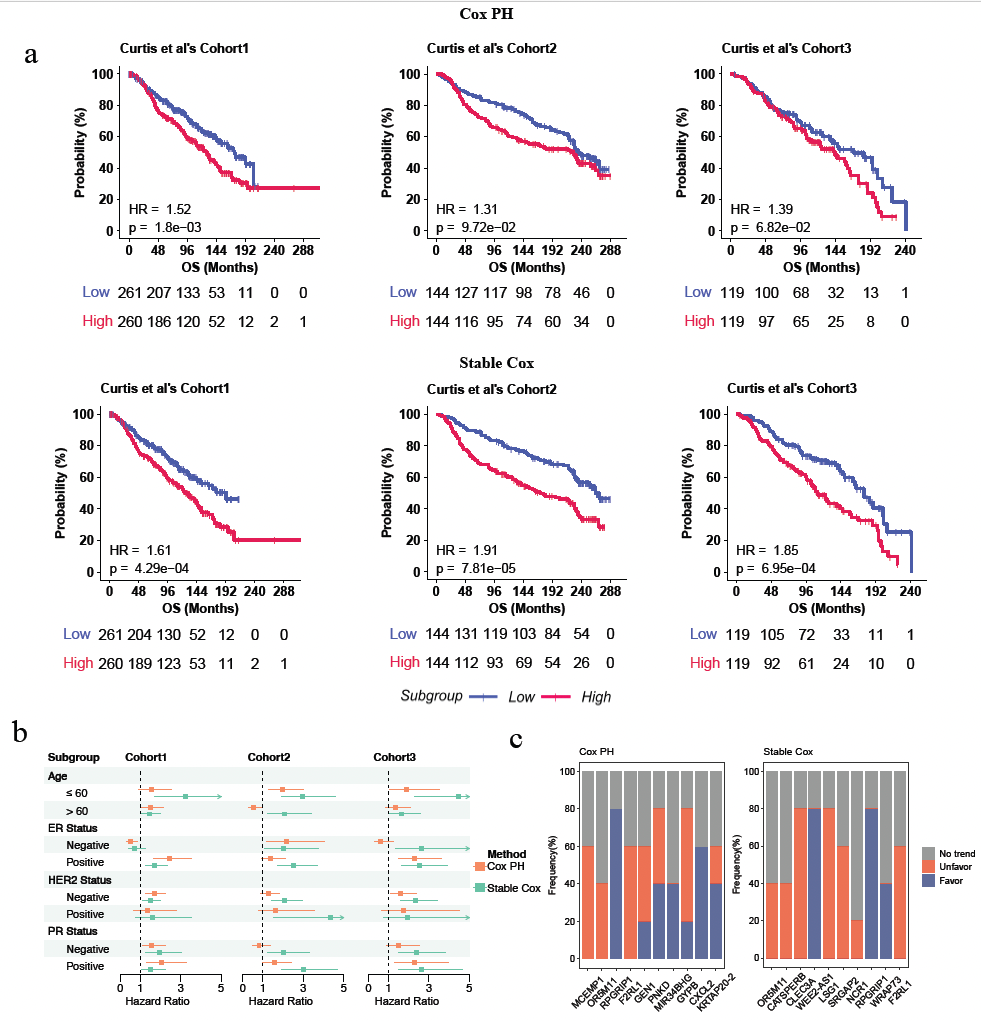
图5 Stable Cox的预后亚型人群分组结果,以及标志物在不同中心预后一致性统计
在图5中,子图a利用Kaplan-Meier生存曲线展示了由两种模型识别的基因分组的患者亚群的生存差异,揭示了Stable Cox模型在不同测试队列中具有更低的P值和更高的风险比(HR),意味着其在患者预后分层上更为精确。子图b通过单变量Cox回归分析,比较了两种模型在关键临床变量(如年龄、ER状态等)亚组中的HR值,显示Stable Cox模型在大多数亚组中识别出更高HR值,表明其在预后预测上的性能更优。子图c评估了两种模型识别的基因在训练和测试队列中的预后一致性,发现Stable Cox模型的基因显示出更高的一致性,即在不同队列中保持相同的预后趋势,而Cox PH模型则有部分基因预后趋势不一致。这些结果证明了Stable Cox模型在识别跨队列一致的预后生物标志物方面的优势。
图6 在肺癌、乳腺癌临床指标上Stable Cox与其他方法在多个人群、独立测试集上的C-index比较
在图6中,子图a聚焦于肺癌数据集,比较了不同方法在多个测试亚群中的整体生存(OS)和无病生存(DFS)性能,结果表明Stable Cox模型在各个亚群中均显著优于基线方法,尤其在OS和DFS任务中分别实现了4.5%和17.7%的性能提升。子图b进一步分析了乳腺癌数据集,Stable Cox模型在两个测试队列中均展现出对Cox PH模型的优势,无论是OS还是无复发生存(RFS)任务,均显示出更好的稳定性和预测准确性。子图c通过Kaplan-Meier生存曲线,直观展示了Stable Cox模型在乳腺癌数据集中对高风险和低风险亚群的区分能力,与Cox PH模型相比,Stable Cox模型分组的两个亚群之间的生存差异更为显著。这些结果证实了Stable Cox模型在不同临床数据集上的泛化能力和鲁棒性,特别是在处理真实世界中多样化的患者群体时,能够提供更可靠和精确的生存预测。
从已有的研究数据中发现稳定的标志物应用于未知分布是机器学习方法用于实际医疗场景中的关键和难题。然而,现有标志物识别技术的泛化能力较差,仅在与训练数据相似的患者样本中有效,无法应用于多样化的开放环境样本。这些问题使得传统技术发现的标志物难以通过前瞻性测试,不仅导致研发资源的巨大浪费,还阻碍了医药领域的进一步发展。迫切需要开发能够在异质性数据中精确识别并具有高泛化能力的生物标志物的新技术,以实现疾病的早期准确诊断,满足社会对健康保障的需求。
稳定学习及其衍生的Stable Cox模型为生存分析领域带来了新的视角和工具。以Stable Cox为代表的稳定生存分析方法旨在通过变量独立使得发现稳定预后标志物成为可能,不仅提高了模型的预测性能,还增强了模型的可解释性。该研究呼唤研究界重视机器学习方法在医疗等关键领域应用的稳定性和可靠性,同时随着研究的深入,稳定学习有望在更广泛的领域中发挥作用,推动科学发现和技术创新,为构建更加稳健和可信的预测模型提供坚实的基础。
[1] Cox, David R (1972). “Regression Models and Life-Tables”. Journal of the Royal Statistical Society, Series B. 34 (2): 187–220.
[2] Peng Cui, Susan Athey. Stable Learning Establishes Some Common Ground Between Causal Inference and Machine Learning. Nature Machine Intelligence, 2022.
[3] Renzhe Xu, Zheyan Shen, Xingxuan Zhang, Tong Zhang, Peng Cui. A Theoretical Analysis on Independence-driven Importance Weighting for Covariate-shift Generalization. ICML, 2022.
[4] https://wiki.swarma.org/index.php/%E7%A8%B3%E5%AE%9A%E5%AD%A6%E4%B9%A0
集智俱乐部联合北京大学大数据科学研究中心博士研究生李昊轩、伦敦大学学院计算机博士研究生杨梦月,卡耐基梅隆大学和穆罕默德·本·扎耶德人工智能大学博士后研究员陈广义共同发起「因果科学+大模型」读书会。这是我们因果科学系列读书会的第五季,旨在探讨在大模型之后为何仍需“因果科学”?大模型如何推动因果科学的研究进展?因果科学能否在推理能力、可解释性和可信性等方面启发更优大模型的设计?以及因果科学的最新进展如何在实际领域中应用和落地?希望汇聚相关领域的学者,共同探讨因果科学的发展和挑战,推动学科发展。读书会已完结,现在报名可加入社群并解锁回放视频权限。
推荐阅读
6. 加入集智,一起复杂!
点击“阅读原文”,报名读书会