合作的密码:从自私基因到群体智慧

导语
合作为何无处不在?从狼群围猎到国际减排,从地铁排队到开源社区,自私的本能似乎难以阻挡集体付出的脚步。在追逐个人利益的世界里,个体为何甘愿为群体出力?演化博弈理论正如一把钥匙,帮助研究人员破解这一古老悖论。美国数理生物学家 Martin Nowak 创始性地利用其揭示了群体合作的奥秘,其成果刊登在《Science》上,并在学术界引起了强烈反响。如今,这一研究领域仍在不断拓展,其意义远超单纯解释生物行为。重要的是,演化博弈理论不仅照亮了群体行为和社会结构的深层逻辑,还为人工智能、平台治理乃至大国博弈等前沿领域提供了科学指引。
关键词:演化博弈,复杂系统,群体行为,强化学习
谢凯丨作者
张江丨审校
1. “我帮你,不是因为我傻”——合作的悖论
1. “我帮你,不是因为我傻”——合作的悖论
你有没有遇到过这种情况:明明是团队任务,大家却一开始都按兵不动,等着最后几个人熬夜“背锅”;或者你一个人精心维护共享文档,别人却从来不补充更新。
你或许也曾听过这样的感慨:“我这么讲义气,结果还不是被人当冤大头?”
但奇妙的是,在很多时候,我们确实还是会选择合作。比如地铁上自觉排队、野外露营时大家轮流做饭,甚至大到国际组织中的减排协议。并且,这种现象即使在生物界也屡见不鲜:狼群合作围猎、蚂蚁协作搬家、海豚集体赶鱼等。可问题是,合作意味着要付出成本,而收益往往被别人共享,这到底值不值?
这个问题其实背后藏着一个古老又现代的哲学与科学谜题:为什么在自利的驱动下,有些人(或动物)却依然愿意付出?演化博弈理论(Evolutionary Game Theory, EGT)就是为了回答这个问题而诞生的——我们今天要聊的,就是它。
2. 从博弈论到达尔文:演化博弈到底是啥?
2. 从博弈论到达尔文:演化博弈到底是啥?
首先来破个梗:“博弈”不只是电视剧里的权谋争斗,它是一种研究冲突和合作的数学方法。
传统博弈论(Game Theory)由冯·诺依曼(Von Neumann) [1]和约翰·福布斯·纳什(John Forbes Nash Jr) [2]等人奠基,假设玩家都是理性的,并且追求收益最大化。然而,现实中我们看到的往往是:
-
有人糊里糊涂参与决策;
-
有人随波逐流看别人怎么选;
-
有人就算吃亏也愿意“做好人”。


Von Neumann(左),来源:https://en.wikipedia.org/wiki/John_von_Neumann;John Forbes Nash Jr(右),来源:https://en.wikipedia.org/wiki/John_Forbes_Nash_Jr.
这时候,生物学站了出来。查尔斯·罗伯特·达尔文(Charles Robert Darwin)的“自然选择”曾说:行为是否合理,不取决于是否理性,而在于是否能留下更多后代。基于此,1973年,约翰·梅纳德·史密斯(John Maynard Smith)和乔治·普莱斯(George Price)开创性地提出 [3]:如果我们把“策略”看成一种可遗传的行为特征,不同策略在群体中相互作用并随时间演化,就可以用博弈模型来研究人类和动物的行为,甚至推演文明进化。
Charles Robert Darwin,来源:https://en.wikipedia.org/wiki/Charles_Darwin
这就是演化博弈论。它假设玩家不一定是理性的,而是带有某种策略倾向的“个体”;策略的成功不靠深思熟虑,而是通过“适者生存”原则在群体中获得传播并稳定存在。换句话说,一个策略能否胜出,不看它理论上多“完美”,而看它在与其他策略的较量中能否“活下来”。
如何描述这种“适者生存”的过程呢?
演化博弈论引入了一个核心的数学模型——复制者动态方程(Replicator Dynamics Equation)。它描述了策略如何随时间变化,其基本思想非常直观:如果一个策略的平均收益(适应度)高于整个群体的平均收益,那么采用该策略的个体比例就会增加;反之,如果低于平均收益,则其比例会减少。例如,在一个简单的双策略(如合作与背叛)博弈模型中,合作者比例的变化率可以表示为:
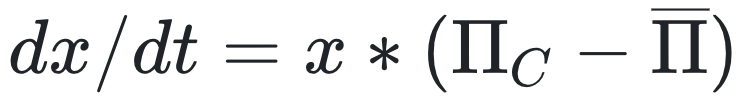
其中,x是合作者在群体中的比例,∏C是合作策略的平均收益,![]() 是整个群体的平均收益。
是整个群体的平均收益。
它和传统博弈论最大的不同在于:玩家不一定理性,但“表现好的策略”会自然留下来,“不适应的策略”被淘汰。
那么,为什么有人会合作?
演化博弈论的核心在于“策略的演化”。在自私的本能驱动下,合作策略之所以能出现,是因为它在某些条件下能带来更高的生存和繁衍优势。比如,帮助他人可能换来回报,从而在群体竞争中让“合作者”更有生存力。这种“自然选择下的合作”不仅解释了生物界的互助行为,也为人类社会的合作现象提供了线索。
3. “合则两利”没那么简单:
合作涌现的基础机制
3. “合则两利”没那么简单:
合作涌现的基础机制
我们现在知道了:演化博弈能解释“为什么有人会合作”。但真正难的,是回答另一个问题:在不合作更容易获利的情况下,合作为什么还能出现并稳定存在?
这就是演化博弈中的“合作难题”。
经典例子:公共物品博弈
想象一个场景:每个人都能为公共项目出资(比如村里修水井),但也可以选择不出钱却享受成果。
-
大家都出资,水井修成,皆大欢喜;
-
你偷懒、别人出力,你白占便宜;
-
大家都偷懒,水井没戏。
这就是“搭便车”问题,也是最难解决的合作障碍之一。

来源:作者创作
合作机制的探索
研究者发现,要解决合作困境,离不开一些关键机制。美国数理生物学家马丁·诺瓦克(Martin Nowak)提出的五种机制为促进合作的涌现奠定了基础 [4]:

Martin Nowak,来源:https://en.wikipedia.org/wiki/Martin_Nowak
1)直接互惠(Direct reciprocity):我帮你一次,下次你也要帮我。
这种机制也被称为“以牙还牙”。它适用于重复互动的场景:我今天帮你,期待你明天回报;你若坑我,我下次就不帮你。这种机制简单高效,建立了一种“可预期的回馈体系”,特别在长期关系(如合伙创业、科研团队)中能够促进信任与合作。
现实案例:朋友之间互请吃饭、邻里之间轮流照看小孩,这些都是典型的直接互惠。
2)间接互惠(Indirect reciprocity):好人出名,合作更易。
如果说直接互惠是“你帮我,我帮你”,那间接互惠就是“你帮了他,我愿意帮你”。 这就引入了“声誉”这个重要中介。你帮别人的行为被第三方看到并记住,他们会认为你是个值得合作的人,从而在未来与你建立合作关系。
现实案例:淘宝卖家靠“五星好评”吸引顾客,求职者靠推荐信增强可信度,本质上都依赖于间接互惠的传播力。
3)空间选择(Spatial Selection):熟人圈里合作更稳。
人类社会不是完全开放的,而是由小圈子构成的“关系网”。在这样的小圈子中,合作更容易维持。一方面,信息传播更快,声誉的反馈更直接;另一方面,背叛者更难“换马甲”。网络结构不仅影响合作,还决定合作是“星火燎原”还是“悄然凋零”。研究显示,在小世界网络、分层社区等网络结构中,合作更易扩散。
现实案例:公司之间贸易往来,往往优先选择与自己“关系网”中的企业进行合作。
4)群体选择(Group Selection):群体竞争促合作。
前三种机制关注个体间合作,而群体选择着眼于群体间竞争。即使个体层面合作吃亏,但合作群体若在竞争中更强大,这种策略就能存活。这是一种“宏观演化逻辑”:自私个体可能短期占优,但合作群体长期胜出。
现实案例:抗战时期,团结协作的游击队常能击败人数众多却无信任的军阀部队。
5)亲缘选择(Kin Selection):血浓于水助合作。
在亲缘关系中,个体更愿帮助血亲,即使牺牲自己利益。这是因为帮助亲属能增加共同基因的传播机会。亲缘选择解释了家庭、家族或部落中合作的高频出现。
现实案例:父母无私养育子女、兄弟姐妹互助,都是亲缘选择的体现;在动物界,蜜蜂工蜂为保护蜂后和幼蜂而牺牲生命也是如此。
来源:https://www.science.org/doi/abs/10.1126/science.1133755#core-collateral-purchase-access
4. 演化博弈遇上AI:智能体如何学会合作?
4. 演化博弈遇上AI:智能体如何学会合作?
随着多智能体系统的发展(比如机器人集群、虚拟人协作、智能体博弈策略优化等),我们越来越需要结合人工智能理解并模拟人类社会中的合作和竞争行为。要做到这一点,仅靠传统的模型和策略规则远远不够,强化学习(Reinforcement Learning, RL)正逐渐成为研究“群体智能演化”的关键工具。
强化学习:智能体的“试错”成长之路
强化学习让智能体通过与环境互动“试错”,学习最佳策略。简单来说,它就像教智能体玩游戏:
1. 每一步行动后会获得“奖励”或“惩罚”;
2. 智能体尝试不同策略,逐渐学会最大化长期奖励;
3. 策略更新的核心在于对未来收益的估计与不断修正。
在演化博弈中,RL被用来模拟个体如何在群体中选择策略,比如在公共物品博弈中决定是否贡献资源。简单来说,智能体不再依赖固定规则,而是利用RL在与环境的互动中不断“试错”,根据获得的奖励动态调整策略。
这种方法更贴近人类在社会中的行为:我们通过经验学习,逐渐找到对自己和群体最有利的选择。这使得模拟能更真实地反映个体间的学习与适应过程。
通过这种方式,我们不仅能观察群体合作行为如何涌现,还能揭示信任、背叛等复杂行为的演化规律。
Q-learning:RL-EGT的入门算法
目前最常用于EGT研究的强化学习算法之一是Q-learning [5,6],它通过学习“状态-动作值函数”来判断当前最优策略。比如,在群体合作博弈中,Q表记录着“合作”或“背叛”可能带来的回报,智能体根据Q表选择回报最高的动作,并通过不断更新Q表来优化决策。然而,传统Q-learning(TQL) 存在一个常见的问题:它容易“过度乐观”,即高估策略的预期收益。这源自其更新公式:
Q(s,a) ← Q(s,a) + α[r + γ * max Q(s’,a’) − Q(s,a)],
其中,
-
Q(s,a) 表示在状态 s 下采取动作 a 所获得的预期回报;
-
α 是学习率,表示预期回报的更新幅度;
-
r 是执行动作后获得的即时奖励;
-
γ 是折扣因子,用于权衡当前奖励与未来回报;
-
max Q(s’,a’) 是在下一个状态 s’ 中能获得的最大未来收益估计。
这里的“最大值估计”(max)让智能体既用 Q 函数来选择动作,又用它评估动作价值。这种“自说自话”的机制往往导致智能体过于相信某些策略的回报,学到的行为看似优秀,实则可能偏离最优解。
Double Q-learning:更精准的选择
最新研究中,中国学者Kai Xie与演化博弈著名学者Attila Szolnoki 教授,首次将Double Q-learning(DQL)算法引入演化模型[7]。其巧妙之处在于使用两个独立的 Q 表:
-
一个Q表负责选择动作;
-
另一个Q表负责评估该动作的价值。
这种“双人舞”设计避免了TQL中的“自欺欺人”现象——在TQL中,同一个Q表既选动作又估价值,容易产生偏差。DQL的更新规则如下:
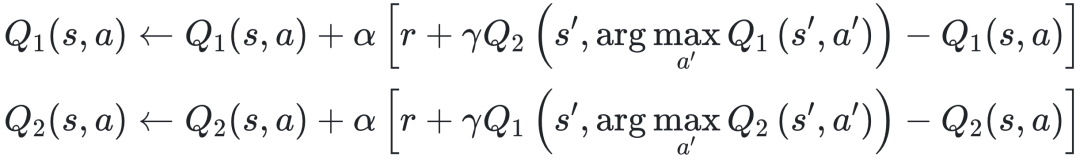
简单来说,两个Q表轮流更新,一个选动作时参考另一个的价值评估,从而减少偏差,让智能体的决策更精准。

Attila Szolnoki,来源:https://ieeexplore.ieee.org/author/37090052031
研究表明,相比TQL,DQL 降低了策略偏差,让智能体更倾向于选择合作策略,形成稳定的合作集群。这种改进就像给智能体装上了“更清晰的眼镜”,让它们更准确地感知群体动态。
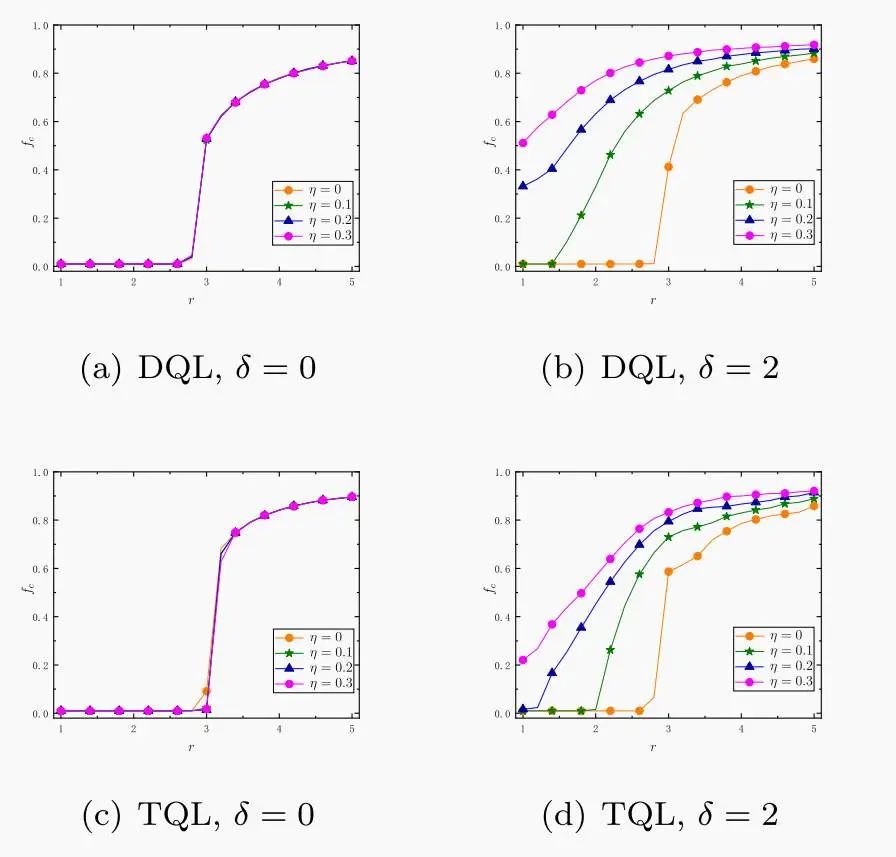
TQL和DQL算法对比。(b)和(d) ,在关键参数不为0的情况下,在促进合作水平方面,DQL整体优于TQL算法。来源:https://www.sciencedirect.com/science/article/pii/S0960077925004114
深度强化学习:复杂场景的突破
除了 Q-learning 及其变体,与深度强化学习(DRL)相关的算法也开始在演化博弈中大放异彩。最具代表性的是深度Q网络(Deep Q-Network, DQN),它利用深度神经网络逼近 Q 值函数,能处理高维度、复杂状态空间的博弈场景。最新的研究被发表在计算机顶级会议IJCAI [8,9]。
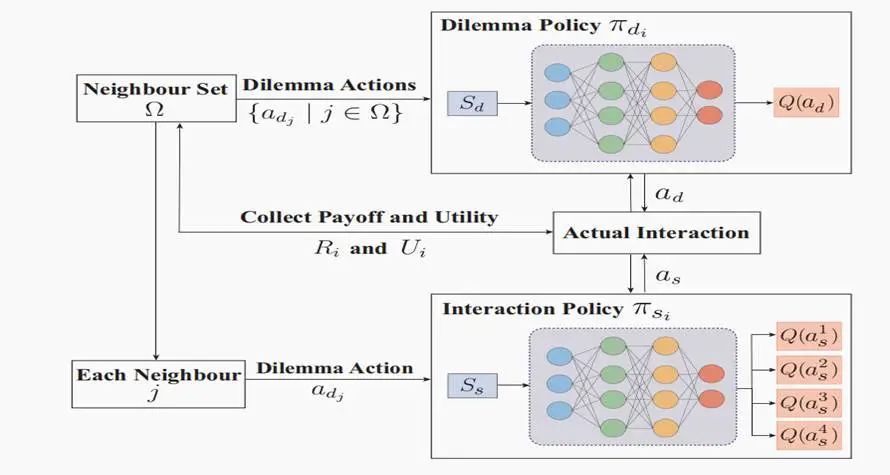
DQN网络演化博弈训练框架,来源:https://arxiv.org/abs/2405.02654
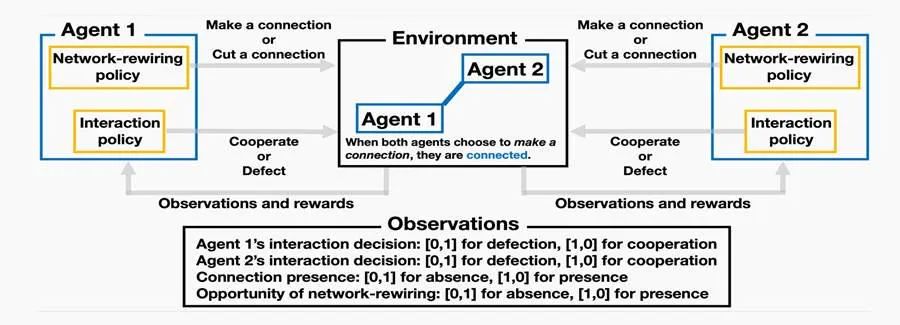
DQN网络演化博弈训练框架,来源:https://arxiv.org/abs/2310.04623
从经典的TQL算法,到有效缓解过估计问题的DQL,再到利用神经网络处理复杂环境信息的 DQN,可以预见,深度强化学习与演化博弈的交叉将在未来进一步深化。这种结合不仅仅是技术层面的融合,更是理念上的升华。我们正在见证智能体从最初专注于“如何最大化自身奖励”的阶段,逐步迈向能够理解和实践“合作共赢”的新纪元。这意味着智能体正在从“学会赢”走向“学会共赢”。
5. 从理论走向实践:
演化博弈的学科交叉前景
5. 从理论走向实践:
演化博弈的学科交叉前景
演化博弈理论从生物学的土壤中萌芽,如今已成长为一棵覆盖心理学、人工智能、社会学、经济学乃至生态治理等多个领域的跨学科大树。它不仅揭示了合作的深层逻辑,也为解决现实世界中的复杂问题提供了实用工具。
在心理学[10]领域,演化博弈被用来解释信任、利他、惩罚、共情等社会行为的起源;研究者通过构建博弈模型,探索人类为何会“做对他人有利却对自己不利的选择”,甚至将其作为分析群体道德直觉的工具。
在人工智能 [11]领域,演化博弈正逐渐成为多智能体学习中的关键理论框架。特别是在无人驾驶、机器人编队协同、元宇宙社交与虚拟经济治理等前沿应用中,理解如何激励“异质智能体”产生持续稳定的合作,比单纯提高算法性能更具战略意义。
在政策治理 [12]方面,演化博弈大有可为。在中美贸易摩擦中,演化博弈能分析关税策略的长期效应,帮中国设计灵活应对方案;在“一带一路”中,它能预测沿线国家的合作意愿,助力政策精准落地。面对大国博弈的“囚徒困境”,演化博弈是破解僵局的科学利器。
在生态与环境政策 [13]中,它也为气候协议、渔业保护、污染防治等全球治理难题提供了理论支持。例如,通过模拟国家之间“合作减排”与“逃避责任”的演化博弈,政策制定者能更清晰地看到激励机制的重要性。
未来,随着大数据、深度强化学习、群体智能与大模型的发展,演化博弈不仅将在理论维度不断深化,也将在更广泛的实践场景中开枝散叶。
正如我们所见,合作从不是理所当然,它是自然选择下的“非理性智慧”,也是人类社会赖以运转的“理性幻想”。从自私基因到群体智慧,在这个智能重塑世界的时代,演化博弈用数字与人性的交融告诉我们:理解合作的本质,才能真正设计出值得信任的世界。
参考文献
[1]v. Neumann, J. (1928). Zur theorie der gesellschaftsspiele. Mathematische Annalen, 100(1), 295-320.
[2]Nash Jr, J. F. (1950). Equilibrium points in n-person games. Proceedings of the National Academy of Sciences, 36(1), 48-49.
[3]Maynard Smith, J. (1976). Evolution and the Theory of Games. American Scientist, 64(1), 41-45.
[4]Nowak, Martin A. “Five rules for the evolution of cooperation.” Science 314.5805 (2006): 1560-1563.
[5]Zheng, G., Zhang, J., Deng, S., Cai, W., & Chen, L. (2024). Evolution of cooperation in the public goods game with Q-learning. Chaos, Solitons & Fractals, 188, 115568.
[6]Tamura, K., & Morita, S. (2024). Analysing public goods games using reinforcement learning: effect of increasing group size on cooperation. Royal Society Open Science, 11(12), 241195.
[7]Xie, K., & Szolnoki, A. (2025). Reputation in public goods cooperation under double Q-learning protocol. Chaos, Solitons & Fractals, 196, 116398.
[8]Ren, T., & Zeng, X. J. (2024). Enhancing cooperation through selective interaction and long-term experiences in multi-agent reinforcement learning. arXiv preprint arXiv:2405.02654.
[9]Ueshima, A., Omidshafiei, S., & Shirado, H. (2023). Deconstructing cooperation and ostracism via multi-agent reinforcement learning. arXiv preprint arXiv:2310.04623.
[10]Conroy-Beam, D., Goetz, C. D., & Buss, D. M. (2015). Why do humans form long-term mateships? An evolutionary game-theoretic model. In Advances in experimental social psychology (Vol. 51, pp. 1-39). Academic Press.
[11]Wu, Y., & Pan, L. (2024). LSTEG: An evolutionary game model leveraging deep reinforcement learning for privacy behavior analysis on social networks. Information Sciences, 676, 120842.
[12]Feng, N., & Ge, J. (2024). How does fiscal policy affect the green low-carbon transition from the perspective of the evolutionary game?. Energy Economics, 134, 107578.
[13]Tilman, A. R., Plotkin, J. B., & Akçay, E. (2020). Evolutionary games with environmental feedbacks. Nature Communications, 11(1), 915.
笔者(谢凯)围绕演化博弈理论发表的论著
[1]Xie, K., & Szolnoki, A. (2025). Reputation in public goods cooperation under double Q-learning protocol. Chaos, Solitons & Fractals, 196, 116398.
[2]Xie, K., & Liu, T. (2024). The regulation of good and evi promotes cooperation in public goods game. Applied Mathematics and Computation, 478, 128844.
[3]Xie, K., Liu, Y., & Liu, T. (2024). Unveiling the masks: Deception and reputation in spatial prisoner’s dilemma game. Chaos, Solitons & Fractals, 186, 115234.
[4]Xie, K., Liu, X., Wang, H., & Jiang, Y. (2023). Multi-heterogeneity public goods evolutionary game on lattice. Chaos, Solitons & Fractals, 172, 113562.
[5]Xie, K., Liu, X., Chen, H., & Yang, J. (2022). Preferential selection and expected payoff drive cooperation in spatial voluntary public goods game. Physica A: Statistical Mechanics and its Applications, 605, 127984.
作者:

本文为科普中国-创作培育计划扶持作品 作者 | 谢凯 审核 | 张江(北京师范大学系统科学学院教授) 出品 | 中国科协科普部 监制 | 中国科学技术出版社有限公司、北京中科星河文化传媒有限公司

复杂网络动力学读书会

6. 探索者计划 | 集智俱乐部2025内容团队招募(全职&兼职)
微信扫一扫,分享到朋友圈











